







前言:更都请看《计算机视觉学习路》
BF(Brute-Force)
暴力特征匹配方法,它使用第一组中的每个特征的描述子与第二组中的所有的特征描述子进行匹配,计算它们之间的相似度,返回相似度最高的。
1.创建匹配器 BFMatcher(normType , crossCheck)
normType: NORM_L1 , NORM_L2 (默认) , HAMMING1(用于ORB的描述子)...
crossCheck : 是否进行交叉匹配,默认false
2.进行特征匹配 match = bf.match(des1,des2)
3.绘制匹配点 img = cv2.drawMatches(搜索图img1 , kp1 , 匹配图img2 , kp2,match)
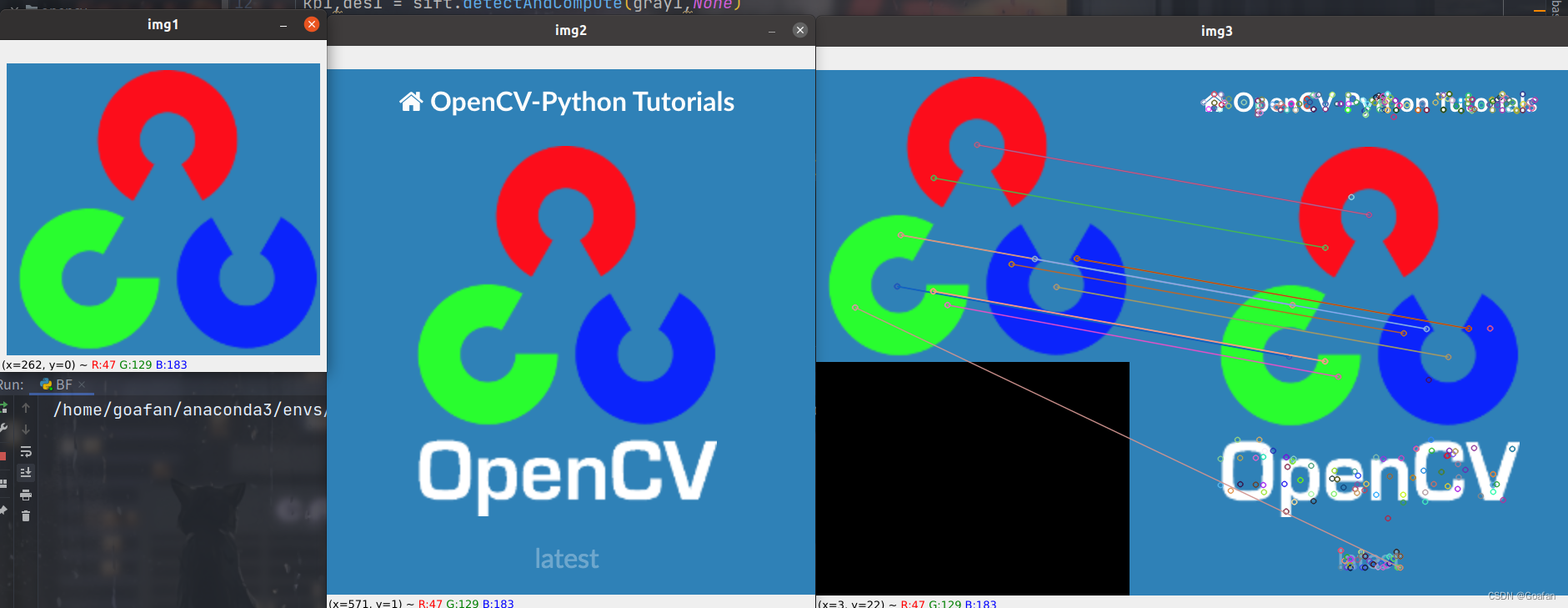
import cv2
import numpy as np
img1 = cv2.imread('../img/opencv_search.png')
img2 = cv2.imread('../img/opencv_orig.png')
# 灰度化才能进行角点检测
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
# 计算关键点和描述子
kp1,des1 = sift.detectAndCompute(gray1,None)
kp2,des2 = sift.detectAndCompute(gray2,None)
bf = cv2.BFMatcher(cv2.NORM_L1)
match = bf.match(des1,des2)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,match,None)
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.imshow('img3', img3)
cv2.waitKey(0)
FLANN
优点:进行批量匹配时,速度更快
缺点:由于它使用邻近近似值,所以精度较差
1.创建匹配器 FlannBaseMatcher(index_params , search_params)
index_params : 字典,匹配算法KDTREE,LSH
如果使用KDTREE,还需要一个字典search_params,指定KDTREE中遍历树的次数
2.进行特征匹配 match = flann.match / knnMatch( )
3.绘制匹配点 cv2.drawMatchers / drawMatchesKnn(搜索图img1 , kp1 , 匹配图img2 , kp2,match )
设置KDTREE
index_params = dict(algorithm = 1(KDTREE),trees = 5)
search_params = dict(checks = 50)
KnnMatch(des1,des2,k)方法
前两个参数为SIFT、SURF、ORB等计算的描述子
k表示欧式距离最近的前k个关键点
返回:DMatch对象,该对象包含的信息为:
distance,描述子之间的距离,值越低越好
queryIdx, 第一个图像的描述子的索引值
trainIdx , 第二个图片的描述子的索引
imgIdx , 第二幅图的索引
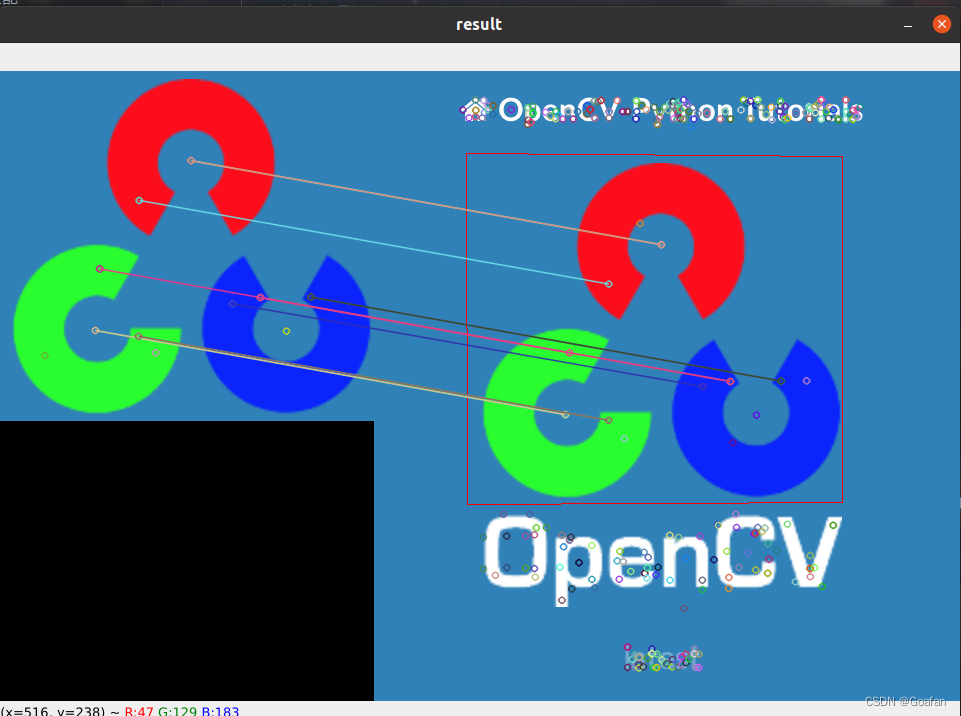
import cv2
import numpy as np
# 打开两个文件
img1 = cv2.imread('../img/opencv_search.png')
img2 = cv2.imread('../img/opencv_orig.png')
# 灰度化
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
sift = cv2.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(g1, None)
kp2, des2 = sift.detectAndCompute(g2, None)
# 创建匹配器
index_params = dict(algorithm=1, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 对描述子进行匹配计算
matchs = flann.knnMatch(des1, des2, k=2)
good = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.7 * n.distance:
good.append(m)
ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('result', ret)
cv2.waitKey()
图像查找
特征匹配 + 单应性矩阵
关于单应性矩阵可以参考《神奇的单应矩阵》《单应矩阵的推导与理解》
H, _ = cv2.findHomography(srcPts, dstPts, cv2.RANSAC, 5.0)
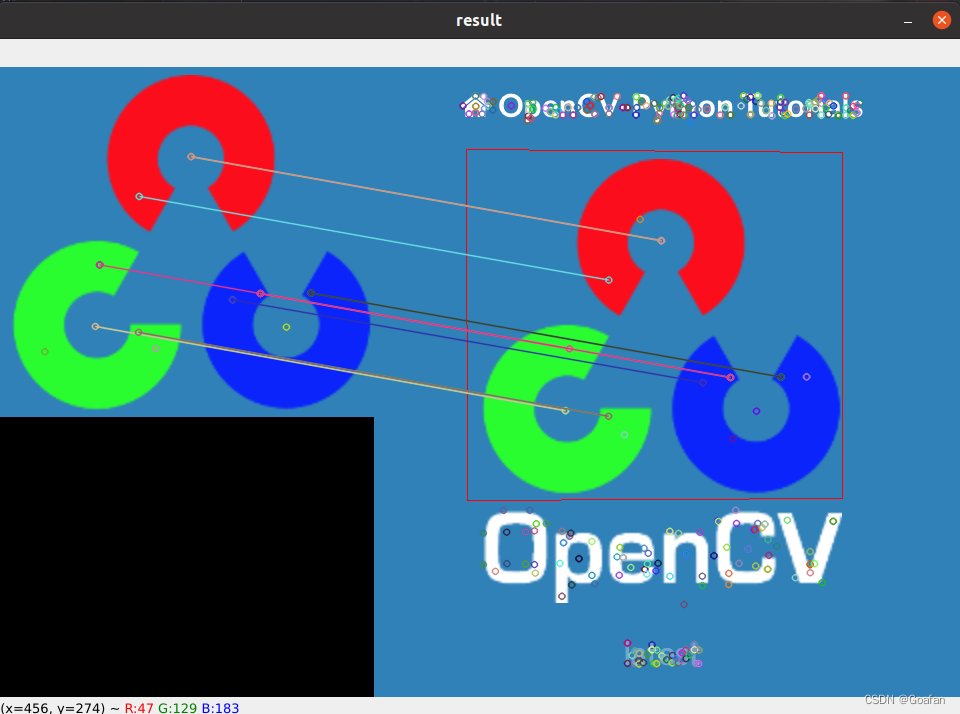
import cv2
import numpy as np
# 打开两个文件
img1 = cv2.imread('../img/opencv_search.png')
img2 = cv2.imread('../img/opencv_orig.png')
# 灰度化
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
sift = cv2.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(g1, None)
kp2, des2 = sift.detectAndCompute(g2, None)
# 创建匹配器
index_params = dict(algorithm=1, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 对描述子进行匹配计算
matchs = flann.knnMatch(des1, des2, k=2)
good = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.7 * n.distance:
good.append(m)
# 匹配点必须大于等于4
if len(good) >= 4:
srcPts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dstPts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
# 找到单应性矩阵
H, _ = cv2.findHomography(srcPts, dstPts, cv2.RANSAC, 5.0)
h, w = img1.shape[:2]
pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
# 透视变换
dst = cv2.perspectiveTransform(pts, H)
# 多边形
cv2.polylines(img2, [np.int32(dst)], True, (0, 0, 255))
else:
print('the number of good is less than 4.')
exit()
ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('result', ret)
cv2.waitKey()
图像拼接

import cv2
import numpy as np
def stitch_image(img1, img2, H):
# 1. 获得每张图片的四个角点
# 2. 对图片进行变换(单应性矩阵使图进行旋转,平移)
# 3. 创建一张大图,将两张图拼接到一起
# 4. 将结果输出
# 获得原始图的高/宽
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0, 0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2)
img2_dims = np.float32([[0, 0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
img1_transform = cv2.perspectiveTransform(img1_dims, H)
# print(img1_dims)
# print(img2_dims)
# print(img1_transform)
result_dims = np.concatenate((img2_dims, img1_transform), axis=0)
# print(result_dims)
[x_min, y_min] = np.int32(result_dims.min(axis=0).ravel() - 0.5)
[x_max, y_max] = np.int32(result_dims.max(axis=0).ravel() + 0.5)
# 平移的距离
transform_dist = [-x_min, -y_min]
# [1, 0, dx]
# [0, 1, dy]
# [0, 0, 1 ]
transform_array = np.array([[1, 0, transform_dist[0]],
[0, 1, transform_dist[1]],
[0, 0, 1]])
result_img = cv2.warpPerspective(img1, transform_array.dot(H), (x_max - x_min, y_max - y_min))
result_img[transform_dist[1]:transform_dist[1] + h2,
transform_dist[0]:transform_dist[0] + w2] = img2
return result_img
def get_homo(img1, img2):
# 1. 创建特征转换对象
# 2. 通过特征转换对象获得特征点和描述子
# 3. 创建特征匹配器
# 4. 进行特征匹配
# 5. 过滤特征,找出有效的特征匹配点
sift = cv2.xfeatures2d.SIFT_create()
k1, d1 = sift.detectAndCompute(img1, None)
k2, d2 = sift.detectAndCompute(img2, None)
# 创建特征匹配器
bf = cv2.BFMatcher()
matches = bf.knnMatch(d1, d2, k=2)
# 过滤特征,找出有效的特征匹配点
verify_ratio = 0.8
verify_matches = []
for m1, m2 in matches:
if m1.distance < 0.8 * m2.distance:
verify_matches.append(m1)
min_matches = 8
if len(verify_matches) > min_matches:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(k1[m.queryIdx].pt)
img2_pts.append(k2[m.trainIdx].pt)
# [(x1, y1), (x2, y2), ...]
# [[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2)
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0)
return H
else:
print('err: Not enough matches!')
exit()
# 第一步,读取文件,将图片设置成一样大小640x480
# 第二步,找特征点,描述子,计算单应性矩阵
# 第三步,根据单应性矩阵对图像进行变换,然后平移
# 第四步,拼接并输出最终结果
# 读取两张图片
img1 = cv2.imread('../img/map1.png')
img2 = cv2.imread('../img/map2.png')
# 将两张图片设置成同样大小
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
inputs = np.hstack((img1, img2))
# 获得单应性矩阵
H = get_homo(img1, img2)
# 进行图像拼接
result_image = stitch_image(img1, img2, H)
cv2.imshow('input img', result_image)
cv2.waitKey()















 5609
5609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











