







第三章. Pandas入门
3.9 数据排序与排名
1.DataFrame数据排序时主要使用sort_values:
DataFrame.sort_values(by,axis=0,ascending=True,inplace=False,kind='quicksort',na_position='last',ignore_index=False)
参数说明:
by:要排序的名称列表
axis:轴,0:行 1:列,默认值:0
ascending:升序还是降序排列
inplace:是否就地排序
kind:指定排序算法,quicksort:快速排序 ;mergesort:混合排序;heapsort:堆排,默认值quicksort
na_position:空值的位置:first:空值在数据开头 last:空值在数据最后,默认值:last
ignore_index:是否忽略索引
2. 按列数据排序:
1).一列:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
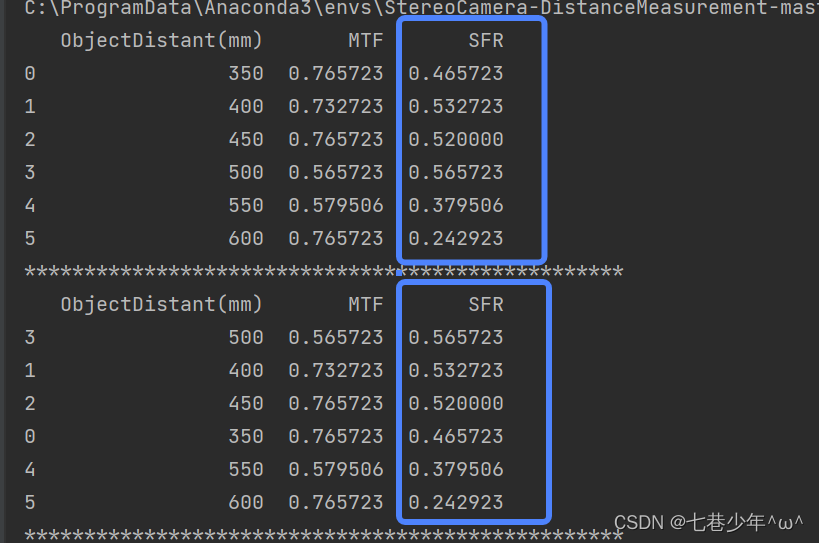
#按一列进行排序
df1 = df.sort_values(by='SFR', ascending=False)
print(df1)
print('*' * 50)
结果展示:
2).多列:
多行排序是按照给定列的前后顺序进行排序,后一次的排序是在前一次重复数据的基础上进行排序的
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
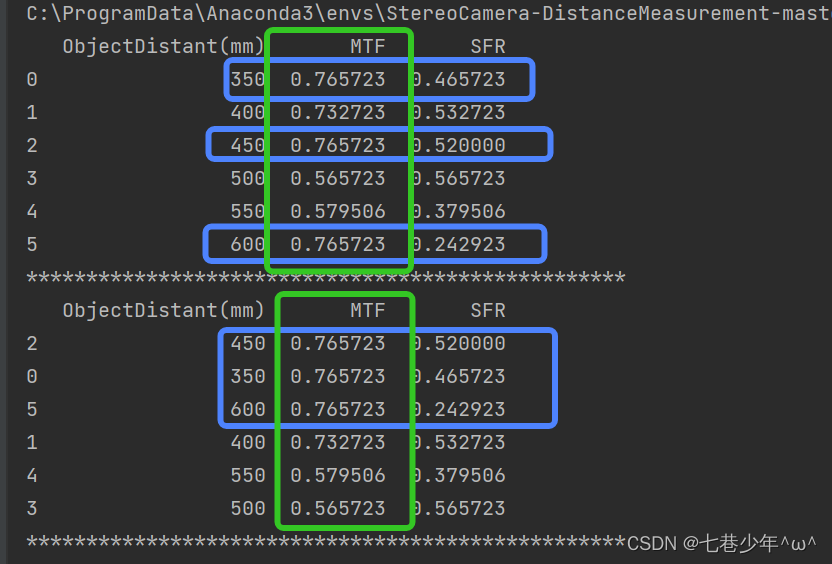
#按多列进行排序
df2 = df.sort_values(by=['MTF', 'SFR'], ascending=[False, False])
print(df2)
print('*' * 50)
结果展示:
3).对统计结果排序:
统计结果排序是把不同类型的进行分组,然后在按照类别进行排序
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
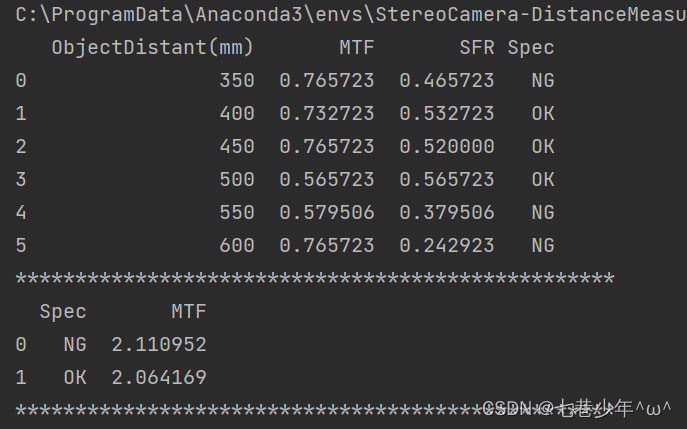
#对分组统计数据进行排序
df1=df.groupby(['Spec'])['MTF'].sum().reset_index()
df2 = df1.sort_values(by='MTF', ascending=False)
print(df2)
print('*' * 50)
结果展示:
3.按行数据排序:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
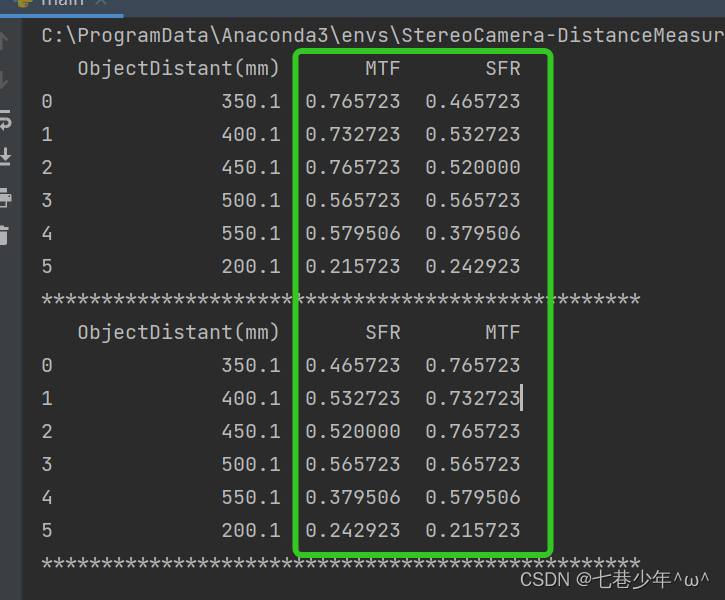
#对行进行排序
df2 = df.sort_values(by=5, ascending=False,axis=1)
print(df2)
print('*' * 50)
结果展示:
4.数据排名:
1).设某列为行索引:
排名主要是根据Series或DataFrame对象的某几列的值进行排名,主要使用rank方法,语法如下:
DataFrame.rank(axis=0, method=’average’, numeric_only=None, na_option=’keep’, ascending=True, pct=False)
参数说明:
axis:轴,0:行,1:列
method:表示在具有相同值得情况下所使用的方法:
| 关键字 | 含义 |
|---|---|
| average | 平均排名(默认值) |
| min | 最小值 |
| max | 最大值 |
| first | 按值在原始数据中出现的顺序分配排名 |
| dense | 类似于最小值排名,但是排名每次只增加一,即排名相同的名词只占一个名次 |
numeric_only:Ture:只对数字列进行排序
na_option:空值的排序方式 keep:保留;top:若是升序排序,将最小排名赋值给NaN;bottom:若是升序排序,将最大排名赋值给NaN
ascending:升序还是降序排序,默认升序
pct:是否以百分比的形式返回排名,默认False
2).顺序排名:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
df2 = df.sort_values(by='MTF', ascending=False)
#对MTF进行排名
df2['Num'] = df2['MTF'].rank(method="first", ascending=False)
print(df2[['MTF', 'Num']])
print('*' * 50)
#平均排名
df2['Num'] = df2['MTF'].rank(method="average", ascending=False)#method=max,min
print(df2[['MTF', 'Num']])
print('*' * 50)
结果展示: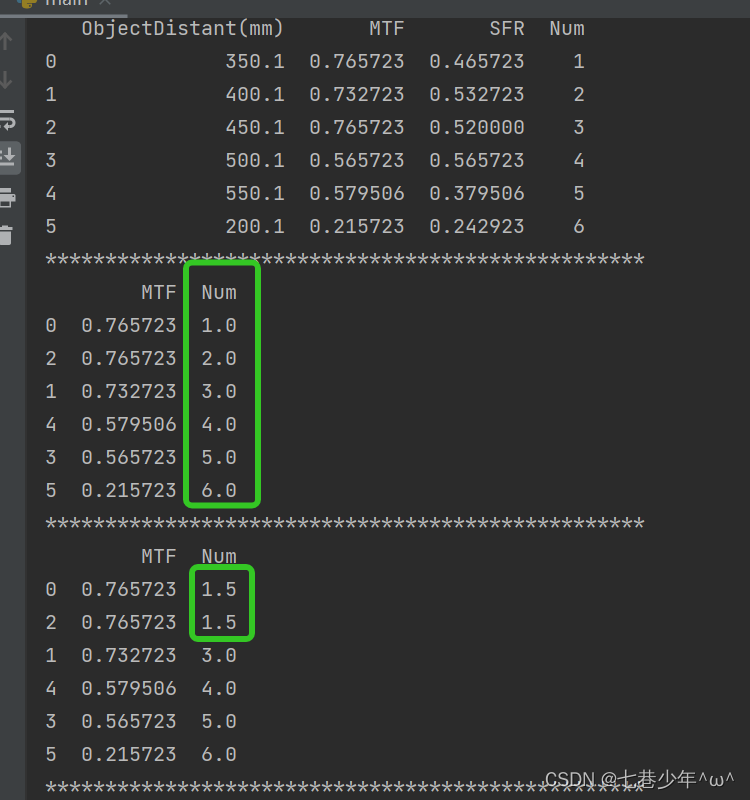















 1830
1830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









