






一、信息熵
猜谁是冠军?假设有32支球队
如果:不知道任何⼀个球队的信息的话,5bit ,1/32 1/32 ……….
5 = -(1/32log1/32 + 1/32log1/32 + …………)
开放⼀些数据信息 德国 巴⻄ 中国 1/6 1/6 1/10
5 > -(1/6log1/6 + 1/6log1/6 + …………
信息熵:
∑
x
∈
X
P
(
x
)
l
o
g
P
(
x
)
\sum_{x \in X}P(x)logP(x)
∑x∈XP(x)logP(x),信息和消除不确定性相关联,信息熵越大,不确定性越大。
二、决策树
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度.
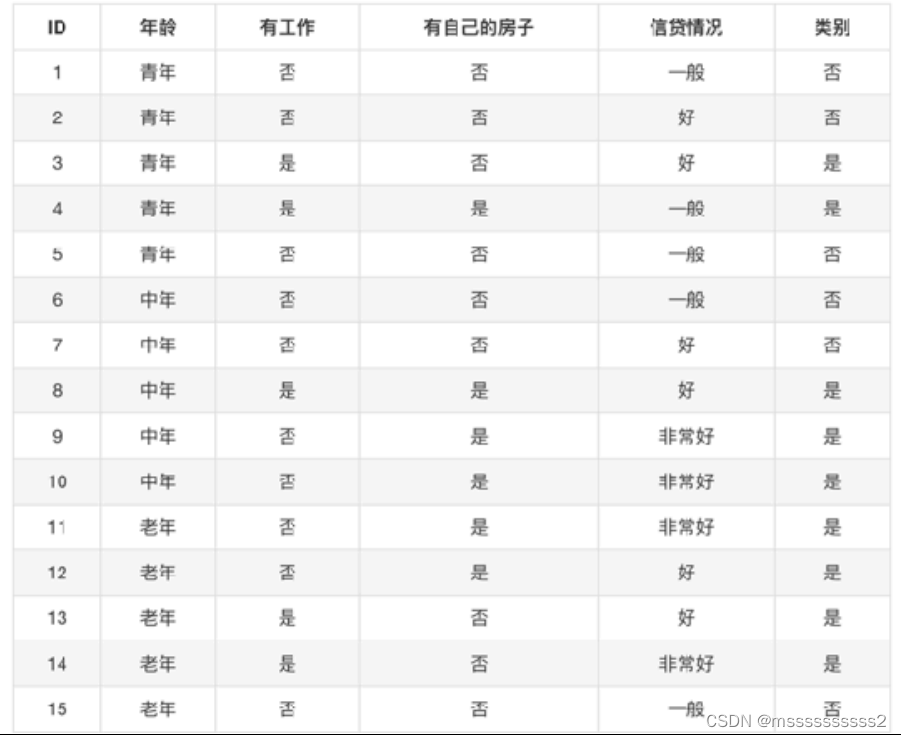
H(D) = -(9/15log9/15 + 6/15log(6/15))
g(D, 年龄) = H(D) - H(D’|年龄) =0.971- [1/3H(⻘年)+1/3H(中年)+1/3H(⽼年)]=
H(⻘年) = -(2/5log(2/5)+ 3/5log(3/5))
H(中年) = -(2/5log(2/5)+ 3/5log(3/5))
H(⽼年) = -(4/5log(4/5)+ 1/5log(1/5))
决策树的分类依据之⼀:信息增益
基尼系数:划分更加仔细
ID3:信息增益 最大的准则
C4.5:信息增益比 最大的准则
CART :
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)默认通过gini系数判断。
优点:易于理解与解释,结果可以可视化;数据准备简单,不需要归一化
缺点:构建过于复杂的树导致过拟合;不稳定,数据的微小变化会导致树的变化
改进:减枝cart算法;随机森林
通过参数min_samples_split(父节点最小样本数),min_samples_leaf(子节点最小样本数)减枝。
三、随机森林
集成学习通过建立模型的组合来解决单一的预测问题,原理是生成多个分类器/模型,每个分类器独立建模和预测,这些预测最后结合成单预测,因此由于单分类做出的预测。
随机森林是一个包含多个决策树的分类器,其输出的类别由个别数输出类别的众数决定。
生成随机森林:N个样本,M个特征
生成一个树的过程
1、有放回的随机抽取N个样本(bootstrap)
2、抽取不重复的m个特征(m<M)
基于上述数据生成决策树,树之间的样本、特征大都不一样
n_estimator决策树的数量
max_depth:每颗树的深度限制
max_features:If “auto”, then max_features=n_features.
If “sqrt”, then max_features=sqrt(n_features).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features
优点:具有极好的准确率;适用于样本量很大的场景;高维度不需要降维;可以容忍缺失值;能够评估各个特征的重要性
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
###读取数据
data=pd.read_csv(r'C:\Users\ms\Desktop\newfile\handson-ml2-master\datasets\titanic\train.csv')
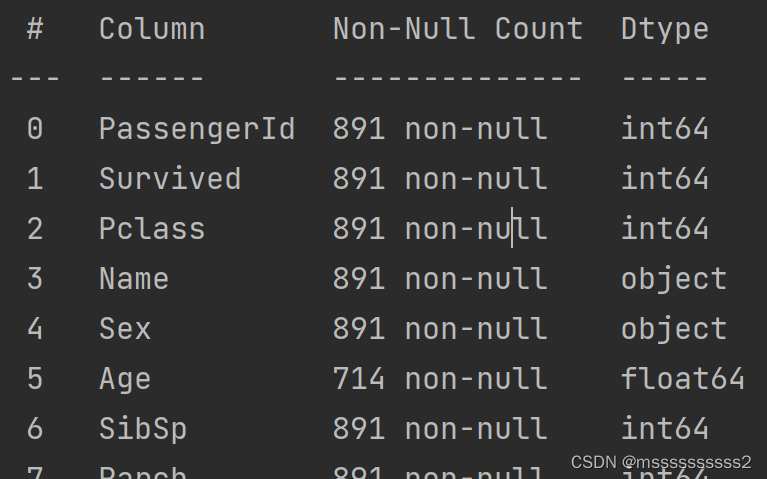
print(data.info())
###处理缺失值
data['Age'].fillna(data['Age'].mean(),inplace=True)
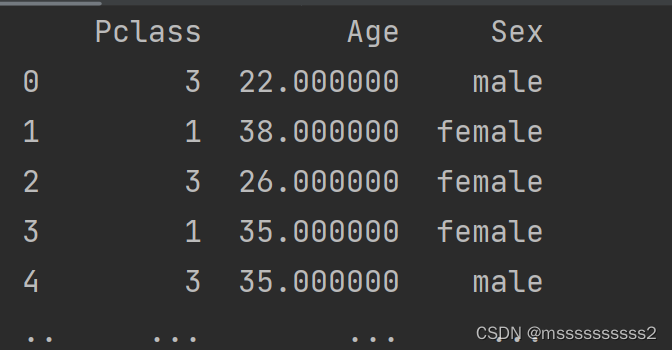
x=data[['Pclass', 'Age', 'Sex']]
x.loc[:,'Pclass']=x['Pclass'].astype('str')
y=data['Survived']
print(x)
###划分训练集测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
###将类别型数据进行onehot编码
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records"))
x_test=dict.transform(x_test.to_dict(orient="records"))
print(dict.get_feature_names_out())
###构建并拟合决策树模型
dec=DecisionTreeClassifier(max_depth=5)
dec.fit(x_train,y_train)
###获取模型准确率
print(dec.score(x_test,y_test))
###导出文件
export_graphviz(dec,out_file="./tree.dot", feature_names=['Age', 'Pclass=1', 'Pclass=2', 'Pclass=3', '男性', '女性'])
##构建并拟合随机森林模型,进行交叉验证
rf=RandomForestClassifier(n_jobs=-1)
param={'n_estimators':[120, 200, 300, 500, 800, 1200],'max_depth':[5, 8, 15, 25, 30]}
gs=GridSearchCV(rf,param_grid=param,cv=2)
gs.fit(x_train,y_train)
###输出准确率
print("准确率:",gs.score(x_test,y_test))
##输出最优模型参数
print("查看选择的参数模型:",gs.best_params_)
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
###读取数据
data=pd.read_csv(r'C:\Users\ms\Desktop\newfile\handson-ml2-master\datasets\titanic\train.csv')
print(data.info())
###处理缺失值
data['Age'].fillna(data['Age'].mean(),inplace=True)
x=data[['Pclass', 'Age', 'Sex']]
x.loc[:,'Pclass']=x['Pclass'].astype('str')
y=data['Survived']
print(x)
###划分训练集测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
###将类别型数据进行onehot编码
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records"))
x_test=dict.transform(x_test.to_dict(orient="records"))
print(dict.get_feature_names_out())

###拟合模型
dec=DecisionTreeClassifier(max_depth=5)
dec.fit(x_train,y_train)
###获取模型准确率
print(dec.score(x_test,y_test))
###导出文件
export_graphviz(dec,out_file="./tree.dot", feature_names=['Age', 'Pclass=1', 'Pclass=2', 'Pclass=3', '男性', '女性'])

##构建并拟合随机森林模型,进行交叉验证
rf=RandomForestClassifier(n_jobs=-1)
param={'n_estimators':[120, 200, 300, 500, 800, 1200],'max_depth':[5, 8, 15, 25, 30]}
gs=GridSearchCV(rf,param_grid=param,cv=2)
gs.fit(x_train,y_train)
###输出准确率
print("准确率:",gs.score(x_test,y_test))
##输出最优模型参数
print("查看选择的参数模型:",gs.best_params_)















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









