







CAT-Net:用于图像拼接检测和定位的压缩伪迹跟踪网络
发布于WACV2021
代码链接:https://github.com/mjkwon2021/CAT-Net
摘要
检测和定位图像拼接已经成为打击恶意伪造的重要手段。局部拼接区域的一个主要挑战是区分真实和篡改的区域的固有属性,如压缩伪迹。我们提出了CAT-Net,一个包含RGB和DCT流的端到端全卷积神经网络,以共同学习RGB和DCT域压缩伪影的取证特征。每个流考虑多重分辨率来处理拼接对象的各种形状和大小。DCT流在双JPEG检测时被预先训练以利用JPEG伪影。该方法在JPEG或非JPEG图像的局部拼接区域的定位上优于最先进的神经网络。
引言
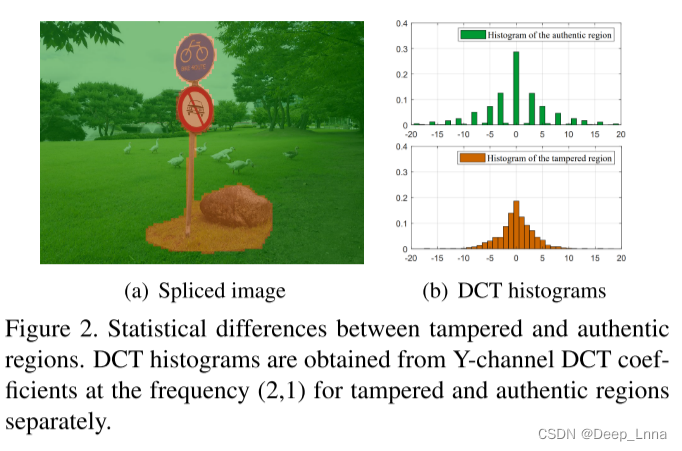
给定一个可能被拼接的图像(图1©),我们的目标是生成一个掩码来定位可能被篡改的图像部分(图1(d))。为了区分拼接区域和真实区域,重要的是分析相机或图像编辑软件内部处理引起的统计指纹(如传感器图案噪声、彩色滤波器阵列的插值迹、压缩伪影等)。现代数码相机通常压缩图像以减少存储空间,JPEG压缩由于其效率,在大多数情况下被使用。然而,由于信息丢失,这会生成各种JPEG伪迹,尽管它们通常是肉眼不可见的。因此,分析JPEG压缩构件可以帮助定位伪造区域。

双JPEG检测,即,确定一个JPEG图像是否被压缩了一两次,可以帮助识别拼接伪造。与真实区域相比,拼接到另一幅图像上的区域在y通道上的DCT系数分布可能有统计学上的差异(图2)。真实区域被双重压缩:首先在相机中,然后作为伪造的一部分再次压缩,在直方图中留下周期性的模式。拼接区域的行为类似于单个压缩,位于次级量化表之后。传统上,DCT直方图被用来检测双JPEG压缩。即使在深度学习时代,深度神经网络也倾向于要求将经过预处理的直方图作为输入,因为与像素不同,由于DCT系数去相关性较大,天真地给出DCT系数作为输入通常效果不佳。由于使用直方图,所有这些方法都产生小块预测。因此,我们采用DCT系数的二值体表示来获得像素预测,这最初是为隐写分析设计的。这允许将语义分割网络与双JPEG检测概念相结合,提供像素级预测。
本文提出压缩伪迹跟踪网络(CAT-Net),一种端到端的全卷积神经网络,用于检测和定位拼接区域。该网络包括RGB流、DCT流和最终融合阶段。RGB流学习视觉伪影,DCT流学习压缩伪影(即DCT系数分布)。我们预训练DCT流用于双JPEG检测,并使用它作为拼接定位的初始化。融合阶段融合来自两个流的多个分辨率特征,生成最终的掩模。
主要贡献
- CAT-Net首次结合RGB和DCT域对拼接对象进行局部定位。使用不同基准数据集进行的大量实验表明,与基线相比,CAT-Net取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









