







目录
简介
目标跟踪算法大致可以分为两类,一类是用前后两帧目标的相似程度来判断它们是否为同一个目标,另一类是预测目标的运动轨迹来判断下一帧同一目标的位置。
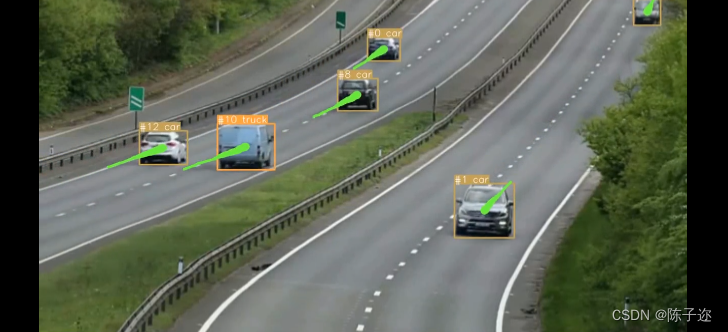
本文也编写一个目标跟踪算法,其原理是计算相邻两帧目标中心点的距离来判断它们是否为同一目标,即我们默认一个目标移动的范围不会超过某一阈值。该算法原理简单、易于实现,虽然比不上成熟的DeepSORT或ByteTrack,但在某些不是那么复杂的场合下,还是具有一定的准确性的。
模块讲解
下面我们就来介绍该算法及其代码。
设置ID:
from collections import defaultdict
import numpy as np
import math
id_history = defaultdict(lambda: [])
id_counter = 0
now_id = []
def set_id(centerPt):
return_id = 0
flag_new_id = True
for k, v in id_history.items():
dist = math.hypot(v[-1][0]-centerPt[0], v[-1][1]-centerPt[1])
if dist < 35:
id_history[k].append((float(centerPt[0]), float(centerPt[1])))
return_id = k
now_id.append(k)
flag_new_id = False
if len(id_history[k]) > 20:
id_history[k].pop(0)
break
if flag_new_id is True:
global id_counter
id_history[id_counter].append((float(centerPt[0]), float(centerPt[1])))
return_id = id_counter
now_id.append(id_counter)
id_counter +=1
return return_id字典变量id_history用于保存目标ID和该目标的中心点的坐标,字典的key为ID,value为该ID的坐标。在这里,我们除了为目标标注ID外,还实现了另一个功能:绘制了该目标的运动轨迹,所以这里的坐标不仅仅是当前帧的坐标,还包括以前同一目标的坐标。
id_counter为目标ID的编号。
我们除了为目标设置ID外,还需要删除那些不再出现的ID,因此我们还需要一个数组变量now_id,用于记录当前帧内的所有ID。
函数set_id的作用就是为当前目标设置ID,它的输入变量是被设置目标ID的中心点坐标centerPt,返回的是该目标的ID号return_id。变量flag_new_id用于标注当前目标是否在前一帧出现过,如果出现过,则赋予前一帧同一目标的ID,否则赋予新的ID。for循环遍历所有以前的目标ID,计算距离测度,当小于35时,我们就认为它们是用一个目标,并把它的坐标添加至该ID内,同时也把该ID添加至now_id内。由于我们只绘制一定长度的运动轨迹,所以需删除早期存储的该ID的多余坐标。if flag_new_id is True内用于为该目标赋予以前从未出现的新ID。除了为目标设置ID外,还需要删除不再出现的ID,否则跟踪算法会不准确:
def del_id():
[id_history.pop(k) for k in set(id_history.keys()) - set(now_id)]
now_id.clear()
由于我们已经把当前帧内出现的ID保存在了now_id内,所以我们只需要把id_history内的ID与now_id比较,将now_id内没有出现的ID从id_history内剔除掉即可。
算法的核心部分就介绍完了,下面我们介绍一个附加功能,绘制目标运动轨迹:
def traj(img, trackid, thick=15, color=(70, 250, 116),):
points = np.hstack(id_history[trackid]).astype(np.int32).reshape((-1, 2))
leng = len(id_history[trackid])
for i in range(leng-1):
thickness = max(thick - i, 3)
cv2.line(frame, points[-1*(i+1)], points[-1*(i+2)], color=color, thickness=thickness, lineType=cv2.LINE_AA)
函数traj实现了绘制ID为trackid的运动轨迹。轨迹坐标就保存在id_history的key为trackid的value内,这些坐标是按先后顺序保存的。为了使轨迹看起来更形象逼真,我们并没有使用cv2.polylines一次性的绘制,而是采用cv2.line两两坐标画线,而采用的线宽thickness是渐变的。代码的其他部分就是目标检测器和绘制目标边框。
主函数
我们选择YOLOv8来检测目标,具体的注解就不再赘述,在这里只是附上代码:
import torch
from ultralytics import YOLO
import cv2
model = YOLO("yolov8l.pt")
device = torch.device("cuda")
model.to(device)
cap = cv2.VideoCapture('D:/track/british_highway_traffic.mp4')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fNUMS = cap.get(cv2.CAP_PROP_FRAME_COUNT)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
videoWriter = cv2.VideoWriter("D:/track/track.mp4", fourcc, fps, size)
def box_label(image, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
cv2.rectangle(image, p1, p2, color, thickness=2, lineType=cv2.LINE_AA)
if label:
w, h = cv2.getTextSize(label, 0, fontScale=2 / 3, thickness=1)[0]
outside = p1[1] - h >= 3
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
cv2.rectangle(image, p1, p2, color, -1, cv2.LINE_AA)
cv2.putText(image,
label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
0,
2 / 3,
txt_color,
thickness=1,
lineType=cv2.LINE_AA)
while(cap.isOpened()):
ret, frame = cap.read()
if not ret:
break
results = model(frame,device='cuda')[0]
boxes = results.boxes.data
for box in boxes:
x1, y1, x2, y2 = box[:4]
x = (x1+x2)/2
y = (y1+y2)/2
track_id = set_id((x,y)) #为当前目标设置ID
if box[-1] == 2:
box_label(frame, box, '#'+str(track_id)+' car', (89, 161, 197))
traj(frame, track_id) #为该目标绘制轨迹
elif box[-1] == 7:
box_label(frame, box, '#'+str(track_id)+' truck', (67, 161, 255))
traj(frame, track_id)
elif box[-1] == 3:
box_label(frame, box, '#'+str(track_id)+' motorcycle', (186, 55, 2))
traj(frame, track_id)
elif box[-1] == 5:
box_label(frame, box, '#'+str(track_id)+' bus', (19, 222, 24))
traj(frame, track_id)
cv2.imshow('frame',frame)
cv2.putText(frame, "https://blog.csdn.net/zhaocj", (25, 50),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
videoWriter.write(frame)
del_id() #删除该帧内没有出现的ID
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
videoWriter.release()
cv2.destroyAllWindows()
该算法在目标被遮挡,甚至断帧的情况下,识别效果肯定不行,但在一般情况下,该算法也不失为一种简单有效的方法。

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











