






KCPNet: Knowledge-Driven Context Perception Networks for Ship Detection in Infrared Imager
1.Introduction
1.1 研究意义
在这几年,人们越来越把精力放在海洋资源发展,空间利用和环境保护。作为海洋carrier的交通运输工具。舰船检测是海洋检测的关键。同时红外图像的舰船检测在民用和军用领域有很大的战略价值,比如海洋交通管理、海洋救援和走私监管。
1.2 不同海洋图像的优缺点
有三种不同的海洋图像,分别为可见光、SAR图像和红外图像。
可见光:提供足够的语义信息,但是在晚上可见光图像是无法工作的。
SAR:可以全天工作。于是SAR图像在舰船检测中起到了很重要的作用。
红外:在某些敏感波段能够更好地进行检测、定位和识别。这些功效在军事中作用很大。此外,红外图像能投全天候并长距离检测技术,特别是基于空间的检测应用。因此使用红外图像进行舰船检测,是很重要的。
1.3 Challenges
1)低像素并且单通道
2)场景复杂。由于有白天和黑夜的变换。海洋和陆地 的灰度值呈现双极性的特点。同时舰船和背景的差异有多样性,由于有薄云和温度变化。同时厚云和条状的建筑会造成虚警。如下面两张图片所示:
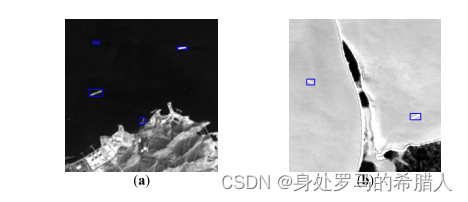
其中左边的图片是白天的红外图像。右边的图片是晚上的红外图像。
3)舰船在红外图像中是非常小同时缺乏语义信息。同时船靠岸时容易被海岸淹没。
1.4 深度舰船网络的方法
现在的检测方法能够被分成两个:分别是基于卷积的视觉特征方法和基于深度学习的算法。前者是属于模型驱动的方法。依靠手工的设计信息。在过去的二十年,模型驱动的方法取得了巨大的突破在红外小目标检测领域。但是这种方法的鲁棒性并不是很好。
同时,基于数据驱动的深度算法,比如Faster RCNN、YOLO、SSD和CenterNet。在可见光图像中的效果较好。但是又一个缺点就是预警无法使用背景特征进行获取;2)在由于多尺度池化导致小船消失或者被淹没。
1.5 Contribution
1)为了检测小目标,一个平衡特征融合网络被提出确保小目标信息子啊不同层的传递。同时,网络的感受野能够平衡本地和非本地特征。
2)考虑到红外目标其实没有多少语义信息和虚警在复杂场景中,本文设计像素级别的上下文信息(CA-Net)去增强目标和上下文信息。同时一直预警信息和抑制复杂的背景。
3)为了进一步减少预警,一个新的只是驱动的预测头被设计。其实就是用神经网路去预测图像的各种信息;
4)构建了一个新的数据ISDD。
2. 红外舰船检测的数据
2.1 为什么要自己制作新的数据集
现在数据在网络中扮演这非常重要的角色在基于数据驱动的模型中。但是,现在没有公开的的数据集合对于舰船检测在红外舰船检测中。之前主要使用的方法是1)使用小尺度的私人数据集。2)使用可见遥感的图像进行转换。
但是现在的私人的图片数量不超过500张。这些私人的数据是很难获取的,并且这数据对于本使用数据驱动的网路文章中的研究是不足够的。
目前有三种方式将可见光图像转换成红外图像,他们分别是:1)GAN。2)VAE。3)传统的图像生成算法。
总而言之现在的红外数据集合是无法满足小目标的标注的,于是,本文中提出了一种新的数据集合叫做ISDD的数据集合。
2.2数据来源
波段:Lband7,band 5和band 4。
地点:us,cn,jp,au,eu,etc。
2.2 ISDD的特点
1)目标一般比较小
2)场景多样
3)天气条件多样
4)公共可以获得,网址是: https://github.com/yaqihan-9898/ISDD.
3.Methodology
整体网络结构如下:
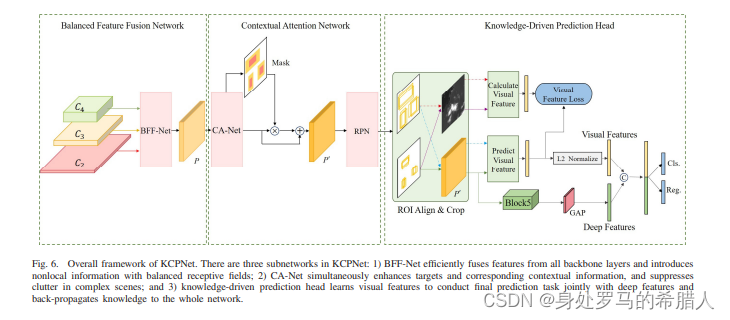
3.1 Balanced Feature Fusion Network
提出的BFF-Net网络用于平衡三个方面的特征。1)平衡语义信息和位置信息(resolution)2)许多特征融合网络添加或者拼接不同层。很显然不同层的网络对于网络的贡献是不一样的。3)可同时感受野扩展模块(receptive field expansion module.RFEM)用于平衡不同感受野的结构。

3.1.1 特征融合
我们使用了ResNet的Block1-Block4作为我们的backbone。为了加速收敛和防止过拟合,我们使用ResNet的Block5和global average pooling代替普遍应用在prediction head的两个FC层。因此,我们的骨干网络只残生四个特征层。同时我们运用了双线性操作和1×1卷积(老方法调整特征层的通道数)。我们应用一个通道注意力模块来调整注意力模块的权重(因为每个这则会那个层的 重要性是不同的)。
channel attention用于层间和层内的特征图的融合。但是,
C
4
C_4
C4后面没有通道注意力模块。因为如果
C
4
C_4
C4的channel attention。其中FFM的公式如下:
F
=
C
o
n
v
1
×
1
[
U
p
S
a
m
p
l
e
(
C
4
)
]
+
C
A
(
C
3
)
+
C
A
(
C
o
n
v
1
×
1
[
D
o
w
m
S
s
m
p
l
e
(
C
2
)
]
)
F=Conv_{1\times 1}[UpSample(C_4)]+CA(C_3)+CA (Conv_{1\times 1} [DowmSsmple(C_2)])
F=Conv1×1[UpSample(C4)]+CA(C3)+CA(Conv1×1[DowmSsmple(C2)])
其中CA代表着通道注意力模块。同时upsample代表
2
×
2\times
2×双线性插值,DownSample代表双线性下采样。
C
o
n
v
1
×
1
Conv_{1\times 1}
Conv1×1代表输出为512维的卷积层,F代表被混合的特征层。
3.1.2 RFRM
原因:由于缺乏小目标的本地信息,有一个必要的需要去提取非本地全局信息将非本地信息和本地信息相融合。特征图如下入所示:

得到的网络公式如下:
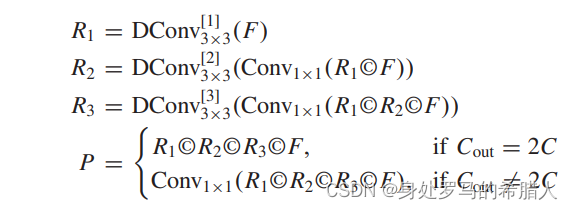
这是使用空洞卷积扩大感受野:其中
c
o
n
v
1
×
1
conv_{1\times 1}
conv1×1都是用于通道数调整。
D
C
o
n
v
3
×
3
[
1
]
DConv^{[1]}_{3\times 3}
DConv3×3[1]使用diated rate为2的空洞卷积。
D
C
o
n
v
3
×
3
[
2
]
DConv^{[2]}_{3\times 3}
DConv3×3[2]使用空洞卷积大小为4的卷积核。。
D
C
o
n
v
3
×
3
[
3
]
DConv^{[3]}_{3\times 3}
DConv3×3[3]使用空洞卷积大小为8的卷积核。同时使用的是拼接操作。
通过如上的方法,
R
1
,
R
2
,
R
3
和
P
R_1,R_2,R_3和P
R1,R2,R3和P的感受野分别是F的5,13,29和29倍。很明显,感受野得到了极大的扩展,基本上扩大到当时特征层的大小的
62
×
62
62\times 62
62×62倍。
本文提出的RFEM的特征:1.于ASPP不同,本文提出了空洞卷积网络解决了空洞卷积网格化的问题。同时重复利用了之前的感受野和导致了本地信息的损失。2.横夺基于卷积的REEMs往往忽略了特征图的从属和等级关系,导致了初始特征的碗篮。在本文中RFEM保持了最初信息。3.随着dilate rate的增加。卷积的过滤特征逐渐减少。但是大多数其他的模块只采取一个平行特征和casace结构.。
3.2 上下文注意力网络
海洋在现实应用中是十分复杂的,特别是靠近海岸。背景聚集和虚警严重影检测的准确率。为了解决这个问题,注意力机制被提出。最近的研究大多数都是集中于无监督注意力网络。但是无监督注意力网络无法明确学习到明确目标。于是在注意力网络中引入先验信息是很有必要的。
本文中提出了一种基于无监督的双掩膜注意力网络,本文提出了新的注意力网络-CA-Net。来打破小舰船的语义信息的局限并减少虚警。

Fig.9是感受野偏小的图像,其实普通人无法识别到底是虚警还是目标。而Fig.10是感受野偏大的图像,我们人就相对容易地区分目标和结果。所以目标检测的主要的不应该只有目标也应该有观察目标的周围的特点。具体的网络如下:
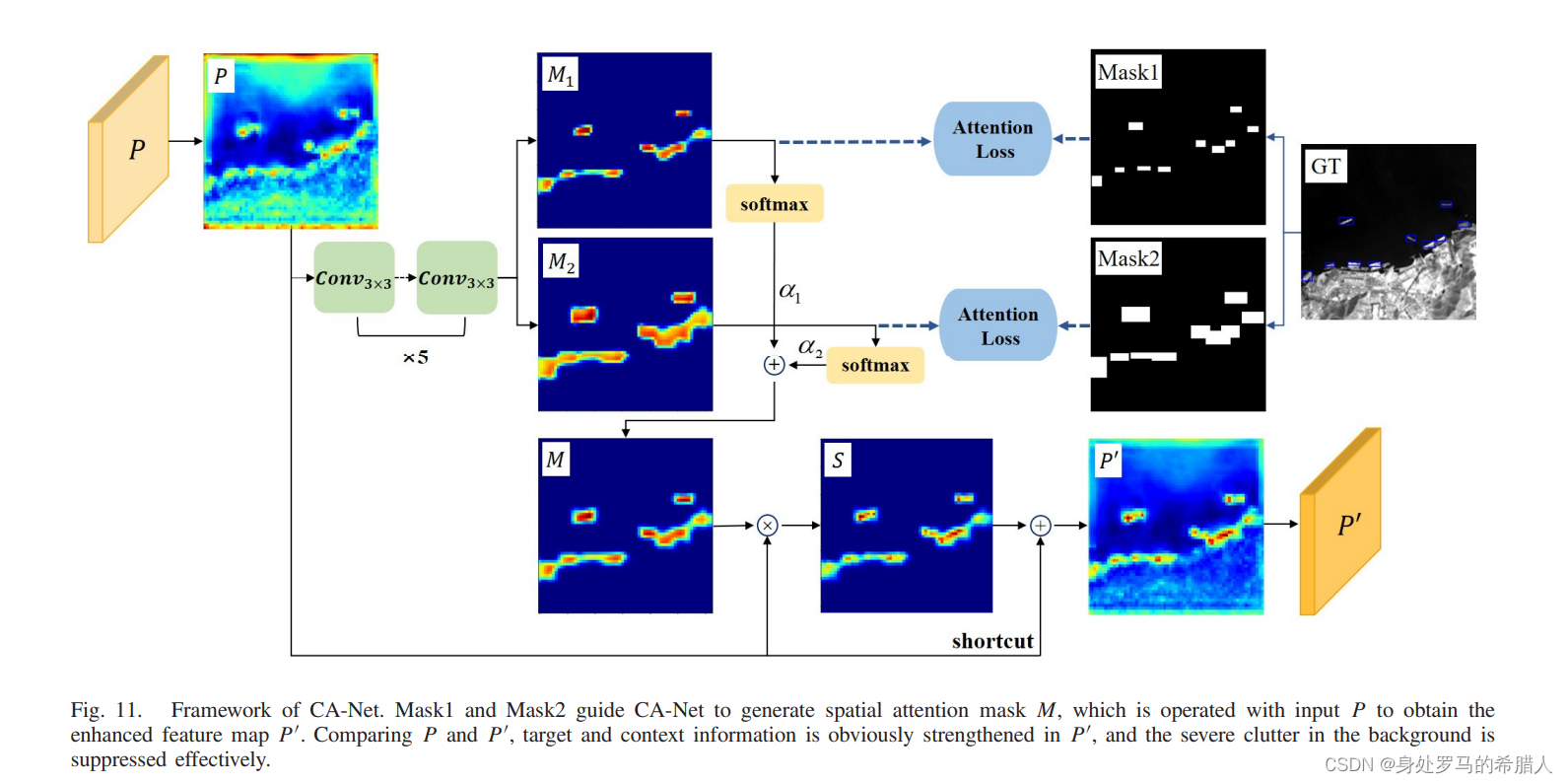
本文提出的CA-Net是一个有监督的像素级别的注意力网络。本文提出的CA-Net网络如图11所示。在本文中使用了两个掩膜,分别是Mask1和Mask2。将前景设置为1,同时将背景设置为0。对于Mask1而言,先验框设置为1,同时背景是0。对于Mask2而言,
β
\beta
β乘以GT的大小。在Mask2和Mask1的监督下,CA-Net运用5个
3
×
3
3\times 3
3×3的256通道的卷积。CA-Net的损失函数在SectionIV-D中描述可得。同时本文中使用了shortcut的方法,防止常见的梯度消失。
M
1
=
C
o
n
v
3
×
3
×
256
×
1
[
1
]
(
C
o
n
v
3
×
3
×
2561
×
1
5
)
(
P
)
)
M
2
=
C
o
n
v
3
×
3
×
256
×
1
[
2
]
(
C
o
n
v
3
×
3
×
2561
×
1
5
)
(
P
)
)
P
=
P
⨂
[
1
+
α
∙
s
o
f
t
m
a
x
(
M
1
)
+
α
∙
s
o
f
t
m
a
x
(
M
2
)
]
M_1=Conv^{[1]}_{3\times 3\times 256\times 1}(Conv^5_{3\times 3\times 256 1\times 1})(P))\\ M_2=Conv^{[2]}_{3\times 3\times 256\times 1}(Conv^5_{3\times 3\times 256 1\times 1})(P))\\ P=P\bigotimes [1+\alpha \bullet softmax(M_1)+\alpha \bullet softmax(M_2)]
M1=Conv3×3×256×1[1](Conv3×3×2561×15)(P))M2=Conv3×3×256×1[2](Conv3×3×2561×15)(P))P=P⨂[1+α∙softmax(M1)+α∙softmax(M2)]
P代表输出特征层从BFF-Net,
C
o
n
v
3
×
3
×
256
[
5
]
Conv^{[5]}_{3\times 3 \times 256}
Conv3×3×256[5]代表折着5个
3
×
3
×
256
3\times 3 \times 256
3×3×256卷积层,
M
1
M_1
M1和
M
2
M_2
M2共享相同的
C
o
n
v
3
×
3
×
256
[
5
]
Conv^{[5]}_{3\times 3 \times 256}
Conv3×3×256[5]。
C
o
n
v
3
×
3
×
2
[
1
]
Conv^{[1]}_{3\times 3\times 2}
Conv3×3×2[1]和
C
o
n
v
3
×
3
×
2
[
2
]
Conv^{[2]}_{3\times 3\times 2}
Conv3×3×2[2]代表着
3
×
3
×
2
3\times 3\times 2
3×3×2卷积。
⨂
\bigotimes
⨂代表点乘。
α
1
\alpha_1
α1和
α
2
\alpha_2
α2是用于平衡的超参数。
就像上文分析可以得到,CA-Net不再局限于目标本身,而是扩展上下文特征。我们可以看到与之前的方法不同,本文使用的注意力网络更加关注目标所属的环境。这对减少小目标的漏检。
3.3 知识驱动的预测头
3.3.1 预测头结构
预测头结构。由于CNN网络的黑箱属性,深度特征的物理可解释性是缺乏的。实验已经证明许多虚警是无法辨别如果只是使用深度特征。考虑到CNN学习过程中模拟人类的认知过程,从根本上去解决虚警问题,我们应该分析为什么人类能够那么快地检测出舰船,比如舰船的形状和与环境的对比。其中我们关键的益处我们有足够的先验知识。因此,我们结合了模型驱动和数据驱动的两个方法。网络的结构图如下图所示:
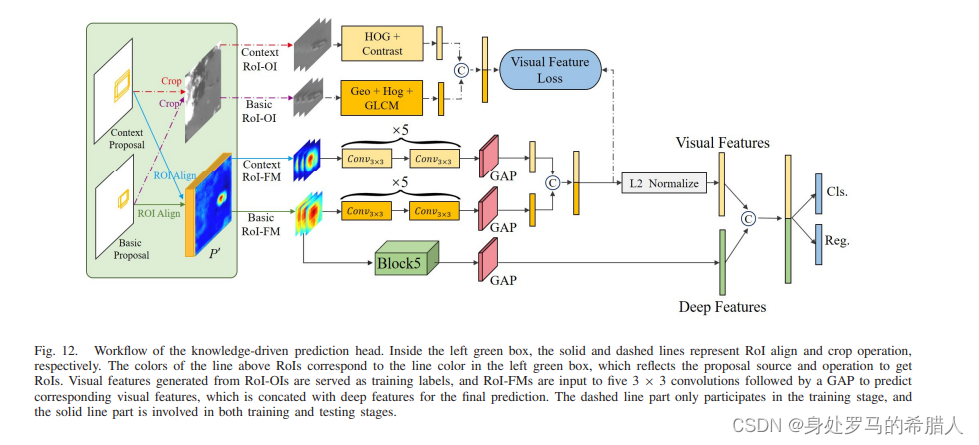
在上一节中,上下文信息被引入到舰船和非舰船目标的检测的过程中。因此,在知识驱动的预测头中,RoI对齐进行了两侧从特征图中获取基本RoI和上下文RoI从特征图中。基本的RoI-FM和传统的RoI相同点:1)有两阶段网络;2)RoI-FM是从上下文目标中产生的,
β
\beta
β倍数的基础长度和宽度的基础目标。
本文使用了两个RoI:1)使用传统的RoI,crop原始图片;2)上下文的Context RoI-OI提取图片。也就是一个面积大,一个是面积小。
视觉特征从Basic RoI-OIs和Context RoI-OIs作为训练的标签。
但是直接使用视觉特征会严重影响网络计算的复杂度,从而降低网络的速度。从而本文中选用卷积网络预测网络的特征追
3.3.2 视觉信息
视觉信息应当包含有两个特点:1)有足够的先验信息;2)能够区别舰船和虚警。为了更好地设计视觉特征,我们需要特征分析虚警的特征。
目前主要的虚警种类:1.云虚警;2.土地虚警。云虚警包含有两类:1.条状云虚警;2.点云。土地虚警有:1.条状高俩个建筑;2.突出土地;3,小岛。主要的效果如下:

通过上图我们可以知道,大多数虚警在形状和与背景的对比上和舰船有一定的类似程度。幸运的是,目前还是有很多不同在虚警和真正的目标之间。基于上面的三种视觉类型,我们可以选择三种视觉信息:1.集合特征2.纹理特征3.对比特征。具体说明如下:
(1)集合特征包括矩形度数、AR和连接区域的数目。所有RoI-OIs应该二值化在计算集合特征之前。几何特征表现得最好,因为它去除了不规则的云和土地。具体特征如下:

(2)纹理特征包含HOG特征和CLCM特征。将Context RoI-OI划分成四个区域。具体方法如下:
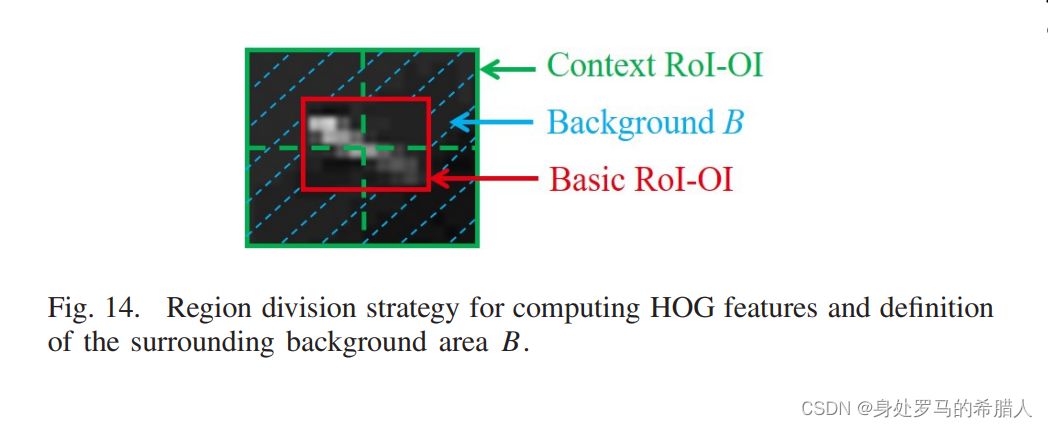
通过计算分别计算不同区域的HOG特征。
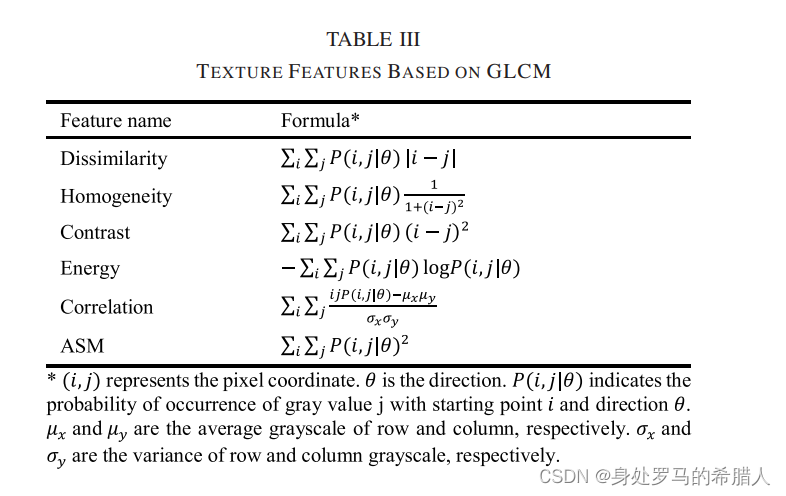
CLCM特征包括六个特征,包括dissimilarity, homogeneity, contrast,energy, correlation, and angular second moment dissimilarity, homogeneity, contrast, energy, correlation, and angular second moment。具体计算公式如下:
纹理特征对灰度分布不均匀的特征。
(3)对比特征是描述RoI和周围背景的区别。对比特征图表如图所示:
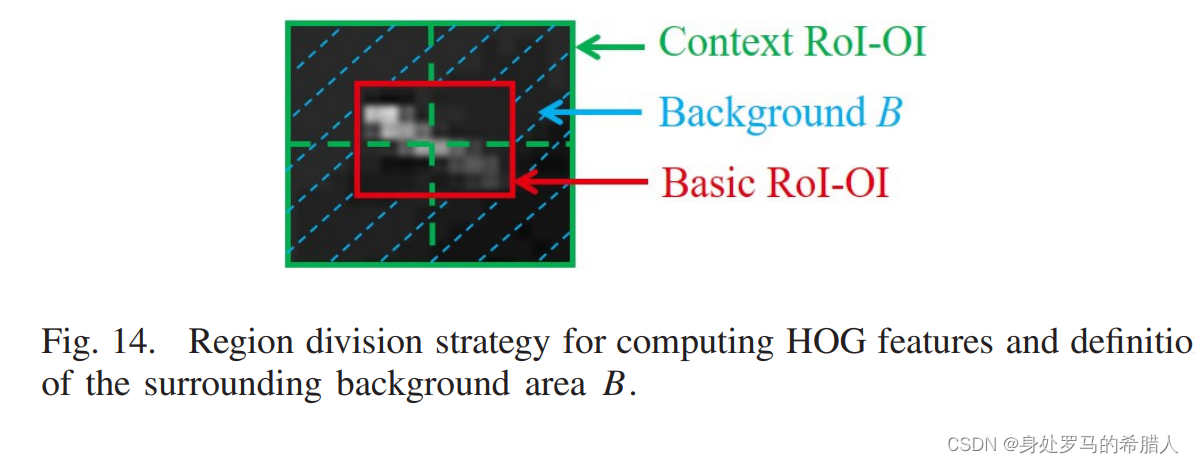
本文将周围背景被定义为Context RoI-OI去除Basic RoI-OI的环形区域。由于大气折射和光学散焦的影响,红外舰船展现了高斯特征。由于传统的对比度算法使用了八邻域灰度插值或者比值,但是舰船存在拖尾效应,于是本方法并不适合对舰船对比进行建模。正如(a)所示,MPCM能够鉴别云和岸边虚警。但是trailing ships是不正确的低的,同时岸边的虚警没有办法进行区分。但是,舰船拖尾区域变化很大的。公式如下:

我跑通的环境如下
absl-py==1.2.0
albumentations==0.5.0
astor==0.8.1
astunparse==1.6.3
backcall==0.2.0
biwrap==0.1.6
catboost==1.0.6
certifi @ file:///opt/conda/conda-bld/certifi_1663615672595/work/certifi
click==8.1.7
cloudpickle==2.2.0
contourpy==1.0.5
cycler==0.11.0
Cython==3.0.10
cython-bbox==0.1.5
dask==2023.5.0
debugpy==1.6.3
decorator==5.1.1
entrypoints==0.4
fonttools==4.37.3
fsspec==2024.3.1
gast==0.3.3
google-pasta==0.2.0
graphviz==0.20.1
grpcio==1.49.1
h5py==2.10.0
imageio==2.34.1
imgaug==0.4.0
importlib-metadata==6.1.0
ipykernel==6.15.3
ipython==7.34.0
jedi==0.18.1
joblib==1.2.0
jupyter-core==4.11.1
jupyter_client==7.3.5
Keras-Applications==1.0.8
Keras-Preprocessing==1.1.2
kiwisolver==1.4.4
lazy_loader==0.4
lightgbm==3.3.2
locket==1.0.0
Markdown==3.4.1
MarkupSafe==2.1.2
matplotlib==3.6.0
matplotlib-inline==0.1.6
nest-asyncio==1.5.5
networkx==3.1
numpy==1.23.3
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-cupti-cu11==11.7.101
nvidia-cuda-nvcc-cu11==11.7.99
nvidia-cuda-runtime-cu11==11.7.99
nvidia-cudnn-cu11==8.5.0.96
nvidia-cufft-cu11==10.7.2.91
nvidia-curand-cu11==10.2.10.91
nvidia-cusolver-cu11==11.4.0.1
nvidia-cusparse-cu11==11.7.4.91
nvidia-dali-cuda110==1.16.0
nvidia-dali-nvtf-plugin==1.16.0+nv22.8
nvidia-nccl-cu11==2.14.3
nvidia-pyindex==1.0.9
nvidia-tensorflow==1.15.5+nv22.8
opencv-python==4.6.0.66
opencv-python-headless==4.9.0.80
opt-einsum==3.3.0
packaging==21.3
pandas==1.5.0
parso==0.8.3
partd==1.4.1
pexpect==4.8.0
pickleshare==0.7.5
Pillow==9.2.0
plotly==5.10.0
prompt-toolkit==3.0.31
protobuf==3.20.2
psutil==5.9.2
ptyprocess==0.7.0
pycocotools==2.0.7
Pygments==2.13.0
pyparsing==3.0.9
python-dateutil==2.8.2
pytz==2022.2.1
PyWavelets==1.4.1
PyYAML==6.0.1
pyzmq==24.0.1
scikit-image==0.21.0
scikit-learn==1.1.2
scipy==1.9.1
seaborn==0.12.0
shapely==2.0.4
six==1.16.0
sklearn==0.0
spyder-kernels==2.3.3
tenacity==8.1.0
tensorboard @ file:///tensorboard-1.15.0-py3-none-any.whl
tensorflow-estimator==1.15.1
tensorflow-plot==0.3.2
termcolor==2.0.1
threadpoolctl==3.1.0
tifffile==2023.7.10
toolz==0.12.1
tornado==6.2
tqdm==4.64.1
traitlets==5.4.0
wcwidth==0.2.5
Werkzeug==2.2.3
wrapt==1.14.1
wurlitzer==3.0.2
xgboost==1.6.2
zipp==3.15.0

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









