








-
作者:Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, Parisa Kordjamshidi
-
单位:密歇根州立大学,密歇根大学,北卡罗来纳大学教堂山分校,阿德莱德大学
-
论文标题:Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models
-
出版信息:Transactions on Machine Learning Research-2024
-
论文链接:https://openreview.net/pdf?id=yiqeh2ZYUh
-
项目主页:https://github.com/zhangyuejoslin/VLN-Survey-with-Foundation-Models
主要贡献
-
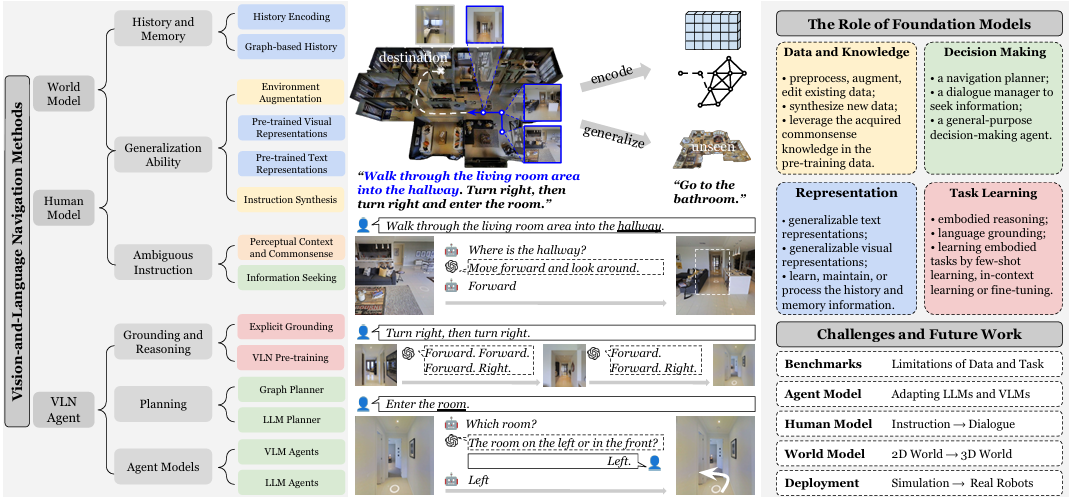
论文引入了基于LAW框架的系统框架,用于组织和理解VLN中的多模态推理和规划任务,强调了基础模型在构建世界模型和智能体模型中的作用。
-
详细讨论了基础模型(如LLMs和VLMs)在VLN中的应用,展示了它们在多模态理解、推理和跨域泛化方面的优势。
-
从世界模型、人类模型和VLN智能体三个角度对VLN的挑战进行了分类,并提供了相应的解决方案。
-
探讨了基础模型在VLN中的未来应用机会,包括改进基准数据集、处理动态环境和扩展到室外导航等,为未来的研究提供了方向。
1 介绍
-
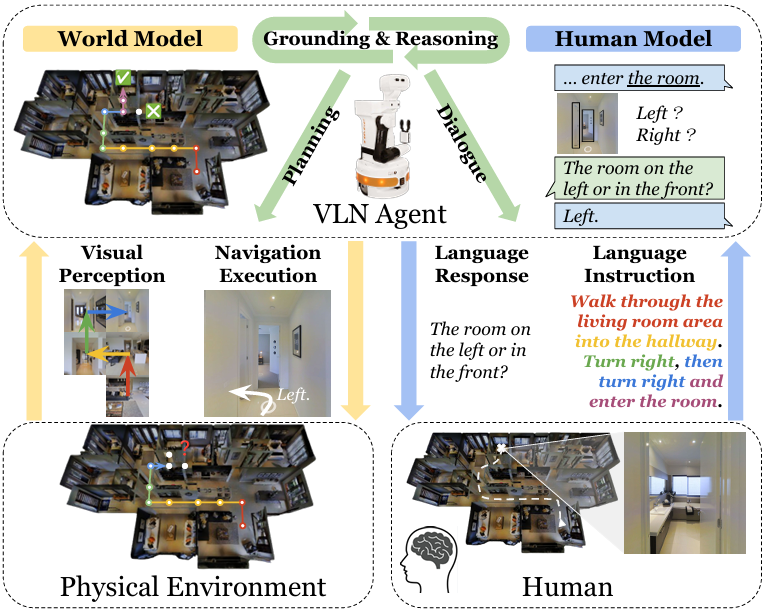
背景: 开发能够与人类及其周围环境互动的具身智能体是人工智能(AI)的一个长期目标。这些系统在现实世界中有巨大的应用潜力,例如作为家庭机器人、自动驾驶汽车和个人助理。
-
VLN的定义:VLN被定义为一个需要智能体遵循人类指令、探索三维环境并在各种形式的歧义下进行情境交流的多模态和协作任务。这个任务要求智能体能够理解和执行自然语言指令,同时处理视觉信息。
-
研究进展:论文回顾了VLN的研究进展,包括在真实光景模拟器和真实环境中进行的探索。这些研究导致了多个基准数据集的开发,每个数据集都提出了略有不同的问题形式。
-
基础模型的影响:论文强调了基础模型(如BERT、大语言模型和视觉-语言模型)在VLN中的最新影响。这些模型在多模态理解、推理和跨域泛化方面表现出色,显著提高了VLN任务的性能。
-
研究重点的转变:基础模型的引入使得VLN研究从多模态注意力学习和策略政策学习转向预训练通用视觉和语言表示,从而支持任务规划、常识推理以及在现实环境中的泛化。
-
研究目标:论文的目标是通过里程碑式进展和探索基础模型在该领域的机会和潜在角色,为VLN研究提供有价值的资源和见解。此外,论文旨在将VLN的不同挑战和解决方案组织起来,以便于研究人员对基础模型的理解和应用。
2 背景与任务定义
2.1 认知基础
-
论文首先探讨了人类和其他导航动物的认知基础,强调了理解空间导航的重要性。例如,Gallistel(1990)描述了两种基本机制:
-
piloting(涉及环境地标并计算距离和角度),
-
path integration(通过自我运动感知计算位移和方向变化)。
-
-
这些机制对于理解动物如何在环境中导航至关重要。
-
此外,论文提到认知地图假说,认为大脑形成统一的时空表示来支持记忆和导航(Epstein et al., 2017; Bellmund et al., 2018)。
-
Tolman(1948)的研究表明,当熟悉路径被阻断且没有地标时,老鼠能够采用正确的新路径。
-
神经科学家还发现了海马体中的位置细胞,表明存在一个编码地标和目标的空间坐标系统(O'Keefe & Dostrovsky, 1971; O'Keefe & Nadel, 1978)。
-
-
最近的研究提出了非欧几里得表示,如认知图(Warren, 2019; Ericson & Warren, 2020),以展示我们如何表示世界的空间知识。
-
视觉和听觉感知在空间表示中显然很重要(Klatzky et al., 2006),但我们的语言技能和空间认知也紧密相连(Pruden et al., 2011)。
-
研究表明,理解空间语言的不同方面可以帮助完成与空间相关的任务(Pyers et al., 2010),而语言影响儿童通过识别地标在识别位置时的互动(Shusterman et al., 2011)。
-
研究VLN不仅有助于发展遵循人类指令的具身AI,还能加深我们对认知智能体如何发展导航技能、适应不同环境以及语言使用与视觉感知和动作之间联系的理解。
2.2 相关任务和综述范围
-
论文指出,传统的自然语言导航指令建模通常使用符号世界表示,如地图(Anderson et al., 1991; MacMahon et al., 2006; Paz-Argaman & Tsarfaty, 2019)。
-
然而,本文的重点是使用视觉环境和解决多模态理解和对齐挑战的模型。
-
论文还提到,尽管视觉导航(Zhu et al., 2021b; Zhang et al., 2022a; Zhu et al., 2022)和移动机器人导航(Gul et al., 2019; Crespo et al., 2020; Müller et al., 2021)的研究集中在视觉感知和物理体现上,但这些研究对语言在导航任务中的作用讨论较少。
-
因此,本文主要关注导航任务,并提供详细的文献综述。
2.3 VLN任务定义和基准
VLN任务定义
-
典型的VLN智能体从人类教练处接收一系列语言指令,并通过自上而下的视觉视角在环境中导航。智能体的任务是通过生成一系列离散视图或低级动作的轨迹来跟随指令,并控制到达目的地。成功是指智能体在指定距离内到达目的地。
-
此外,智能体可能在导航过程中与教练交换信息,例如请求帮助或进行自由形式的语言交流。随着对VLN智能体的期望增加,它们还被要求集成其他任务,如操作(Shridhar et al., 2020)和物体检测(Qi et al., 2020b)。
基准
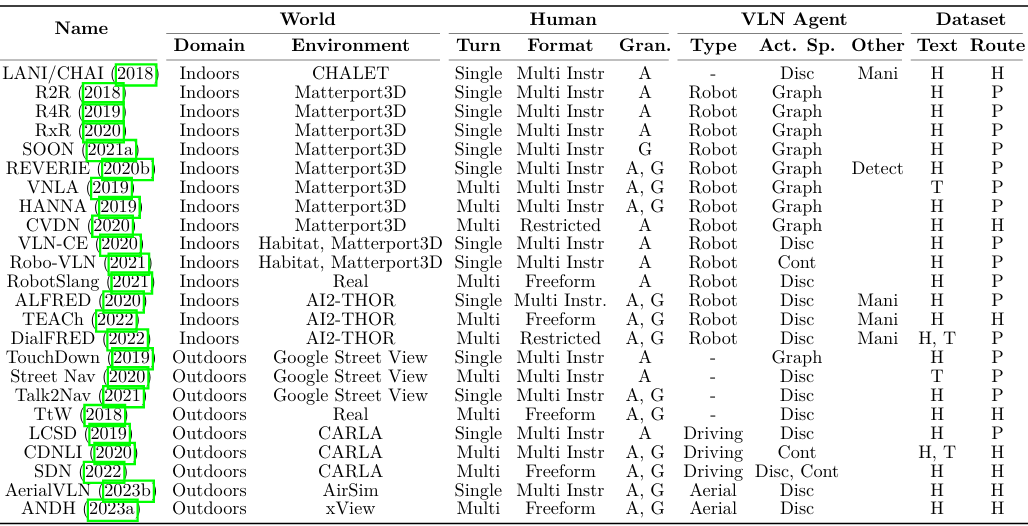
-
VLN涵盖了一系列基准和任务定义,这些差异引入了独特的挑战。现有的VLN基准可以根据几个关键方面进行分类:
-
导航发生的世界(包括领域和环境)、
-
涉及的人类交互类型(包括交互回合、通信格式和语言粒度)、
-
VLN智能体类型(包括智能体类型、动作空间和额外任务)、
-
以及数据集收集方法(包括文本收集方法和路线演示方法)。
-
-
代表性的基准包括:
-
Anderson等人(2018)创建的Room-to-Room(R2R)数据集,基于Matterport3D模拟器,要求智能体遵循精细的导航指令到达目标。
-
Room-across-Room(RxR)(Ku et al., 2020)是多语言版本,包括英语、印地语和泰卢固语指令。
-
Krantz等人(2020)提出在连续环境中进行VLN(VLN-CE),通过将离散R2R路径转移到连续空间来实现。
-
评估指标
- 用于评估导航性能的主要指标包括:
-
导航误差(NE)、成功率(SR)和路径长度加权的成功率(SPL)。
-
- 其他指标包括:
-
覆盖率加权长度得分(CLS)、归一化动态时间规整(nDTW)和归一化动态时间规整加权的成功率(sDTW),用于衡量指令遵循的忠实度和预测轨迹与真实轨迹的一致性。
-
2.4 基础模型
-
基础模型在大规模数据集上进行训练,显示出广泛的下游应用泛化能力。
-
文本基础模型(如BERT和GPT-3)在NLP领域取得了革命性的成果。
-
视觉-语言基础模型(如LXMERT、CLIP和GPT-4)通过整合视觉和文本数据,扩展了多模态学习的范式,特别适用于各种VL应用。
3 世界模型:学习和表示视觉环境
3.1 历史和记忆
-
在VLN任务中,智能体需要结合过去的行为和观察的历史信息来做出决策,而不仅仅是考虑当前的单个步骤。
-
这与其他视觉-语言任务(如视觉问答VQA)不同,后者通常只考虑单个步骤的信息。
技术方法
-
多模态Transformer:
-
使用预训练的多模态Transformer来结合指令和导航历史进行决策。
-
这些模型通常从在领域内指令-轨迹数据上预训练的模型初始化。
-
-
状态token更新:
-
一些方法通过递归更新的状态token来编码导航历史。
-
Hong等人(2021)提出使用最后一步的[CLS]标记来编码历史信息,而Lin等人(2022a)则引入了一个可变长度的记忆框架,存储来自前一步骤的动作激活作为历史编码。
-
-
序列编码:
-
另一种方法是直接将导航历史编码为序列。Pashevich等人(2021)对每个步骤的单视图图像进行编码。
-
Chen等人(2021b)进一步提出使用全景编码器来编码每个时间步的全景视觉观察,并通过历史编码器来编码所有过去的观察。
-
-
文本描述:
-
随着大语言模型(LLM)在导航中的应用,一些工作将视觉环境转换为文本描述,并将世界解释为文本的趋势。
-
这种方法通过将视觉环境转换为文本描述来编码导航历史,并结合相对空间信息(如方向、高度和距离)。
-
-
图结构:
-
另一条研究线通过图信息增强导航历史建模。一些技术使用结构化的Transformer编码器来捕捉环境中的几何线索。
-
这些方法还包括使用拓扑图、俯视图信息(如网格图)、语义图和局部度量图来建模观察历史。
-
3.2 在未见环境中泛化
- 在VLN中,一个主要的挑战是从有限的环境中学习并在新环境中泛化。许多工作表明,
-
从语义分割特征中学习(Zhang et al., 2021a)、
-
在训练期间在环境中添加dropout信息(Tan et al., 2019),
-
以及最大化来自不同环境的语义对齐图像对的相似性(Li et al., 2022a)可以提高智能体在新环境中的泛化性能。
-
技术方法
-
预训练视觉表示:
-
大多数工作从在ImageNet上预训练的ResNet获取视觉表示。
-
Shen等人(2022)用CLIP视觉编码器替换ResNet,CLIP通过图像-文本对的对比损失进行预训练,自然更好地对齐图像和指令。
-
-
环境增强:
-
一条主要的研究线专注于通过自动生成合成数据来增强导航环境。
-
EnvEdit(Li et al., 2022b)、EnvMix(Liu et al., 2021)、KED(Zhu et al., 2023)和FDA(He et al., 2024a)通过改变Matterport3D中的现有环境来生成合成数据。
-
Pathdreamer(Koh et al., 2021)和SE3DS(Koh et al., 2023)进一步通过给定当前观察的未来步骤合成环境来探索利用合成视图作为增强的数据。
-
-
预训练中的学习:
-
随着基础模型的进步,学习范式发生了变化。
-
在基础模型普及之前,大多数工作通过在训练环境中直接增强新环境并微调LSTM-based VLN智能体来进行。
-
随着预训练的证明对基础模型至关重要,它也成为VLN在预训练阶段从收集的环境中学习的标准做法。
-
4 人类模型:指令理解与交互
4.1 模糊指令
-
在单轮导航场景中,智能体通常需要遵循初始指令而不需要进一步的人类互动来澄清。
-
这些指令可能缺乏灵活性,无法训练智能体适应动态环境的语言理解和视觉感知。模糊指令的主要问题包括:
-
不可见的地标:指令中提到的地标在当前视角下不可见。
-
难以区分的地标:从多个视角可见的地标难以区分。
-
为了解决这些问题,研究采用了以下方法:
-
感知上下文和常识知识:利用大规模的跨模态预训练模型(如CLIP)来获取视觉对象及其状态的感知上下文和常识知识,以解决模糊性。例如,
-
VLN-Trans(Zhang & Kordjamshidi, 2023)使用CLIP从视觉观察中提取可见且独特的对象,构建易于遵循的子指令。
-
LANA+(Wang et al., 2023f)利用CLIP查询地标的语义标签,并选择最相关的文本线索作为显著地标的表示。
-
-
信息寻求:另一种方法是直接从伙伴(即生成指令的人类)寻求帮助。这涉及三个关键挑战:
-
何时寻求帮助:决定何时请求帮助(Chi et al., 2020)。
-
生成信息寻求问题:生成关于下一步行动、物体和方向的问题(Roman et al., 2020; Singh et al., 2022)。
-
开发一个提供信息的oracle:oracle可以是真人(Singh et al., 2022)、规则和模板(Gao et al., 2022),或神经模型(Nguyen & Daumé III, 2019)。
-
最近的研究探索了使用大语言模型(LLMs)作为信息寻求模型,或者作为人类助手或信息提供模型的智能体。
-
4.2 指令理解的泛化
导航数据的规模和多样性有限,影响了智能体理解和遵循各种语言表达的能力,特别是在未见导航环境中。为了提高泛化能力,研究采用了以下方法:
-
预训练文本表示:利用预训练的语言模型(如BERT和多模态Transformer)来增强智能体的语言泛化能力。例如,
-
PRESS(Li et al., 2019b)通过微调预训练的语言模型BERT来获得更好的文本表示。
-
PREVALENT(Hao et al., 2020)通过在大量文本-图像对上进行预训练来获得更通用的视觉-语言表示。
-
-
指令合成:通过合成更多指令来提高智能体的泛化能力:
-
早期工作采用Speaker-Follower框架(Fried et al., 2018; Tan et al., 2019; Kurita & Cho, 2020; Guhur et al., 2021a)来训练离线指令生成器。然而,生成的指令质量较低。
-
Marky(Wang et al., 2022a; Kamath et al., 2023)使用多模态扩展的多语言T5模型来生成接近人类的指令。
-
PASTS(Wang et al., 2023c)引入了一个具有进度感知的空间-时间Transformer生成器,以更好地利用序列化的多模态特征。
-
SRDF(Wang et al., 2024c)构建了一个强大的指令生成器,通过迭代自训练来增强其性能。
-
5 VLN智能体:具身推理和规划
5.1 对齐和推理
-
与VQA和图像描述等其他视觉-语言任务不同,VLN智能体需要根据其动作来推理指令和环境中的空间和时间动态。
-
具体来说,智能体需要考虑之前的动作,识别要执行的子指令部分,并将文本与视觉环境对齐以执行相应的动作。
显式语义对齐
- 之前的方法通过显式的语义建模来增强智能体的对齐能力,包括:
-
在视觉和语言模态中对运动和地标进行建模(Hong et al., 2020b; He et al., 2021; Hong et al., 2020a; Zhang et al., 2021b; Qi et al., 2020a),
-
利用指令中的句法信息(Li et al., 2021),
-
以及空间关系(Zhang & Kordjamshidi, 2022b; An et al., 2021)。
-
-
然而,使用基础模型的研究较少探索在VLN智能体中进行显式对齐。Lin et al. (2023a)、Zhan et al. (2024a) 和 Wang et al. (2023b) 等研究提出了在VLN智能体中使用基础模型进行显式对齐的尝试。
预训练VLN基础模型
-
除了显式的语义建模外,之前的研究还通过辅助推理任务来增强智能体的对齐能力(Ma et al., 2019; Wu et al., 2021; Zhu et al., 2020; Raychaudhuri et al., 2021; Dou & Peng, 2022; Kim et al., 2021)。
-
这些方法在基础模型的VLN智能体中较少被探索,因为它们的预训练已经提供了对空间和时间语义的一般理解。
- 为了提高智能体的对齐能力,研究者们提出了各种预训练方法,设计专门的任务来增强这种能力:
-
Lin et al. (2021) 引入了专为场景和对象对齐设计的预训练任务。
-
LOViS (Zhang & Kordjamshidi, 2022a) 提出了两个专门的预训练任务,分别用于增强方向和视觉信息。
-
HOP (Qiao et al., 2022; 2023a) 引入了一个历史和顺序感知的预训练范式,强调历史信息和轨迹顺序。
-
Li & Bansal (2023) 建议通过增强智能体预测未来视图语义的能力来帮助其在较长路径导航中表现更好。
-
Dou et al. (2023) 设计了一个掩码路径建模目标,以重建给定随机掩码子路径的原始路径。
-
Cui et al. (2023) 提出了实体感知的预训练,通过预测对齐的实体并将其与文本对齐。
-
5.2 规划
-
动态规划使VLN智能体能够适应环境变化并实时改进导航策略。
-
除了基于图的规划器利用全局图信息来增强局部动作空间外,基础模型特别是大语言模型(LLMs)的兴起也带来了基于LLM的规划器进入VLN领域。
基于图的规划器
- 最近的研究强调了通过全局图信息来增强导航智能体的规划能力:
-
Wang et al. (2021); Chen et al. (2022c); Deng et al. (2020); Zheng et al. (2024b) 通过从访问节点的图前沿获取全局动作步骤来增强局部导航动作空间,以实现更好的全局规划。
-
Gao et al. (2023) 进一步通过高层次的区域选择和低层次的选择节点来进行高层次的规划,以增强导航决策。
-
Liu et al. (2023a) 通过为图前沿增加网格级动作来丰富全局和局部动作空间,以实现更准确的动作预测。
-
在连续环境中,Krantz et al. (2021); Hong et al. (2022); Anderson et al. (2021) 采用分层规划方法,通过从预测的局部可导航图中选择局部路点来替代低层次的规划。
-
CM2 (Georgakis et al., 2022) 通过在局部地图内对对齐指令来实现轨迹规划。
-
An et al. (2024; 2023); Wang et al. (2023g); Chang et al. (2024); Wang et al. (2022c) 构建全局拓扑图或网格地图,以促进基于地图的全局规划。
-
此外,Wang et al. (2023a; 2024a) 使用视频预测模型或神经辐射表示模型预测多个未来路点,以根据候选路点的长期效果计划最佳动作。
-
基于LLM的规划器
- 与此同时,一些研究利用LLMs的常识知识生成文本计划(Huang et al., 2022; 2023b):
-
LLM-Planner (Song et al., 2023) 创建详细的计划,由子目标组成,并根据检测到的对象动态调整这些计划。
-
Mic (Qiao et al., 2023b) 和 A2Nav (Chen et al., 2023b) 专注于将导航任务分解为详细的文本指令,Mic从静态和动态角度生成分步计划,而A2Nav使用GPT-3将指令解析为可操作的子任务。
-
ThinkBot (Lu et al., 2023) 使用思维链推理生成缺失的动作,与交互对象一起使用。
-
VL-Map (Huang et al., 2023a) 将导航指令分解为代码格式的序列化、目标相关函数,并使用代码编写的大语言模型来指导这些目标的执行。
-
此外,SayNav (Rajvanshi et al., 2024) 构建一个3D场景图作为输入到LLMs,以生成可行且上下文适当的高层次计划。
-
5.3 基于基础模型的VLN智能体
-
随着基础模型的出现,VLN智能体的架构经历了显著的变化。最初由Anderson et al. (2018) 概念化的VLN智能体是在Seq2Seq框架内构建的,使用LSTM和注意力机制来模拟视觉和语言模态之间的交互。
-
随着基础模型的出现,智能体的后端从LSTM过渡到Transformer,最近则转向这些大规模预训练系统。
VLMs作为智能体
-
主流方法是将单流VLMs作为VLN智能体的核心结构(Hong et al., 2021; Qi et al., 2021; Moudgil et al., 2021; Zhao et al., 2022)。
-
这些模型在每个时间步同时处理来自语言、视觉和历史标记器的输入。它通过对这些跨模态标记器进行自注意力来捕捉文本-视觉对应关系,然后用于推断动作概率。
-
在零样本VLN中,CLIP-NAV (Dorbala et al., 2022) 利用CLIP来获得自然语言指称表达,描述目标对象并做出顺序导航决策。
-
VLN-CE智能体(Krantz et al., 2020)与VLN-DE智能体(Anderson et al., 2018)的区别在于其动作空间,执行连续环境中的低级控制而不是基于图的高级动作选择。
-
尽管早期的工作(Krantz et al., 2020; Raychaudhuri et al., 2021)使用LSTM来推断低级动作,但引入路点预测器允许将方法从DE转移到CE(Krantz et al., 2021; Krantz & Lee, 2022; Hong et al., 2022; Anderson et al., 2021; An et al., 2022; Zhang & Kordjamshidi, 2024)。
-
所有这些方法都使用路点预测器来获得从智能体当前位置到可能的相邻路点的可导航候选路点,智能体选择一个作为当前目的地。
LLMs作为智能体
- 由于LLMs具有强大的推理能力和世界的语义抽象能力,并且在未知的大规模环境中表现出强大的泛化能力,最近的研究开始直接使用LLMs作为智能体来完成导航任务。通常,视觉观察被转换为文本描述并与指令一起输入到LLM中,然后执行动作预测。
-
NavGPT (Zhou et al., 2024a) 和MapGPT (Chen et al., 2024a) 展示了零样本导航的可行性,NavGPT使用GPT-4自主生成动作,MapGPT将拓扑地图转换为全局探索提示。
-
DiscussNav (Long et al., 2024b) 通过部署多个领域特定的VLN专家来自动化和减少人类在导航任务中的参与。它包括指令分析专家、视觉感知专家、完成估计专家和决策测试专家。
-
- 使用多个领域特定的VLN专家将任务分配给专门的智能体,减少了单个模型的负担,并允许优化、任务特定的处理。这种多专家方法通过利用多个大模型的集体优势来增强鲁棒性、透明度和整体性能。
-
MC-GPT (Zhan et al., 2024b) 采用记忆拓扑地图和人类导航示例来多样化策略,
-
而InstructNav (Long et al., 2024a) 将导航分解为子任务,并使用多源价值图进行有效执行。
-
- 相比之下,一些研究(Zheng et al., 2024a; Zhang et al., 2024a; Pan et al., 2024)通过微调LLMs来有效应对具身导航任务:
-
(Wei et al., 2022)结合了思维链(CoT)推理机制来改进推理过程。
-
Nav-CoT (Lin et al., 2024a) 将LLMs转变为世界模型和导航推理智能体,通过模拟未来环境来简化决策。
-
这展示了微调语言模型在仿真和真实世界场景中的灵活性和实际潜力,标志着传统应用的重大进步。
-
挑战和未来研究方向
6.1 基准数据集的挑战
数据和任务的局限性
-
当前的VLN数据集在质量、多样性、偏差和可扩展性方面存在局限性。
-
例如,R2R数据集中的指令-轨迹对偏向于最短路径,可能无法准确代表真实世界的导航场景。
-
未来的研究可以关注如何改进数据集的质量和多样性,以更好地反映真实世界的导航需求。
统一和真实的任务和平台
-
建立稳健的基准和确保可重复性对于在真实世界环境中评估VLN至关重要。需要一个通用的模拟到真实的评估平台,以便在模拟和真实环境中进行标准化的测试。
-
此外,任务和活动应设计得更加真实,以满足人类的需求。例如,BEHAVIOR-1K提供了一个虚拟、互动和生态的环境中的日常家庭活动的基准,以解决多样性和真实性的需求。
动态环境
-
现实世界环境复杂多变,包括移动物体、人员和光照、天气等变化因素,这些都可能破坏导航系统的视觉感知,使得保持可靠性能变得困难。
-
最近的研究如HAZARD、Habitat 3.0和HA-VLN考虑了动态环境,为研究提供了良好的起点。
从室内到室外
-
在室外环境中进行导航的研究也开始受到关注,例如自动驾驶和无人机。现有的语言引导数据集(如Sriram et al., 2019; Ma et al., 2022)已经开发出来。
-
早期研究尝试通过提示工程或微调LLMs来预测下一步动作或规划未来轨迹(Chen et al., 2024b; Mao et al., 2023)。
-
为了将现成的VLMs适应到这些户外导航领域,研究人员使用了真实世界的驾驶视频、模拟驾驶数据和两者的结合来进行指令调整。
6.2 世界模型的挑战
从2D到3D
-
VLN本质上是一个3D任务,智能体需要在3D环境中感知真实世界。尽管当前研究使用强大的2D表示来表示世界,但在3D世界中的空间语言理解仍然不足。
-
许多研究开发了显式的3D表示,如语义SLAM和体积表示、深度信息、Bird's-Eye-View表示和局部度量图。
-
然而,这些表示在开放词汇设置中仍然有限。最近出现的3D基础模型(如3D重建模型和3D多模态表示)可以为VLN提供更好的3D环境感知能力。
6.3 人类模型的挑战
从指令到对话
-
以前的研究主要采用说话者-听众范式或受限的问答对话,允许智能体在模糊或困惑的情况下请求帮助。
-
最近出现了新的基准,支持完全自由形式的通信,其中智能体可以在任何情况下询问、提议、解释、建议、澄清和协商。
-
未来的研究需要整合基础模型来进行情境任务导向的对话管理,或者探索现有的基础模型进行任务导向的对话。
6.4 智能体模型的挑战
适应基础模型进行VLN
-
尽管基础模型显示出强大的泛化能力,但将其应用于导航任务仍然具有挑战性。LLMs缺乏视觉感知实际环境的能力,容易产生幻觉。
-
未来的研究需要解决这些问题,以提高基础模型在导航任务中的应用效果。
缺乏具身经验
-
LLMs可能仅依赖预先建立的常识进行任务规划和推理,这可能无法满足特定真实世界的需求。
-
一些研究通过将视觉观察转化为文本描述来解决这个问题,但这可能会丢失重要的视觉语义。
-
VLM智能体虽然能够感知视觉世界并进行规划,但它们主要从互联网数据中开发,缺乏具身经验,需要进行微调以实现鲁棒的智能体决策。
幻觉问题
-
LLMs和VLMs可能会生成不存在的对象,导致错误的信息。例如,当LLM进行任务规划时,可能会生成诸如“向前走并在沙发处左转”这样的指令,即使房间中没有沙发。
-
这种不准确性可能导致执行错误的或不可能的动作。
LLMs在规划和推理中的应用
-
尽管有一些文献评估了LLMs在更复杂的规划任务中的零样本推理和规划能力,但这些工作突显了LLMs在某些方面的局限性,如幻觉或未能掌握复杂规划问题的关系结构。
-
在VLN任务中,LLMs的角色不是取代整个规划过程,而是通过提供结构化的指令分解来辅助导航。
6.5 从模拟到真实机器人的部署
- 模拟环境往往缺乏真实环境的复杂性和可变性,较低的渲染图像质量加剧了这一问题。
-
首先,感知差距导致性能和准确性的下降,凸显了对更强大感知系统的需求。
-
此外,模拟到真实的应用中存在具身差距和数据稀缺的问题。
-
-
机器人配送技术的兴起也为在真实人类-机器人交互中扩展VLN数据提供了替代方案。
总结
-
论文总结了基础模型在视觉和语言导航任务中的应用,并提出了未来研究的方向。
-
基础模型在多模态理解、推理和跨域泛化方面展示了卓越的性能,特别是在VLN任务中。
-
尽管存在一些局限性,如数据和任务的限制、动态环境的复杂性以及从模拟到真实机器人的部署挑战,基础模型仍然为VLN研究提供了新的机会和解决方案。
-
未来的研究应继续探索改进基准测试、处理动态环境和从模拟到真实机器人的部署等方向。


















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









