






关于iPython笔记本
iPython Notebook是嵌入在网页中的交互式编码环境。 你将在此类中使用iPython笔记本。 你只需要在### START CODE HERE ###和### END CODE HERE ###注释之间编写代码。 编写代码后,通过按“ SHIFT” +“ ENTER”或单击笔记本上部栏中的“Run Cell”来运行该单元块。
我们通常会在注释中说明“(≈X行代码)”,以告诉你需要编写多少行代码。 当然这只是一个粗略的估计,当你的代码更长或更短时,也不用在意。
这里学生本人直接下载了Anaconda。
练习:运行下面的两个单元格中将test设为“ Hello World”,并输出“ Hello World”。

你需要记住以下几点:
-使用SHIFT + ENTER(或点击“Run cell”)运行单元格
-使用Python 3在指定区域内编写代码
-请勿在指定区域以外修改代码
1-使用numpy构建基本函数
Numpy是Python中主要的科学计算包。它由一个大型社区维护。在本练习中,你将学习一些关键的numpy函数,例如np.exp,np.log和np.reshape。你需要知道如何使用这些函数去完成将来的练习。
1.1- sigmoid function和np.exp()
在使用np.exp()之前,你将使用math.exp()实现Sigmoid函数。然后,你将知道为什么np.exp()比math.exp()更可取。
练习:构建一个返回实数x的sigmoid的函数。将math.exp(x)用于指数函数。
提示:![]() 有时也称为逻辑函数。它是一种非线性函数,即可用于机器学习(逻辑回归),也能用于深度学习。
有时也称为逻辑函数。它是一种非线性函数,即可用于机器学习(逻辑回归),也能用于深度学习。
要引用特定程序包的函数,可以使用package_name.function()对其进行调用。运行下面的代码查看带有math.exp()的示例。

预期输出:
0.9525741268224334
因为函数的输入是实数,所以我们很少在深度学习中使用“math”库。 而深度学习中主要使用的是矩阵和向量,因此numpy更为实用。



练习:使用numpy实现sigmoid函数。
说明:x可以是实数,向量或矩阵。 我们在numpy中使用的表示向量、矩阵等的数据结构称为numpy数组。现阶段你只需了解这些就已足够。
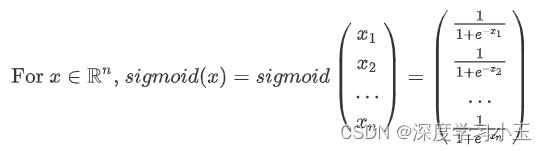
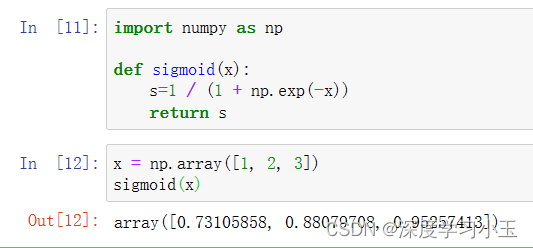
预期输出:
array([ 0.73105858, 0.88079708, 0.95257413])
1.2- Sigmoid gradient
正如你在教程中所看到的,我们需要计算梯度来使用反向传播优化损失函数。 让我们开始编写第一个梯度函数吧。
练习:创建函数sigmoid_grad()计算sigmoid函数相对于其输入x的梯度。 公式为:![]()
我们通常分两步编写此函数代码:
1.将s设为x的sigmoid。 你可能会发现sigmoid(x)函数很方便。
2.计算![]()
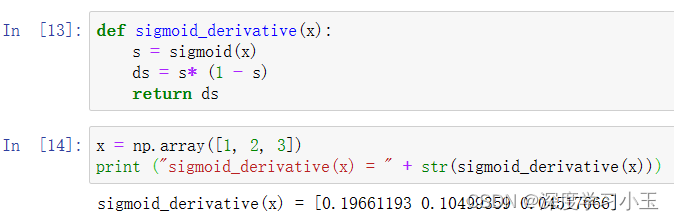
预期输出:
sigmoid_derivative([1,2,3]) = [ 0.19661193 0.10499359 0.04517666]

练习:实现image2vector() ,该输入采用维度为(length, height, 3)的输入,并返回维度为(length*height*3, 1)的向量。例如,如果你想将形为(a,b,c)的数组v重塑为维度为(a*b, 3)的向量,则可以执行以下操作:
v = v.reshape((v.shape[0]*v.shape[1], v.shape[2])) # v.shape[0] = a ; v.shape[1] = b ; v.shape[2] = c
-请不要将图像的尺寸硬编码为常数。而是通过image.shape [0]等来查找所需的数量。


练习:执行 normalizeRows()来标准化矩阵的行。 将此函数应用于输入矩阵x之后,x的每一行应为单位长度(即长度为1)向量。
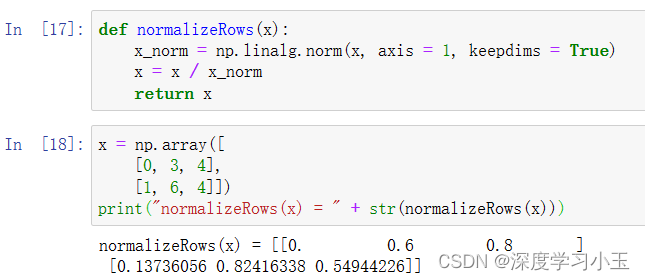
注意:
在normalizeRows()中,你可以尝试print查看 x_norm和x的维度,然后重新运行练习cell。 你会发现它们具有不同的w维度。 鉴于x_norm采用x的每一行的范数,这是正常的。 因此,x_norm具有相同的行数,但只有1列。 那么,当你将x除以x_norm时,它是如何工作的? 这就是所谓的广播broadcasting,我们现在将讨论它!
1.5- 广播和softmax函数
在numpy中要理解的一个非常重要的概念是“广播”。 这对于在不同形状的数组之间执行数学运算非常有用。 有关广播的完整详细信息,你可以阅读官方的broadcasting documentation.
练习: 使用numpy实现softmax函数。 你可以将softmax理解为算法需要对两个或多个类进行分类时使用的标准化函数。 你将在本专业的第二门课中了解有关softmax的更多信息。
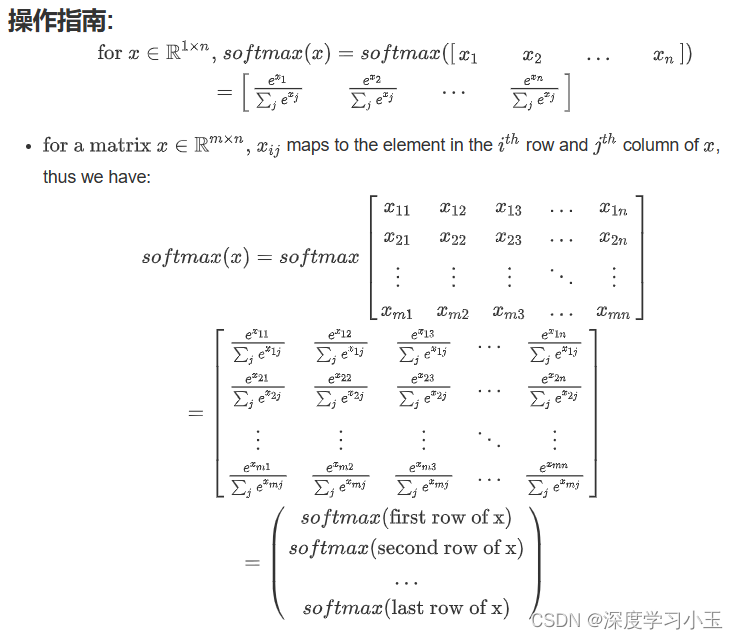
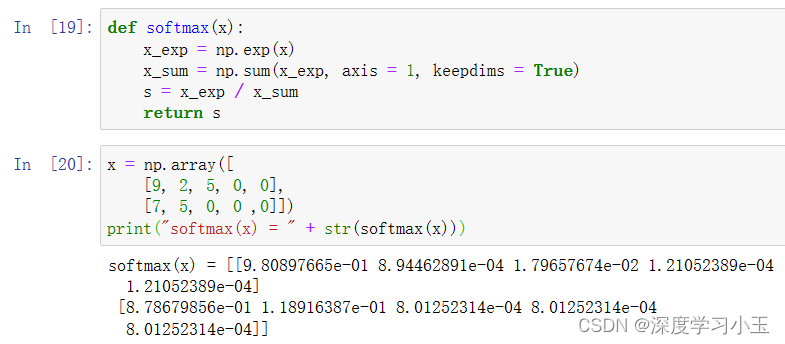
注意:
-如果你在上方输出 x_exp,x_sum和s的维度并重新运行练习单元,则会看到x_sum的纬度为(2,1),而x_exp和s的维度为(2,5)。 x_exp/x_sum 可以使用python广播。
恭喜你! 你现在已经对python numpy有了很好的理解,并实现了一些将在深度学习中用到的功能。
你需要记住的内容:
-np.exp(x)适用于任何np.array x并将指数函数应用于每个坐标
-sigmoid函数及其梯度
-image2vector通常用于深度学习
-np.reshape被广泛使用。 保持矩阵/向量尺寸不变有助于我们消除许多错误。
-numpy具有高效的内置功能
-broadcasting非常有用
2-向量化
在深度学习中,通常需要处理非常大的数据集。 因此,非计算最佳函数可能会成为算法中的巨大瓶颈,并可能使模型运行一段时间。 为了确保代码的高效计算,我们将使用向量化。 例如,尝试区分点/外部/元素乘积之间的区别。
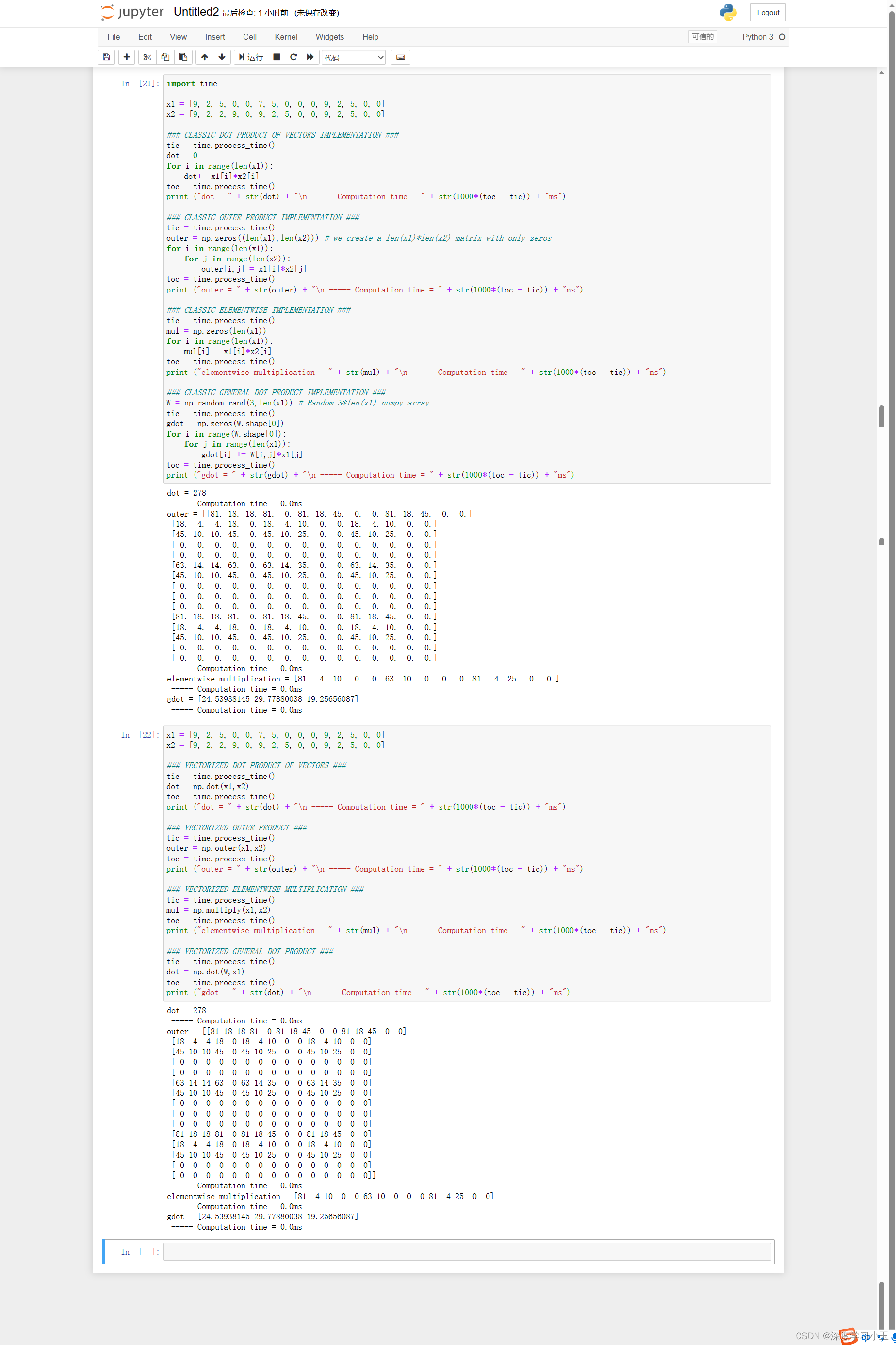
你可能注意到了,向量化的实现更加简洁高效。 对于更大的向量/矩阵,运行时间的差异变得更大。(下图为向量化)
注意 不同于np.multiply()和* 操作符(相当于Matlab / Octave中的 .*)执行逐元素的乘法,np.dot()执行的是矩阵-矩阵或矩阵向量乘法。




你需要记住的内容:
-向量化在深度学习中非常重要, 它保证了计算的效率和清晰度。
-了解L1和L2损失函数。
-掌握诸多numpy函数,例如np.sum,np.dot,np.multiply,np.maximum等。
用神经网络思想实现Logistic回归
欢迎来到你的第一个编程作业! 你将学习如何建立逻辑回归分类器用来识别猫。 这项作业将引导你逐步了解神经网络的思维方式,同时磨练你对深度学习的直觉。
说明:
除非指令中明确要求使用,否则请勿在代码中使用循环(for / while)。
你将学习以下内容:
- 建立学习算法的一般架构,包括:
- 初始化参数
- 计算损失函数及其梯度
- 使用优化算法(梯度下降)
- 按正确的顺序将以上所有三个功能集成到一个主模型上。
2- 问题概述
问题说明:你将获得一个包含以下内容的数据集("data.h5"):
- 标记为cat(y = 1)或非cat(y = 0)的m_train训练图像集
- 标记为cat或non-cat的m_test测试图像集
- 图像维度为(num_px,num_px,3),其中3表示3个通道(RGB)。 因此,每个图像都是正方形(高度= num_px)和(宽度= num_px)。
你将构建一个简单的图像识别算法,该算法可以将图片正确分类为猫和非猫。
让我们熟悉一下数据集吧, 首先通过运行以下代码来加载数据。
我们在图像数据集(训练和测试)的末尾添加了"_orig",以便对其进行预处理。 预处理后,我们将得到train_set_x和test_set_x(标签train_set_y和test_set_y不需要任何预处理)。
train_set_x_orig和test_set_x_orig的每一行都是代表图像的数组。 你可以通过运行以下代码来可视化示例。 还可以随意更改index值并重新运行以查看其他图像。
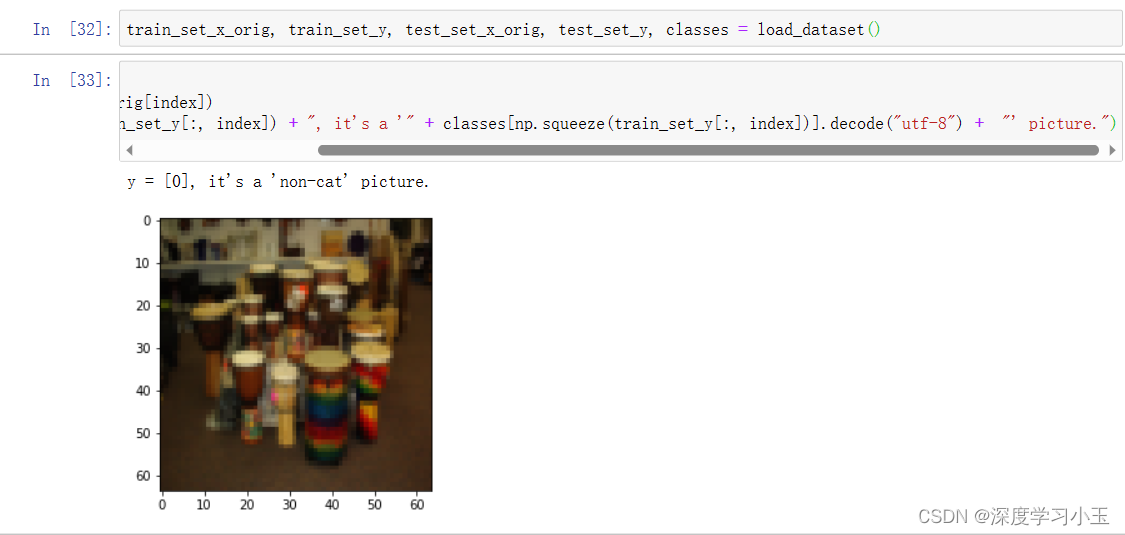
深度学习中的许多报错都来自于矩阵/向量尺寸不匹配。 如果你可以保持矩阵/向量的尺寸不变,那么将消除大多错误。
练习: 查找以下各项的值:
- m_train(训练集示例数量)
- m_test(测试集示例数量)
- num_px(=训练图像的高度=训练图像的宽度)
请记住,“ train_set_x_orig”是一个维度为(m_train,num_px,num_px,3)的numpy数组。 例如,你可以通过编写“ train_set_x_orig.shape [0]”来访问“ m_train”。
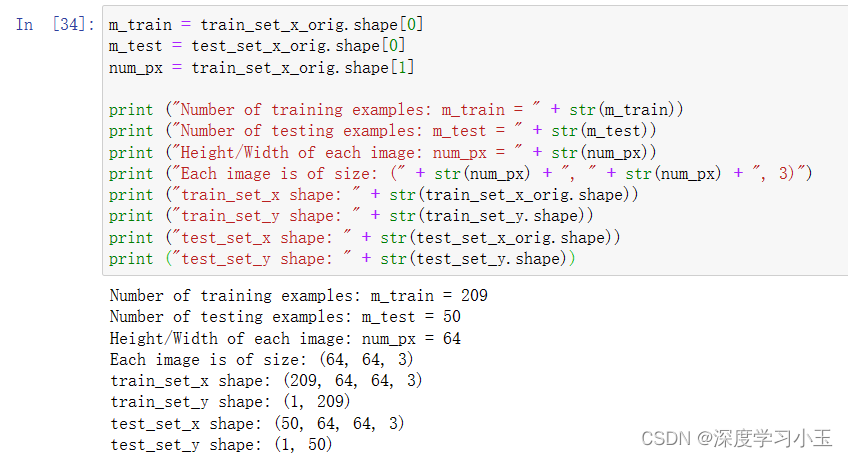
预期输出:
训练集数量:m_train = 209
测试集数量:m_test = 50
每个图像的高度/宽度:num_px = 64
每个图像的大小:(64,64,3)
train_set_x维度:(209、64、64、3)
trainsety维度:(1,209)
test_set_x维度:(50、64、64、3)
test_set_y维度:(1,50)
为了方便起见,你现在应该以维度(num_px ∗ num_px ∗ 3, 1)的numpy数组重塑维度(num_px,num_px,3)的图像。 此后,我们的训练(和测试)数据集是一个numpy数组,其中每列代表一个展平的图像。 应该有m_train(和m_test)列。
练习: 重塑训练和测试数据集,以便将大小(num_px,num_px,3)的图像展平为单个形状的向量(num_px ∗ num_px ∗ 3, 1)。
当你想将维度为(a,b,c,d)的矩阵X展平为形状为(b∗c∗d, a)的矩阵X_flatten时的一个技巧是:X_flatten = X.reshape(X.shape [0],-1).T # 其中X.T是X的转置矩阵
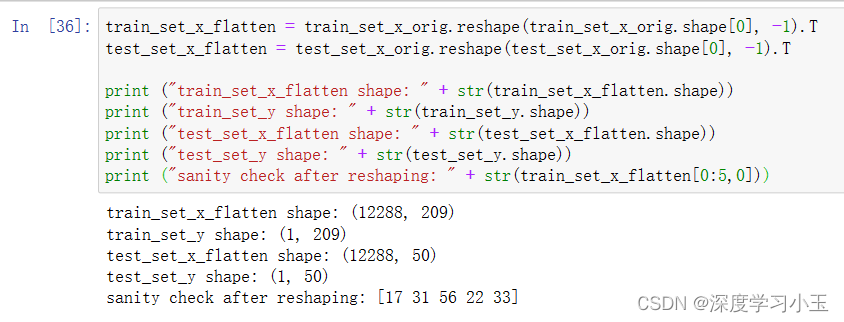
预期输出:
train_set_x_flatten维度:(12288,209)
trainsety维度:(1,209)
test_set_x_flatten维度:(12288,50)
test_set_y维度:(1,50)
重塑后的检查维度:[17 31 56 22 33]
为了表示彩色图像,必须为每个像素指定红、绿、蓝色通道(RGB),因此像素值实际上是一个从0到255的三个数字的向量。
机器学习中一个常见的预处理步骤是对数据集进行居中和标准化,这意味着你要从每个示例中减去整个numpy数组的均值,然后除以整个numpy数组的标准差。但是图片数据集则更为简单方便,并且只要将数据集的每一行除以255(像素通道的最大值),效果也差不多。
在训练模型期间,你将要乘以权重并向一些初始输入添加偏差以观察神经元的激活。然后,使用反向梯度传播以训练模型。但是,让特征具有相似的范围以至渐变不会爆炸是非常重要的。具体内容我们将在后面的教程中详细学习!
开始标准化我们的数据集吧!

你需要记住的内容:
预处理数据集的常见步骤是:
- 找出数据的尺寸和维度(m_train,m_test,num_px等)
- 重塑数据集,以使每个示例都是大小为(num_px \ num_px \ 3,1)的向量
- “标准化”数据
3- 学习算法的一般架构
现在是时候设计一种简单的算法来区分猫图像和非猫图像了。
你将使用神经网络思维方式建立Logistic回归。 下图说明了为什么“逻辑回归实际上是一个非常简单的神经网络!”
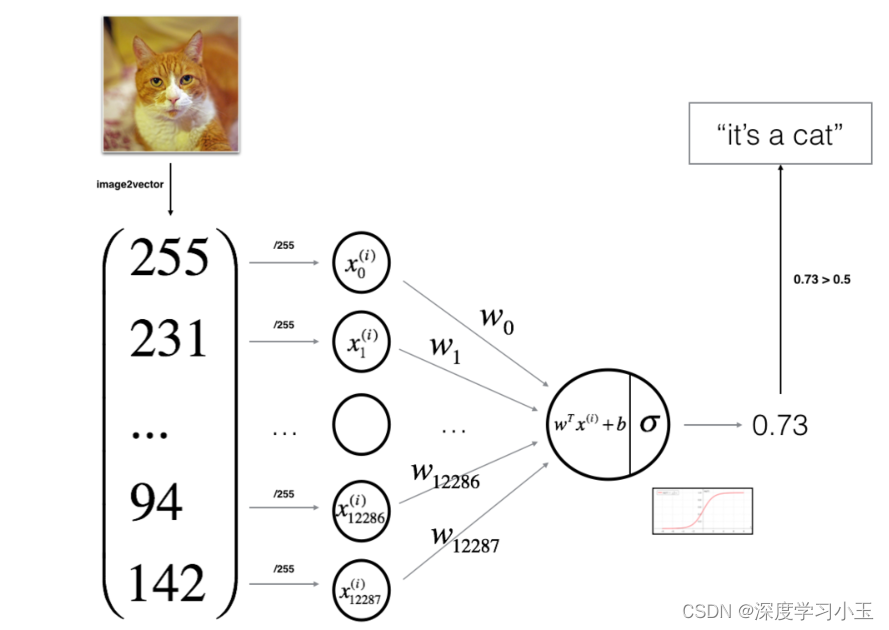

关键步骤:
在本练习中,你将执行以下步骤:
- 初始化模型参数
- 通过最小化损失来学习模型的参数
- 使用学习到的参数进行预测(在测试集上)
- 分析结果并得出结论
4- 构建算法的各个部分
建立神经网络的主要步骤是:
1.定义模型结构(例如输入特征的数量)
2.初始化模型的参数
3.循环:
- 计算当前损失(正向传播)
- 计算当前梯度(向后传播)
- 更新参数(梯度下降)
你通常会分别构建1-3,然后将它们集成到一个称为“ model()”的函数中。


4.2- 初始化参数
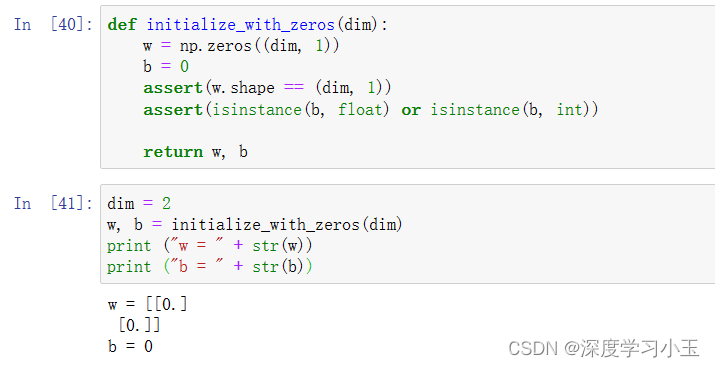
练习: 在下面的单元格中实现参数初始化。 你必须将w初始化为零的向量。 如果你不知道要使用什么numpy函数,请在Numpy库的文档中查找np.zeros()。





你需要记住以下几点:
你已经实现了以下几个函数:
- 初始化(w,b)
- 迭代优化损失以学习参数(w,b):
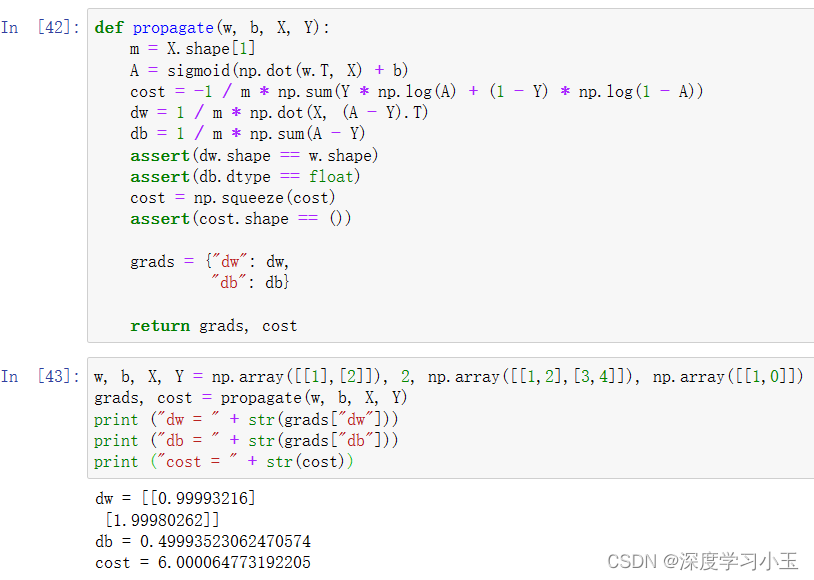
- 计算损失及其梯度
- 使用梯度下降更新参数
- 使用学到的(w,b)来预测给定示例集的标签
5- 将所有功能合并到模型中
现在,将所有构件(在上一部分中实现的功能)以正确的顺序放在一起,从而得到整体的模型结构。
练习: 实现模型功能,使用以下符号:
- Y_prediction对测试集的预测
- Y_prediction_train对训练集的预测
- w,损失,optimize()输出的梯度
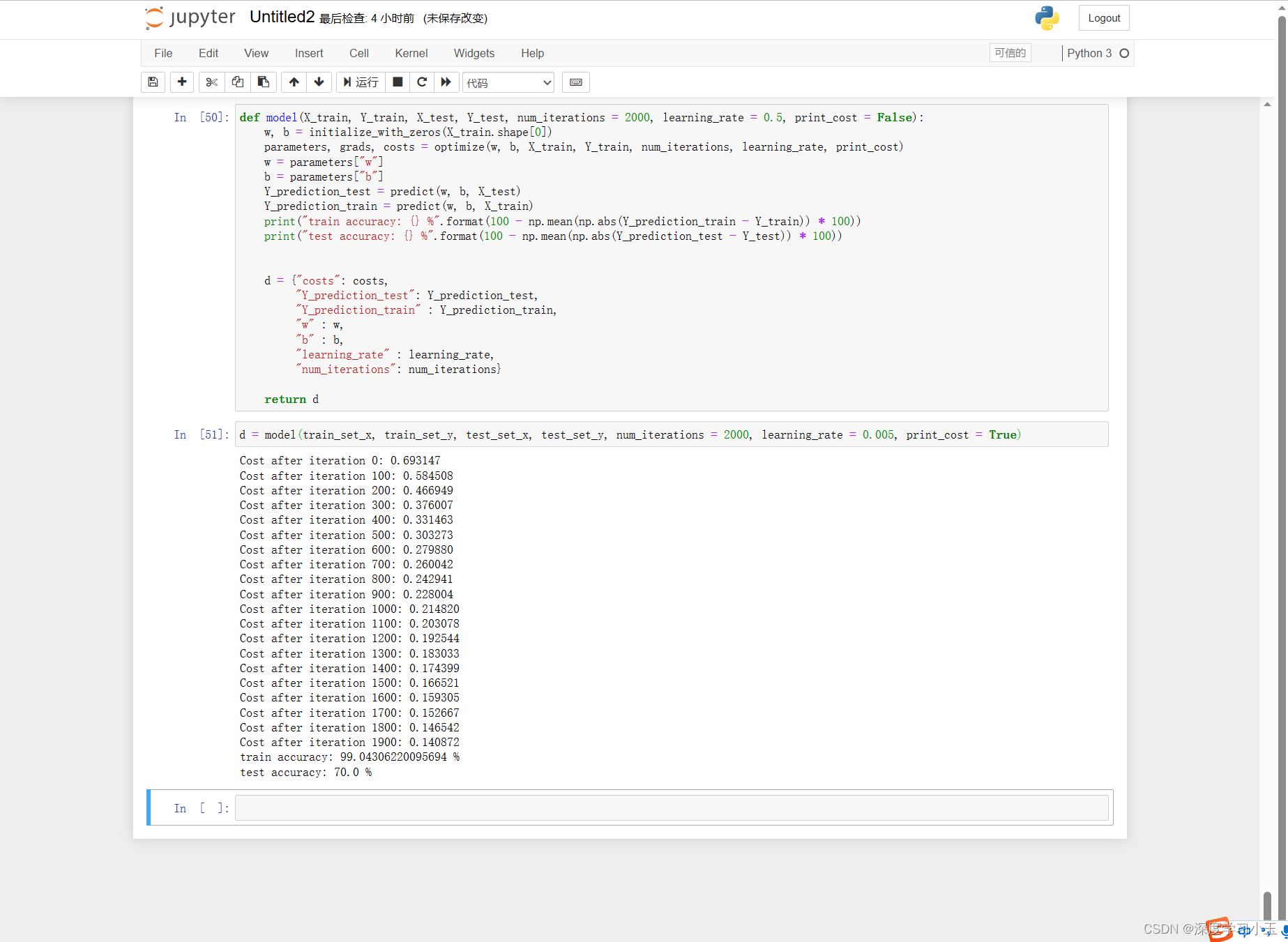
评价:训练准确性接近100%。 这是一个很好的情况:你的模型正在运行,并且具有足够的容量来适合训练数据。 测试误差为68%。 考虑到我们使用的数据集很小,并且逻辑回归是线性分类器,对于这个简单的模型来说,这实际上还不错。 但请放心,下周你将建立一个更好的分类器!
此外,你会看到该模型明显适合训练数据。 在本专业的稍后部分,你将学习如何减少过度拟合,例如通过使用正则化。 使用下面的代码(并更改index变量),你可以查看测试集图片上的预测。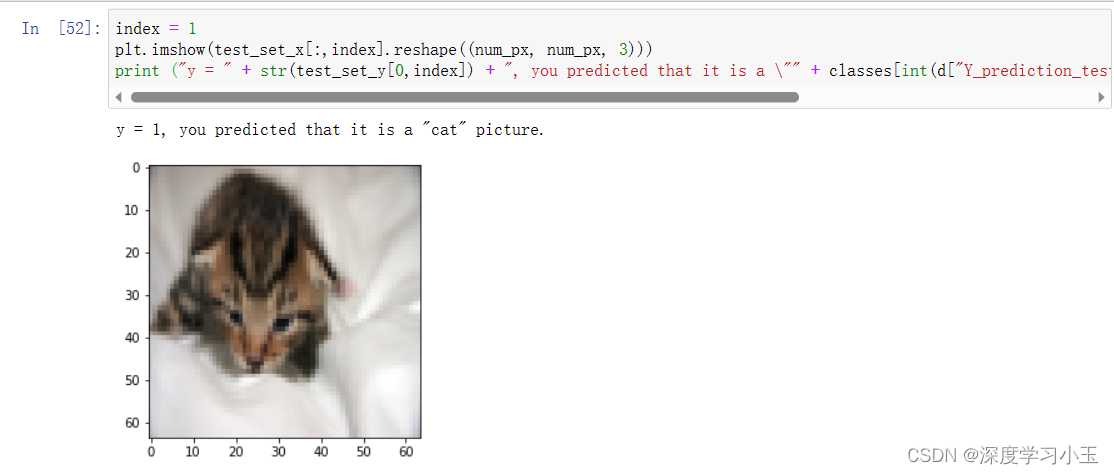
损失函数和梯度

解释:
损失下降表明正在学习参数。 但是,你看到可以在训练集上训练更多模型。 尝试增加上面单元格中的迭代次数,然后重新运行这些单元格。 你可能会看到训练集准确性提高了,但是测试集准确性却降低了。 这称为过度拟合。















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









