










 本文详细介绍了量化感知训练(QAT)的概念,其通过在训练过程中模拟量化,以减少量化带来的精度损失并提高模型在特定硬件上的运行效率。文章还提供了全代码示例,展示了如何在PyTorch中实现QAT,包括模型搭建、observer的加入以及校准和量化的过程。
本文详细介绍了量化感知训练(QAT)的概念,其通过在训练过程中模拟量化,以减少量化带来的精度损失并提高模型在特定硬件上的运行效率。文章还提供了全代码示例,展示了如何在PyTorch中实现QAT,包括模型搭建、observer的加入以及校准和量化的过程。
QAT是对PTQ的优化,如果不熟悉PTQ的朋友可以康康这篇先哦:
《模型量化(二)—— 训练后量化PTQ(全代码)》
QAT介绍
量化感知训练(Quantization Aware Training, QAT)是一种减小深度学习模型大小、提高运行效率,同时尽量减少量化带来的精度损失的方法。与传统的训练后量化(Post-training Quantization)不同,QAT在训练过程中模拟量化的效果(伪量化因子),使得模型能够适应量化带来的信息损失,从而在实际应用量化时保持更高的性能。
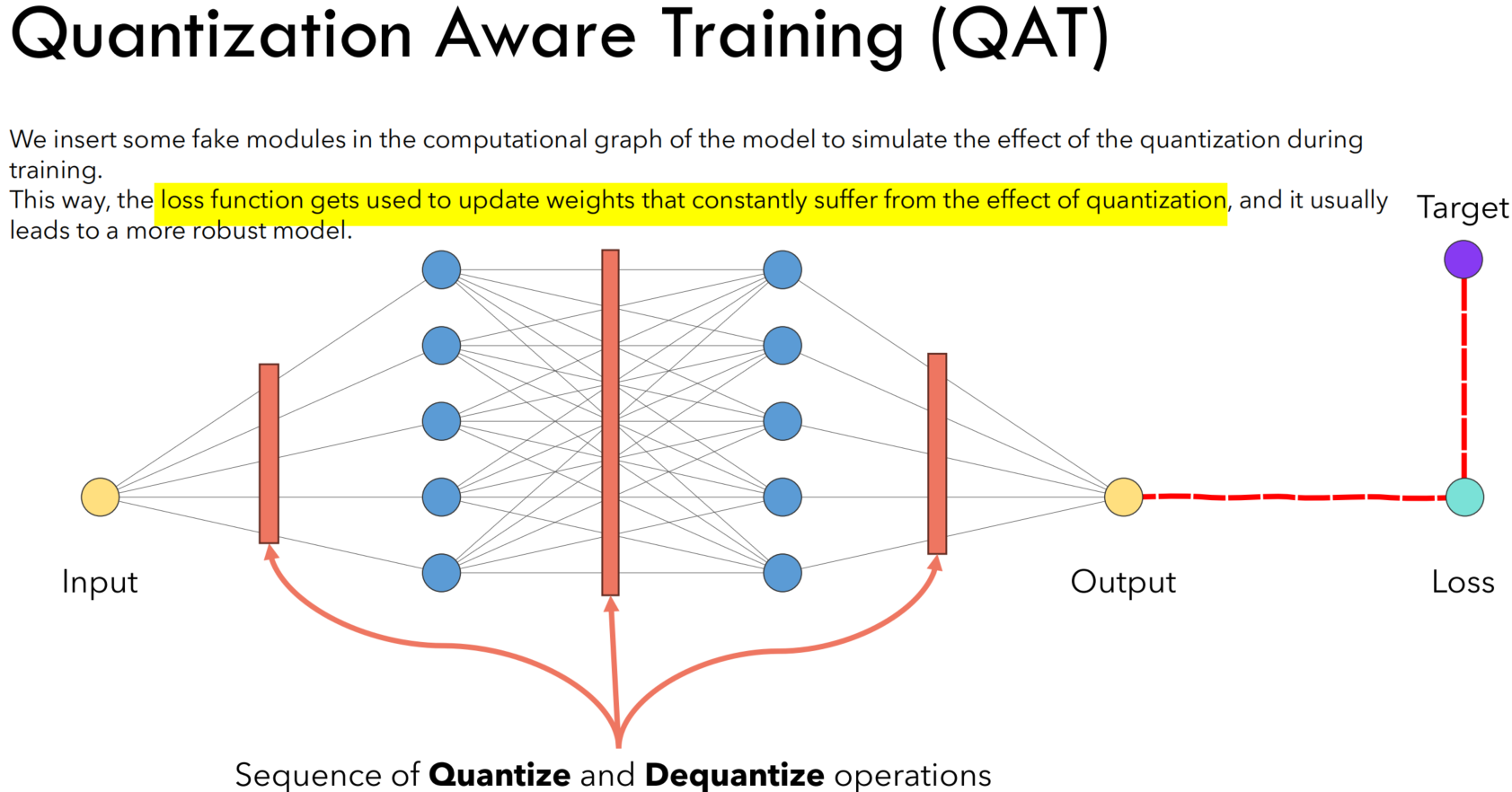
QAT的关键思想是在模型训练过程中引入量化的操作,让模型“意识”到量化过程,并通过反向传播优化模型参数,以适应量化带来的影响。具体来说,QAT遵循以下步骤:
- 模拟量化:在模型的前向传播过程中,将权重和激活值通过量化和反量化的过程,模拟量化在实际部署中的效果。这意味着,权重和激活值先被量化到低位宽的整数表示,然后再被反量化回浮点数,以供后续的计算使用。
- 梯度近似:由于量化操作(如取整)是不可微分的,为了在反向传播过程中计算梯度,QAT采用了梯度近似的技术。常见的方法包括直接通过量化操作传递梯度(即假设量化操作的梯度为1)或使用“直通估计”(Straight Through Estimator, STE)。
- 优化参数:通过模拟量化的前向传播和梯度近似的反向传播,模型参数在训练过程中得到优化,使模型适应量化后的表示。
QAT优点:
- 减少量化损失:由于QAT在训练过程中考虑了量化的影响,它可以显著减少量化对模型精度的负面影响,相比于PTQ,通常能够获得更好的性能。
- 提高模型兼容性:QAT使模型适应了量化后的权重和激活值的分布,从而提高了模型在特定硬件上的兼容性和运行效率。
- 灵活性和适应性:QAT允许开发者根据目标平台的特定需求,调整量化方案(如量化位宽、量化策略等),优化模型的性能。
注意,QAT和PTQ不是对立关系,QAT得到一个准备好量化的预训练模型,PTQ(或者其他高阶的量化技术)对这个预训练模型进行量化压缩,QAT的目的是通过在训练阶段就考虑量化的效果,为量化后的模型提供了一种“内生”的适应性,让PTQ压缩时模型精度最大程度保留。
当然,QAT最大的 overhead 就是训练成本。由于QAT需要在训练过程中模拟量化的效果,它可能会增加模型训练的时间和计算资源消耗。
全代码
代码跟上一篇《模型量化(二)》很像的,只是改了点pytorch对于QAT的函数,主要是 torch.ao.quantization.prepare 变成 torch.ao.quantization.prepare_qat
模型搭建与加入observer
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.nn as nn
import matplotlib.pyplot as plt
from tqdm import tqdm
from pathlib import Path
import os
# Make torch deterministic
_ = torch.manual_seed(0)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# Load the MNIST dataset
mnist_trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# Create a dataloader for the training
train_loader = torch.utils.data.DataLoader(mnist_trainset, batch_size=10, shuffle=True)
# Load the MNIST test set
mnist_testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(mnist_testset, batch_size=10, shuffle=True)
# Define the device
device = "cpu"
class VerySimpleNet(nn.Module):
def __init__(self, hidden_size_1=100, hidden_size_2=100):
super(VerySimpleNet,self).__init__()
self.quant = torch.quantization.QuantStub()
self.linear1 = nn.Linear(28*28, hidden_size_1)
self.linear2 = nn.Linear(hidden_size_1, hidden_size_2)
self.linear3 = nn.Linear(hidden_size_2, 10)
self.relu = nn.ReLU()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, img):
x = img.view(-1, 28*28)
x = self.quant(x)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.linear3(x)
x = self.dequant(x)
return x
net = VerySimpleNet().to(device)
net.qconfig = torch.ao.quantization.default_qconfig
net.train()
net_quantized = torch.ao.quantization.prepare_qat(net) # Insert observers
net_quantized
def train(train_loader, net, epochs=5, total_iterations_limit=None):
cross_el = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
total_iterations = 0
for epoch in range(epochs):
net.train()
loss_sum = 0
num_iterations = 0
data_iterator = tqdm(train_loader, desc=f'Epoch {epoch+1}')
if total_iterations_limit is not None:
data_iterator.total = total_iterations_limit
for data in data_iterator:
num_iterations += 1
total_iterations += 1
x, y = data
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
output = net(x.view(-1, 28*28))
loss = cross_el(output, y)
loss_sum += loss.item()
avg_loss = loss_sum / num_iterations
data_iterator.set_postfix(loss=avg_loss)
loss.backward()
optimizer.step()
if total_iterations_limit is not None and total_iterations >= total_iterations_limit:
return
def print_size_of_model(model):
torch.save(model.state_dict(), "temp_delme.p")
print('Size (KB):', os.path.getsize("temp_delme.p")/1e3)
os.remove('temp_delme.p')
train(train_loader, net_quantized, epochs=1)
#就训练一个epoch意思意思
校准
def test(model: nn.Module, total_iterations: int = None):
correct = 0
total = 0
iterations = 0
model.eval()
with torch.no_grad():
for data in tqdm(test_loader, desc='Testing'):
x, y = data
x = x.to(device)
y = y.to(device)
output = model(x.view(-1, 784))
for idx, i in enumerate(output):
if torch.argmax(i) == y[idx]:
correct +=1
total +=1
iterations += 1
if total_iterations is not None and iterations >= total_iterations:
break
print(f'Accuracy: {round(correct/total, 3)}')
print(f'Check statistics of the various layers')
net_quantized
量化模型
net_quantized.eval()
net_quantized = torch.ao.quantization.convert(net_quantized)
print(f'Check statistics of the various layers')
net_quantized
# Print the weights matrix of the model after quantization
print('Weights after quantization')
print(torch.int_repr(net_quantized.linear1.weight()))
print('Size of the model after quantization')
print_size_of_model(net_quantized)
print('Testing the model after quantization')
test(net_quantized)
搞定。
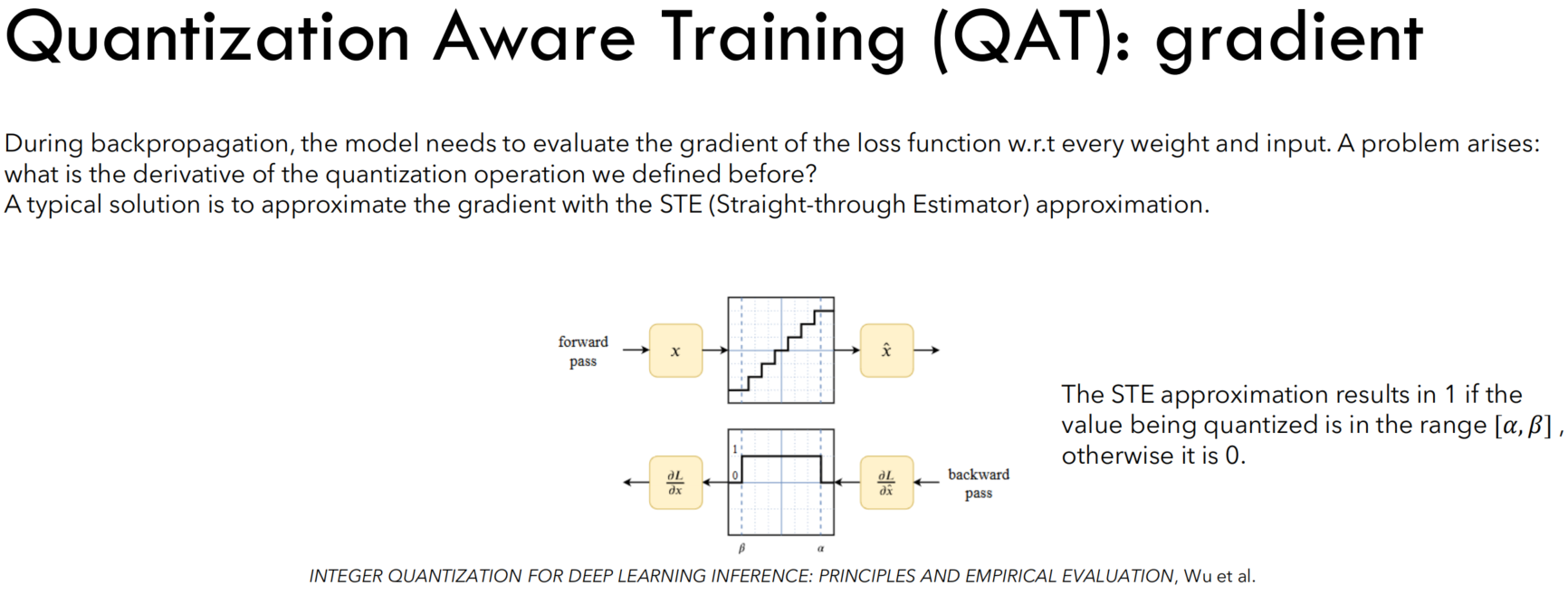
梯度问题
由于量化操作(如取整)是不可微分的,为了在反向传播过程中计算梯度,QAT采用了梯度近似的技术。常见的方法包括直接通过量化操作传递梯度(即假设量化操作的梯度为1)或使用“直通估计”(Straight Through Estimator, STE)。
QAT的合理性分析
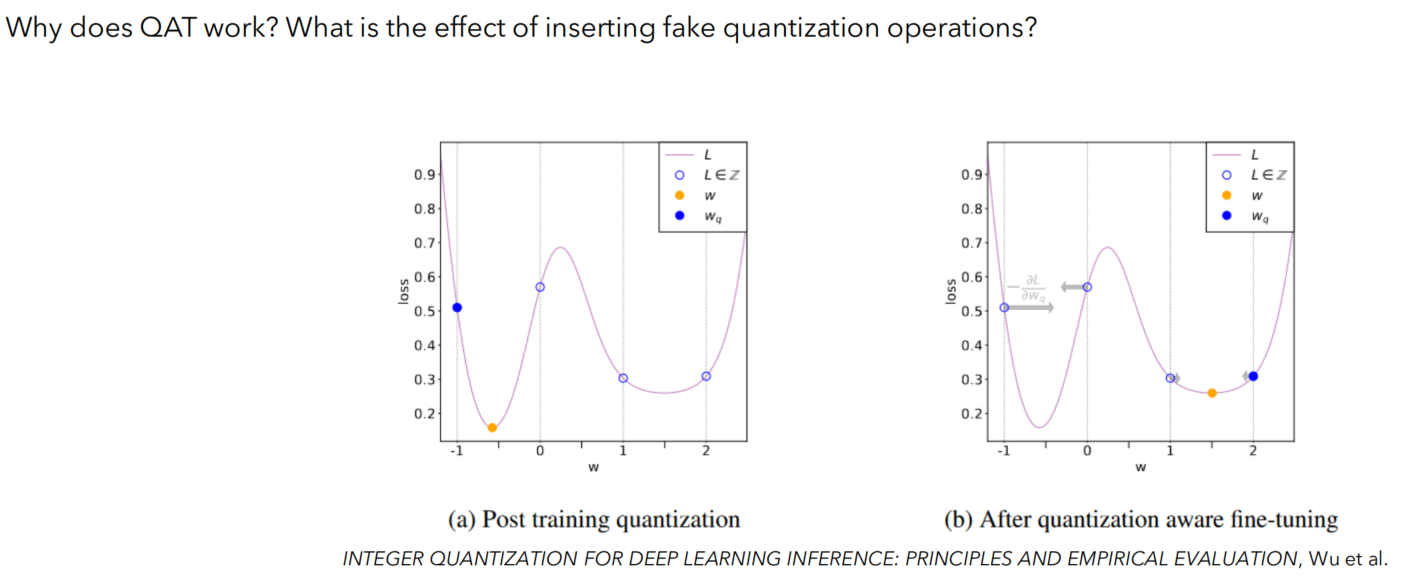
损失函数平滑:插入伪量化操作后,模型的损失函数会相对于量化后的权重变得更加平滑。如图中(b)所示,相较于(a),经过QAT的模型在量化权重 Wq 的周围有更小的损失变化,这意味着量化的误差对模型性能的影响被减少了。
梯度优化:在反向传播时,伪量化操作允许梯度通过,尽管量化操作实际上是不可微的。这样做使得模型可以根据量化后的梯度信息进行更新,而这种更新反映了量化的影响。
伪量化操作的效果
降低了量化的灵敏度:由于模型权重在训练过程中已经根据量化的影响进行了调整,因此模型对量化操作更加“麻木”,或者说不那么敏感。
提高了量化后的性能:如图(b)所示,通过QAT,量化后的权重 Wq 导致的损失比未经QAT优化的模型(图a)要小。这表明,经过QAT的模型能够更有效地减轻量化带来的性能下降。
梯度调整:QAT期间,梯度更新会考虑到量化误差,从而使模型在训练阶段就对量化误差产生适应性,这有助于在实际应用量化时减少精度损失。



















 3268
3268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











