










模型量化是一种减少深度学习模型大小和提高推理速度的技术,通过降低模型参数的精度(例如,从32位浮点数减少到8位整数)来实现。
量化三个好处:
- 更少的内存消耗(对于智能手机等端侧设备很重要)
- 更少的推断时间,因为数据类型更简单。
- 更少的能量消耗,因为推断需要更少的计算。
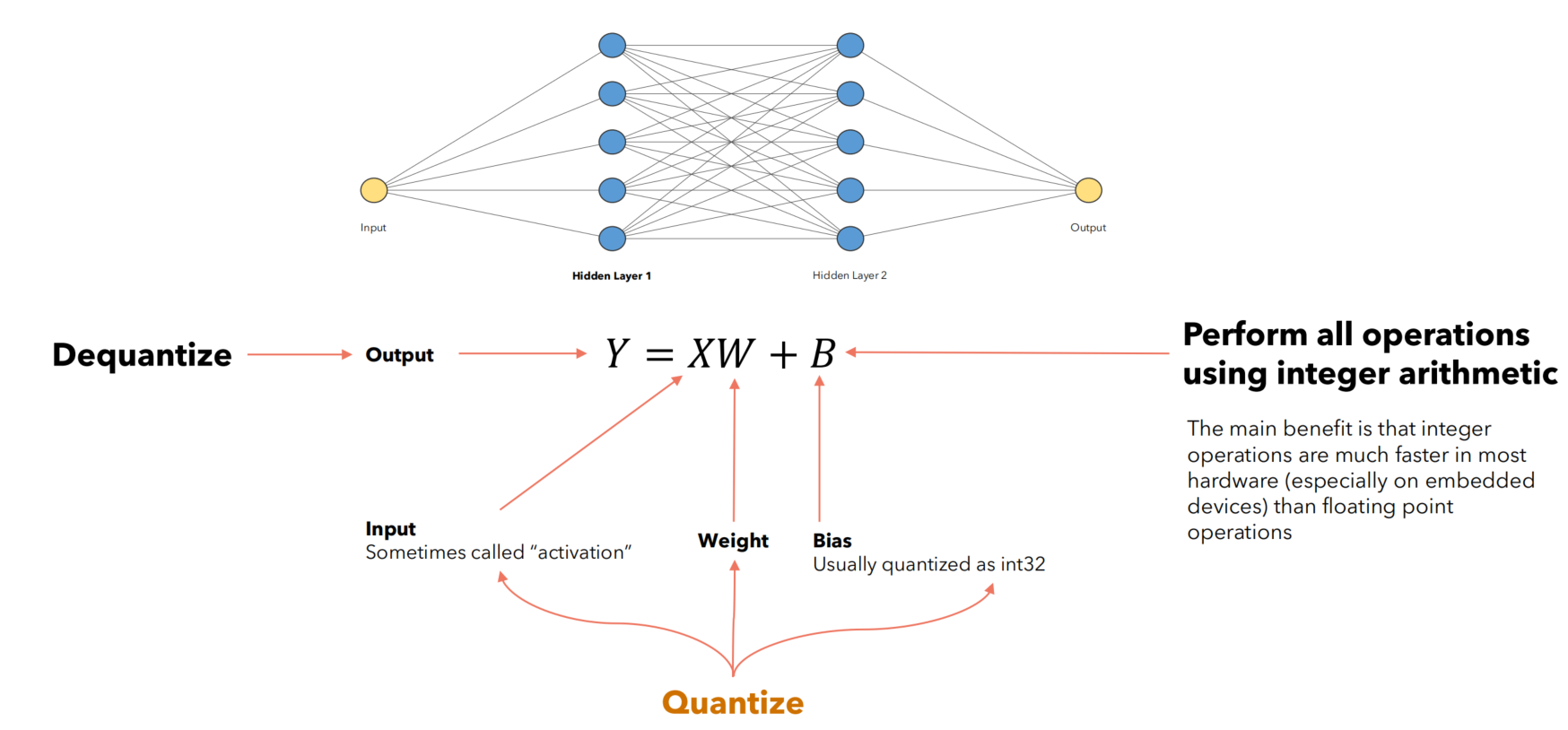
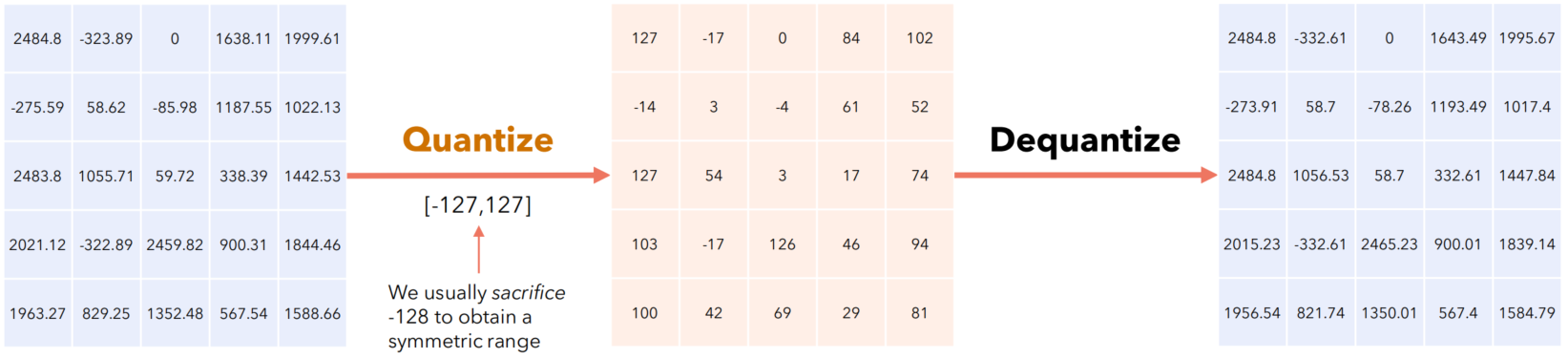
(题外话:反量化操作是为了让量化后的神经元输出与量化前的输出变化不大,不然整型变换后相乘的参数值会与原本的浮点值差很多,对于后面的神经元来说输入相当于就变了,模型准确率自然大打折扣,所以激活值需要经过反量化,从而使得后面的神经元察觉不到输入发生变化,对于整个神经网络来说,输入什么就输出什么,仿佛没有量化操作参与,精度自然能保持。)
量化可以应用于模型的权重和激活(即中间输出值)上。在量化方法中,非对称量化和对称量化是两种常见的量化策略,它们各有特点和应用场景。白话说就是对称量化时0点对齐。
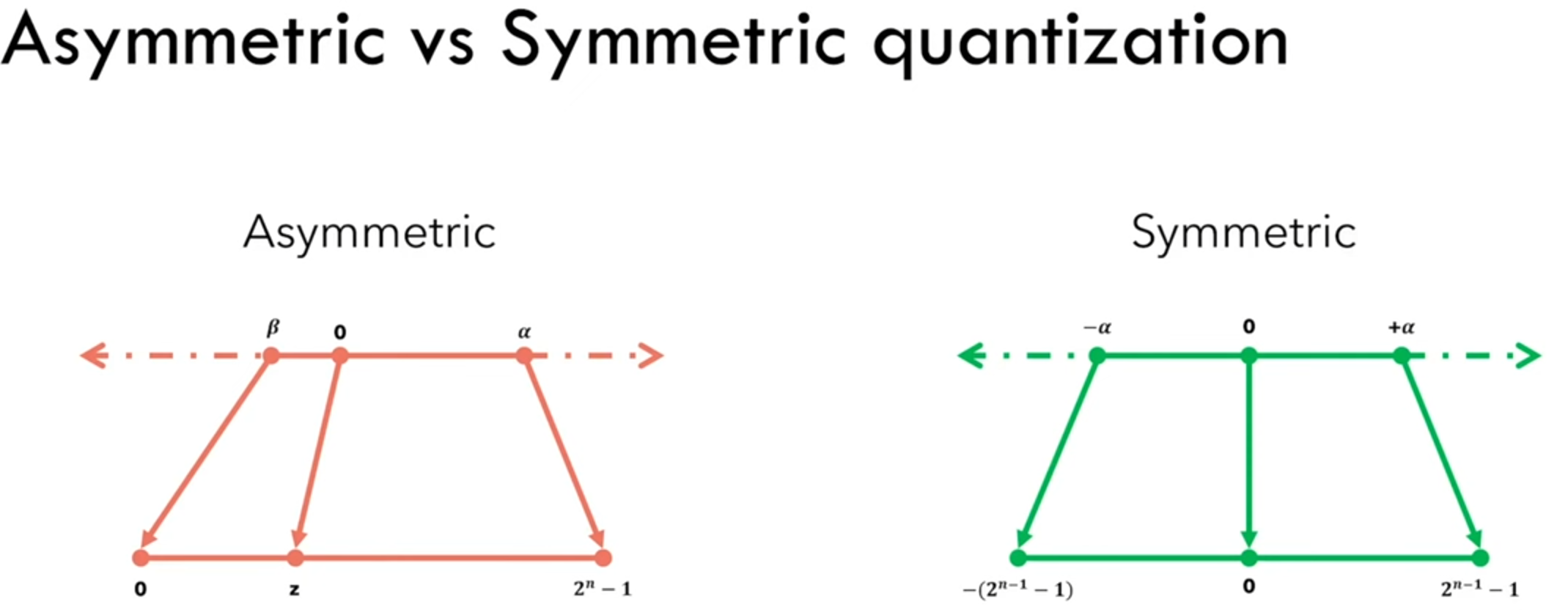
贴上一个自己总结的笔记,看完本文回过头来看这个会很清晰。

具体的模型量化方法分为
post-training quantization(训练后量化)和quantization-aware training(量化感知训练),在之后的博客中详细讨论,本文先打好量化的基础。
非对称量化
非对称量化不要求量化后的值中零点对应于原始值中的零。这意味着量化操作可以有一个任意的零点,这个零点被映射到量化范围内的某个整数值上。因此,非对称量化使用三个参数(量化最小值、量化最大值和零点)来定义从原始数值到量化数值的映射关系。

缺点是执行量化和反量化操作可能需要更多的计算。
对称量化
对称量化要求量化后的值中零点必须对应于原始值中的零,这意味着量化操作的零点固定不变。因此,对称量化通常使用两个参数(量化的最小值和最大值)来定义量化的范围,而这个范围是以零为中心对称的。

缺点是很少有参数矩阵是很对称的,无法像非对称量化那样精确地表示数据范围,导致量化误差增加。
Python全代码
#1. Create a simple tensor with random items
import numpy as np
# Suppress scientific notation
np.set_printoptions(suppress=True)
# Generate randomly distributed parameters
params = np.random.uniform(low=-50, high=150, size=20)
# Make sure important values are at the beginning for better debugging
params[0] = params.max()
params[1] = params.min()
params[2] = 0
# Round each number to the second decimal place
params = np.round(params, 2)
# Print the parameters
print(params)
#2. Define the quantization methods and quantize
def clamp(params_q: np.array, lower_bound: int, upper_bound: int) -> np.array:
params_q[params_q < lower_bound] = lower_bound
params_q[params_q > upper_bound] = upper_bound
return params_q
def asymmetric_quantization(params: np.array, bits: int) -> tuple[np.array, float, int]:
# Calculate the scale and zero point
alpha = np.max(params)
beta = np.min(params)
scale = (alpha - beta) / (2**bits-1)
zero = -1*np.round(beta / scale)
lower_bound, upper_bound = 0, 2**bits-1
# Quantize the parameters
quantized = clamp(np.round(params / scale + zero), lower_bound, upper_bound).astype(np.int32)
return quantized, scale, zero
def asymmetric_dequantize(params_q: np.array, scale: float, zero: int) -> np.array:
return (params_q - zero) * scale
def symmetric_dequantize(params_q: np.array, scale: float) -> np.array:
return params_q * scale
def symmetric_quantization(params: np.array, bits: int) -> tuple[np.array, float]:
# Calculate the scale
alpha = np.max(np.abs(params))
scale = alpha / (2**(bits-1)-1)
lower_bound = -2**(bits-1)
upper_bound = 2**(bits-1)-1
# Quantize the parameters
quantized = clamp(np.round(params / scale), lower_bound, upper_bound).astype(np.int32)
return quantized, scale
def quantization_error(params: np.array, params_q: np.array):
# calculate the MSE
return np.mean((params - params_q)**2)
(asymmetric_q, asymmetric_scale, asymmetric_zero) = asymmetric_quantization(params, 8)
(symmetric_q, symmetric_scale) = symmetric_quantization(params, 8)
print(f'Original:')
print(np.round(params, 2))
print('')
print(f'Asymmetric scale: {asymmetric_scale}, zero: {asymmetric_zero}')
print(asymmetric_q)
print('')
print(f'Symmetric scale: {symmetric_scale}')
print(symmetric_q)
#2.1 Dequantize the parameters back to 32 bits
params_deq_asymmetric = asymmetric_dequantize(asymmetric_q, asymmetric_scale, asymmetric_zero)
params_deq_symmetric = symmetric_dequantize(symmetric_q, symmetric_scale)
print(f'Original:')
print(np.round(params, 2))
print('')
print(f'Dequantize Asymmetric:')
print(np.round(params_deq_asymmetric,2))
print('')
print(f'Dequantize Symmetric:')
print(np.round(params_deq_symmetric, 2))
#2.2 Calculate the quantization error
print(f'{"Asymmetric error: ":>20}{np.round(quantization_error(params, params_deq_asymmetric), 2)}')
print(f'{"Symmetric error: ":>20}{np.round(quantization_error(params, params_deq_symmetric), 2)}')
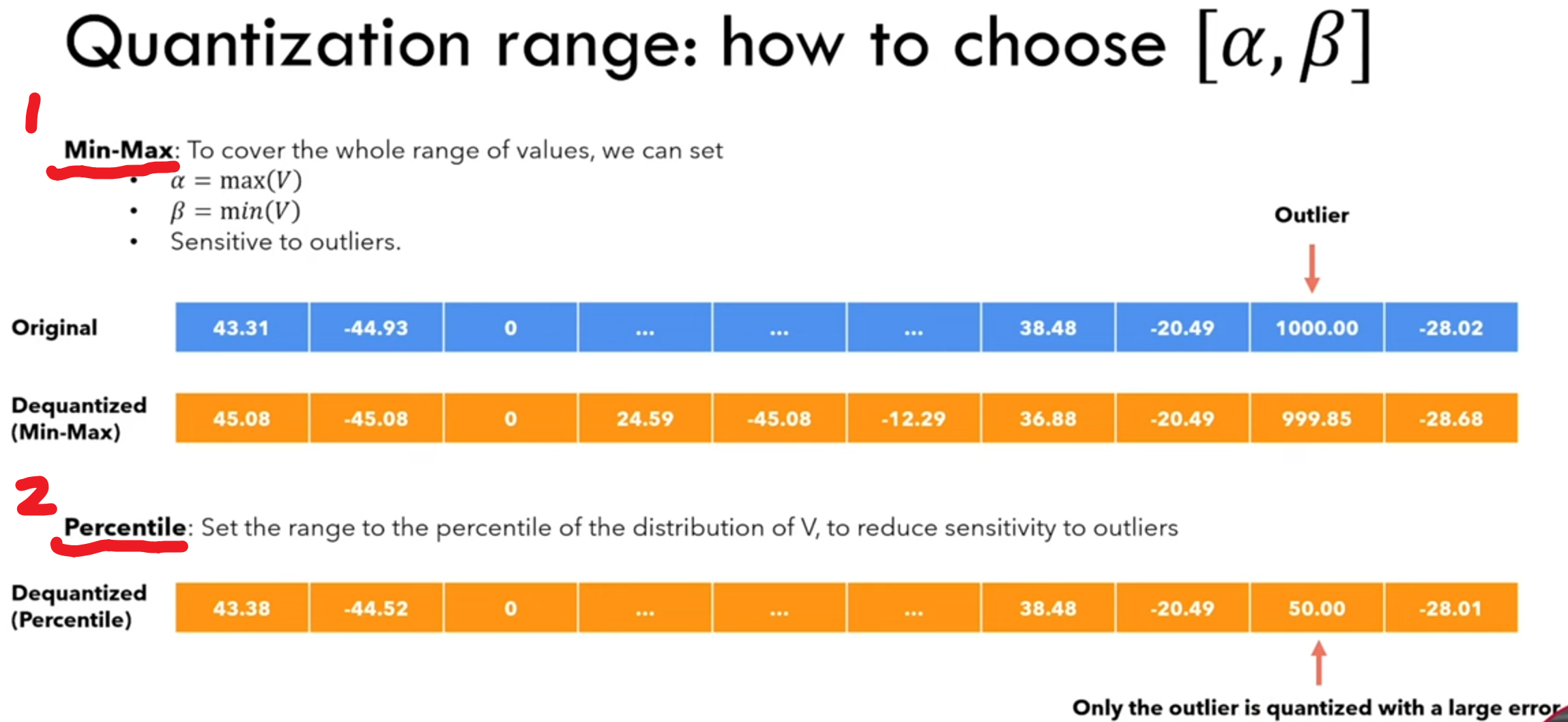
如何选 𝛼, β
Min-Max很简单不谈了,就取列表中的最大和最小值当作 𝛼, β,确实是如果出现outlier,量化误差就很大。
Percentile为了规避outlier的影响,选择列表比绝大部分数据都大的数为𝛼,但这个比例不是100%哦,不然过滤不掉outlier,可以选99%或99.9%。
np.percentile是NumPy库中的一个函数,用于计算给定数据集在指定百分位数下的值。百分位数是一种统计度量,表示在一个数据集中,有多少比例的数据点小于或等于这个值。
下面用代码对比两种方式:
#1. Create a simple tensor with random items
import numpy as np
# Suppress scientific notation
np.set_printoptions(suppress=True)
# Generate randomly distributed parameters
params = np.random.uniform(low=-50, high=150, size=10000)
# Introduce an outlier
params[-1] = 1000
# Round each number to the second decimal place
params = np.round(params, 2)
# Print the parameters
print(params)
#2. Define the quantization methods and quantize
#2.1 Compare min-max and percentile range selection strategies
def clamp(params_q: np.array, lower_bound: int, upper_bound: int) -> np.array:
params_q[params_q < lower_bound] = lower_bound
params_q[params_q > upper_bound] = upper_bound
return params_q
def asymmetric_quantization(params: np.array, bits: int) -> tuple[np.array, float, int]:
alpha = np.max(params)
beta = np.min(params)
scale = (alpha - beta) / (2**bits-1)
zero = -1*np.round(beta / scale)
lower_bound, upper_bound = 0, 2**bits-1
quantized = clamp(np.round(params / scale + zero), lower_bound, upper_bound).astype(np.int32)
return quantized, scale, zero
def asymmetric_quantization_percentile(params: np.array, bits: int, percentile: float = 99.99) -> tuple[np.array, float, int]:
# find the percentile value
alpha = np.percentile(params, percentile)
beta = np.percentile(params, 100-percentile)
scale = (alpha - beta) / (2**bits-1)
zero = -1*np.round(beta / scale)
lower_bound, upper_bound = 0, 2**bits-1
quantized = clamp(np.round(params / scale + zero), lower_bound, upper_bound).astype(np.int32)
return quantized, scale, zero
def asymmetric_dequantize(params_q: np.array, scale: float, zero: int) -> np.array:
return (params_q - zero) * scale
def quantization_error(params: np.array, params_q: np.array):
# calculate the MSE
return np.mean((params - params_q)**2)
(asymmetric_q, asymmetric_scale, asymmetric_zero) = asymmetric_quantization(params, 8)
(asymmetric_q_percentile, asymmetric_scale_percentile, asymmetric_zero_percentile) = asymmetric_quantization_percentile(params, 8)
print(f'Original:')
print(np.round(params, 2))
print('')
print(f'Asymmetric (min-max) scale: {asymmetric_scale}, zero: {asymmetric_zero}')
print(asymmetric_q)
print(f'')
print(f'Asymmetric (percentile) scale: {asymmetric_scale_percentile}, zero: {asymmetric_zero_percentile}')
print(asymmetric_q_percentile)
#2.2 Dequantize the parameters back to 32 bits
params_deq_asymmetric = asymmetric_dequantize(asymmetric_q, asymmetric_scale, asymmetric_zero)
params_deq_asymmetric_percentile = asymmetric_dequantize(asymmetric_q_percentile, asymmetric_scale_percentile, asymmetric_zero_percentile)
print(f'Original:')
print(np.round(params, 2))
print('')
print(f'Dequantized (min-max):')
print(np.round(params_deq_asymmetric,2))
print('')
print(f'Dequantized (percentile):')
print(np.round(params_deq_asymmetric_percentile,2))
#3. Evaluate the quantization error (excluding the outlier)
# Calculate the quantization error
print(f'{"Error (min-max) excluding outlier: ":>40}{np.round(quantization_error(params[:-1], params_deq_asymmetric[:-1]),2)}')
print(f'{"Error (percentile) excluding outlier: ":>40}{np.round(quantization_error(params[:-1], params_deq_asymmetric_percentile[:-1]),2)}')
浮点数存储格式(IEEE-754)
题外话,浮点数的存储格式




















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











