 ShuffleNet_v1与v2:模型架构、计算复杂度与优化
ShuffleNet_v1与v2:模型架构、计算复杂度与优化





 ShuffleNet是一种轻量级的深度学习模型,旨在降低计算复杂度,提高运行速度。ShuffleNet_v1通过组卷积和深度可分离卷积降低FLOPs,而ShuffleNet_v2则提出了新的设计准则,包括避免MAC碎片化、减少卷积层输入输出通道数不等的情况等,进一步优化了网络架构。 Shuffle操作在组间信息交互中起到关键作用,同时v2版还调整了1*1卷积和ReLU的位置,以提高效率。
ShuffleNet是一种轻量级的深度学习模型,旨在降低计算复杂度,提高运行速度。ShuffleNet_v1通过组卷积和深度可分离卷积降低FLOPs,而ShuffleNet_v2则提出了新的设计准则,包括避免MAC碎片化、减少卷积层输入输出通道数不等的情况等,进一步优化了网络架构。 Shuffle操作在组间信息交互中起到关键作用,同时v2版还调整了1*1卷积和ReLU的位置,以提高效率。
目录
shuffleNet结合ResNeXt的组卷积(GConv)与MobileNet的DW卷积。ResNeXt中1*1卷积占用了94.3%的Mdds,引入组卷积GConv减少计算复杂度。进行组卷积时,每组卷积独立进行,因此引入shuffle操作使得Group与Group间信息交互。
1.shuffle操作
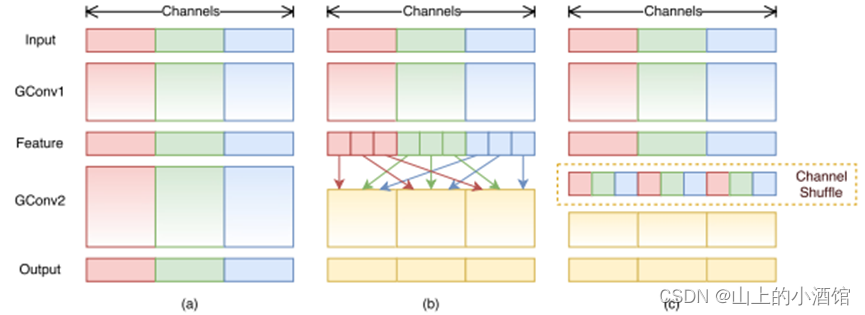
2.计算复杂度对比:
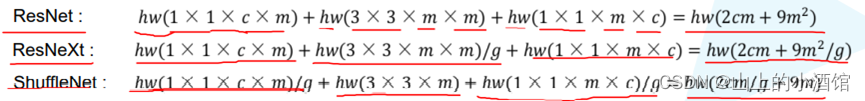
相较于ResNet,ShuffleNet_v1对1*1的卷积进行了分组,并且中间3*3卷积使用DW卷积,组数g=通道数m。
3.Shuffle Net_v1模型架构以及参数设定
接下来看模型架构与各层的参数:
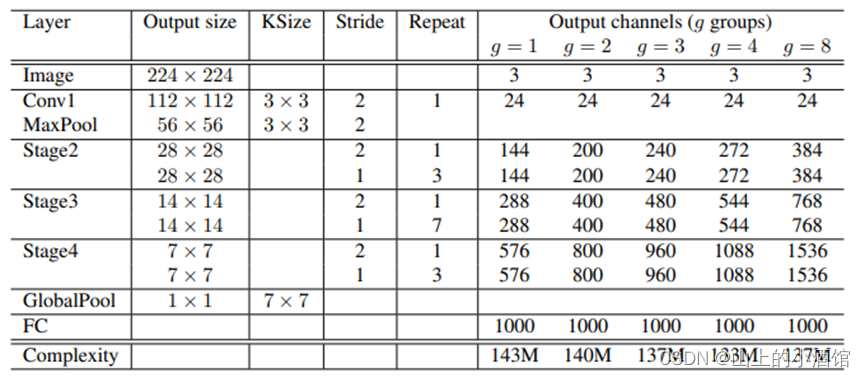
每个stage的第一个block步距stride为2,下个阶段输出channels翻倍(下采样)如结构图(c)。bottleneck(中间3*3DW卷积)的通道数为输出通道的1/4。
4.Shuffle Net_v1准确率
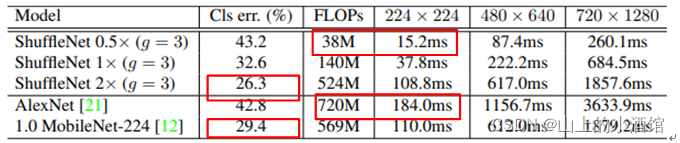
shufflenet_v2
5.Shuffle Net_v2设计准则
shufflenet_v2提出了四条高效设计网络的指标,
FLOPs是间接指标,而速度才是模型计算快慢的直接指标,MAC(内存占用)、平台、并行度都是影响模型快慢的指标,提出四条设计高效网络的准则:
(1)卷积层的输入特征矩阵与输出特征矩阵通道数相等时,MAC最小。

(2)当GConv的group增大时(FLOPs不变),MAC也增大。
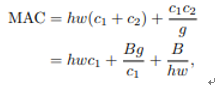
(3)网络的碎片化程度越高,网络越慢。虽然提高精度,但对具备并行运算的硬件设备不友好。
(4)Element—wise(ReLU、shortcut等)的影响不可忽略。
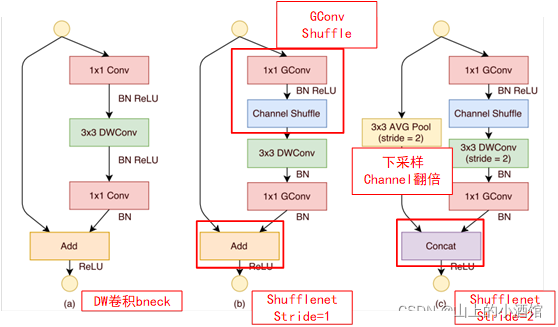
6.Shuffle Net_v2网络架构改进
根据以上四条原则, shufflenet_v2对 shufflenet_v1进行了一系列改进,网络架构如下图:
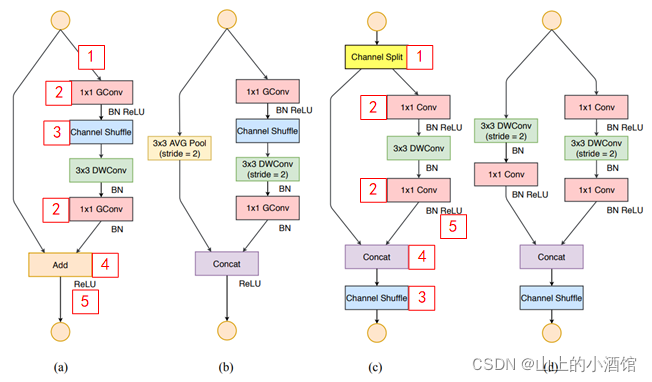
1处采用划分channle_split的方式,减少进入bneck的通道数,对半分。
2处将组卷积改回普通1*1卷积,遵循第二条2,较少组数g。
3处采用shuffle的位置变化。
4处采用concat拼接保证整体input_c=output_c。
5处ReLU的位置变化。
6bneck中1*1—3*3—1*1三层卷积的输入通道数与输出通道数相等。
(d)图中下采样操作,通道划分channle_split,输出通道数增加为两倍。
7.Shuffle Net_v2参数
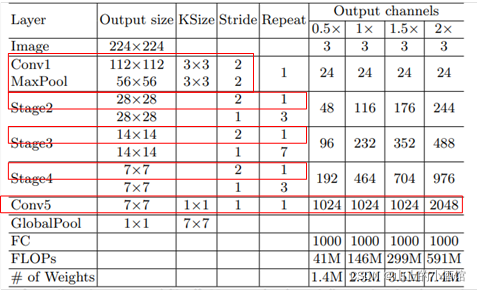
对于每一个stage的第一个block,channel翻倍,比如stage2的block1,每个分支有58个channels,对应(d)图。而其他block采用split的方法将input_channels均分。


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











