







需求分析
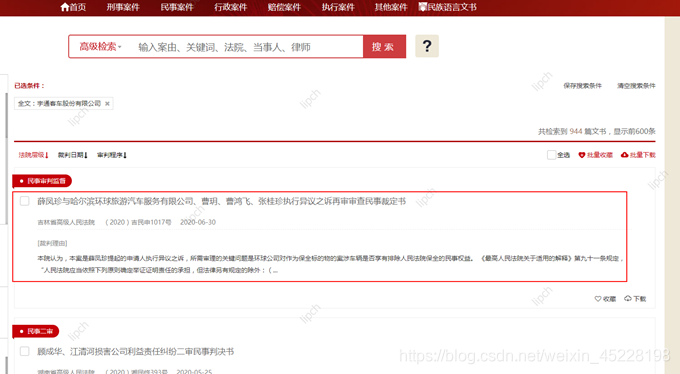
题目:爬取裁判文书网(https://wenshu.court.gov.cn/),
包含“宇通客车股份有限公司”涉及的案号,发布日期,案由,案件名称,链接等信息。
分析思路
快速开发:使用selenium+Chrome+mongodb的解决方案
- 为了能快速拿到数据,选择使用selenium+Chrome来抓数据。
- 打开网站主页,在搜索框输入搜索内容,点击搜索时,提示需登录,所以需注册一个账号,且使用selenium实现账号的登录。
- 登录后,再输入搜索内容“宇通客车股份有限公司”,点击搜索,就会获得服务端的响应数据。分析响应页面中数据内容的结构,发现每页有五个案件,均在类属性为"LM_list"的div元素块中。
- 获取页面中的5个div节点,逐一的解析其中的目标数据。
- 然后模拟人点击“下一页”,浏览器加载到数据后,同样的方法解析页面的数据,直到最后一页。所有解析的数据存入mongodb数据库。
- 爬取过程中,注意给浏览器足够的时间,加载数据,渲染页面,否则selenium无法从浏览器解析元素节点,从而出现异常。
- 如果过多的关注爬取效率问题,就需要使用requests/scrapy库来实现,或者搭建分布式爬虫。
以上,解决问题!
项目代码
from selenium import webdriver
import pymongo
import time
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(message)s")
def parse_data(i):
"""
定义函数:解析每一页的案例
"""
logging.info("正在解析第%d个页面..."%i)
#解析第一页的数据,默认一页有5个案件,在5个div块,class='LM_list'
divs = browser.find_elements_by_class_name('LM_list')
for d in divs:
data = {}
data["case_name"] = d.find_element_by_xpath('./div[2]/h4/a').text
data["case_link"] = d.find_element_by_xpath('./div[2]/h4/a').get_attribute("href")
data["court_name"] = d.find_element_by_xpath('./div[3]/span[1]').text
data["case_id"] = d.find_element_by_xpath('./div[3]/span[2]').text
data["release_time"] = d.find_element_by_xpath('./div[3]/span[3]').text
data["case_reason"] = d.find_element_by_xpath('./div[4]/p').text
#案例数据入库
c1.insert_one(data)
if __name__=="__main__":
#1.请求主页,完成登录
#打开浏览器
browser = webdriver.Chrome()
#get请求裁判网主页
url = "https://wenshu.court.gov.cn/"
browser.get(url)
time.sleep(random.uniform(1,3)) #给浏览器时间,完成页面的加载
#最大化窗口
browser.maximize_window()
#模拟登录
#在主页窗口找到"登录"节点,点击登录
browser.find_element_by_xpath('//*[@id="loginLi"]/a').click()
time.sleep(random.uniform(0.5,1.5))
#账号、密码输入框,在页面内的iframe子页面内,所以需切换到iframe节点
#找到iframe节点
iframe = browser.find_element_by_xpath('//*[@id="contentIframe"]')
#切换进去
browser.switch_to.frame(iframe)
#在iframe内的子页面查找账号、密码输入框
#找到账号输入框,并输入账号
browser.find_element_by_xpath('//*[@id="root"]/div/form/div/div[1]/div/div/div/input').send_keys("account")
time.sleep(random.uniform(1,3)) #模拟人的操作延时,防止反爬
#找到密码输入框,并输入密码
browser.find_element_by_xpath('//*[@id="root"]/div/form/div/div[2]/div/div/div/input').send_keys("password")
time.sleep(random.uniform(1,3)) #模拟人的操作延时,防止反爬
#找到登录按钮,点击登录
browser.find_element_by_xpath('//*[@id="root"]/div/form/div/div[3]/span').click()
time.sleep(random.uniform(3,5)) #给浏览器时间,完成页面的加载
#到此,成功登录!
#2. 在搜索框内,输入"宇通客车股份有限公司"
#找到搜索框
browser.find_element_by_xpath('//*[@id="_view_1540966814000"]/div/div[1]/div[2]/input').send_keys("宇通客车股份有限公司")
time.sleep(random.uniform(0.5,1)) #模拟人的操作延时,防止反爬
#找到搜索按钮,进行点击搜索
browser.find_element_by_xpath('//*[@id="_view_1540966814000"]/div/div[1]/div[3]').click()
time.sleep(random.uniform(2,5)) #给浏览器时间,加载数据
#到此,完成搜索功能,并加载到数据
#3.解析目标数据
"""
court_name:法院名称
case_id:案号
release_time:发布时间
case_reason:案由
case_name:案件名称
case_link:案件的连接
数据存入mongodb
"""
#连接mongo 数据库
mongo = pymongo.MongoClient("localhost",27017)
case = mongo["case"]
c1 = case["case_c1"]
#分页获取数据
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(random.uniform(2,3))
i = 1
while browser.find_element_by_link_text('下一页').get_attribute("class") == " pageButton":
#解析默认的当前页面的数据,并存入mongodb
parse_data(i)
#点击 ‘下一页’
browser.find_element_by_link_text('下一页').click()
time.sleep(random.uniform(1,2)) #给浏览器时间,加载数据
#滚动条滑动到最下
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(random.uniform(0.5,1.5))
i += 1
#控制抓取10页
if i == 10:
break
#解析最后一页数据,此时页面中“下一页”不可点击
#解析当前页面的数据,并存入mongodb
parse_data(i)
time.sleep(5)
#关闭浏览器
browser.quit()
数据存储
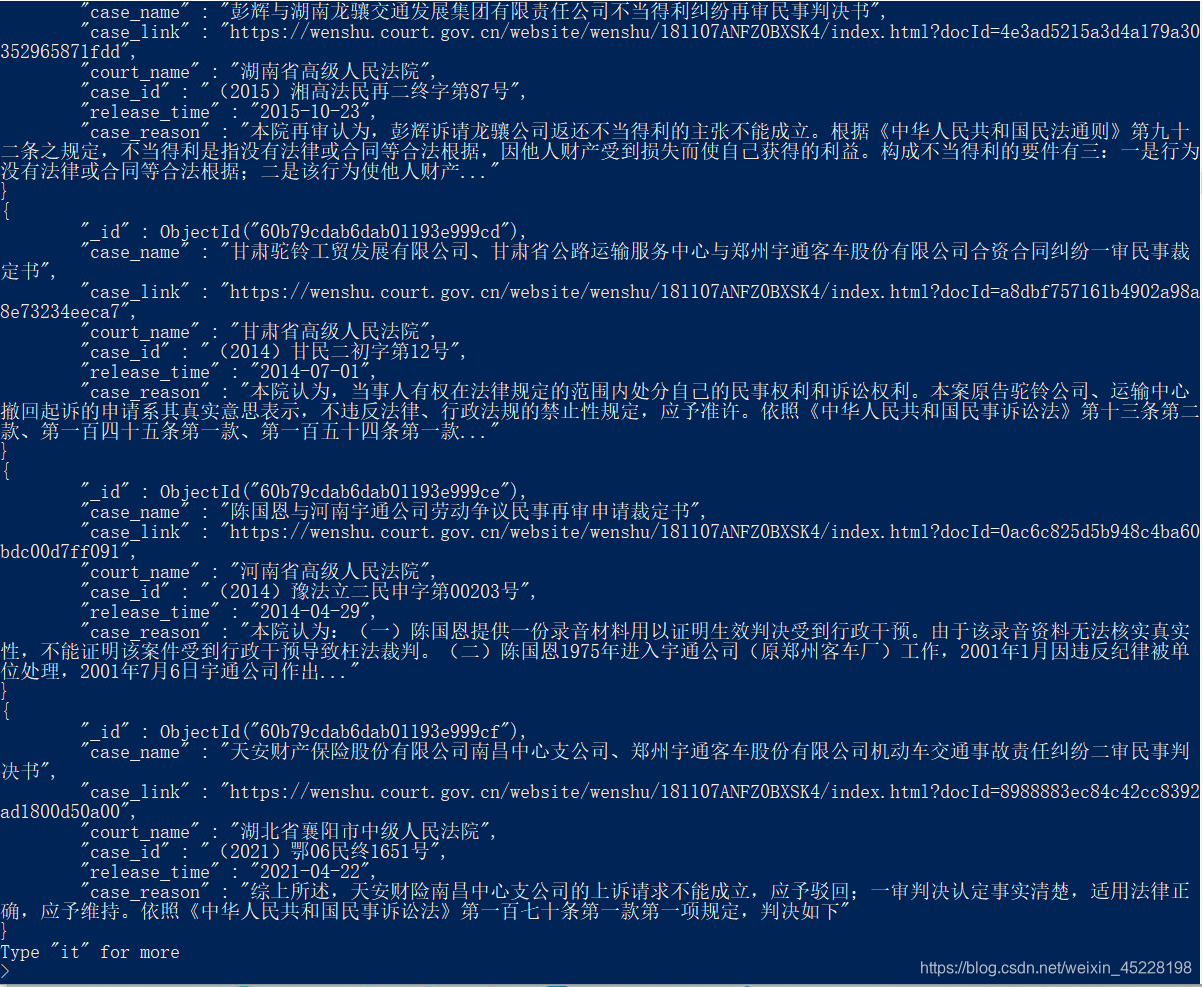
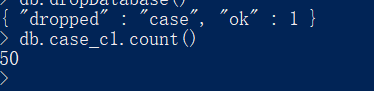
目前,控制程序抓了10页,共50个案件。
项目的缺点
- 抓取的效率低,selenium+Chrome组合的特性决定的
- 可以设置无头浏览器,只在内存渲染页面,提高效率
- 代码的结构,可以优化,实现面向对象
- 创建scrapy/scrapy-redis项目
常用的反爬机制
- 检查请求头
User-Agent
Cookie
Referer - 检查IP的访问频率
使用代理IP - 检查同一个账户发请求的频率
设置一定的访问延时
使用不同的Cookies,模拟不同的账户 - js请求加密
解析加密算法,使用python构造加密数据,发请求 - 图形验证码
简单的图形验证码-----pytesseract/ tesseract-ocr
滑块验证-------selenium模拟人的滑动,先快,后慢
















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











