







第三章. Pandas入门
3.7 数据清洗
1. 缺失值:指的是由于某种原因导致数据为空,这种情况一般有四种处理方式:
1).不处理
2).删除
3).填充或者替换
4).差值:均值、中位数、众数等填补
1).查看缺失值的方式:
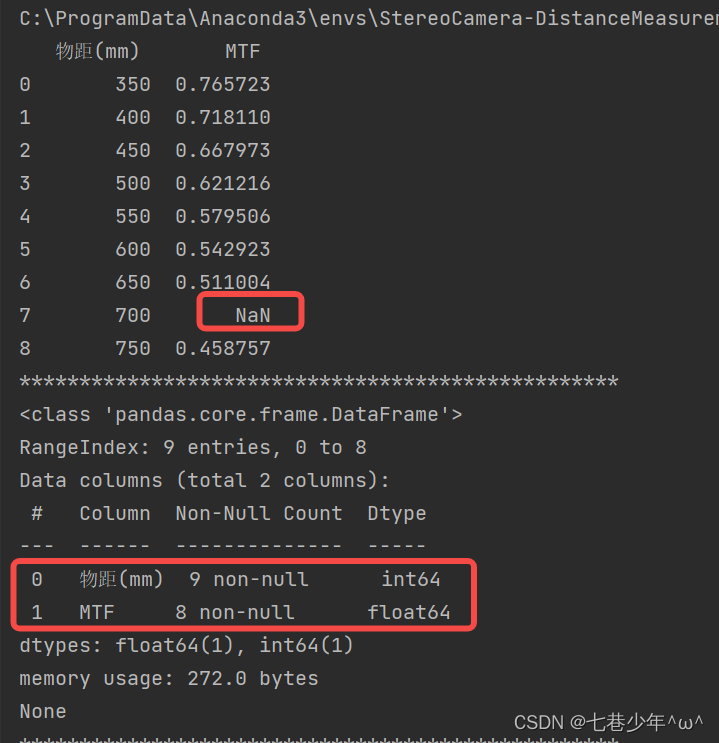
使用DataFrame对象中的info属性
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#查看缺失值
print(df.info())
print('*' * 50)
结果展示:
2).判断数据是否存在缺失值的方法:
使用DataFrame对象中的isnull和notnull方法
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#判断数据是否存在缺失值
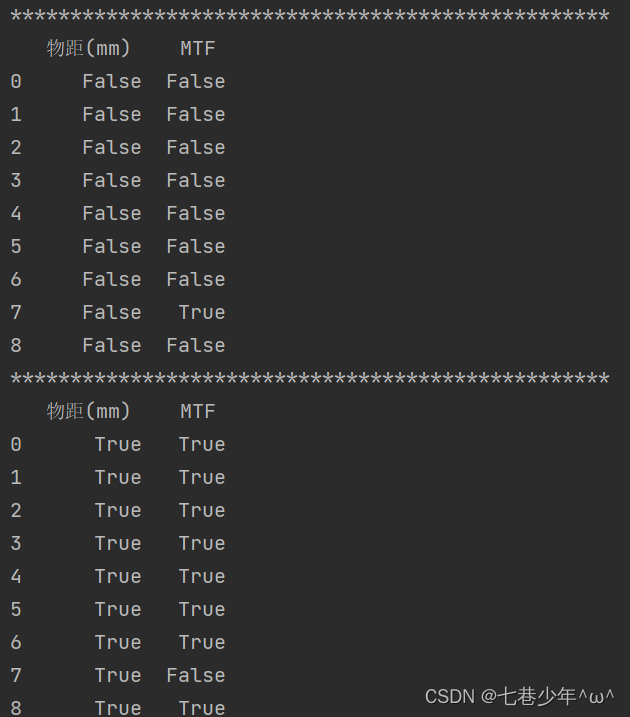
print(df.isnull())
print('*' * 50)
print(df.notnull())
结果展示:
2. 删除缺失值的方法:
1).删除含有缺失值的行:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#删除含有缺失值的行
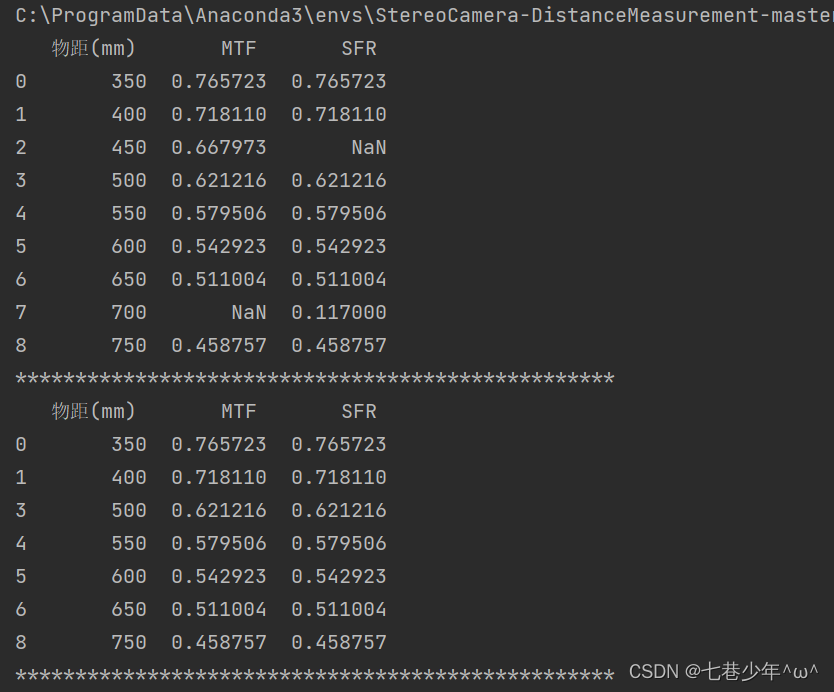
df1=df.dropna(inplace=False);
print(df1)
print('*' * 50)
结果展示:
2).删除指定列名的缺失值的方法:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#删除指定列名的缺失值的方法
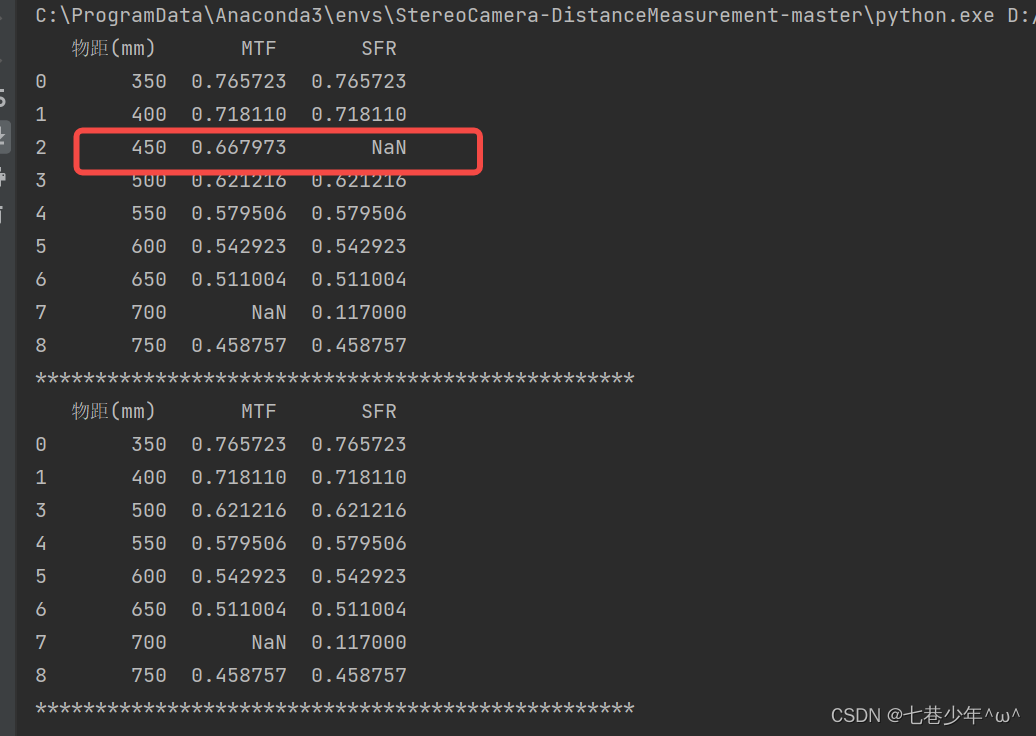
df2=df[df['SFR'].notnull()]
print(df2)
print('*' * 50)
结果展示:
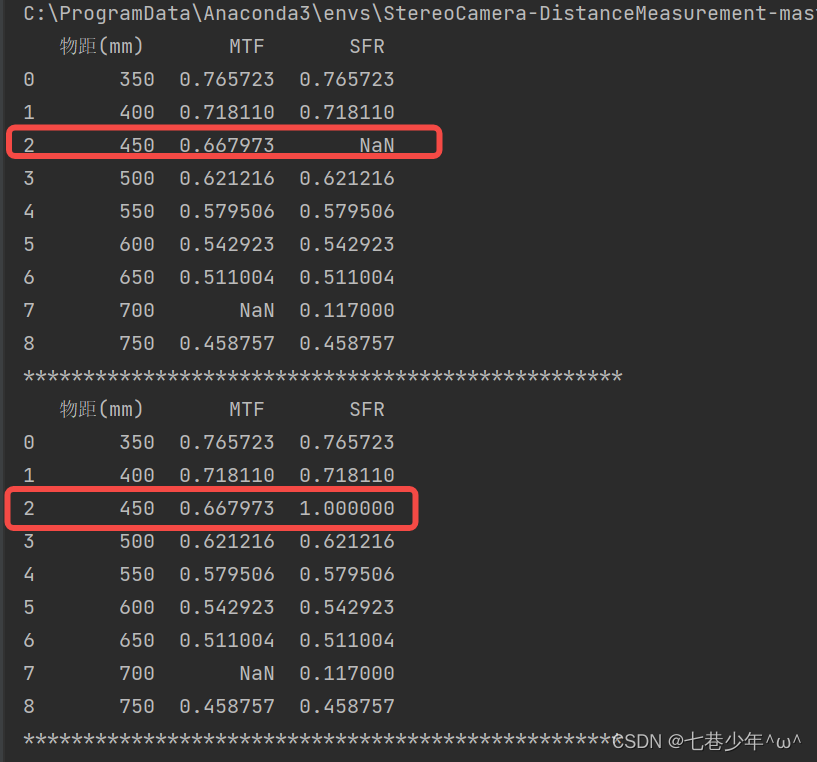
3).缺失值的填充处理:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#缺失值的填充处理
df['SFR']=df['SFR'].fillna(1)
print(df)
print('*' * 50)
结果展示:
3.重复值处理:
主要使用DataFrame对象中的drop_duplicates方法,语法如下:
DataFrame.drop_duplicates(
self,
subset: Hashable | Sequence[Hashable] | None = None,
keep: Literal["first"] | Literal["last"] | Literal[False] = "first",
inplace: bool = False,
ignore_index: bool = False,
)
参数说明:
subset:列标签,可选
subset:first: 保留第一次出现的重复行。last: 保留最后一次出现的重复行。False: 删除所有重复行,默认值为first
inplace:是否删除重复项或返回副本
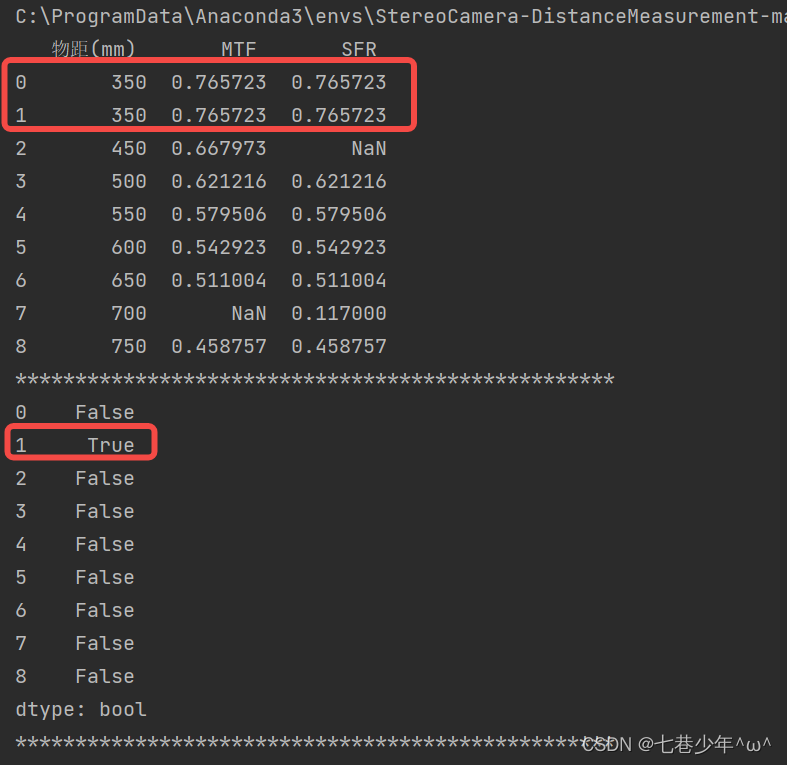
1).判断某行与某行数据是否重复,重复置为True,使用duplicated函数:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#判断某行与某行数据是否重复,重复置为True
df1=df.duplicated()
print(df1)
print('*' * 50)
结果展示:
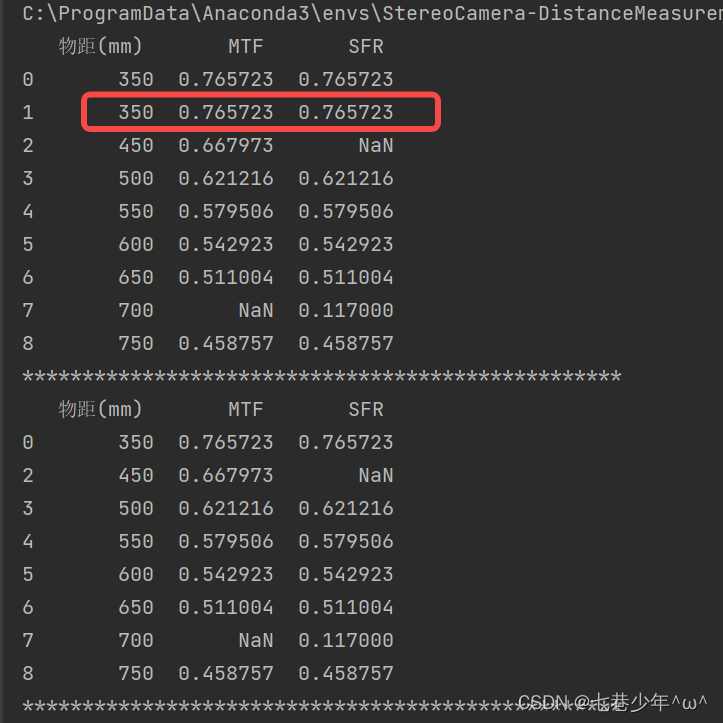
2).去除全部的重复数据,使用drop_duplicates函数:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df=pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#去除全部的重复数据
df1=df.drop_duplicates()
print(df1)
print('*' * 50)
结果展示:
3).保留重复行的哪行数据,使用drop_duplicates函数:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
# 去除指定列的重复数据
df1 = df.drop_duplicates(['SFR'], keep='first')//keep='last'
print(df1)
print('*' * 50)
结果展示:















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









