






关于transformer的学习
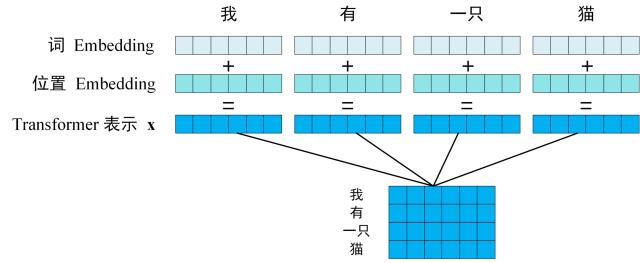
1.transformer第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
那就是说向量 x,实际上是同一个单词和它在句子中的位置Embedding后的一组变量??
以"我有一只猫"为例:
x1表示“我”组成的向量
x2表示“有”组成的向量
x3表示“一只”组成的向量
x4表示“猫”组成的向量
2.Embedding就是从原始数据提取出来的Feature,这个feature是啥??
在自然语言处理(NLP)中,Embedding(嵌入)指的是将文本数据(如单词、句子或文档)映射到一个低维的向量空间中的过程。这个低维向量被称为嵌入向量,它捕捉了文本数据的语义和语法信息。
具体来说,对于单词嵌入(Word Embedding),它是从大规模文本语料中学习得到的,其目标是使得语义上相似的单词在嵌入空间中的表示也相似。例如,对于语义上相似的单词(如“king”和“queen”),它们在嵌入空间中的向量表示应该是接近的。
嵌入向量通常是通过词嵌入模型(如Word2Vec、GloVe、FastText等)在训练过程中学习得到的,这些模型通过观察文本数据中单词的上下文信息来学习单词的向量表示。这些向量不仅仅捕捉了单词的语义信息,还可以用于向模型提供输入特征,从而帮助模型更好地理解和处理文本数据。
总结来说,Embedding 就是从原始文本数据中提取出来的、用于表示文本语义信息的低维向量特征。
3.将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C
为什么要经过encode呢,而且还是6个,得到的单词表示向量矩阵和 矩阵 C 有啥区别??
在自然语言处理中,特别是在使用Transformer或类似架构的模型时,“Encoder” 指的是处理输入文本序列的部分。这里的 “encode” 操作指的是将输入的单词表示向量矩阵(每一行是一个单词的表示向量
𝑥
x)通过多个Encoder block进行处理,从而得到句子中所有单词的编码信息矩阵
𝐶
Encoder的作用:
Transformer 模型中的 Encoder 主要负责处理输入序列,以及在处理过程中提取和编码输入序列的语义和句法信息。它通过堆叠多个相同的 Encoder block(通常为6个)来逐层提取和传递信息。
单词表示向量矩阵:
这是指对输入的文本序列中的每个单词,通过预训练的词嵌入模型(如Word2Vec、GloVe等)或者模型自身学习得到的向量表示。
编码信息矩阵 𝐶
这是经过Encoder处理后得到的结果。在每个Encoder block中,输入的单词表示向量矩阵会经历多轮的自注意力机制(self-attention)、前馈神经网络等操作,以捕捉单词之间的依赖关系和句子层次的语义信息。经过多个Encoder block的处理后,每个单词的表示会被逐步更新和丰富,最终得到整个句子的编码信息矩阵 𝐶
区别和作用:
a.单词表示向量矩阵是原始的输入,每一行代表一个单词的静态向量表示,没有经过额外的上下文和序列信息的处理。
b.编码信息矩阵 𝐶 经过了多个Encoder block的处理,每个单词的表示向量已经被动态地更新和编码,包含了丰富的语义和句法信息,适合用于后续的任务,如情感分析、机器翻译等。
因此,经过Encoder处理后得到的编码信息矩阵 𝐶
比原始的单词表示向量矩阵更加丰富和信息密集,能够更好地表达句子的语义内容,这也是为什么要经过多个Encoder block处理的原因。
4.那我可否这么理解:输入的单词表示的向量矩阵的每一行x实际上是同一个单词和它在句子中的位置Embedding后的一组变量, 然后经过n个Embedding就是对不同单词进行排列组合,n越大组成的句子类型约广泛?
单词表示的向量矩阵(每一行是一个单词的表示向量 𝑥):
这个矩阵中的每一行 𝑥 确实是表示一个单词的向量,这个向量包含了该单词的语义信息(通过词嵌入模型获得)和位置信息(通过位置编码加入)。
Embedding 的理解:
Embedding 在自然语言处理中通常指的是词嵌入(Word Embedding),它是将单词映射到一个低维的向量空间中,捕捉了单词的语义相似性。
而在Transformer等模型中,还会加入位置编码(Positional Encoding),以表示单词在句子中的位置关系,确保模型能够理解输入序列的顺序信息。
关于句子类型的理解:
经过多个Encoder block处理后得到的编码信息矩阵 𝐶
C 并不是简单的对不同单词进行排列组合。每个Encoder block的作用是增强输入序列的表示,使其能够更好地传递和捕捉序列中的信息,包括语义关系和依赖关系。
增加Encoder block的数量,理论上可以提升模型对句子结构的理解能力,但并不一定意味着能够覆盖更多的句子类型。关键在于模型结构和训练数据的质量和多样性。
总结来说,单词表示的向量矩阵中的每一行 𝑥是对单词的语义和位置信息的编码;而经过多个Encoder block处理后得到的编码信息矩阵 𝐶 是对整个句子语义的深度表示。增加Encoder block可以增强模型的表达能力,但并非简单地进行排列组合,而是通过层层处理,捕捉句子中的复杂关系和语义。
5.那你对“我有一只猫”这个句子有怎样的深度表示呢??
具体来说,对于这个句子:
我、有、一只、猫 这四个单词各自的表示向量经过模型的处理后,会包含它们在语义上的相似性和差异性。
单词之间的顺序信息和依赖关系(例如,"我"是主语,"有"是动词,"一只"是数量描述词,"猫"是宾语)也会被模型捕捉和编码。
模型通过多层的自注意力机制和前馈神经网络,逐步加深对句子结构和语义的理解,使得最终的编码信息 𝐶 具有丰富的语义表达能力。
这种深度表示的编码信息 𝐶 可以用于许多自然语言处理任务,如情感分析、问答系统、语义理解等,因为它不仅仅是简单的词袋模型,而是能够真正理解和表达句子中复杂语义的向量化表示。
6.不明白是怎么捕捉 单词之间的顺序信息和依赖关系(例如,"我"是主语,"有"是动词,"一只"是数量描述词,"猫"是宾语)??
*位置编码(Positional Encoding):
在Transformer模型中,由于自注意力机制不考虑单词的顺序,为了确保模型能够处理序列的顺序信息,引入了位置编码。
位置编码是一种特殊的向量,它会被加到单词的嵌入向量中,以便在输入到模型前加入位置信息。通常使用正弦和余弦函数来计算位置编码,确保不同位置的单词有不同的编码,这样模型可以区分单词的相对位置。
自注意力机制(Self-Attention Mechanism):
Transformer模型中的核心是自注意力机制,它允许模型在单个输入序列中同时计算每个单词与其他所有单词之间的注意力权重。
在Encoder中,每个单词都会与其他所有单词进行交互,根据它们之间的语义和位置关系分配不同的注意力权重。
这意味着模型可以动态地捕捉到每个单词与整个句子中其他单词的关系,包括顺序信息和依赖关系。
层次化处理(Layer-wise Processing):
Transformer模型由多个Encoder block堆叠而成,每个Encoder block都会对输入进行一系列的处理,包括多头自注意力和前馈神经网络等操作。
通过堆叠多个Encoder block,模型可以逐层地增强对单词之间复杂依赖关系的理解,从而捕捉到更高层次的语义和语法信息。
综上所述,Transformer模型通过位置编码、自注意力机制和层次化处理,能够有效地捕捉到单词之间的顺序信息和依赖关系。这些机制使得模型能够在处理自然语言时,不仅仅关注单词的静态语义,还能理解和利用句子中单词之间复杂的语境和关联关系,从而提高了对文本理解和生成任务的效果。
7.有一点明白了,自注意力机制之所以叫自注意力机制,是因为他还能计算每个单词和其他单词的注意力权重
自注意力机制(Self-Attention Mechanism)之所以被称为自注意力,是因为它不仅仅能够计算每个单词与其他所有单词之间的注意力权重,还包括单词自身与自身之间的关注。这种机制允许模型在处理输入序列时,根据每个单词与整个序列中其他单词的语义关系,动态地分配权重,从而更好地理解单词在上下文中的重要性和相互作用。
具体来说,对于一个输入序列,自注意力机制可以帮助模型做出以下几点:
计算注意力权重:对于每个单词,通过与其他所有单词的比较,确定其在上下文中的重要性。这些权重反映了每个单词与整个序列中其他单词的相关性,从而使模型能够重点关注对理解和处理文本有重要贡献的部分。
建立全局联系:通过全局考虑整个输入序列,自注意力机制帮助模型捕捉到长距离的依赖关系和语境信息,而不仅仅是局部的局部信息。
提升模型效率:尽管每个单词都与所有其他单词有关,但使用矩阵乘法和并行计算,自注意力机制可以高效地进行处理,特别是在Transformer等深度学习模型中。
8.层次化处理不理解他的作用,一层有什么缺点,多层有什么有点??
层次化处理在Transformer模型中的作用是通过多层的Encoder或Decoder block来逐步提取和表示输入序列或输出序列的语义信息和依赖关系。让我来详细解释一下一层和多层的区别以及其作用:
单层Encoder/Decoder的缺点:
有限的表示能力:单层Encoder/Decoder可能无法捕捉到复杂的语义关系和长距离依赖关系。每一层的自注意力机制和前馈神经网络虽然可以增强单词之间的交互,但仍然受到层次的限制。
信息流的狭窄性:在单层情况下,输入的信息只能在该层内传递和处理,可能会导致信息流的狭窄,难以在不同层之间有效地共享和整合信息。
多层Encoder/Decoder的优点:
提升模型的表示能力:通过堆叠多个Encoder或Decoder block,模型可以逐层地增强对输入序列或输出序列的表示能力。每一层都可以学习和提取不同层次、不同粒度的语义信息,从而更好地理解文本的结构和含义。
捕捉更复杂的依赖关系:多层结构能够帮助模型捕捉更长距离的依赖关系和语境信息。例如,第一层可能捕捉到局部的语义信息,而后续的层次可以在此基础上逐步整合更广泛的上下文信息。
增强模型的鲁棒性和泛化能力:通过多层处理,模型可以学习到更加抽象和泛化的特征,有助于提升模型在不同任务和数据上的泛化能力和鲁棒性。
总结:
多层Encoder/Decoder的主要优点在于能够逐层地提升模型对输入序列或输出序列的表示能力和理解能力,从而更好地处理复杂的自然语言处理任务。每一层的处理可以看作是在不同抽象级别上对文本进行理解和建模,使得模型能够更有效地解决长距离依赖、语义理解和生成等任务。
9.不理解,你能以“我有一只猫”举例说明吗
当使用Transformer模型处理句子 “我有一只猫” 时,可以通过多层Encoder来解释层次化处理的作用。让我们以一个简化的方式来说明:
单层Encoder处理 “我有一只猫”:
在单层Encoder中,模型会依次处理每个单词的表示向量 𝑥,假设每个单词的表示向量 𝑥是通过词嵌入和位置编码得到的。在单层处理中:
输入:每个单词的表示向量 𝑥会被输入到Encoder中。
处理:单层Encoder将会通过自注意力机制和前馈神经网络对输入进行处理,尝试捕捉单词之间的依赖关系和语义信息。
输出:最终,单层Encoder会输出一个编码信息矩阵 𝐶单层,其中包含了 “我有一只猫” 这句话在单层处理下的语义表示。这个表示可能会包含基础的语义信息和单词之间的基础依赖关系。
多层Encoder处理 “我有一只猫”:
现在,考虑多层Encoder处理相同的句子 “我有一只猫”。假设有3层Encoder:
多层处理:每一层Encoder都会接受上一层Encoder的输出作为输入,然后进行进一步的处理和学习。
逐层提取语义信息:第一层Encoder可能会捕捉到基础的单词级别的语义和依赖关系(例如,“有”是动词,“猫”是宾语),第二层Encoder可以在此基础上进一步整合这些信息,捕捉到更高级别的语义(例如,“一只猫”是一个整体的概念),第三层Encoder可以继续增强对句子整体语义的理解。
输出:最终,第三层Encoder的输出 𝐶多层将会是经过多层处理后的句子 “我有一只猫” 的深度语义表示。这个表示会比单层处理更加丰富和抽象,能够更好地捕捉句子中复杂的语义和依赖关系,包括单词的顺序信息和整体意义。
总结:
多层Encoder的主要作用在于通过逐层的处理和信息整合,使得模型能够逐步提升对输入序列(如句子)的理解能力。每一层的处理都可以看作是在不同抽象层次上对输入数据进行更深入和全面的分析,从而使得模型能够更有效地捕捉长距离依赖关系和复杂的语义信息。















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









