








就像一个小学生不做作业,然后被爸爸打了,然后小学生就知道做作业了,因为赌博还没有被爸爸打,所以小学生以为赌博是对的,就去赌博,然后又被爸爸打了,小学生才知道不能赌博

无监督模型后面没有label(是否招女孩子喜欢)

对于监督学习而言呢,从数学形式来讲,主要分两种,我们首先看一下训练集呢,我一般是这样表述的,这个T就代表训练集去圈你。training data, x1就表示这条样本,y就表示是否招女孩子喜欢,比如说这个x(x(1),x(2)…)就是我们之前的体重,身高,年龄
对于每一个x呢,它其实是有很多维度的,它是一个向量,比如说刚才的体重,那么x1可能就是这个体重x2呢,表示成绩,xn呢表示这个呃长得好看不好看,那么一一个样本有很多的维度去表示这个数据到底是一个什么样子的数据
统计学习三要素

我们可以想象这么一件事情在我们生活当中,我们的空间是三维是吧?那么在空间当中的每一个坐标呢?都代表着空间当中的一个点。啊,那么假设空间也是这样子,你可以把这个假设空间想象成你生活当中的一个三维空间,那么它是这个整个空间里头的每一个点。它每一个点呢,就是一个假设,就是一个模型,所有的这个模型啊,就是所有的这个函数,都在这个空间当中。你就好像把世界上所有的函数全都塞到了一个箱子里头,那么这个箱子它就叫一个假设空间,它的内部每个点都有一个函数一个模型,也就是说你从小到大见过的没见过所有函数都可以在这个空假设空间当中找到,只是说我们。假设有这么一个地方,就叫假设空间
要用的函数是哪个函数由setae决定

假设空间有这么大啊,咱们怎么去确定setae参数呢?
我们可以用损失函数来定义它,其实整体的流程是这样子的,模型一开始什么也不会。我们输进去它里头所有的参数都是随机的,那么我们。数据输进去以后呢,它很可能会给我们一些错误的答案,是不是就像小孩一样,他就是不懂,他就瞎猜一些答案啊,那么我们要告诉他正确答案,同时要去比较,就是说让他这个和错误的答案进行一个比较啊,他当前的这个错误的答案和我们正确答案差距还有多少,也就是首先第一我们要告诉模型,他当前预测错了。第二个,我们要告诉他,他预测错的偏差有多大,那么他要去弥补这个差距,那么就是这个差距,怎么去量化呢啊?我们用损失函数L就是loss,就是损失函数。
介绍一下01损失函数,就是说只要你输出fx的预测和我真实的标签y,是不相等的,我就返回一个1。相等的我就返回一个0,1就告诉你错了,0就是对的,就是你和这个真实的数据还有差距,你要继续努力,我返回你一个零,就告诉你,你这里做的很对了,不用努力了,它只能输出0和1,它并不能告诉你距离真实目标差距还有多大,就好像大家小的时候啊,做作业老师告诉你错了,他不告诉你错哪了,让你自己猜
那么,平方损失函数和绝对值函数呢?就弥补了这样一个问题
对数损失函数的好处,目前暂不明朗,后面深入学习再探究

那么我们现在这个评估模型距离我们这个真实的标签差距有多大了呢?那么怎么把这个东西用起来呢?我们有两种方式,第一个呢,就是经验风险最小化。就是整个训练集当中,我对于每个样本呢都去跑一遍,对于每一个样本都去求一个loss,就用这个loss,去做一个平均值。那么,我这个值越大的话,我这个模型啊,离我真实的这个要拟合的这个东西,它差距还比较远。如果它真题比较小的话,那就说明我这个模型,还是挺符合我这个数据的真实的一个分布情况
结构风险最小化,它其实是加了一个正则项。可以看到,前面都是一样的,后面加了一个正则项lambda,然后这个是一个正则项。它是为了防止过拟合的啊,它为了防止这个模型啊,在训练过程当中变得过于的复杂
三元素最后一个是算法,挑选一个合适的算法。每一个算法呢,它都有不同的优势,也有不同的缺陷啊,选一个合适的算法去做这件事情,那么得到模型一定会效果好一点
两个误差和三个集合

比如说你跑了好几个模型,你怎么知道哪个模型更好呢?是不是首先第一我们可以对这个训练集的每个样本,它的误差去做一个平均,平均误差比较高的,那么说明这个模型在训练集上效果不是很好,那么它可能会比较差,但是也有个问题啊。就是你们的模型就是用训练集去训练,就好像我们期末考试一样,我们考试肯定见到的都是一些新的题,老师新出的题才能判断我们成绩怎么样.
你考你期末考试不能拿平时的课后测验题去当这个期末考试题,那我在平时的时候就已经见过这种题了,原题我当然会做了,这个时候我们还会去划分一个测试集出来,这个测试集呢,在训练的时候是不用的。
比如说100个数据,那么训练集里头我们分80个进去测,那么我们用这些数据,就去让模型去拟合一个模型出来。这个模型训完了以后,我们平时的课后题都做完了,那么接下来,就拿测试集20个,拿这些新的数据再去跑一下。新的题目进来,我们去看一下能不能做得好,如果做得好啊,那说明我们才真的会了是吧,那就期末考试,新的题目也都会做了,那那肯定牛逼呀是吧,考了100分。所以说,这个误差,在测试集上的误差就叫这个测试误差啊。我们一般模型评估,都是在测试误差上面去评估的
那么验证集的作用呢?
验证集其实是一个中间的步骤。我们只用训练集和测试集的时候会有一个问题,就是我们训练集训练完了,比方说我们训练了十个模型出来,或者说一个模型在训练当中,有迭代这个概念,要迭代多少轮。那我们也可能要看哪一轮的效果会更好一点,那么最后我们怎么去挑选好的这个模型呢?就是哪个模型在测试集上效果最好,我们就用它,那这就有个问题,这个测试集的样本啊。哎,正好是某个模型,他擅长的东西,那别的数据他就不会了,他就会这20个,它在别的数据上效果并不好.训练完数据以后,我们在验证集上去验证,我们通过验证集,去选取一个最高的,或者说一个最好的模型出来。那么这个时候,我们通过验证机选取了一个最优的模型,这个时候呢,我们再用再去测试机上跑。去跑一个分数出来,那么这个分数,就是我们用来和其他模型做比较的分数,如下图

在训练集上面分数肯定是不断增加的,然后dev验证集在75以后降低了,就是过拟合了,所以我们选择dev里面分数最高的75,然后用测试集去测试,得到一个分数,就是这个模型和其他模型比较的分数
多项式拟合

M值越大,这个模型更复杂了,它能力更高了,那么它很有可能会去拟合出一些乱七八糟的东西出来,因为它想抓住一切,哪怕这个数据是个噪音,它都想抓住,然后就过拟合了,模型在训练集上面误差很小,但是在测试集或者其他数据上面的误差很大

正则化
后面那个lambda是正则项, J(f)是正则函数,它就是说用来约束这个函数的参数不能多,比方说100个参数,那么我要求30个参数一定要是零。那么我最后这个模型其实只有70个参数,它就不是100个了,强制性的减少这个模型的复杂度,正则项是为了减少模型的复杂度,是为了防止过拟合
交叉验证
s交叉验证,比方说我这个训练训练集选80,比如说100个选80,我这次选这80个数据。下一次我再选那80个数据,我选个十次,这样我用十个80个数据,就可以训十个模型出来,,那么这个训练集呢,就是剩下的这个子集对应的再去做测试,这样子呢,再选出一个最好的模型出来
泛化误差上界

这个可以一定程度证明模型的合理性
但是这个很有局限性,因为必须是有限个函数的集合,我们后面也不会用到,因为有限个是个强假设
泛化误差其实就是期望误差,经验误差是训练误差
推导过程如下

最后结果表明,训练集小,其他的按理说也小
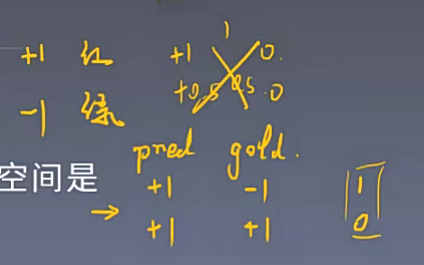
我们模型要判断一颗豆子,它是一个红豆还是一个绿豆,如果是红豆,模型就输出正一。如果是绿豆。模型就输出负一,那么通过这样子的方式,去构建一个二分类器,也就是说这个模型去预测这个豆子到底红豆还是绿豆,预测对了就是0,预测错了就是1

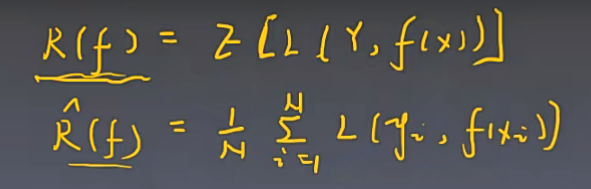
生成模型和判别模型

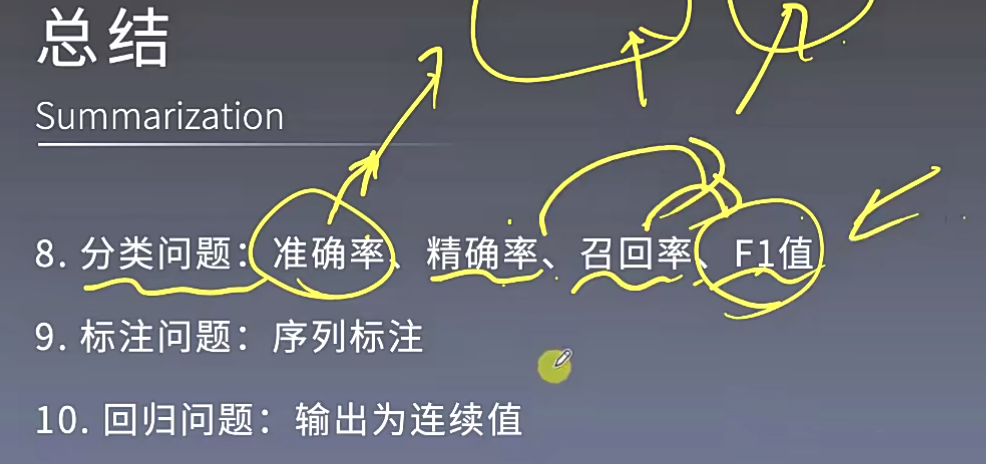
分类问题

关键看看精确率和召回率的计算

标注问题

回归问题

我要预测气温为276度呢啊278度,这个问题分类模型是没有办法解决的,回归问题可以去输出一个精确的值。带小数点都可以
总结

















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









