






深度增强学习——Q-learning和决策梯度
一、什么是强化学习
强化学习是指,我们有一个智能体(agent),能够在其环境(environment)中采取行动,也可以因为其行动获得奖励,它的目标是学会如何行动以最大限度地获得奖励。强化学习多是一种动态规划的思路,使用生活化语言描述,就叫做:实践出真知。与之前学过的监督学习和无监督学习不同,强化学习本身并不依赖于数据或者数据的标签,而是依赖于对输入数据预测之后的反馈,因此它介于监督学习和非监督学习之间。
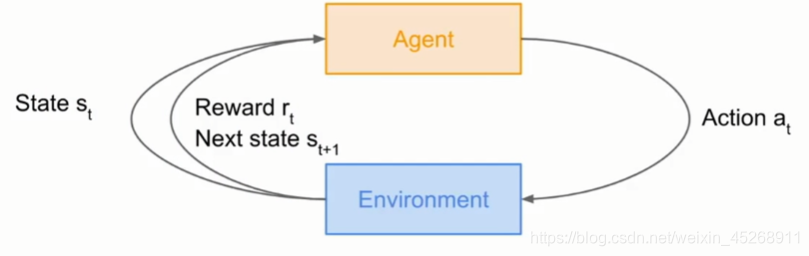
如上图所示,一个agent(例如:玩家)做出了一个action,对environment造成了影响,也就是改变了state,而environment为了反馈给agent,agent就得到了一个Reward(例如:积分/分数),不断的进行这样的循环,直到结束为止。
上述过程就相当于一个马尔可夫决策过程(MDPs),因为符合马尔可夫假设:
- 当前状态 St 只由上一个状态 St-1 和行为所决定,而和前序的更多的状态是没有关系的。
在这个过程中,Agent可能做得好,也可能做的不好,环境始终都会给它反馈,agent会尽量去做对自身有利的决策,通过反反复复这样的一个循环,agent会越来越做的好,就像孩子在成长过程中会逐渐明辨是非,这就是强化学习。
二、Q-learning
1. 为什么要引入Q-learning
在之前的监督学习和无监督学习中,我们都是可以得到及时反馈的,但是在强化学习中,引入了时间这一维度,反馈来的不是那么及时。比如种瓜,要经历选种、浇水、施肥等等操作,最后结出果实才能看出好坏,也就是说,我们执行中间的某个操作时,并不能立即得到结果好坏这一反馈。
为了应对时间带来的不确定性,就需要一个框架来量化时间的流逝对我们关系的Reward有什么影响。因此,我们引入了Q-learning算法,是一种基于值函数的方法(Value-Based)
2. Q-learning算法思想
首先理解Q的含义,Q为动作效用函数(action-utility function),用于评价在特定状态下采取某个动作的优劣。
Q-Learning的目的是学习特定State下、特定Action的价值。是建立一个Q-Table,以State为行、Action为列,通过每个动作带来的奖赏更新Q-Table。其主要优势就是使用了时间差分法TD(融合了蒙特卡洛和动态规划)能够进行离线学习, 使用bellman方程可以对马尔科夫过程求解最优策略。TD更新公式如下所示
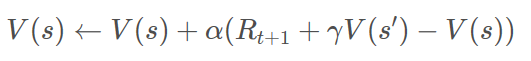
其中,V代表估值函数,R代表奖励;下一个时刻s’的估值乘以折现率,再减去当前的差值,代表了一个策略的间接影响,可以看做是战略决策,再加上下一个时刻能立即获得的奖励,就是agent关注的策略的影响,最后乘以学习率,用来控制随机性的影响,既要避免由于学习率过低导致agent学的太慢,又要避免学习率过高导致agent矫枉过正。
根据是否亲自尝试不同策略,Q-learning可以分为在线和离线两种,如下棋,前者是AI通过和人类选手博弈来提升,后者是AI不操作只观察他人下棋的棋谱,上面的TD更新公式同时也是在线的Q-learning算法下Q table的更新公式(Sarsa算法)。其离线更新公式如下:
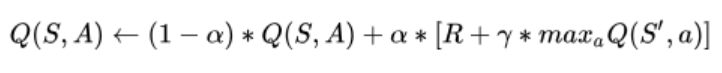
和之前的公式对比,最大的不同是未来的Q值是所有行动对于未来Q值中最大的那个,这代表着模型根据已有的知识,选择了局部最优的那个行动,通过不断的优化Q table,使得这样一个只考虑一步的最简型启发规则,也能学到全局相对较优的策略
3. 案例分析
这个例子很简单也很常见,如下图所示,两行两列,每个格子代表一个状态,有一个炸弹和宝藏,并设置 alpha = 1, γ 设置为 0.8:
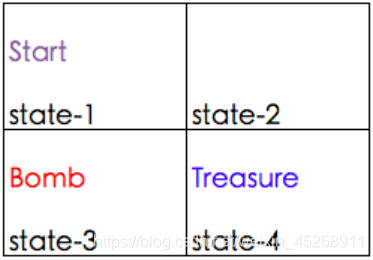
reward 表如下:
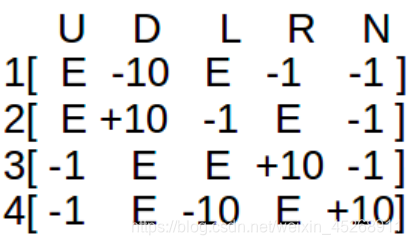
- 初始的 Q-table 的值全是 0,每一行代表一个状态,每一列代表每个状态时可以有 5 种行动,上下左右和原地不动:

- 例如我们从状态 1 开始走,可以向下或者向右,我们先选择向下
- 这时到达了状态 3
- 在状态 3 可以向上, 或者向右
- 用 Bellman Equation 更新 Q-table:
Q(1,D) = R(1,D) + γ * [ max( Q(3,U) & Q(3,R) ) ] = -10 + 0.8 * 0 = -10
R(1,D) = -10 是从状态 1 向下走到了炸弹处,
Q(3,U) 和 Q(3,R) 都是 0,因为初始表格都还是 0
于是更新后的表格变成了这样:

- 然后将状态 3 变成当前状态,这时假设我们选择向右,就走到了 4,在 4 处可以选择向上或者向左,于是再根据公式计算 Q 值:
Q(3,R) = R(3,R) + 0.8 * [ max( Q(4,U) & Q(4,L) ) ] = 10 + 0.8 * 0 = 10

这时我们走到了 4 也就是目标状态了,就可以结束这条路径了。 - 接下来可以重复上面的过程,走更多次,让 agent 尝试完所有可能的 state-action 组合,直到表格的值保持不变了,它也就学会了所有状态和行为的 Q 值:

4. 算法步骤
从上面的案例分析,我们可以整理出Q-learning算法的计算步骤
Step1 给定参数γ和reward矩阵R
Step2 令Q=0
Step3 For each episode
Step3.1 随机选择一个初始的状态s
Step3.2 若未达到目标状态,则执行以下几步
Step3.2.1 在当前状态s的所有可能行为中选取一个行为a
Step3.2.2 利用选定的行为a,得到下一个状态s’
Step3.2.3 按照更新公式计算Q(s,a)
Step3.2.4 令s := s’
agent利用上述算法从经验中进行学习,每一个episode相当于一个training session,在一个training session中,agent探索外界环境,并接受环境的reward,直到达到目标状态。训练的目的是强化agent的‘大脑’,训练的越多,则Q被优化更好。当矩阵Q被训练强化后,agent便很容易找到达到目标状态的最快路径了。要注意的是
- 在状态s’时,只是计算了 在s’时要采取哪个a’可以得到更大的Q值,并没有真的采取这个动作a’。
- 动作a的选取是根据当前Q网络以及策略(e-greedy),即每一步都会根据当前的状况选择一个动作A,目标Q值的计算是根据Q值最大的动作a’计算得来,因此为off-policy学习。
公式中的γ位于0到1之间,趋于0,表示agent主要考虑immediate reward,趋于1,表示agent同时考虑更多的future reward。利用训练好的矩阵Q,我们可以很容易地找到一条从任意状态S0出发到达目标状态的行为路径:
Step1 令当前状态s = s0
Step2 确定a,它满足Q(s,a) = max{Q(s,a)}
Step3 令当前状态s :=s’(s’表示执行a后对于的下一个状态)
Step4 重复执行step2和step3知道s成为目标状态
补充一下Sarsa算法(在线状态)的步骤,SARSA算法根Q-learning很像,也是基于Q-table,但是不同的是,在每一个episode的每一个step,我们会确定下一步采取的动作,而不是在下一个step开始时动态的确定step,算法步骤看下面的图示。

因此对于SARSA来说
- 在状态s’时,就知道了要采取哪个a’,并真的采取了这个动作。
- 动作a的选取遵循e-greedy策略,目标Q值的计算也是根据(e-greedy)策略得到的动作a’计算得来,因此为on-policy学习。
5. Q-learning和Sarsa的区别
Q-learning是off-policy,而Sarsa是on-policy学习。Q-learning在更新Q table时,它只会选择Q值最大,但是不一定会选择使这个Q值最大的动作,因为选择哪个动作是由其他的策略决定的,但是Sarsa在更新Q table时,不一定是Q最大的那个,而且接下来会选择此Q对应的action。Q-learning属于勇敢型,无论前方的路上有什么危险,它都会直接走过去,而Sarsa比较保守,一般只是会远远的躲过危险。
三、策略梯度
1. Q-learning和策略梯度(Policy Gradient)的对比
Q-learning 是一种基于值函数估计的强化学习方法,Policy Gradient是一种策略搜索强化学习方法。上文讨论了值函数的方法,把优化的重点放在了值函数上,得到了最优值函数,即可得到最优策略。我们的最优策略π*需要满足
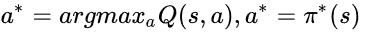
通俗地讲,基于值函数的方法就是通过计算每一个状态动作的价值,然后选择价值最大的动作执行,这是一种间接的做法。现在我们来讨论一种更直接的方法,就是一个神经网络,输入是状态,输出直接就是动作(不是Q值),我们将这个网络称为策略网络,即Policy Network。要更新策略网络,或者说要使用梯度下降的方法来更新网络,我们需要有一个目标函数,这时就引入了策略梯度。
2. Policy Gradient的基本思想
现在仅仅从概率的角度来思考问题。我们有一个策略网络,输入状态,输出动作的概率。然后执行完动作之后,我们可以得到reward,或者result。那么这个时候,我们有个非常简单的想法:
如果某一个动作得到reward多,那么我们就使其出现的概率增大,如果某一个动作得到的reward少,那么我们就使其出现的概率减小。
但是,用reward来评判动作的好坏是不准确的,甚至用result来评判也是不准确的。因为任何一个reward,result都依赖于大量的动作才导致的。因此,如果我们能够构造一个好的动作评判指标,来判断一个动作的好与坏,那么我们就可以通过改变动作的出现概率来优化策略。
假设这个评价指标是f(s,a),那么我们的Policy Network输出的是概率,一般情况下,更常使用logπ(a|s,θ)。因此,我们就可以构造一个损失函数如下:

举个简单的AlphaGo的例子。对于AlphaGo而言,f(s,a)就是最后的结果。也就是一盘棋中,如果这盘棋赢了,那么这盘棋下的每一步都是认为是好的,如果输了,那么都认为是不好的。好的f(s,a)就是1,不好的就-1。所以在这里,如果a被认为是好的,那么目标就是最大化这个好的动作的概率,反之亦然。
以上就是策略梯度的基本思想。
关于其具体公式推导,内容较多,可以参照[策略梯度的方法]
3. Policy Gradient与基于值函数方法的优劣
优点:
1)基于策略的学习可能会具有更好的收敛性,这是因为基于策略的学习虽然每次只改善一点点,但总是朝着好的方向在改善;
2)在对于那些拥有高维度或连续状态空间来说,使用基于价值函数的学习在得到价值函数后,制定策略时,需要比较各种行为对应的价值大小,这样如果行为空间维度较高或者是连续的,则从中比较得出一个有最大价值函数的行为这个过程就比较难了,这时候使用基于策略的学习就高效的多。
3)能够学到一些随机策略。基于价值函数的学习通常是学不到随机策略的。有时候计算价值函数很困难。比如当小球从空中掉下来你需要通过左右移动去接住它时,计算小球在某一个位置(状态)时采取什么样的行动(action)是很困难的。但是基于策略函数就简单了,只需要朝着小球落地的方向移动修改策略就好了。
缺点:
1)策略搜索的方法容易收敛到局部最小值。
2)评估单个策略时并不充分,方差较大。
最后,我对基于策略搜索的强化方法理解还不够深入,它有三种不同的策略梯度算法,之后还有针对其缺点的一系列改进算法,有待补充

















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









