







VLN阶段性小结2023.1.10
- 1,ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
- 2,ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts(CVPR2022)
- 3,CLIP-NAV: USING CLIP FOR ZERO-SHOT VISION-AND-LANGUAGE NAVIGATION
- 4,ENVEDIT: Environment Editing for Vision-and-Language Navigation(CVPR2022)
- 5,LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
- 6,SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments-2021
- 7,LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
- 8,BEVBert: Topo-Metric Map Pre-training for Language-guided Navigation
- 9,HOP+: History-and-Order Aware Pre-training for Vision-and-Language Navigation(CVPR2022)
本文简单总结了近期的VLN任务方法
最近的许多VLN任务都或多或少地应用了CLIP和GPT-3技术,zero-shot似乎给了之前的视觉对话导航一些提示,提问不再基于给定的模板。
一些VLN论文认为,VLN中语义很重要,另一些觉得环境信息较少需要进行数据增强
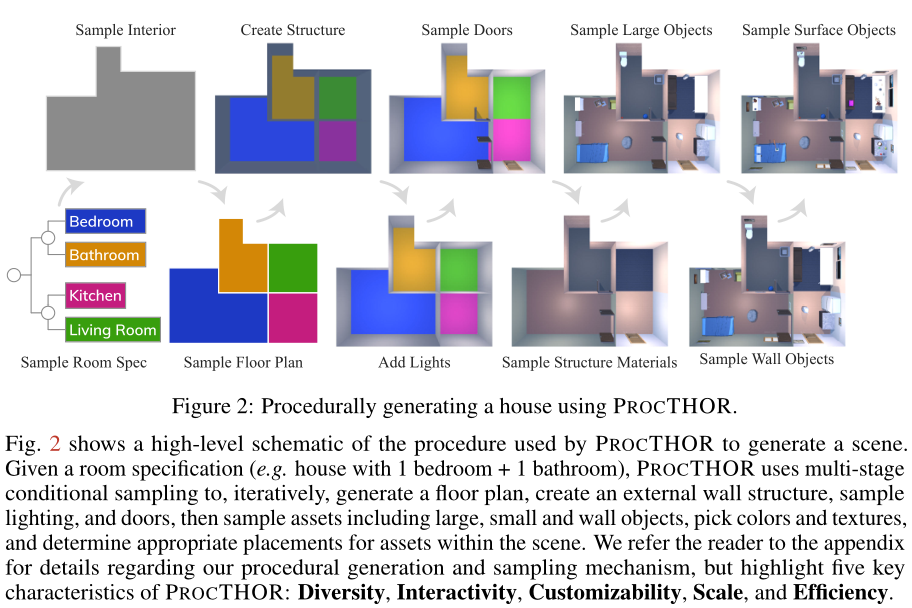
1,ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
海量数据集和高容量模型推动了计算机视觉和自然语言领域的进展。本文试图提出一个程序生成的框架来在embodied AI上取得成功。

具体来说,本文有三个主要贡献:
1): 提出了一个允许无限数量的多样化的、完全交互的模拟环境的性能程序生成的框架,(2)ARCHITECTHOR,一套新的3D艺术设计的用于embodied-AI评估的房屋,
以及(3)横跨六个E-AI基准的SoTA结果,涵盖操作和导航任务,包括强zero-shot结果。PROCTHOR将是开源的,在这项工作中使用的代码将被发布:https://procthor.allenai.org/
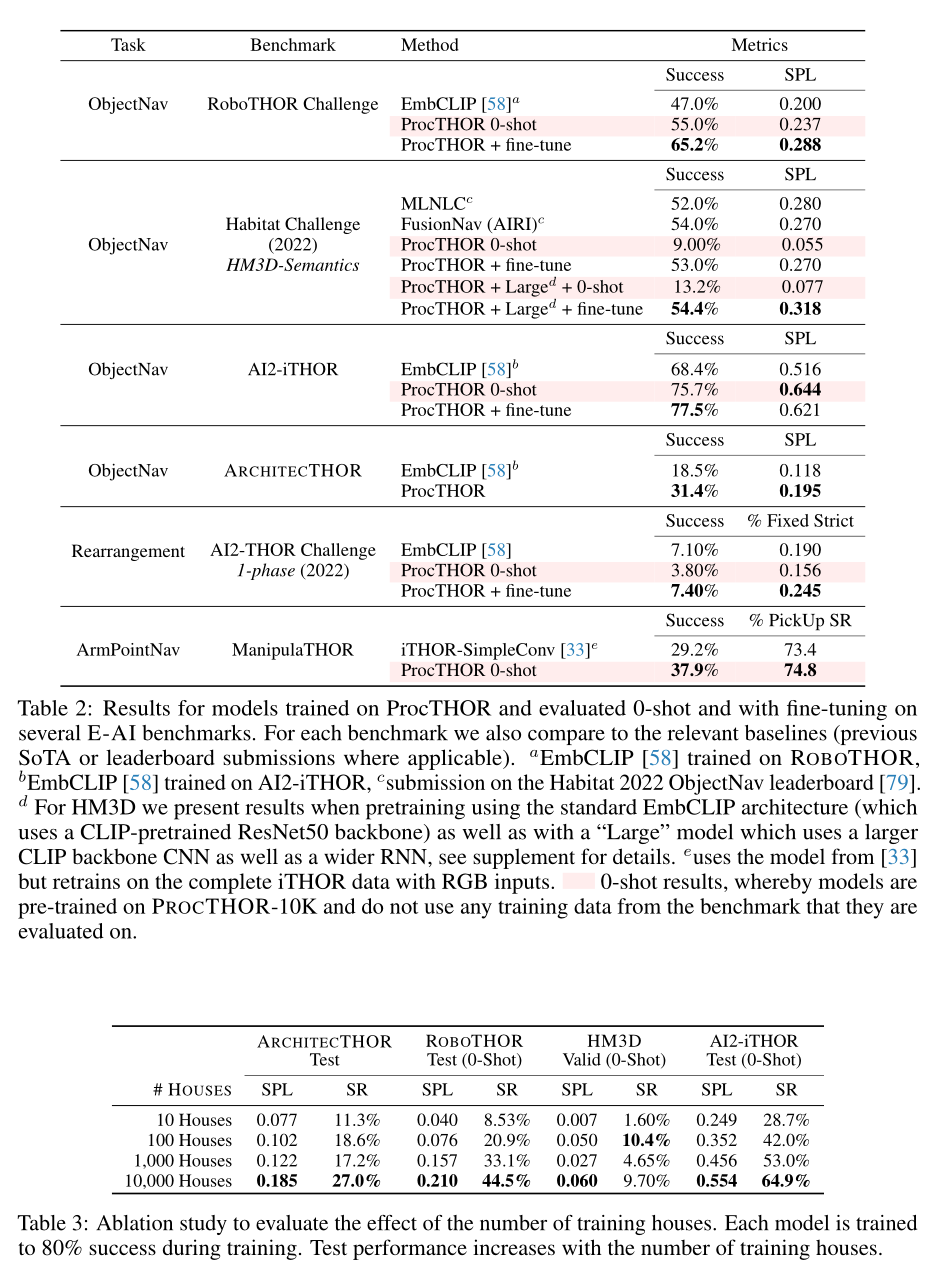
一些实验结果如下:
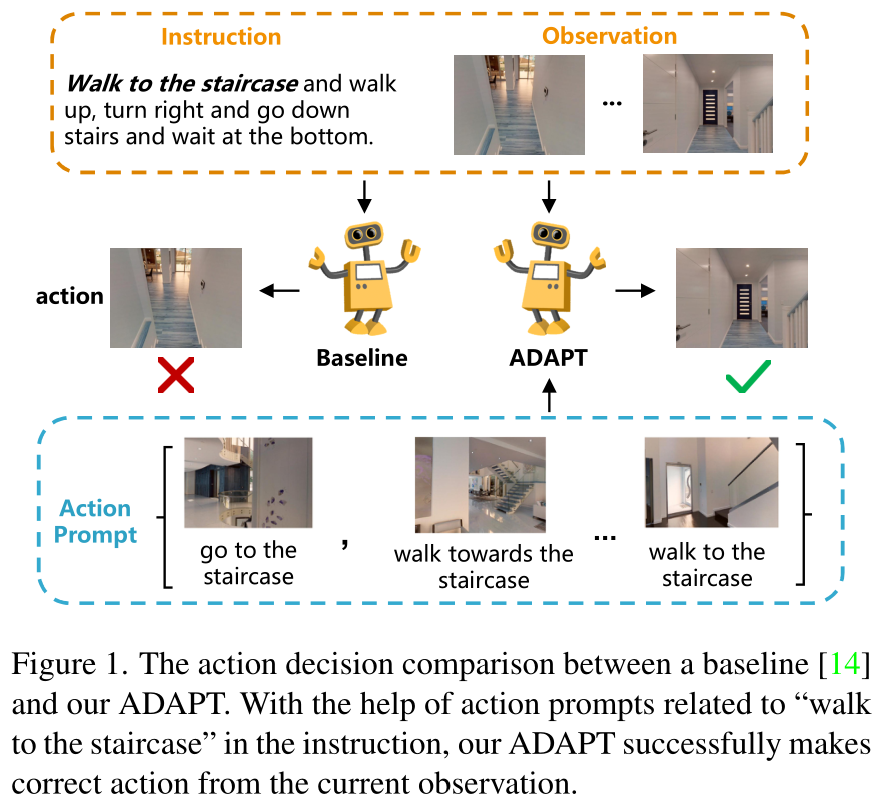
2,ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts(CVPR2022)
论文,代码,地址
- 本文提出了模态对齐行动提示(ADAPT),它为VLN代理提供了行动提示,使其能够明确学习行动层面的模态对齐,以追求成功的导航。
具体来说,一个行动提示被定义为一对模态对齐的图像子提示和文本子提示,其中前者是一个单视图观察,后者是一个短语,如 “走过椅子”。
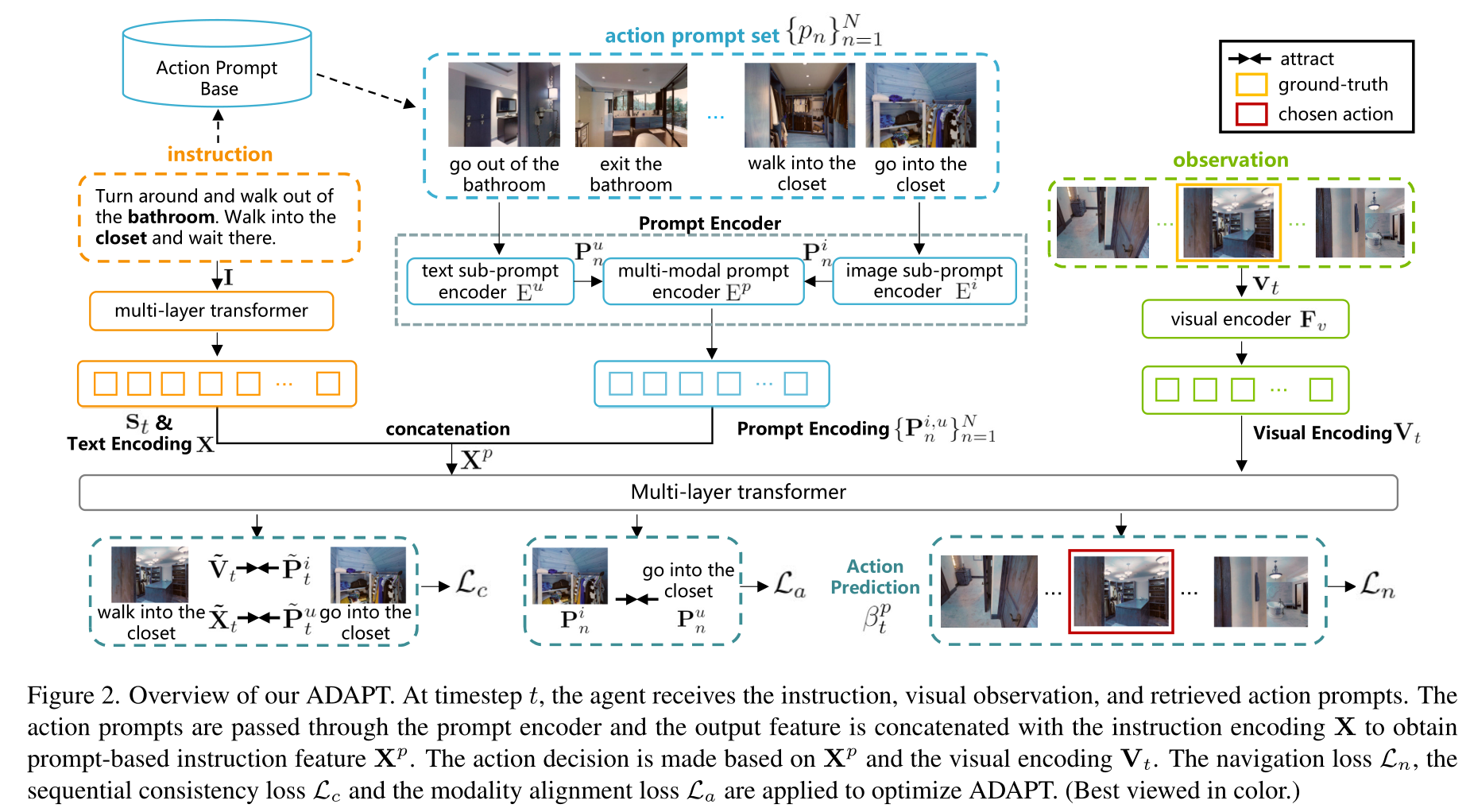
-
当开始导航时,与指令相关的动作提示集从预先建立的动作提示库中检索出来,并通过提示编码器来获得提示特征。强制模型学习跨模态特征
-
然后,将提示特征与原始指令特征串联起来,送入多层转化器进行动作预测。开发了一种模态对齐损失和顺序一致性损失,以实现对动作提示的有效学习。
-
为了收集高质量的动作提示到提示库中,本文使用了对比语言-图像预训练**(CLIP)**模型,它具有强大的跨模态对齐能力。我们进一步引入了模态对齐损失和顺序一致性损失,以加强动作提示的对齐,并强制代理按顺序关注相关提示。在R2R和RxR上的实验结果表明,ADAPT比最先进的方法更有优势。
下图用于建立动作提示库的动作提示收集图示。给定一个训练指令路径实例,首先通过CLIP和最近的动词搜索获得图像和文本子提示。和文本子提示首先分别通过CLIP和最近的动词搜索获得。然后,与同一视觉对象/位置和动作相关的多模态子提示被收集起来。相同的视觉对象/位置和动作相关的多模式子提示被排列起来,形成一个动作提示。这里以 "厨房 "这个词为例。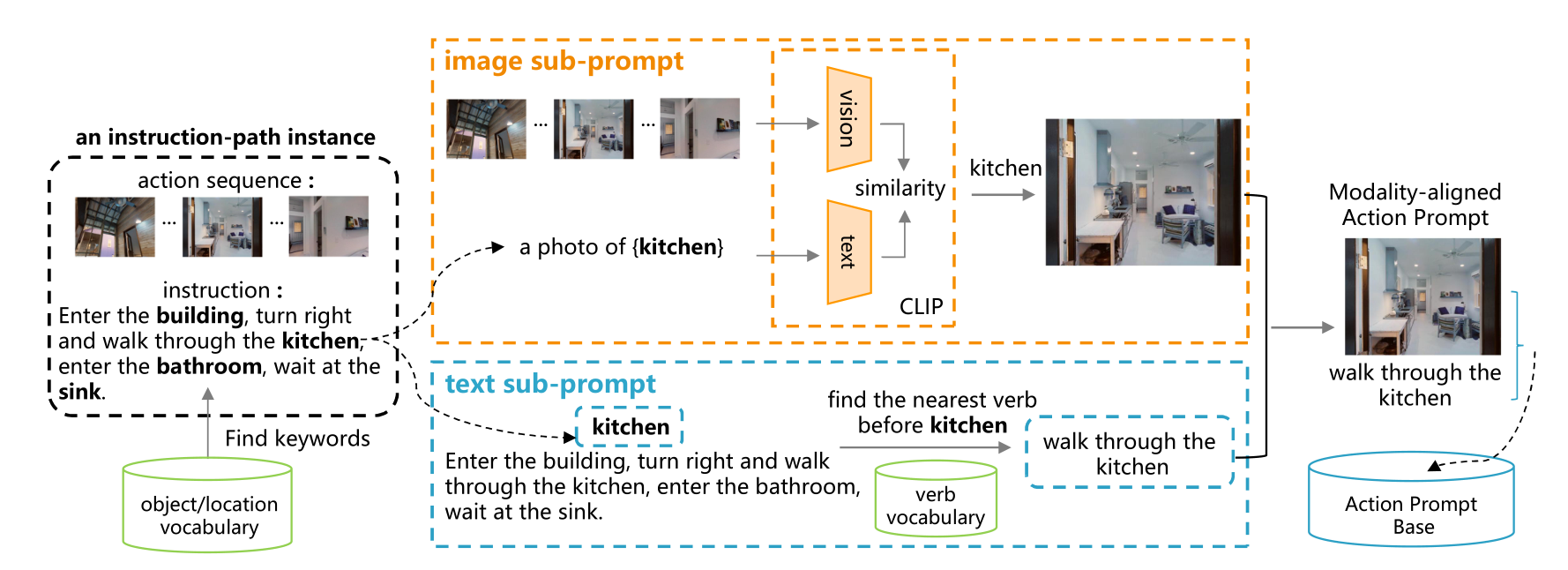
最终在r2r和rxr上的实验结果有所提高,而且所有实验都是在单个V100GPU上完成的。
3,CLIP-NAV: USING CLIP FOR ZERO-SHOT VISION-AND-LANGUAGE NAVIGATION
论文,
-
最近,像CLIP这样的视觉语言模型在zero-shot物体识别的任务上表现出了巨大的性能。在这项工作中,我们询问这些模型是否也能够进行zero-shot的语言定位。特别是,我们利用CLIP来解决zero-shot VLN的新问题,使用描述目标物体的自然语言指代表达,
-
与过去使用描述物体类别的简单语言模板的工作不同。本文研究了CLIP在没有任何数据集特定微调的情况下做出顺序导航决定的能力,并研究它如何影响代理所采取的路径。
-
在REVERIE的粗粒度指令跟踪任务上的结果显示了CLIP的导航能力,在成功率(SR)和按路径长度加权的成功率(SPL)方面都超过了有监督的基线。更重要的是,从数量上表明,当通过成功率相对变化(RCS)进行评估时,与SOTA、完全监督的学习方法相比,我们的基于CLIP的zero-shot方法能更好地概括,在不同环境中表现出一致的性能。
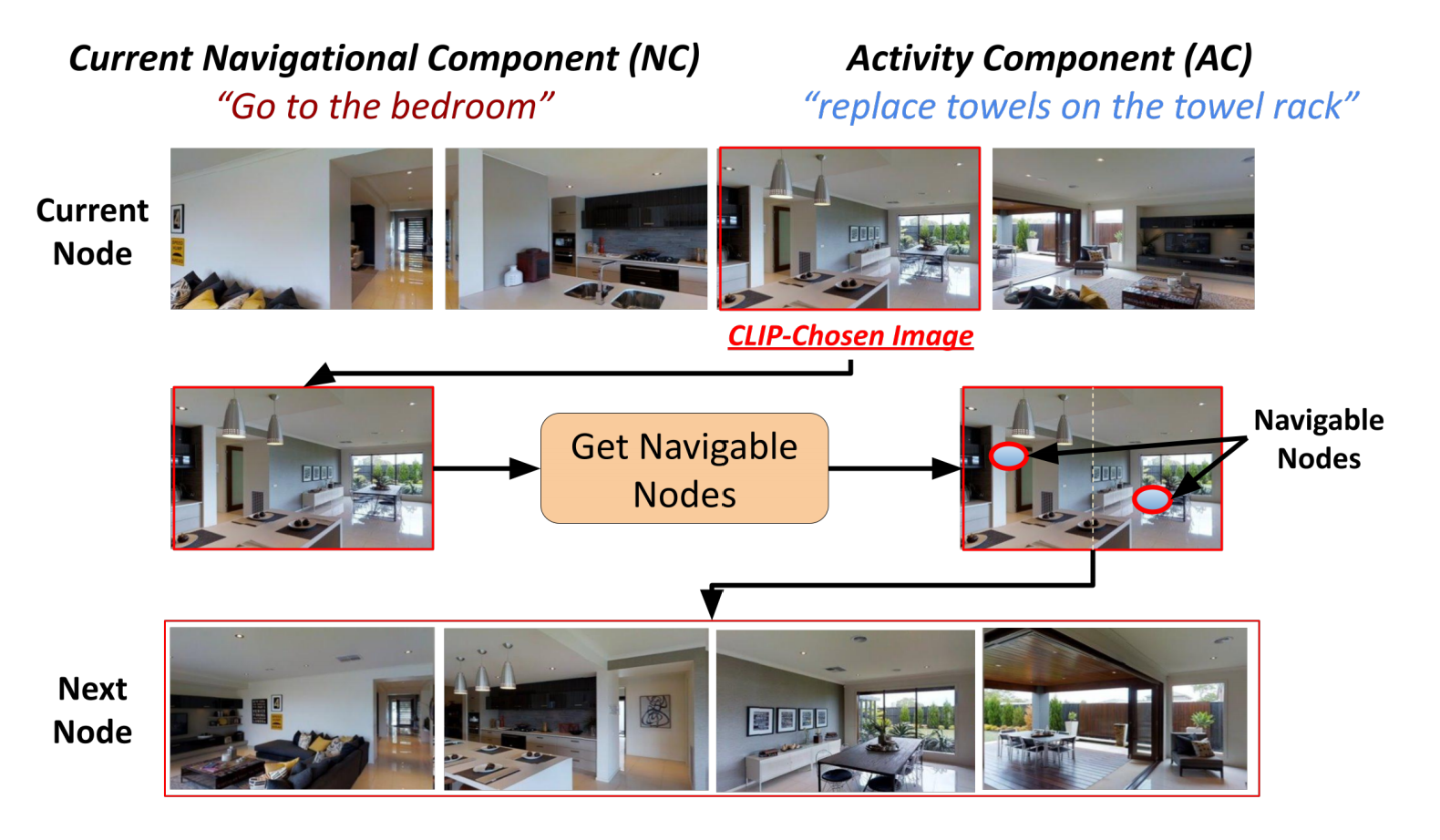
CLIP-nav
在每个时间点,一个CLIP-选择的图像是通过将当前的数控系统与每个全景splits grounding来确定的。选择的图像代表了我们的模型为zero-shot导航所选择的方向。在这种情况下,它指的是卧室有可能在所选方向的某个地方。AC grounding score给了我们一个停止的阈值,即我们的代理认为它已经到达了目标。CLIP-Nav迭代运行,直到达到这个阈值。
seq CLIP-nav
为了提高CLIP-Nav的性能,我们加入了一个反向追踪机制。在一连串的时间步骤中,CLIP的分数被平均化,以获得一个序列接地分数(SGS)。这个分数然后被用来确定代理是否需要回到几个节点(回溯)或不回溯。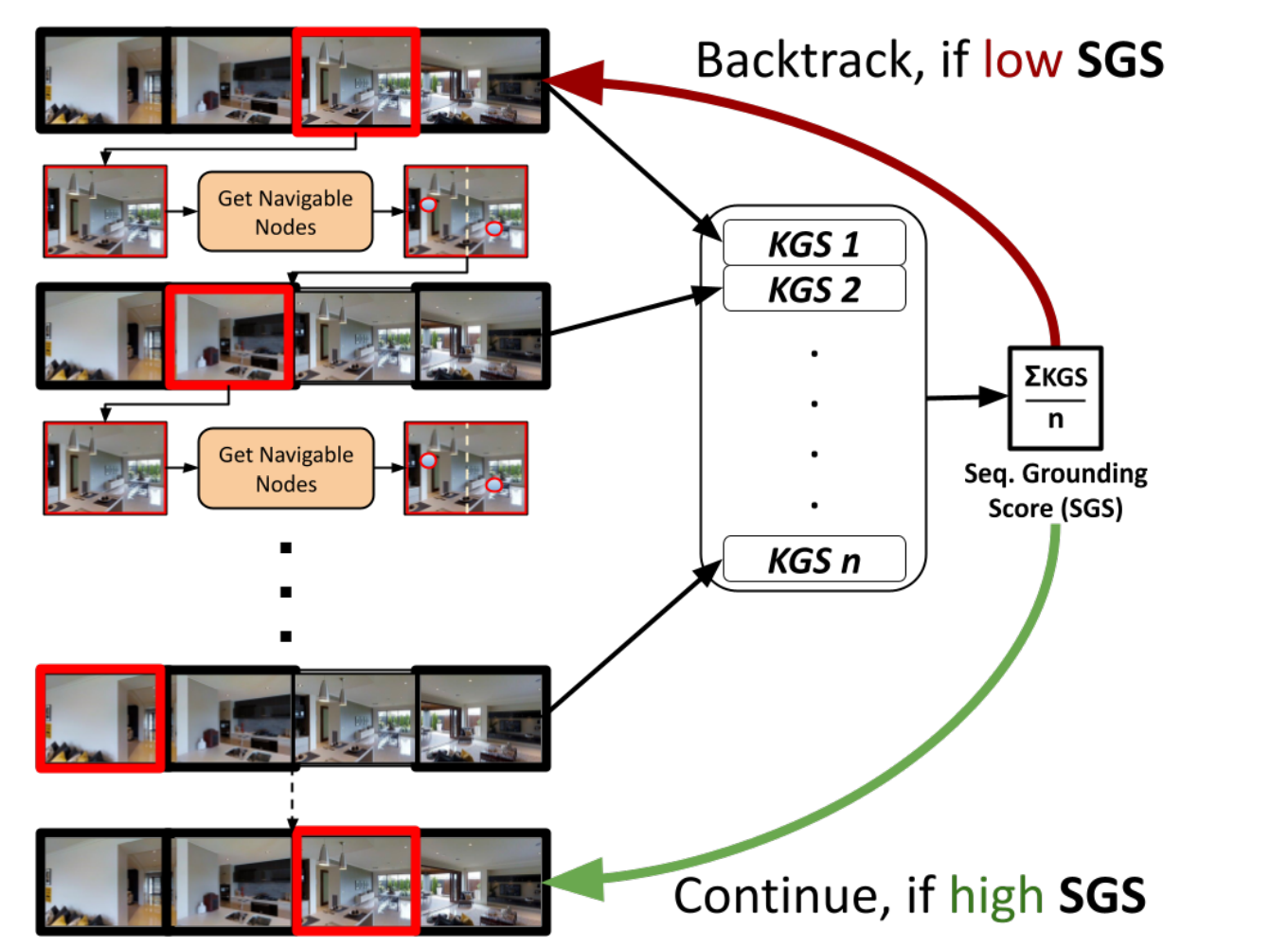
实验结果
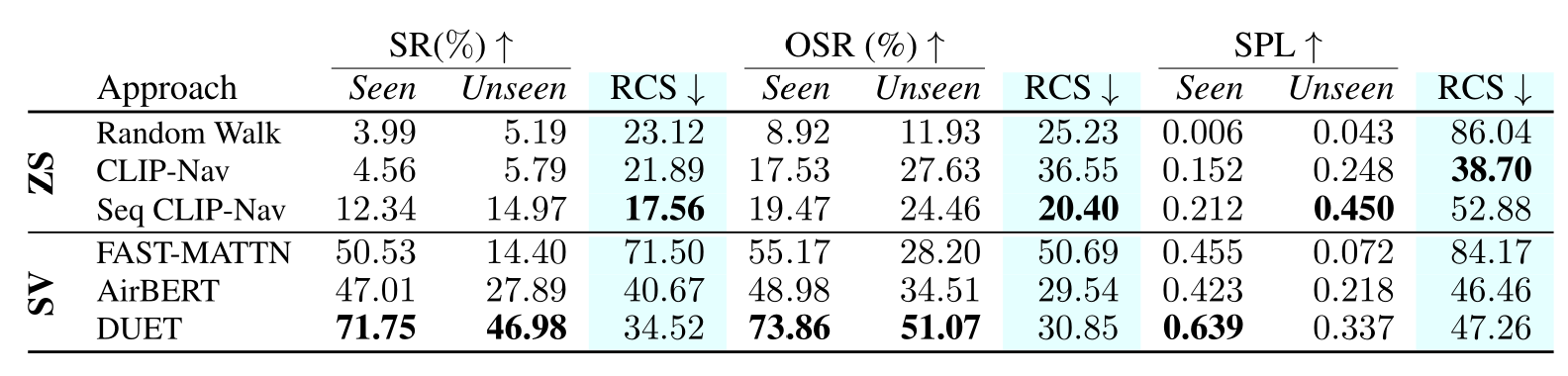
图中的结果虽然没有展示出zero-shot在成功率上面的提升,但是RCS分数较少,说明zero-shot方法比监督方法的泛化能力更好。其中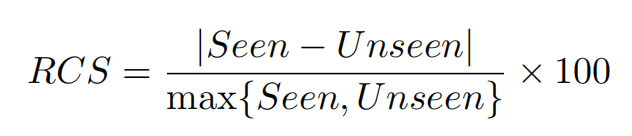
4,ENVEDIT: Environment Editing for Vision-and-Language Navigation(CVPR2022)
在视觉和语言导航(VLN)中,由于可用于代理训练的数据有限,而且导航环境的多样性有限,代理要概括到新的、未见过的环境中是很有挑战性的。为了解决这个问题,本文提出了ENVEDIT,一种通过编辑现有环境来创建新环境的数据增强方法,这些环境被用来训练一个更通用的代理。我们增强的环境可以在三个不同的方面与看到的环境不同:风格、物体外观和物体类别。
在这些编辑过的环境中进行训练,可以防止代理对现有环境的过度适应,并有助于对新的、未见过的环境进行更好的概括。经验表明,在Room-to-Room和多语言Room-Across-Room数据集上,我们提出的ENVEDIT方法在预训练和非预训练的VLN代理上的所有指标都得到了明显的改善,并在测试排行榜上达到了新的先进水平。
我们进一步在不同的编辑环境中对VLN代理进行了组合,并表明这些编辑方法是互补的。
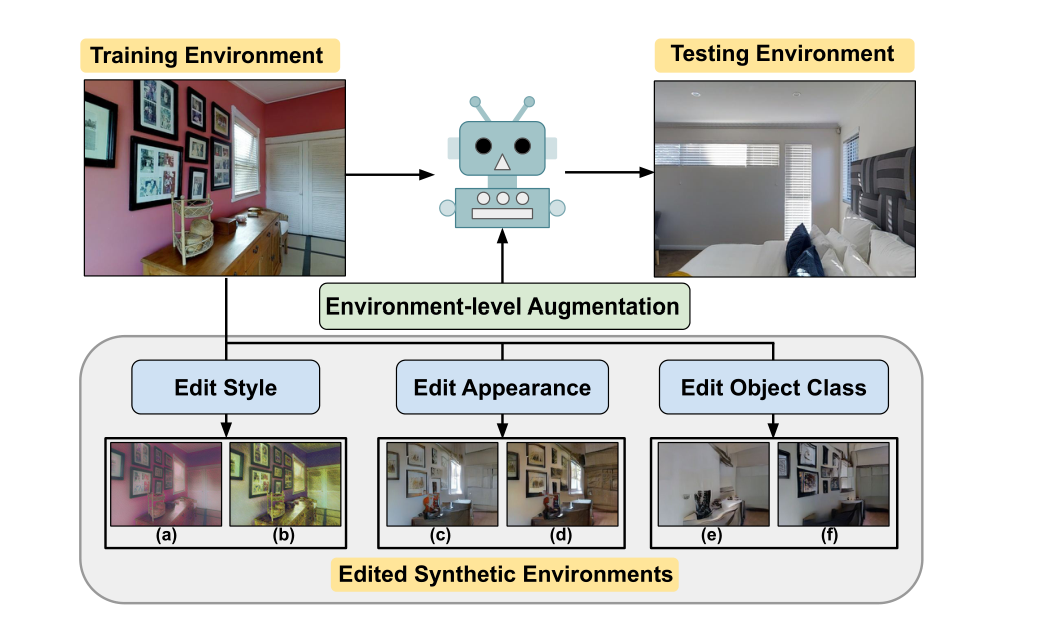
通过编辑训练环境的样式(a, b)、对象外观(c, d)和对象类(e, f)来创建合成环境。我们的合成环境在训练期间充当环境级数据增强,并帮助智能体泛化到未见的测试环境。
在第一阶段,代理人用风格转移和图像合成的方法以五种方式编辑原始环境。然后,代理在视觉和语言导航任务中使用原始环境和创建的环境进行训练。最后,利用风格感知的说话者为未注释的路径生成合成指令,用于回译。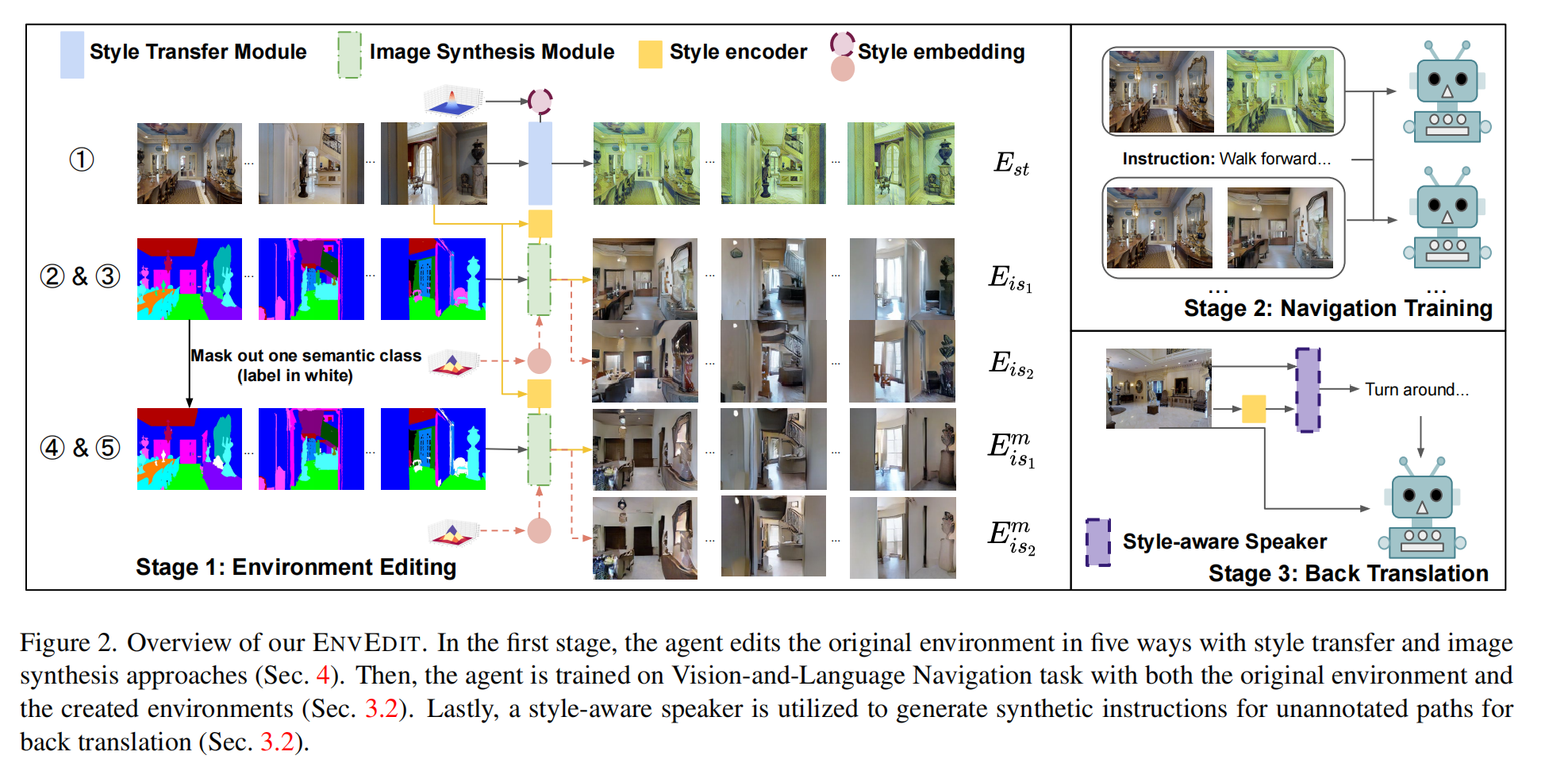
实验结果
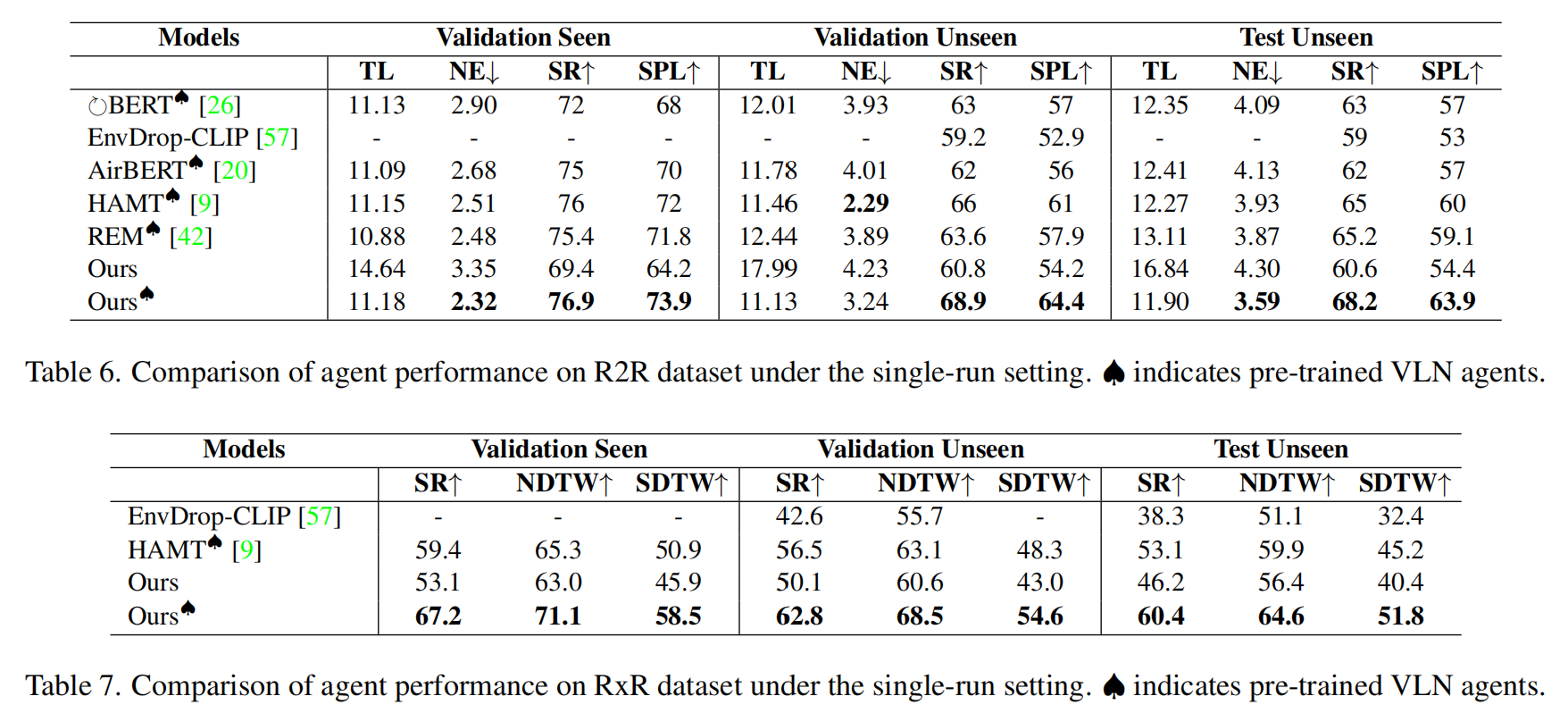
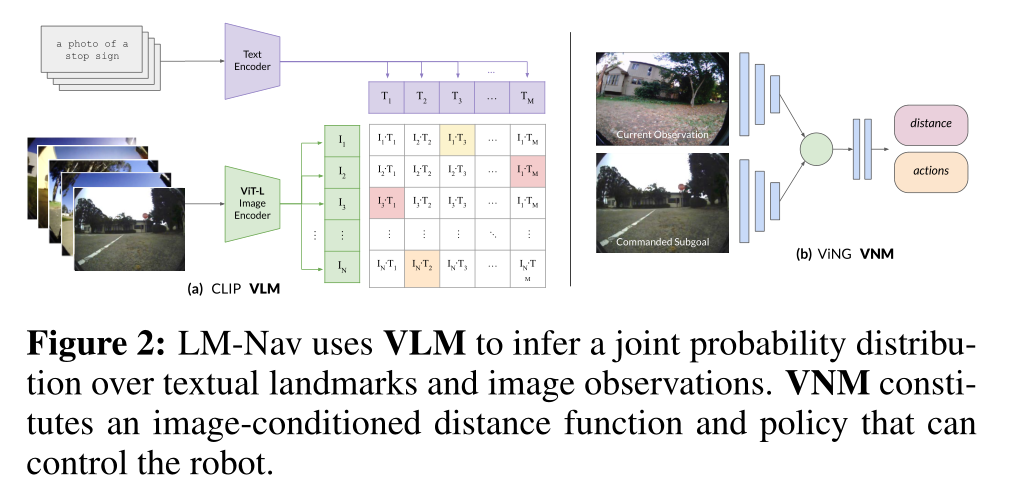
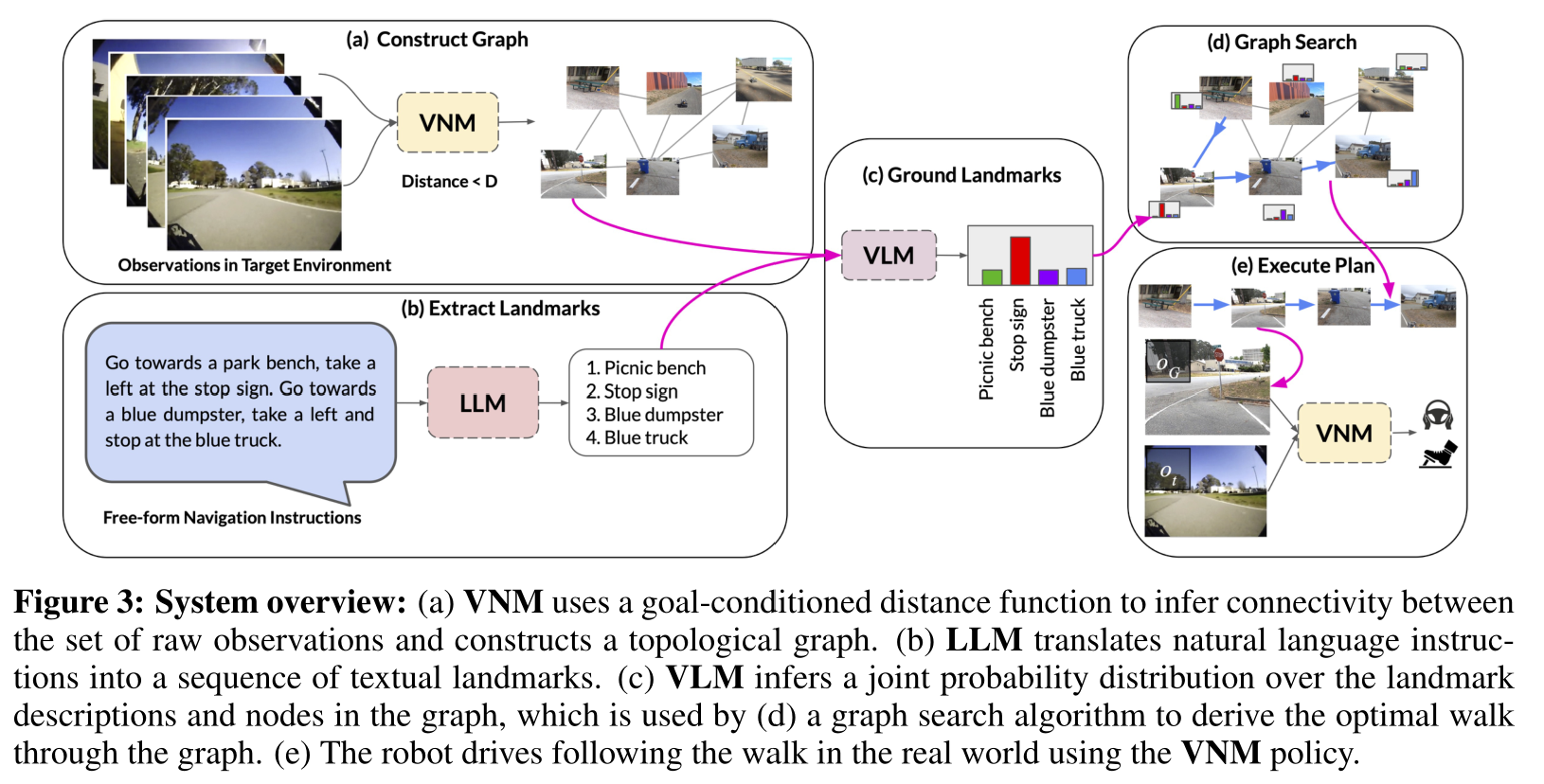
5,LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
本文是户外的导航,记录此文希望对室内导航带来一点启示。
用于机器人导航的目标条件策略可以在大型的、没有注释的数据集上进行训练,为现实世界的环境提供良好的概括性。
然而,特别是在基于视觉的环境中,指定目标需要一个图像,这使得界面不自然。语言为与机器人的交流提供了更方便的方式,但当代的方法通常需要昂贵的监督,其形式是用语言描述注释的轨迹。
本文提出了一个用于机器人导航的系统LM-Nav,该系统享有在未注释的大型轨迹数据集上进行训练的好处,同时还为用户提供了一个高级接口。结果表明,这样一个系统可以完全由预先训练好的导航(ViNG)、图像-语言关联(CLIP)和语言建模(GPT-3)模型构成,而不需要任何微调或语言注释的机器人数据,而不是利用标记的指令跟踪数据集。
本文在一个真实世界的移动机器人上实例化了LM-Nav,并展示了根据自然语言指令在复杂的户外环境中的长距离导航。
6,SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments-2021
本文提出了一种新的连续三维环境中的视觉和语言导航(VLN)任务的方法,该方法需要一个自主的代理在看不见的环境中遵循自然语言指令。现有的基于端到端学习的VLN方法在这项任务中很困难,因为它们主要专注于利用原始的视觉观察,而缺乏语义时空推理能力,而这在推广到新环境中至关重要。在这方面,我们提出了一个混合transformer-recurrence模型,其重点是将经典的语义映射技术与基于学习的方法相结合。
本文通过构建一个自上而下的以自我为中心的局部语义映射来创建一个时间语义记忆,并执行跨模态基础来对齐地图和语言模式,从而能够有效地学习VLN策略。在一个逼真的长范围模拟环境中的经验结果表明,所提出的方法优于各种最先进的方法和基线,在之前未看到的环境中,SPL相对提高超过22%。
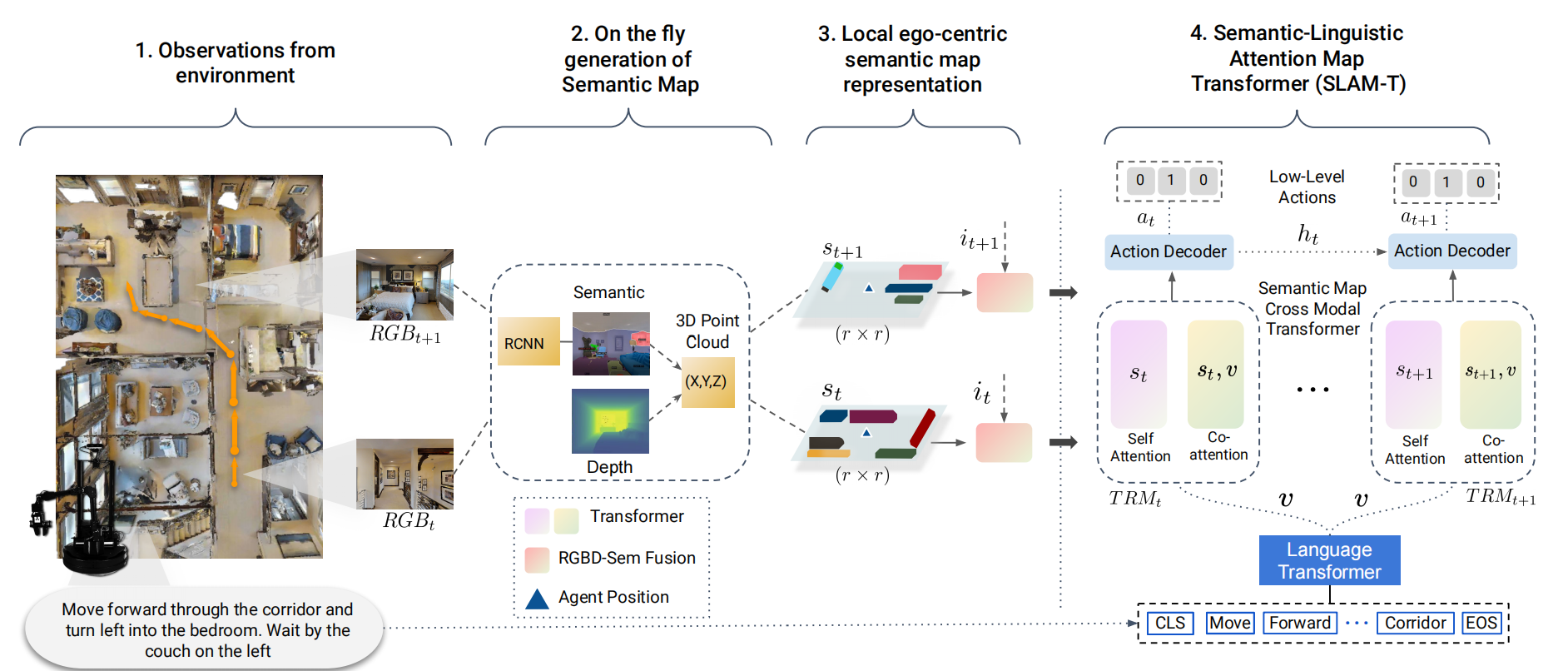
视觉和语言导航任务和我们提出的SASRA代理。本文的主要创新之处在于,通过利用跨模态的Semantic-Linguistic Attention Map Transformer(SLAM-T),为VLN采用了混合transformer-recurrence模型。在每个 时间步t,代理人从视觉观察中生成一个局部语义图。代理人始终在空间(跨模态)和语言(跨模态)两方面对环境进行推理。空间(语义图和语言之间的跨模态注意)和时间(通过时间保存以前的状态信息 时间)领域来解码每个时间步长的低层次行动(at)。
7,LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
论文,代码,地址
这项研究的重点是能够遵循自然语言指令在视觉感知的环境中完成复杂任务的具身代理。
现有的方法依靠大量的(指令,黄金轨迹)对来学习一个好的策略。高昂的数据成本和糟糕的采样效率阻碍了能够完成多种任务并能快速学习新任务的多功能代理的发展。
在这项工作中提出了一种新的方法,即LLMPlanner,它利用大型语言模型(LLM)的力量,如GPT-3,为具身的代理做少量规划。我们进一步提出了一种简单而有效的方法,用physical grounding来增强LLM,以产生基于当前环境的计划。
在ALFRED数据集上的实验表明,我们的方法可以实现非常有竞争力的几率性能,甚至超过了最近的几个基线,这些基线使用完整的训练数据进行训练,尽管使用的是不到0.5%的配对训练数据。现有的方法在同样的几率设置下几乎不能成功完成任何任务。
8,BEVBert: Topo-Metric Map Pre-training for Language-guided Navigation
论文,代码,地址















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









