







VLN算法学习:GridMM——使用网格记忆图来表征历史轨迹中的场景空间关系GridMM: Grid Memory Map for VLN
【VLN入门介绍】
一文搞懂视觉语言导航,从任务介绍到基本算法讲解:https://blog.csdn.net/qq_50001789/article/details/144676313
【VLN算法笔记】
DUET(CVPR2022),首篇使用Transformer来建模全局图节点相关性的工作:https://blog.csdn.net/qq_50001789/article/details/144632851
AZHP(CVPR2023),使用自适应区域分层规划器来实现层次化导航的目的:https://blog.csdn.net/qq_50001789/article/details/144635128
GridMM(ICCV2023),使用网格记忆图来表征历史轨迹中的场景空间关系:https://blog.csdn.net/qq_50001789/article/details/144652403
【VLN辅助任务】
MLM、SAP、SAR、SPREL——预训练、微调中常用的提点策略:https://blog.csdn.net/qq_50001789/article/details/144633984
【VLN环境配置】
Matterport3DSimulator——用于视觉语言导航算法研发的仿真环境配置:https://blog.csdn.net/qq_50001789/article/details/142621259
综述
论文题目:《GridMM: Grid Memory Map for Vision-and-Language Navigation》
源码链接:https://github.com/MrZihan/GridMM
论文出处:ICCV23,蒋树强老师团队
背景
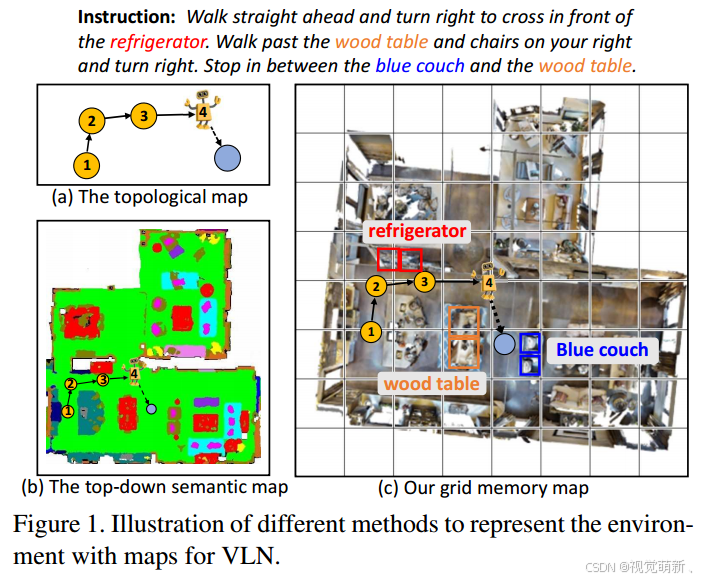
在视觉语言导航中,历史信息在环境理解中起着重要的作用,在以前的任务中,大多使用隐藏层编码特征来存储历史信息,将历史观测和动作一起编码到固定大小的状态向量中。然而,这种“浓缩”状态特征可能不足以捕捉轨迹历史中的基本信息。为了构建历史轨迹中的环境编码特征,并进行全局规划,DUET算法利用观测节点的特征构建全局拓扑图(如图1(a)所示),然而,这类方法有很多问题:
-
全局拓扑图特征很难表示历史观测中物体和场景之间的空间关系,因此丢失了大量的细节信息;
-
有一部分工作使用自上而下(top-down)的语义图对导航环境进行建模,从而更精确地表示空间关系,但是,由于预定义的语义标签非常有限,因此先前的语义标签中未包含的对象或者场景无法表示;
-
全局拓扑图的节点特征缺少对象属性的特征(例如“木桌”、“蓝色沙发”),因此难以表征具有多种属性的对象(其实就是缺少对象级特征object-level)。
主要思想
本算法同时使用RGB图像和深度图来观测每一个节点的环境信息,作者提出了一种网格记忆图(Grid Memory Map, GridMM),用于在导航过程中对全局历史观测的场景空间关系进行建模,利用时间和空间信息来描述全局访问环境。具体地来说,网格地图将访问环境划分为许多大小相等的网格区域,每个网格区域包含许多细粒度的视觉特征,我们动态地构建网格存储库,从而在导航过程中更新网格地图。在导航的每一步,利用CLIP提取的视觉特征都会保存到存储库中,之后我们根据深度图的深度信息计算坐标,根据坐标数据将所有的视觉特征分类到网格地图区域中。为了获得每个区域的特征表示,作者设计了一种指令相关的聚合方法(instruction relevance aggregation)来捕获与指令最相关的视觉特征,并将他们聚合为一个整体特征。借助聚合的 N × N N\times N N×N地图特征,智能体能够准确地进行下一步的行动决策。
方法
注:为了方便描述,后文均用第一人称来描述具体的操作步骤。
网格记忆图
在每个导航步骤
t
t
t中,我们首先将细粒度的视觉特征及其对应的坐标存储在网格记忆(grid memory)中。对于RGB全景图
R
t
=
{
r
t
,
k
}
k
=
1
K
\mathcal R_t=\{r_{t,k}\}^K_{k=1}
Rt={rt,k}k=1K,我们使用预训练的CLIP-ViT-B/32模型来提取网格特征
G
t
=
{
g
t
,
k
∈
R
H
×
W
×
D
}
G_t=\{g_{t,k}\in\mathbb R^{H\times W\times D}\}
Gt={gt,k∈RH×W×D},第
h
h
h行和
w
w
w列的网格特征表示为
g
t
,
k
,
h
,
w
∈
R
D
g_{t,k,h,w}\in\mathbb R^D
gt,k,h,w∈RD,之后将对应的深度图像
D
t
\mathcal D_t
Dt下采样到相同的尺度
D
t
′
=
{
d
t
,
k
′
∈
R
H
×
W
}
k
=
1
K
\mathcal D'_t=\{d'_{t,k}\in\mathbb R^{H\times W}\}^K_{k=1}
Dt′={dt,k′∈RH×W}k=1K,第
h
h
h行和第
w
w
w列特征位置的深度数值表示为
d
t
,
k
,
h
,
w
′
d_{t,k,h,w}'
dt,k,h,w′。为了方便起见,我们将所有的下标
(
k
,
h
,
w
)
(k,h,w)
(k,h,w)表示为
i
i
i,其中
i
i
i的取值范围为
1
1
1到
I
I
I,
I
=
K
⋅
H
⋅
W
I=K\cdot H\cdot W
I=K⋅H⋅W,
g
t
,
k
,
h
,
w
g_{t,k,h,w}
gt,k,h,w可以表示为
g
^
t
,
i
\hat{g}_{t,i}
g^t,i,
d
t
,
k
,
h
,
w
d_{t,k,h,w}
dt,k,h,w可以表示为
d
^
t
,
i
\hat{d}_{t,i}
d^t,i,我们可以利用如下公式计算
g
^
t
,
j
\hat{g}_{t,j}
g^t,j的绝对坐标
P
(
g
^
t
,
i
)
P(\hat{g}_{t,i})
P(g^t,i):
P
(
g
^
t
,
i
)
=
(
x
t
,
i
,
y
t
,
i
)
=
(
X
t
+
d
t
,
i
l
i
n
e
⋅
c
o
s
(
θ
t
,
i
)
,
Y
t
+
d
t
,
i
l
i
n
e
⋅
s
i
n
(
θ
t
,
i
)
)
P(\hat{g}_{t,i})=(x_{t,i},y_{t,i})\\ =(\mathcal X_t+d_{t,i}^{line}\cdot cos(\theta_{t,i}),\mathcal Y_t+d_{t,i}^{line}\cdot sin(\theta_{t,i}))
P(g^t,i)=(xt,i,yt,i)=(Xt+dt,iline⋅cos(θt,i),Yt+dt,iline⋅sin(θt,i))
其中
(
X
t
,
Y
t
)
(\mathcal X_t,\mathcal Y_t)
(Xt,Yt)表示智能体当前的坐标,
θ
t
,
i
\theta_{t,i}
θt,i表示
g
^
t
,
i
\hat{g}_{t,i}
g^t,i与智能体当前方向之间的航向角(水平角度,heading),
d
t
,
i
l
i
n
e
d^{line}_{t,i}
dt,iline表示
g
^
t
,
i
\hat g_{t,i}
g^t,i与智能体之间的欧氏距离,可以通过
d
^
t
,
i
\hat{d}_{t,i}
d^t,i和
θ
t
,
i
\theta_{t,i}
θt,i来计算。我们将所有这些网格特征及其绝对坐标存储在网格存储器中:
M
t
=
M
t
−
1
∪
{
[
g
^
t
,
i
,
P
(
g
^
t
,
i
)
]
}
i
=
1
I
\mathcal M_t=\mathcal M_{t-1}\cup\{[\hat{g}_{t,i},P(\hat{g}_{t,i})]\}^I_{i=1}
Mt=Mt−1∪{[g^t,i,P(g^t,i)]}i=1I
然后,我们提出了一种动态坐标变换方法,利用网格记忆
M
t
\mathcal M_t
Mt中的视觉特征构建网格记忆地图(grid memory map),如图3(a)所示,通过将所有的历史观测
g
^
t
,
i
\hat g_{t,i}
g^t,i投影到基于绝对坐标的统一地图中,我们可以以一个统一的特征框架来表征所访问的环境。然而, 这种绝对坐标下的地图主要有两个缺点:
- 将候选的观测和指令与绝对坐标的对齐难度比较高;
- 如果没有关于环境的先验信息,很难确定地图的尺度和范围,很难建立起绝对坐标系下的地图数据。
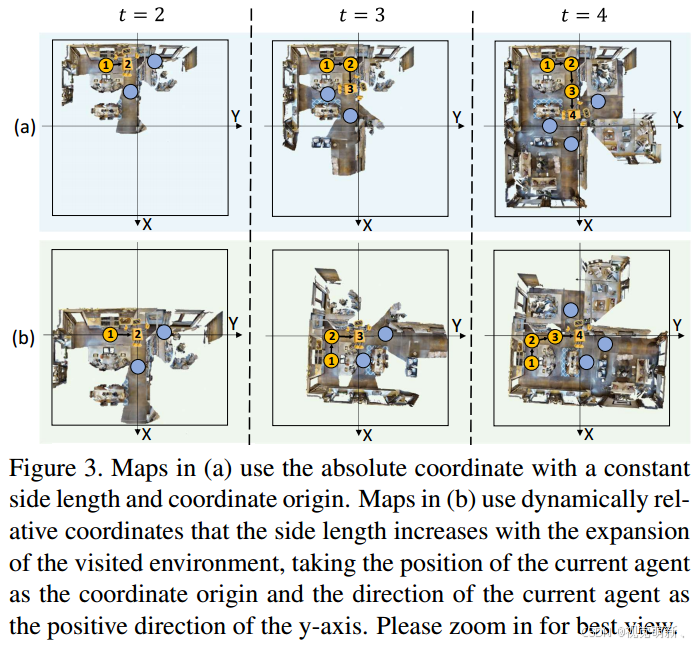
为了解决这些不足,我们提出了一种新的映射方法来构建自顶向下、以自我为中心的动态增长的地图,如图3(b)所示,在每一步中,我们通过将网格记忆
M
t
\mathcal M_t
Mt的所有特征投影到一个新的平面迪卡尔坐标系中,以智能体的位置作为坐标原点,以智能体当前的方向作为y轴的正方向。在新的坐标系中,对于网格记忆
M
t
\mathcal M_t
Mt中的每个网格特征
g
^
s
,
i
\hat g_{s,i}
g^s,i,我们可以利用如下公式在时间步
t
t
t上计算一个新的相对坐标
P
t
r
e
l
(
g
^
s
,
i
)
P^{rel}_t(\hat g_{s,i})
Ptrel(g^s,i):
P
t
r
e
l
(
g
^
s
,
i
)
=
(
x
s
,
i
r
e
l
,
y
s
,
i
r
e
l
)
=
(
(
x
s
,
i
−
X
t
)
⋅
c
o
s
Θ
t
+
(
y
s
,
i
−
Y
t
)
⋅
s
i
n
Θ
t
,
(
y
s
,
i
−
Y
t
)
⋅
c
o
s
Θ
t
−
(
x
s
,
i
−
X
t
)
⋅
s
i
n
Θ
t
)
\begin{aligned} P_{t}^{rel}&(\hat{g}_{s,i})=(x_{s,i}^{rel}\:,\:y_{s,i}^{rel})\\ =&(\:(x_{s,i}-\mathcal{X}_t)\cdot cos\Theta_t+(y_{s,i}-\mathcal{Y}_t)\cdot sin\Theta_t\:,\\ &(y_{s,i}-\mathcal{Y}_t)\cdot cos\Theta_t-(x_{s,i}-\mathcal{X}_t)\cdot sin\Theta_t\:)\\ \end{aligned}
Ptrel=(g^s,i)=(xs,irel,ys,irel)((xs,i−Xt)⋅cosΘt+(ys,i−Yt)⋅sinΘt,(ys,i−Yt)⋅cosΘt−(xs,i−Xt)⋅sinΘt)
其中,
Θ
t
\Theta_t
Θt表示新坐标系和旧坐标系之间的航向角(heading angle)。进一步地,我们通过网格特征及其新坐标来构建网格记忆图(Grid Memory Map, GridMM),在第
t
t
t步中,网格记忆图取
L
t
L_t
Lt作为边长:
L
t
=
2
⋅
m
a
x
(
m
a
x
(
{
{
∣
x
s
,
i
r
e
l
∣
}
i
=
1
I
}
s
=
1
t
)
,
m
a
x
(
{
{
∣
y
s
,
i
r
e
l
∣
}
i
=
1
I
}
s
=
1
t
)
)
L_{t}=2\cdot max(\:max(\{\{|x_{s,i}^{rel}|\}_{i=1}^{I}\}_{s=1}^{t})\:, max(\{\{|y_{s,i}^{rel}|\}_{i=1}^{I}\}_{s=1}^{t})\:)
Lt=2⋅max(max({{∣xs,irel∣}i=1I}s=1t),max({{∣ys,irel∣}i=1I}s=1t))
GridMM的大小随着访问环境的扩大而增大,智能体总是在这个地图的中心,地图在以自我为中心的视图中与当前的全景观测对齐,之后将地图划分为
N
×
N
N\times N
N×N单元,根据新的相对坐标将
M
t
\mathcal M_t
Mt中所有的特征投影到这些单元中。最后,利用
N
×
N
N\times N
N×N的单元格构建网格记忆GridMM,每个单元格包含多个细粒度的视觉特征。将每个cell中的所有视觉特征聚合到一个嵌入向量中,得到图特征
M
t
∈
R
N
×
N
×
D
M_t\in \mathbb R^{N\times N\times D}
Mt∈RN×N×D,详细的聚合方法可参考图记忆编码小节。
模型结构
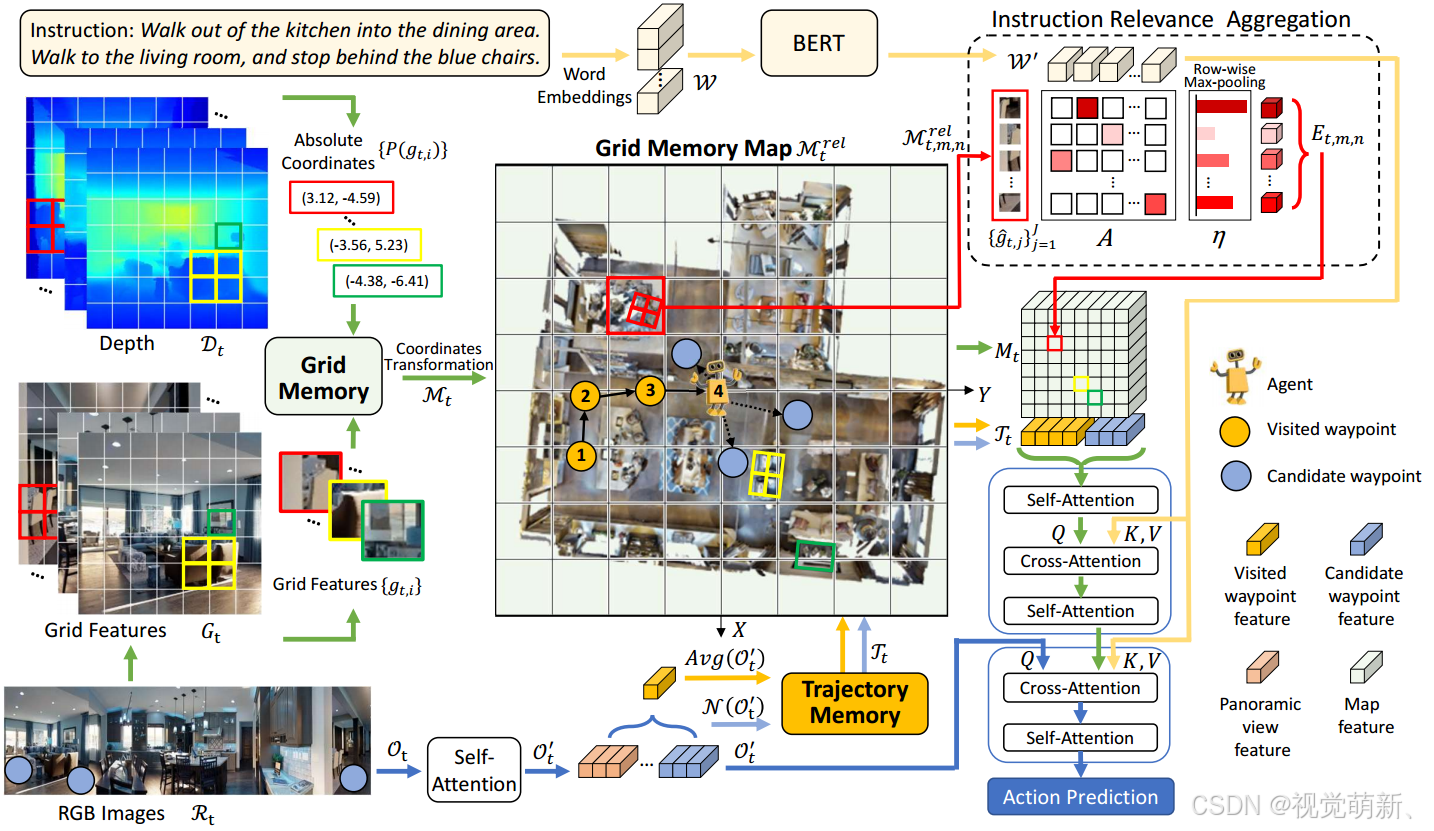
指令和观测编码
对于指令编码, W \mathcal W W中的每个单词向量先加一个位置编码和token类型编码,所有的单词token传入一个多层transformer模块来获得单词表征,可以表示为 W ′ = { w l ′ } l = 1 L \mathcal W'=\{w_l'\}^L_{l=1} W′={wl′}l=1L。
视觉观测编码可以表示为:
O
t
=
L
N
(
W
1
O
[
R
t
′
;
N
(
R
t
′
)
]
)
+
L
N
(
W
2
O
[
a
t
;
b
t
;
c
t
;
e
t
]
)
\mathcal O_t=LN(W_1^{\mathcal O}[\mathcal R_t';\mathcal N(\mathcal R_t')])+LN(W_2^{\mathcal O}[a_t;b_t;c_t;e_t])
Ot=LN(W1O[Rt′;N(Rt′)])+LN(W2O[at;bt;ct;et])
其中参数的意义分别为:
- R t ′ \mathcal R_t' Rt′:全景观测的视觉图像 R t \mathcal R_t Rt,使用在ImageNet上预训练的ViT-B/16提取的视觉特征表示为 R t ′ \mathcal R'_t Rt′;
- N ( R t ′ ) \mathcal N(\mathcal R_t') N(Rt′):候选路径点的观测特征(The candidate waypoints)
- a t a_t at:视图的相对角度编码, a t = ( s i n θ t a , c o s θ t a , s i n φ t a , cos φ t a ) a_t=(sin\theta^a_t,cos\theta^a_t,sin\varphi^a_t,\cos\varphi^a_t) at=(sinθta,cosθta,sinφta,cosφta),其中 θ t a \theta^a_t θta和 φ t a \varphi^a_t φta是相对于智能体当前方向的航角(heading)和仰角(elevation);
- b t b_t bt:可观测路径点与当前智能体之间的线距离;
- c t c_t ct:智能体和起始点的相对角度编码, c t = ( s i n θ t c , c o s θ t c , s i n φ t c , cos φ t c ) c_t=(sin\theta^c_t,cos\theta^c_t,sin\varphi^c_t,\cos\varphi^c_t) ct=(sinθtc,cosθtc,sinφtc,cosφtc);
- e t e_t et: e t = ( d i s t l i n e ( V 0 , V t ) + d i s t t r a j ( V 0 , V t ) + d i s t s t e p ( V 0 , V t ) ) e_t=(dist_{line}(\mathcal V_0, \mathcal V_t)+dist_{traj}(\mathcal V_0,\mathcal V_t)+dist_{step}(\mathcal V_0,\mathcal V_t)) et=(distline(V0,Vt)+disttraj(V0,Vt)+diststep(V0,Vt)), d i s t l i n e dist_{line} distline表示智能体与起始点之间的直线距离, d i s t t r a j dist_{traj} disttraj表示轨迹长度, d i s t s t e p dist_{step} diststep表示动作步长;
- L N LN LN表示归一化层, W 1 O W^{\mathcal O}_1 W1O和 W 2 O W^{\mathcal O}_2 W2O为可学习的参数
之后将一个"stop"token O t , 0 \mathcal O_{t,0} Ot,0添加到 O t \mathcal O_t Ot,之后传入两层transformer做特征映射,得到 O t ′ \mathcal O'_t Ot′
图记忆编码
在导航的每一步,我们需要将每个单元格中的多个网格特征居合道一个编码向量(embedding vector)中。由于导航环境的复杂性,每个单元格区域内的大量网格特征并不都是智能体完成导航所需要的,智能体需要更多地与当前指令高度相关的关键信息来理解环境,因此,我们提出了一种指令关联方法来聚合每个单元中的特征。具体地来说,对于每个单元格cell中的网格特征
M
t
,
m
,
n
r
e
l
=
{
g
^
t
,
j
∈
R
D
}
j
=
1
J
\mathcal M^{rel}_{t,m,n}=\{\hat g_{t,j}\in\mathbb R^D\}^J_{j=1}
Mt,m,nrel={g^t,j∈RD}j=1J,其中对应的坐标
{
P
r
e
l
(
g
^
t
,
j
)
}
j
=
1
J
\{P^{rel}(\hat g_{t,j})\}^J_{j=1}
{Prel(g^t,j)}j=1J都在第
m
m
m行、第
n
n
n列的单元格cell内,单元格内的特征总数为
J
J
J,我们通过计算相关矩阵
A
A
A来评估每个网格特征与导航指令的相关性:
A
=
(
M
t
,
m
,
n
r
e
l
W
1
A
)
(
W
′
W
2
A
)
T
A=(\mathcal M^{rel}_{t,m,n}W^A_1)(\mathcal W'W^A_2)^T
A=(Mt,m,nrelW1A)(W′W2A)T
其中
W
1
A
W^A_1
W1A和
W
2
A
W^A_2
W2A为可学习的参数。之后,我们在A上计算逐行的最大池化,用于评估每个网格特征与指令的相关性:
a
j
=
m
a
x
(
{
A
j
,
l
}
l
=
1
L
)
a_j=max(\{A_{j,l}\}^L_{l=1})
aj=max({Aj,l}l=1L)
最后,我们将每个单元格内的网格特征聚合成一个编码向量
E
t
,
m
,
n
E_{t,m,n}
Et,m,n:
η
=
s
o
f
t
m
a
x
(
{
α
j
}
j
=
1
J
)
E
t
,
m
,
n
=
∑
j
=
1
J
η
j
(
W
E
g
^
t
,
j
)
\eta=softmax(\{\alpha_j\}^J_{j=1})\\ E_{t,m,n}=\sum^J_{j=1}\eta_j(W^E\hat g_{t,j})
η=softmax({αj}j=1J)Et,m,n=j=1∑Jηj(WEg^t,j)
其中
W
E
W^E
WE为可学习的参数,为了表示空间关系,我们在网格记忆图中引入了位置信息,具体地来说,在每个单元中心和智能体之间,我们表示线距离为
q
t
M
q^M_t
qtM,表示相对航角位
h
t
M
=
(
s
i
m
Φ
t
M
,
c
o
s
Φ
t
M
)
h^M_t=(sim\Phi^M_t,cos\Phi^M_t)
htM=(simΦtM,cosΦtM),图特征可以表示为:
M
t
=
L
N
(
E
t
)
+
L
N
(
W
M
[
q
t
M
;
h
t
M
]
)
M_t=LN(E_t)+LN(W^M[q^M_t;h^M_t])
Mt=LN(Et)+LN(WM[qtM;htM])
其中
W
M
W^M
WM为可学习的参数。
导航轨迹编码
为了实施全局动作规划,我们进一步GridMM中引入导航轨迹编码模块(类似于DUET算法), 在时间步
t
t
t处,智能体接收到路径点
V
t
\mathcal V_t
Vt处的全景图像特征
O
t
′
\mathcal O_t'
Ot′,之后对
O
t
′
\mathcal O_t'
Ot′做全局平均池化(沿视图方向做平均池化),得到当前点的视觉表征
A
v
g
(
O
t
′
)
Avg(\mathcal O_t')
Avg(Ot′)。由于智能体也可以部分地观测到候选点,因此我们使用包含这些可导航路点的视图图像特征
N
(
O
t
′
)
\mathcal N(\mathcal O_t')
N(Ot′)作为他们的部分视觉表征。在路径点和当前智能体之间,我们使用
q
T
q^{\mathcal T}
qT表示线距离,使用
h
t
T
=
(
s
i
n
Φ
t
T
,
c
o
s
Φ
t
T
)
h^{\mathcal T}_t=(sin\Phi^{\mathcal T}_t,cos\Phi^{\mathcal T}_t)
htT=(sinΦtT,cosΦtT)表示相对的航角(heading),使用
u
T
u^{\mathcal T}
uT表示动作步编码(action step embedding),所有的历史点特征
{
A
v
g
(
O
t
′
}
i
=
1
t
−
1
\{Avg(\mathcal O_t'\}^{t-1}_{i=1}
{Avg(Ot′}i=1t−1,当前点的特征
A
u
g
(
O
t
′
)
Aug(\mathcal O_t')
Aug(Ot′)和候选点特征
N
(
O
t
′
)
\mathcal N(\mathcal O_t')
N(Ot′)共同组成导航轨迹:
T
t
=
[
{
L
N
(
A
v
g
(
O
i
′
)
)
+
L
N
(
W
1
T
[
q
i
T
;
h
i
T
]
)
+
u
i
T
}
i
=
1
t
;
L
N
(
N
(
O
t
′
)
)
+
L
N
(
W
2
T
[
q
N
T
;
h
N
T
]
)
+
u
N
T
]
\mathcal{T}_{t}=[\{LN(Avg(\mathcal{O}_i^{^{\prime}}))+LN(W_1^{\mathcal{T}}[q_i^{\mathcal{T}};h_i^{\mathcal{T}}])+u_i^{\mathcal{T}}\}_{i=1}^t;\\ LN(\mathcal{N}(\mathcal{O}_t^{^{\prime}}))+LN(W_2^{\mathcal{T}}[q_{\mathcal{N}}^{\mathcal{T}};h_{\mathcal{N}}^{\mathcal{T}}])+u_{\mathcal{N}}^{\mathcal{T}}]
Tt=[{LN(Avg(Oi′))+LN(W1T[qiT;hiT])+uiT}i=1t;LN(N(Ot′))+LN(W2T[qNT;hNT])+uNT]
其中
W
1
T
W^{\mathcal T}_1
W1T和
W
2
T
W^{\mathcal T}_2
W2T分别表示可学习的参数,“stop” token
T
t
,
0
\mathcal T_{t,0}
Tt,0被加入到
T
t
\mathcal T_t
Tt中,用于预测停止动作。
跨模态推理
下图中 M t \mathcal M_t Mt为提取的特征集合, M t r e l \mathcal M^{rel}_{t} Mtrel为相对坐标下的投影特征, M t , m , n r e l \mathcal M^{rel}_{t,m,n} Mt,m,nrel为 M t r e l \mathcal M^{rel}_t Mtrel中一个cell内的子集, M t M_t Mt是聚合后得到的特征图
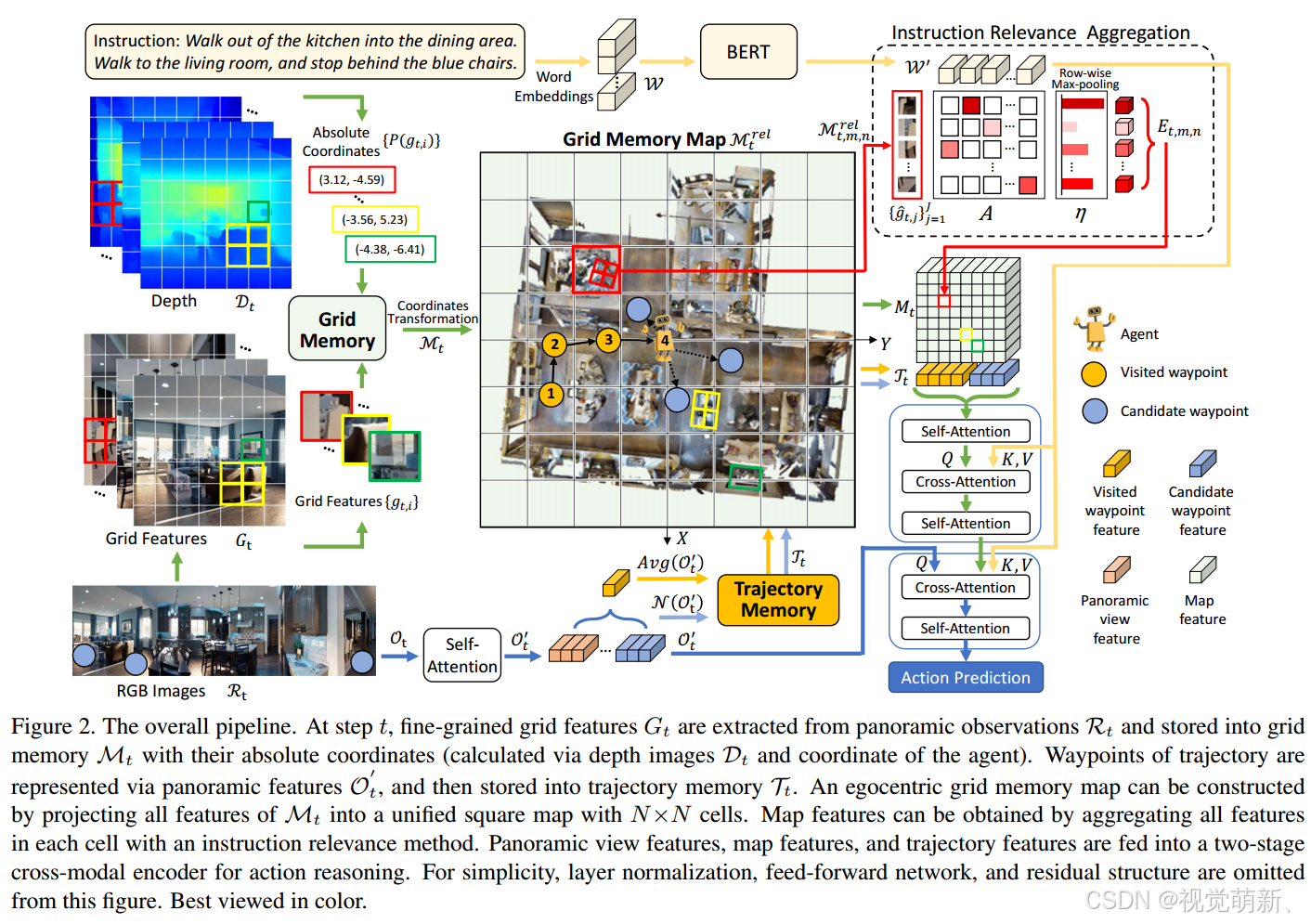
如图2所示,我们将网格图特征和导航轨迹相连接 [ M t ; T t ] [M_t;\mathcal T_t] [Mt;Tt],之后使用跨模态transformer将指令特征 W ′ \mathcal W' W′和 [ M t ; T t ] [M_t;\mathcal T_t] [Mt;Tt]融合,建模时空关系,生成 [ M t ′ ; T t ′ ] [M'_t;\mathcal T'_t] [Mt′;Tt′],在这里使用历史环境推理损失(Historical environment reasoning, HER)来优化该模块,损失的定义可见后文。
随后,使用4层跨模态transformer来建模视觉语言关系和时空关系。具体地来说,每个transformer层包括一个交叉注意力层和一个自注意力层,对于交叉注意力层,我们输入全景观测和导航轨迹编码 [ O t ′ ; T t ′ ] [\mathcal O_t';\mathcal T_t'] [Ot′;Tt′]作为查询向量,查询指令编码、导航轨迹编码、网格图特征 [ W t ′ ; T t ′ ; M t ′ ] [\mathcal W_t';\mathcal T_t';M_t'] [Wt′;Tt′;Mt′]。之后,自注意力层将全景观测编码和导航轨迹编码 [ O t ′ ; T t ′ ] [\mathcal O_t';\mathcal T'_t] [Ot′;Tt′]作为输入,输出表示为 [ O t ^ ; T t ^ ] [\hat{\mathcal O_t};\hat {\mathcal T_t}] [Ot^;Tt^]。
动作预测
流程图如下图所示:
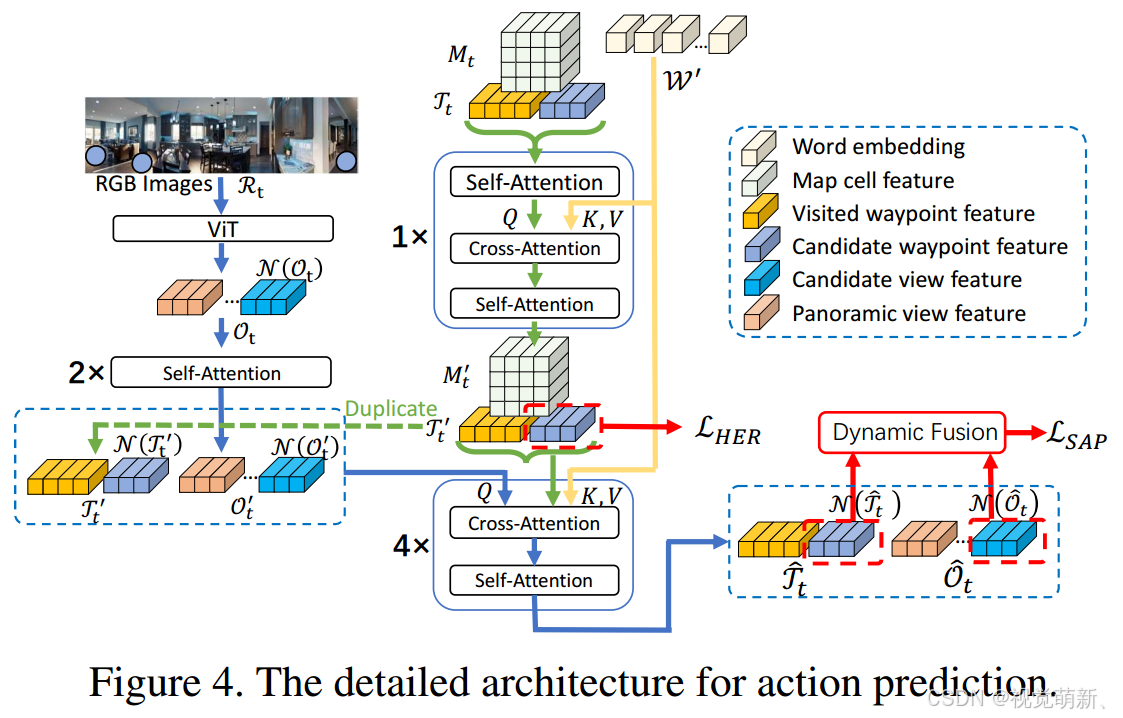
我们基于候选观测
N
(
O
^
t
)
\mathcal N(\hat O_t)
N(O^t)来预测局部导航分数:
S
t
O
=
F
F
N
(
N
(
O
^
t
)
)
S^{\mathcal O}_t=FFN(\mathcal N(\hat {\mathcal O}_t))
StO=FFN(N(O^t))
之后利用候选的可导航点
N
(
T
^
t
)
\mathcal N(\hat {\mathcal T}_t)
N(T^t)来预测全局导航分数:
S
t
T
=
F
F
N
(
N
(
T
^
t
)
)
S^{\mathcal T}_t=FFN(\mathcal N(\hat {\mathcal T}_t))
StT=FFN(N(T^t))
其中
F
F
N
FFN
FFN为两层前馈网络,
S
t
,
0
O
S^{\mathcal O}_{t,0}
St,0O和
S
t
,
0
T
S^{\mathcal T}_{t,0}
St,0T均为停止分数,在预测局部和全局动作分数时,我们使用两个独立的
F
F
N
FFN
FFN预测动作分数,之后参考DUET算法将两个动作分数做融合:
S
t
f
u
s
i
o
n
=
λ
t
S
t
O
+
(
1
−
λ
t
)
S
t
T
λ
t
=
s
i
g
m
o
i
d
(
F
F
N
(
[
O
t
,
0
^
;
T
^
t
,
0
]
)
)
S^{fusion}_t=\lambda_tS^{\mathcal O}_t + (1-\lambda_t)S^{\mathcal T}_t\\ \lambda_t=sigmoid(FFN([\hat{\mathcal O_{t,0}};\hat{\mathcal T}_{t,0}]))
Stfusion=λtStO+(1−λt)StTλt=sigmoid(FFN([Ot,0^;T^t,0]))
预训练、微调
预训练
根DUET类似,使用演示路径来进行预训练,使用常见的辅助任务损失:MLM、MVM(又称MRC)、SAP(与DUET一样)。
此外, 本文还使用历史环境推理损失(Historical Environment Reasoning, HER):需要智能体仅根据地图特征和导航轨迹特征来预测下一个动作,而不需要当前的全景观测:
S
t
H
E
R
=
F
F
N
(
N
(
T
t
′
)
)
L
H
E
R
=
∑
t
=
1
T
C
r
o
s
s
E
n
t
r
o
p
y
(
S
t
H
E
R
,
A
t
)
S^{HER}_t=FFN(\mathcal N(\mathcal T'_t))\\ \mathcal L_{HER}=\sum^T_{t=1}CrossEntropy(S^{HER}_t,\mathcal A_t)
StHER=FFN(N(Tt′))LHER=t=1∑TCrossEntropy(StHER,At)
微调
这里采用Dagger训练策略,使用伪交互演示器来进行微调,该演示器选择从当前航路点到目的地总体距离最短的可导航航路点作为下一个目标。
实验结果
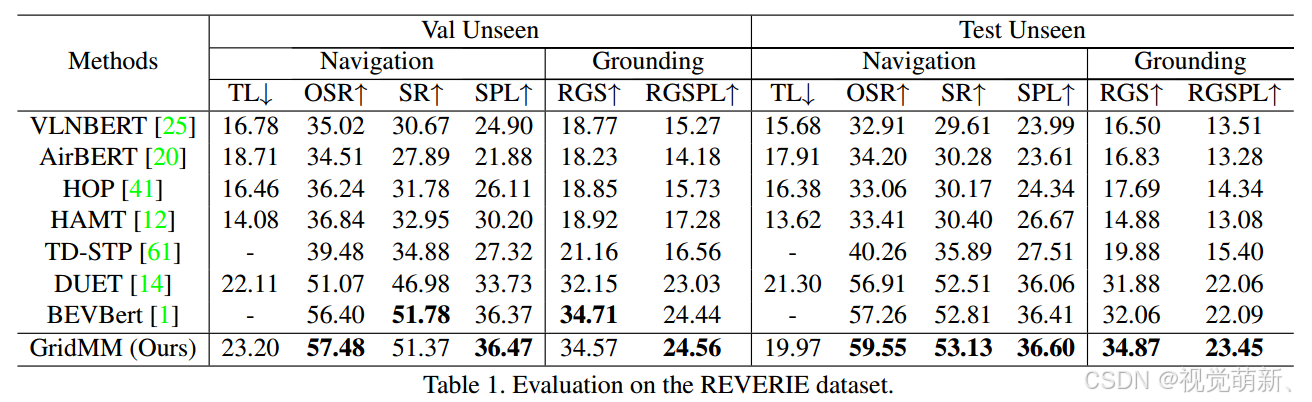
REVERIE数据集
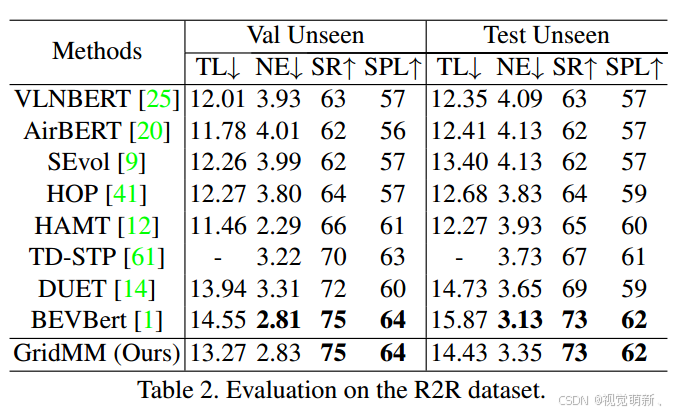
R2R数据集
注:以上仅是笔者个人见解,若有问题,欢迎指正。



















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











