






seq 2 seq & Attention
最流行的seq2seq的任务是序列翻译
一个输入序列 x 1 , … x n x_1, \dots x_n x1,…xn,输出序列 y 1 , y 2 , … , y n y_1, y_2, \dots, y_n y1,y2,…,yn。
我们需要最大化概率的目标序列: p ( y ∣ x ) : y ∗ = arg max y p ( y ∣ x ) p(y|x):y^*=\arg \max \limits_yp(y|x) p(y∣x):y∗=argymaxp(y∣x)
机器学习中 p ( y ∣ x , θ ) p(y|x,\theta) p(y∣x,θ)带有参数 θ \theta θ,然后找到给定的输入
y ′ = arg max y p ( y ∣ x , θ ) y'=\arg \max\limits_yp(y|x, \theta) y′=argymaxp(y∣x,θ)
编码器-解码器框架
编码器:读取源序列并生成其表示形式
解码器:使用来自编码器的原表示来生成目标序列
最简单的编码器-解码器由两个rnn组成
利用交叉熵损失计算
贪婪解码:每一步找到一个概率最高的token。
但是局部最优不一定导致全局最优
arg max ∏ t = 1 n p ( y t ∣ y < t , x ) ≠ ∏ t = 1 n arg max y t p ( y t ∣ y < t , x ) \arg \max \prod\limits_{t=1}^np(y_t|y_{<t},x) \ne \prod \limits_{t=1}^n \arg \max\limits_{y_t}p(y_t|y_{<t},x) argmaxt=1∏np(yt∣y<t,x)=t=1∏nargytmaxp(yt∣y<t,x)
Beam Search:跟踪几个最有可能的假设
Attention
固定的源表示效果欠佳:
(i)对于编码器,很难压缩句子;
(ii)对于解码器,不同的信息可能在不同的步骤中相关。
编码器将整个源句压缩到单个向量中。这可能非常困难 - 源的可能含义的数量是无限的。当编码器被迫将所有信息放入单个向量中时,它可能会忘记某些内容。
Attention的原理是在不同的步骤中,让模型"聚焦"在输入的不同部分。
计算Attention分数最常用的方法
- 点积: s c o r e ( h t , s k ) = h t T s k score(h_t,s_k)=h_t^Ts_k score(ht,sk)=htTsk
- 双线性函数: s c o r e ( h t , s k ) = h t T W s k score(h_t, s_k)=h_t^TWs_k score(ht,sk)=htTWsk
- 多层感知器: s c o r e ( h t , s k ) = w 2 T ⋅ t a n h ( W 1 [ h t , s k ] ) score(h_t, s_k)=w_2^T\cdot tanh(W_1[h_t, s_k]) score(ht,sk)=w2T⋅tanh(W1[ht,sk])
多层感知机
- 编码器:双向
为了更好地编码每个源字,编码器有两个RNN,向前和向后,它们在相反的方向上读取输入。对于每个token,两个 RNN 的状态是连接的。 - 注意力分数:多层感知器
要获得注意力分数,请将多层感知器 (MLP) 应用于编码器状态和解码器状态。 - 注意应用:解码器步骤
之间解码器步骤之间使用注意:状态 h t − 1 h_{t−1} ht−1用于计算注意力及其输出 c ( t ) c(t) c(t),以及两者 h t − 1 h_{t−1} ht−1和 c ( t ) c(t) c(t)在步骤处传递到解码器t.
双线性函数
- 编码器:非重复(简单)
- 注意力评分:双线性函数
- 注意应用:解码器之间的RNN状态t和此步骤的预测
注意在RNN解码器步骤之后使用t在做出预测之前。州断续器用于计算注意力及其输出 c ( t ) c(t) c(t).然后断续器与 c ( t ) c(t) c(t)以获取更新的表示形式 h t h_t ht,用于获取预测。
Transformer
仅使用Attention进行运行
区别于之前seq2seq需要用到注意力来运行
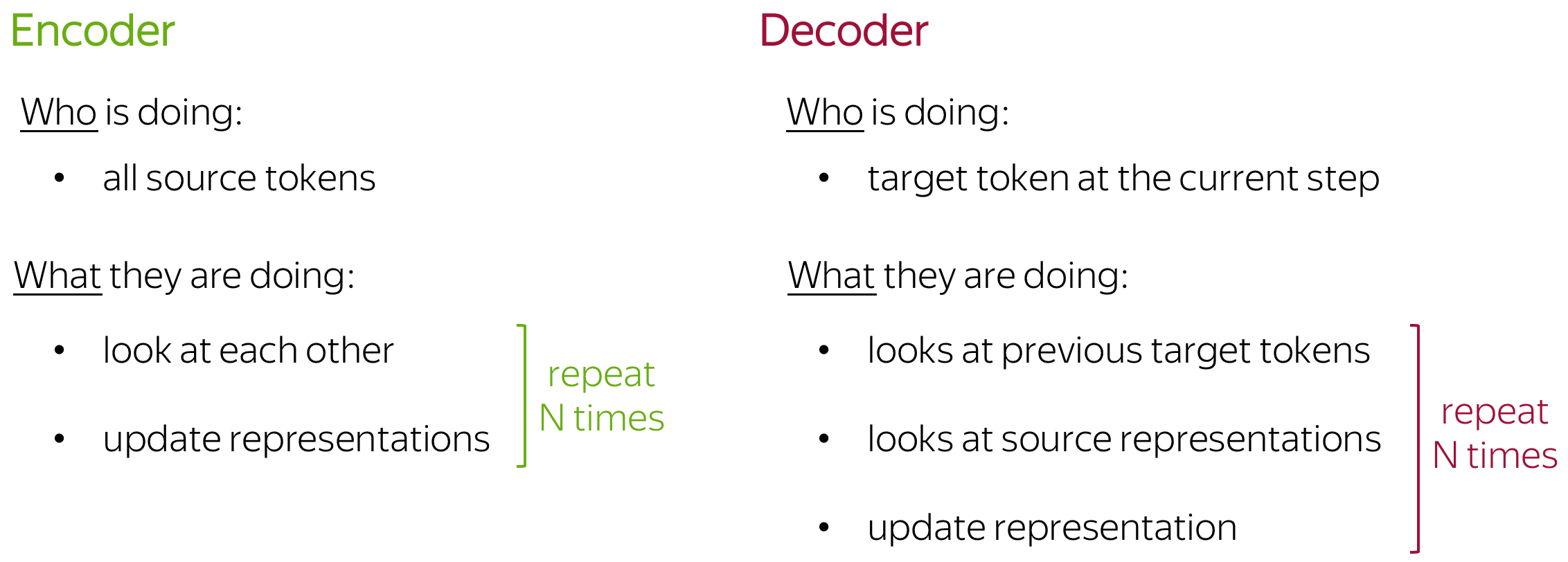
在Transformer的编码器中,token同时相互作用。
self-attention
在相同性质的表示之间起作用

self-attention是模型中相互交互的部分,每个标记都使用注意力机制查看句子中的其他标记,并且收集上下文
- 查询 - 询问信息;
- 关键 - 说它有一些信息;
- 值 - 提供信息。
a t t e n t i o n ( q , k , v ) = s o f t m a x ( q k T d k ) v attention(q,k,v)=softmax(\frac{qk^T}{\sqrt{d_k}})v attention(q,k,v)=softmax(dkqkT)v
Mask
有个自我关注机制:查看之前token功能
虽然编码器一次接收所有token,并且token可以查看输入句子中的所有token,但在解码器中,我们一次生成一个token:在生成过程中,我们不知道将来会生成哪些token。
Multi-attention
模型专注于不同的事情
Transformer模型框架
- 前馈层
两个线性层,之间用Relu连接
- 剩余连接
将块的输入添加到其输出中
- 图层归一化
Add & Norm
- 位置编码
lti-attention
模型专注于不同的事情
Transformer模型框架
- 前馈层
两个线性层,之间用Relu连接
- 剩余连接
将块的输入添加到其输出中
- 图层归一化
Add & Norm
- 位置编码
我们有两组嵌入:token(像往常一样)和仓位(此模型所需的新嵌入)。然后,token的输入表示形式是两个嵌入的总和:token和位置。















 9957
9957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









