







Towards JPEG-resistant Image Forgery Detection and Localization via Self-supervised Domain Adaptation
基于自监督域自适应的抗jpeg图像伪造检测与定位
发布于TPAMI2022
前身:
Self-supervised Domain Adaptation for Forgery Localization of JPEG Compressed Images
JPEG压缩图像的自监督域自适应伪造定位
发布于ICCV2021
摘要
虽然现有的图像伪造定位方法可以在多个公共数据集上取得较好的定位效果,但是在社交网络中常用的 JPEG 压缩方法中,大多数方法的定位效果较差。
针对这一问题,本文提出了一种自监督域自适应网络,该网络由具有Siamese结构的骨干网络和压缩近似网络(ComNet)组成,用于抗 JPEG 图像伪造的检测和定位。为了提高对 JPEG 压缩的性能,ComNet 通过自监督学习来逼近 JPEG 压缩操作,生成具有一般 JPEG 压缩特性的 JPEG 代理图像。然后采用域自适应策略对骨干网络进行训练,定位篡改边界和区域。在几个公共数据集上的大量实验结果表明,该方法在图像伪造检测和定位方面优于或竞争其他最先进的方法,特别是对于 QF 未知的 JPEG 压缩。
先导知识
Siamese结构
又叫做孪生网络,它从数据中去学习一个相似性度量,用这个学习出来的度量去比较和匹配新的未知类别的样本。
Siamese结构是通过共享权值来实现的。共享权值在代码实现的时候,左右两个神经网络甚至可以是同一个网络,不用实现另外一个,因为权值都一样。对于Siamese网络,两边可以是LSTM或者CNN,都可以。
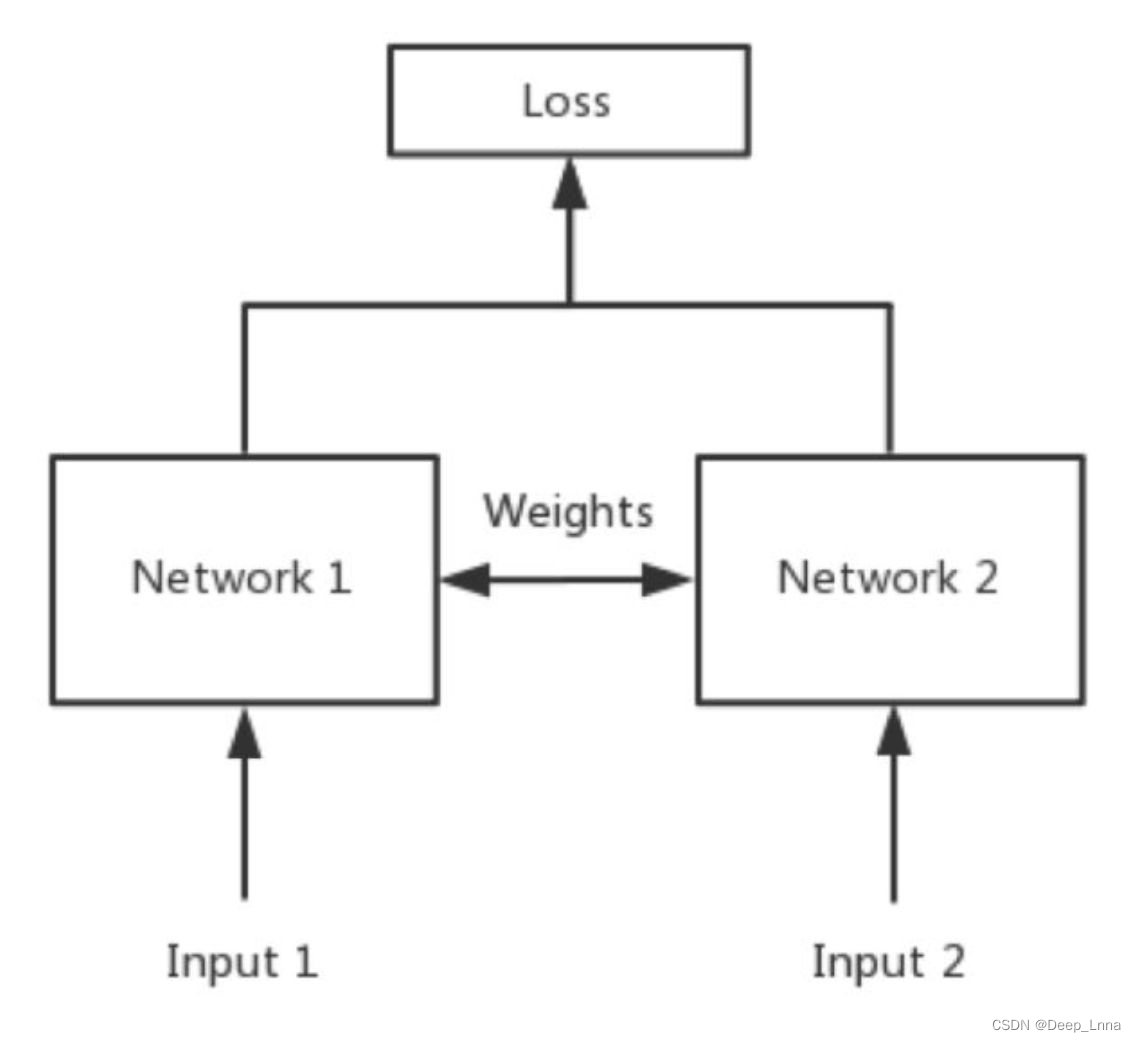
孪生神经网络的用途是什么?
简单来说,衡量两个输入的相似程度。孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
引言
由于存在滤波、重采样、压缩等后处理操作,使得图像篡改定位任务更具挑战性。在这些内容保存操作中,JPEG压缩在社交网络中被广泛用于减少传输带宽或存储空间。然而,在强JPEG压缩后,微小的篡改伪影将被消除,从而降低了伪造取证方法的性能。另一方面,图像篡改操作的多样性,如拼接、复制-移动、删除等,也严重影响了取证方法对看不见的伪造的泛化能力。
基于深度学习的方法利用大量训练样本和多个伪造的优点,在图像伪造检测和定位方面比传统方法有更好的表现。另一方面,为了获得对JPEG压缩更好的鲁棒性,基于深度学习的方法通常会对各种质量因子(QF)篡改的JPEG图像进行有针对性的数据扩充策略训练网络模型。
然而,这在以下几个方面存在不足:
- 一定程度上削弱了边界转换,这与JPEG压缩丢弃的高频成分相对应,因此增加了捕获伪造操作的内在特征表示的难度;
- 要求不同的JPEG样本,以缓解训练阶段和测试阶段采用的JPEG压缩不匹配,这取决于启发式选择QF。
这两个问题使得基于深度学习的方法在对JPEG压缩进行数据增强时性能下降,特别是在训练集较小的情况下。
针对上述问题,本文从数据扩充角度出发,提出一种基于自监督领域自适应的JPEG压缩图像篡改定位网络,如图1所示。该网络由一个孪生骨干网络和一个压缩近似网络(ComNet)组成,其核心思想在于利用自监督学习策略训练ComNet表征JPEG压缩操作,使其生成图像(JPEG代理图像Ia)与随机QF的真实JPEG压缩图像Ic相似,从而使JPEG代理图像具有更普遍的JPEG压缩特性,且保留篡改痕迹。同时,骨干网络采用领域自适应策略进行训练,源领域和目标领域分别对应无压缩图像和JPEG代理图像。通过使两种领域提取的特征相似,网络既能在源领域提取篡改操作的固有特征,又能在目标领域捕获JPEG压缩下的篡改效应,从而提高网络模型对抗JPEG压缩攻击的鲁棒性。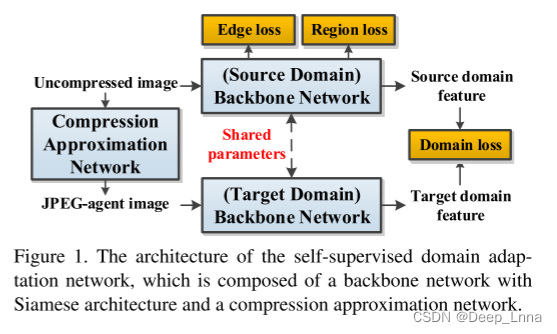
主要贡献
- 提出了一种基于条件随机场(CRF)的注意模块来突出伪造区域过渡边界。与[9]中采用单空间核和递归卷积实现的简化CRF模型不同,我们构建了一个标准CRF来更好地刻画局部模式相关性,并实现了CRF推理的平均场近似迭代。
- 提出了一种基于encoder-decoder的ComNet,通过自监督学习任务逼近JPEG压缩操作,生成具有一般JPEG压缩特性的JPEG代理图像。
- 为了提高对JPEG压缩的性能,应用域自适应策略来缓解源领域(未压缩图像)和目标领域(JPEG代理图像)之间的域转移。
自监督领域自适应网络
下面介绍所提出的自监督域自适应网络的三个关键设计,包括:1)骨干网;2)压缩近似网络(ComNet);3)域自适应策略。如图1所示,骨干网采用Siamese网络架构,由两个参数共享的并行子网组成,源领域和目标领域分别由ComNet生成的未压缩图像和JPEG代理图像组成。
骨干网
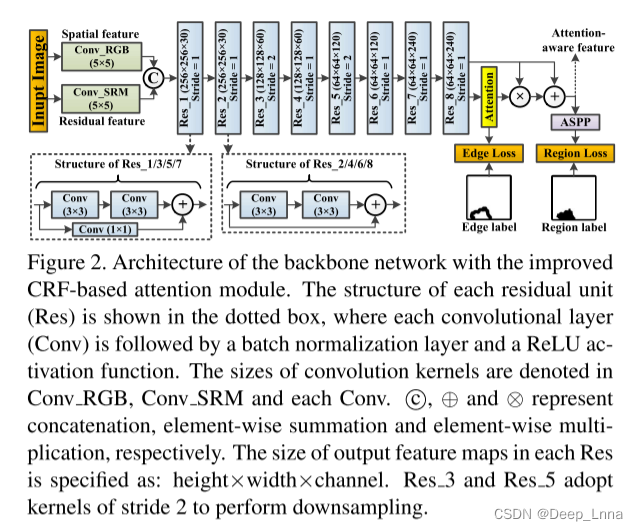
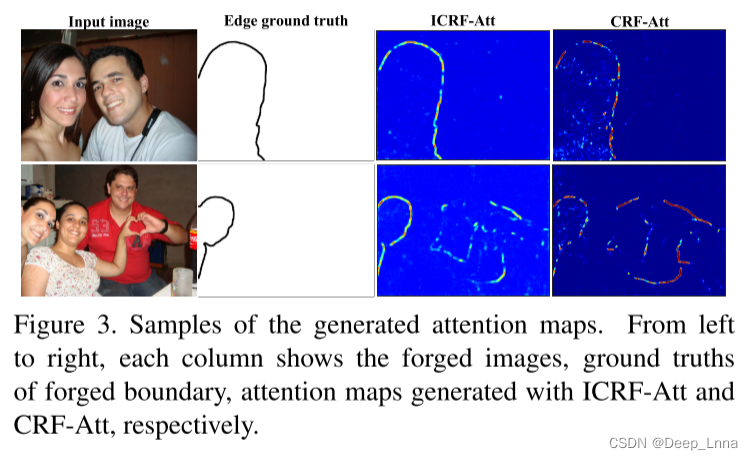
子网络的架构如图2所示。具体来说,为了在空间和残差域中捕获更多的篡改伪影,采用两个并行卷积层来提取双域特征,其中初始化策略应用于Conv_SRM中的内核。接下来的八个残差模块用于提取不同尺度的分层特征。然后是一个注意力模块,以突出伪造区域的边界。将CRF转换为注意力模型(CRF-Att),用于表征局部模式相关性,我们提出了一个改进的基于CRF的注意力模块(ICRF-Att),如下图3所示,其中包含平均场近似的可微实现(MFA)以更充分地利用具有三个空间核的局部模式相关性和仅一次MFA迭代以降低计算成本。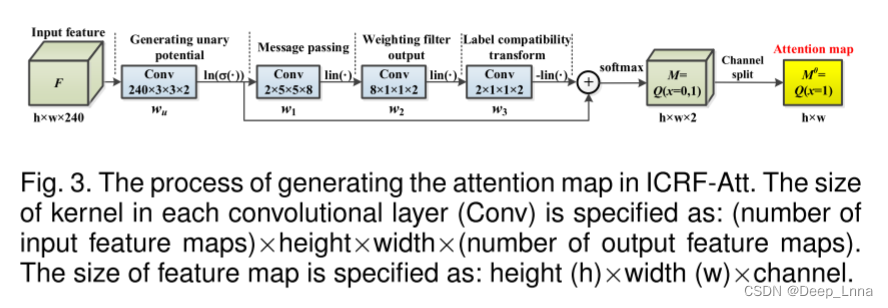
为了说明ICRF-Att的优越性,我们将M0可视化,生成的注意力图的例子如图3所示。由于更好地利用了局部相关性,与CRF-Att相比,ICRF-Att更准确地描绘了伪造的边界,具有罕见的错误警报。在效率方面,与CRF-Att相比,ICRF-Att可以在每次前向传递中减少两个卷积运算。
最后,以四个不同采样率的平行卷积层组成的**空间金字塔池(ASPP)**作为输入H,利用多尺度特征生成细粒度定位结果。 具体而言,利用ASPP生成的融合特征映射通过双线性插值将其上采样到原始图像分辨率,然后利用通道Softmax运算生成篡改概率映射。 由于该篡改概率图比二值映射具有更多的信息量,因此该篡改概率映射被视为伪造定位结果,其值越大代表被伪造的概率越高。
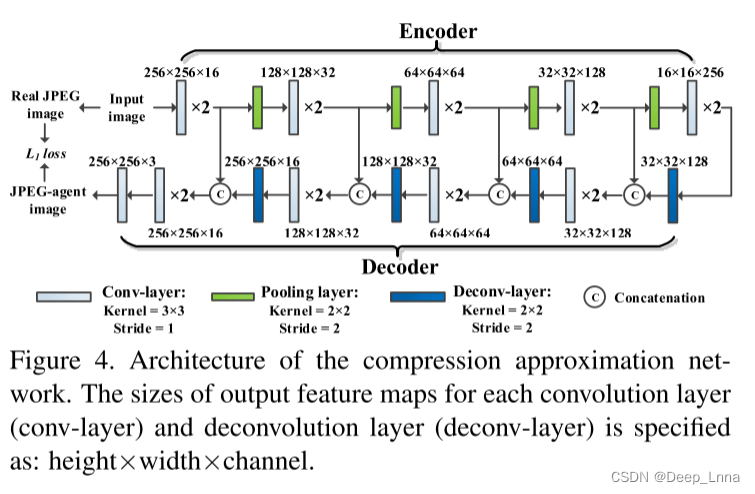
压缩近似网络
为了提高抗JPEG压缩的性能,我们打算构造一种JPEG代理图像,它具有一般的JPEG压缩特性,而不是那些与特定质量因子(QF)相关的特性。为此,我们提出了一种压缩近似网络,即ComNet,来近似JPEG压缩操作,而不考虑QF。这可以从自监督学习任务中有效地学习。具体而言,如图4所示,基于在镜像层之间具有跳跃连接的encoder-decoder网络,ComNet从输入的未压缩图像I生成JPEG代理图像Ia。注意,I是没有JPEG压缩的伪造图像,而不是真实图像。目标图像,即真实的JPEG图像Ic,是使用标准JPEG压缩算法用随机QF从I压缩的。根据我们的实验,L2损失对离群值的鲁棒性低于L1损失。因此,ComNet通过最小化Ia和Ic之间的L1损失进行训练,如下所示:
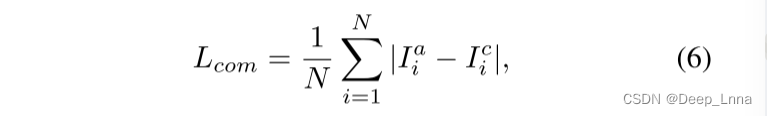
其中i为像素索引,N为像素个数。通过合并包含多个QF的JPEG特性,使用ComNet生成的Ia,即JPEG代理图像,预计会比实际的JPEG图像本身表现出更普遍的JPEG压缩特性,而实际的JPEG图像本身也能够泛化为没有QF的JPEG图像。
领域适应策略
为了进行抗JPEG图像伪造定位,不直接将训练集与JPEG或JPEG代理样本混合,将领域适应策略应用于源领域和目标领域,分别对应于未压缩图像和JPEG代理图像。域自适应可以在捕获源域中固有篡改伪影的同时,对目标域中JPEG压缩具有更好的泛化能力。对骨干网进行三种损失的组合训练:1)区域损失(region loss, Lr)进行像素级分类;2)边缘损失(Le)用于生成锻造边界的注意图;3)领域损失(Ld),用于减少领域转移,将有效知识从源转移到目标领域。注意,Lr和Le仅在源域中计算。分别表示为公式5中从未压缩图像和JPEG代理图像中提取的注意感知特征H和Ha,所涉及的损失计算如下:
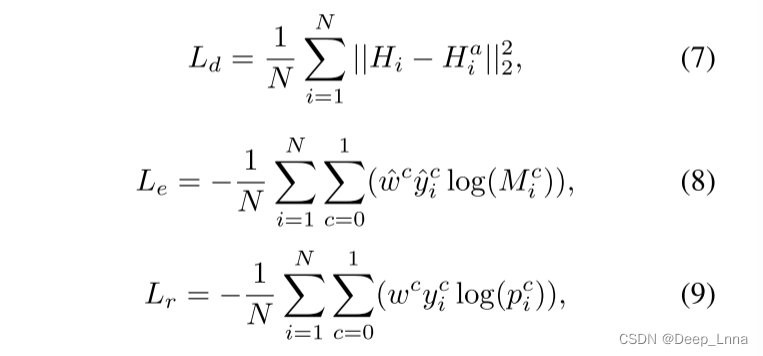
其中i为空间位置索引,N为元素个数。pc和Mc分别表示ASPP的softmax输出和注意图的c类概率。ˆy代表“伪造的边缘”,y代表“gt”。ˆwc和wc分别为c类中避免模型偏差的权重,分别对应ˆy和y。最后,最小化总损失函数如下:
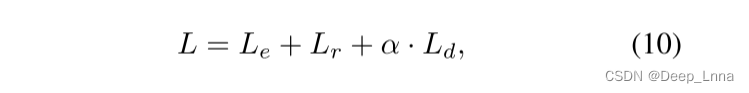
其中超参数α控制不同任务之间的平衡。
实验结果及分析
数据集
为了更好的表现泛化能力,我们对10个数据集进行了跨数据集评估,避免了与数据集相关的极化现象,总结如表1所示。
- 在IEEE取证挑战(IFC)数据集上训练提出的方法,该数据集只包含未经压缩的经过拼接和复制-移动操作的图像,而在其他不可见的数据集上测试性能。
对于测试数据集
- DSO-1数据集主要用于检测包含人的拼接图像。
- Coverage数据集用于检测多个相似但真实对象之间的复制-移动操作。
- Korus数据集包括仅由四个相机获得的真实伪造图像。
- 其他数据集涵盖了包括拼接、复制和删除在内的各种伪造场景,有时甚至在一幅图像中包含一系列伪造操作和随机后处理操作。其中6个数据集包括JPEG压缩图像,其中涉及的压缩操作不公开。
- 几个现有数据集的一个潜在缺点是,它们可能不能代表在线上遇到的各种伪造,因为在互联网上流通的真实世界的伪造与大多数研究论文中使用的典型评估数据集中包含的图像明显不同。为了解决这个问题,我们评估了In-the-Wild数据集和Wild Web数据集上的性能。前者包括从恶搞新闻网站(The Onion)和Reddit Photoshop Battles上得到的伪造图像,后者是一个由用户创建和分享被操纵图像的在线社区。 后者包括从各种社交媒体中收集的真实世界拼接图像,由于压缩和重新缩放等多重后处理操作,这更具有挑战性。

消融研究
注意模块(ICRF-Att)、JPEG-agent图像(Ia)和域适应(DA)策略,如表2所示。
在Nim.16、DSO-1和wild Web数据集上,分别以F1-score (F1)和Matthews Correlation Coefficient (MCC)来比较定位性能。
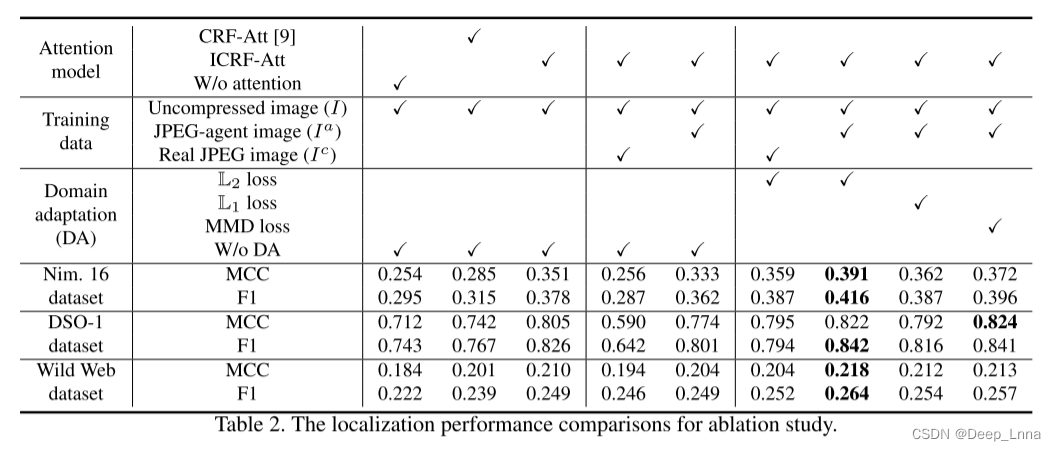
- ICRF-Att:可以看到,与ICRF-Att合并的网络始终明显优于那些没有注意模型和与CRF-Att合并的网络。
- JPEG代理图像(Ia):用未压缩图像(I)和Ia训练的网络优于用I和真实JPEG图像(Ic)训练的网络,但与仅用I训练的网络相比,效果并不理想。这表明不适当的数据扩充阻止了网络为伪造定位提取更多的内在特征表示。
- 领域适应(DA)策略:采用源域I和目标域Ic之间的DA(简称DA-Ic)或源域I和目标域Ia之间的DA(简称DA-Ia),与在同一数据集上训练的网络相比,获得了一致的性能增益。这是因为DA有助于将捕获篡改伪影的先验知识从I传递到Ic或Ia。在Nim.16、DSO1和Wild Web数据集上,利用DA, DA-Ia在MCC方面分别比DA- Ic高出3.2%、2.7%和1.4%,表明在JPEG代理图像Ia中嵌入了更通用的JPEG压缩特性。此外,我们将L2域损失与L1 (Ld_L1)和MMD (maximum mean discrepancy (MMD)(Ld_M)损失函数进行比较,结果如下:

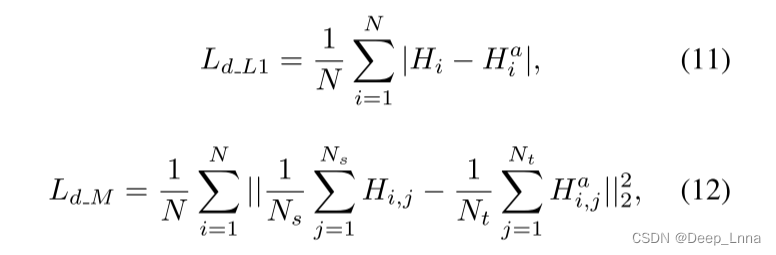
其中,Ns和Nt分别表示小批次的I和Ia的数量,其他变量在式7中采用相同的符号。观察到L2损失达到了最好的性能,这对于缓解所提出的网络的域转移更为有效。
实验结果表明采用JPEG代理图像训练的网络模型(DA-Ia)对JPEG压缩操作的泛化性能优于采用真实JPEG图像训练的网络(DA-Ic)。不同QF的JPEG压缩图像块在DA-Ia和DA-Ic网络模型中的特征分布如图5所示,其包括训练集中已知(QF=65,75)和未知(QF=70,80)的QF。其中(a)和©对应DA-Ia,(b)和(d)对应DA-Ic。Overlap表示重合的特征点。QF=65,70的压缩图像块对应的原始图像块相同,QF=75,80的压缩图像块对应的原始图像块相同。
可以看到,DA-Ia得到的重合点明显多于DA-Ic模型,说明不同QF的图像块之间提取出的特征偏差更小,DA-Ia能很大程度上抑制不同QF对网络的影响,并且可以泛化于检测训练集未知QF的JPEG图像。

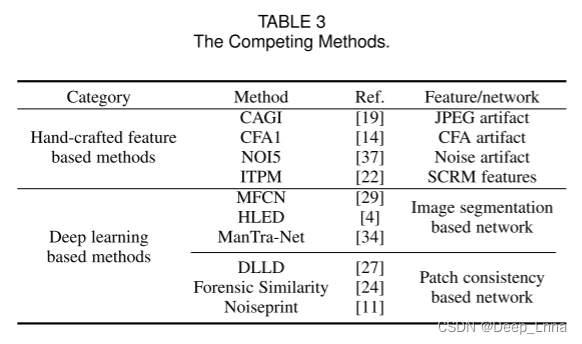
竞争方法
- 传统的基于手工特征的方法,包括CAGI、CFA1、NOI5和ITPM,分别利用基于JPEG、CFA、噪声级伪像的特征,以及SCRM和patch匹配检测器的结合。
- 基于深度学习的方法,能够定位一般的图像伪造操作。包括MFCN , HLED和ManTraNet,它对用于语义分割的网络进行了广义化,以执行像素级伪造定位;DLLD,取证似度(FS)和Noiseprint,通过基于残差和基于相机模型的特征捕捉统计不一致。对于FS,我们报告了10次重复测试的结果,每次我们随机选择一个参考补丁。为了进行公平的比较,除了无监督方法(CAGI、CFA1和NOI5)外,FS、Noiseprint和mantranet都使用它们发布的预训练模型进行测试,而所有剩余的数据驱动方法都在与我们的方法相同的数据集上进行了优化。
伪造检测性能
将提出的处理像素级伪造定位的网络扩展到图像级伪造检测。理想情况下,对于原始图像,篡改概率映射的均值应等于零,而对于伪造图像,篡改概率映射的均值应大于零。因此,对于图像的伪造检测,进行全局平均池化操作,对篡改概率图进行空间平均,从而得到图像的整体被伪造分数。
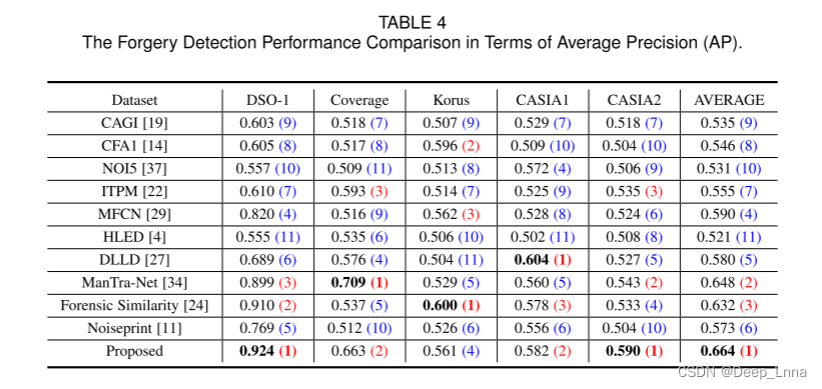
我们现在分别在DSO1、Coverage、Korus、CASIA1和CASIA2数据集上进行图像伪造检测。值得注意的是,在采用的数据集中,正样本(伪造)和负样本(真实)之间保持了很好的平衡,这有利于客观地评价检测性能。我们比较平均精度(AP,即精度-召回率曲线下的面积),并评估平均AP的一般检测性能。括号中的数字表示相关方法在不同数据集上的排名。
如表4所示,本文方法在DSO-1、Coverage、CASIA1和CASIA2 4个数据集上的性能都达到了前2名,并且在DSO-1和CASIA2数据集上的性能一直优于其他所有竞争方法。虽然我们的方法在Korus数据集上排名第四,但仍然获得了最好的平均AP。例如,CFA1只在包含四种相机模型的Korus数据集上表现良好。这与配备拜耳CFA的尼康D90和尼康D7000相机的马赛克伪像过拟合,但与其他相机型号不太吻合。在CASIA1数据集上,DLLD明显优于其他数据集。这是因为在DLLD中使用的基于深度学习的局部描述符对伪造图像原始区域的纹理畸变非常敏感。这些虚警有助于DLLD对伪造图像进行分类,然而,削弱了定位伪造图像的能力,这将在下一小节中进行演示。总体而言,该方法显示出较少的数据集相关极化,并获得了最具通用性的检测性能。
伪造定位性能
表5,6,7分别是在MCC、F1和AP与SOTA方法的比较结果。并计算最后一列中所有数据集的平均性能,括号中各方法在每个数据集上对应的排名。
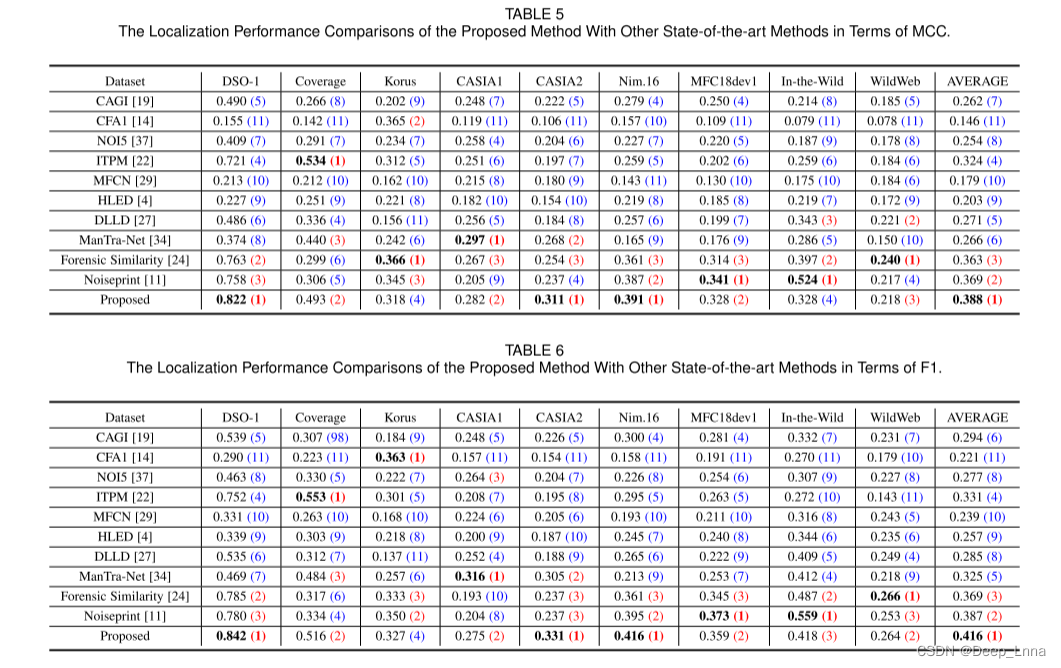
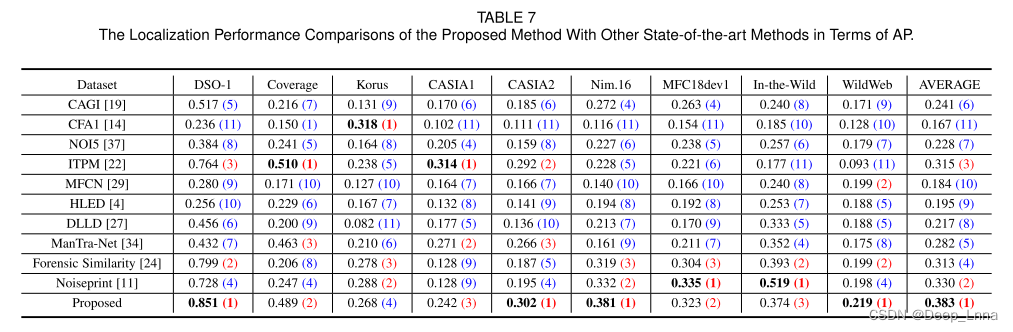
结果表明,除了Korus数据集外,我们提出的方法在每个数据集上都排在前两名,在Korus数据集上也取得了相当的性能。Korus数据集只包含了四种特定的相机模型获取的原始图像,这些原始图像不包含在我们的训练集中。而基于深度学习的方法,如Noiseprint和取证相似度FS,在Korus数据集上的性能优于我们提出的方法,都利用了基于相机模型的特征。
值得注意的是,我们的方法在Coverage(TIFF图像)、CASIA1 (JPEG图像)和CASIA2 (JPEG+TIFF图像)数据集上明显优于Noiseprint和FS。与其他数据集相比,这些数据集的图像尺寸相对较小,平均大小分别为489×380、384×256和473×322像素。这种低分辨率的图像往往很难被Noiseprint检测到,因为图像中提取的特征太少,无法通过期望最大化(EM)算法进行正确的聚类。对于小尺寸的图像,由于滑动窗口大小固定为128×128或256×256像素,FS无法生成细粒度的结果。我们的方法在CASIA2数据集上比在CASIA1数据集上表现更好,因为CASIA2包含了60%的未压缩图像,这些图像更容易被检测出来。对于JPEG压缩图像,Noiseprint部署46个网络,每个网络都用特定QF (QF55-QF100)的JPEG图像进行训练。相比之下,该方法通过一个单独的Siamese网络进行训练,并使用未压缩的JPEG代理图像,大大降低了计算成本。此外,由于实际情况下Wild Web数据集的特点是伪造图像的质量较低,大多数方法在该数据集上表现出比在其他数据集上更差的性能。尽管如此,我们的方法仍然在该数据集上获得了前3名的性能。
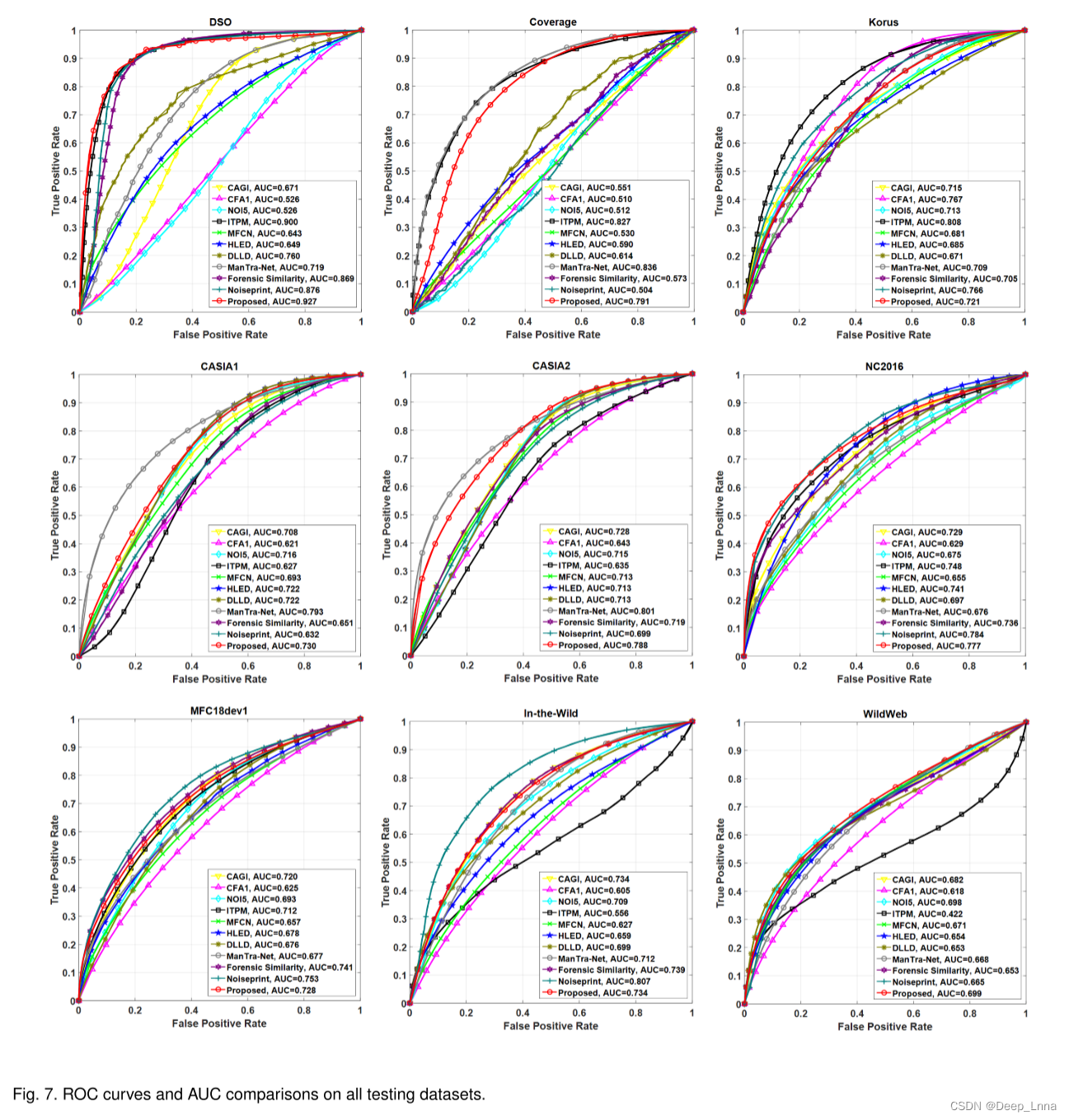
总体而言,我们的方法获得了最优的平均性能,在MCC、F1和AP方面分别比第二好的noise-print方法高出1.8%、2.9%和5.3%。为了完整起见,我们还演示了ROC曲线和AUCs(曲线下面积)的比较。如图7所示,我们的方法的ROC性能除了在Korus数据集上排名第4外,一直处于最好的三种方法之间。最后,从图8中所有测试数据集上的平均性能来看,我们比较了最好的六种方法的篡改热图定性定位结果,以说明我们可以更精确地定位锻造区域的情况。
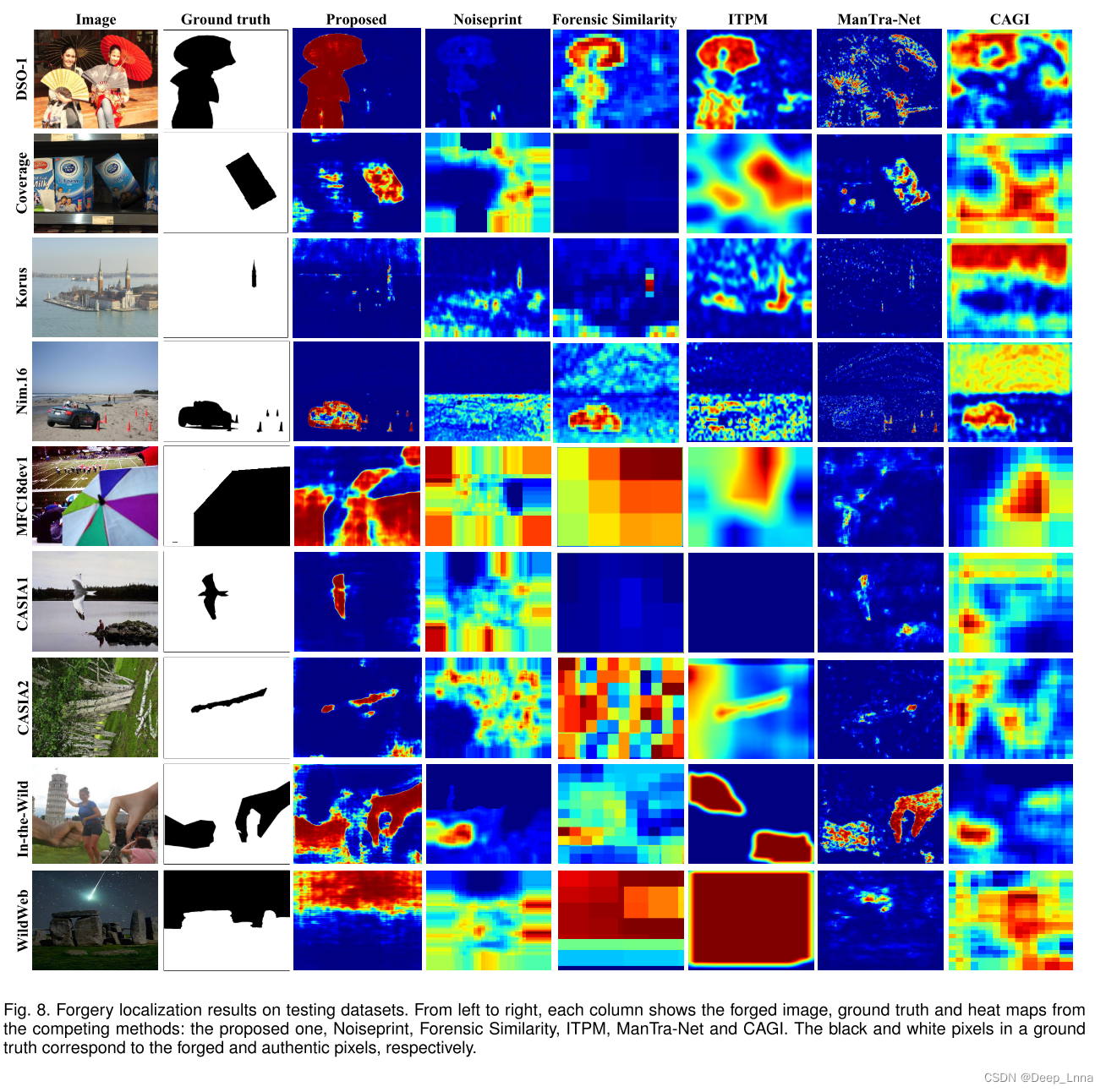
抗JPEG压缩的鲁棒性
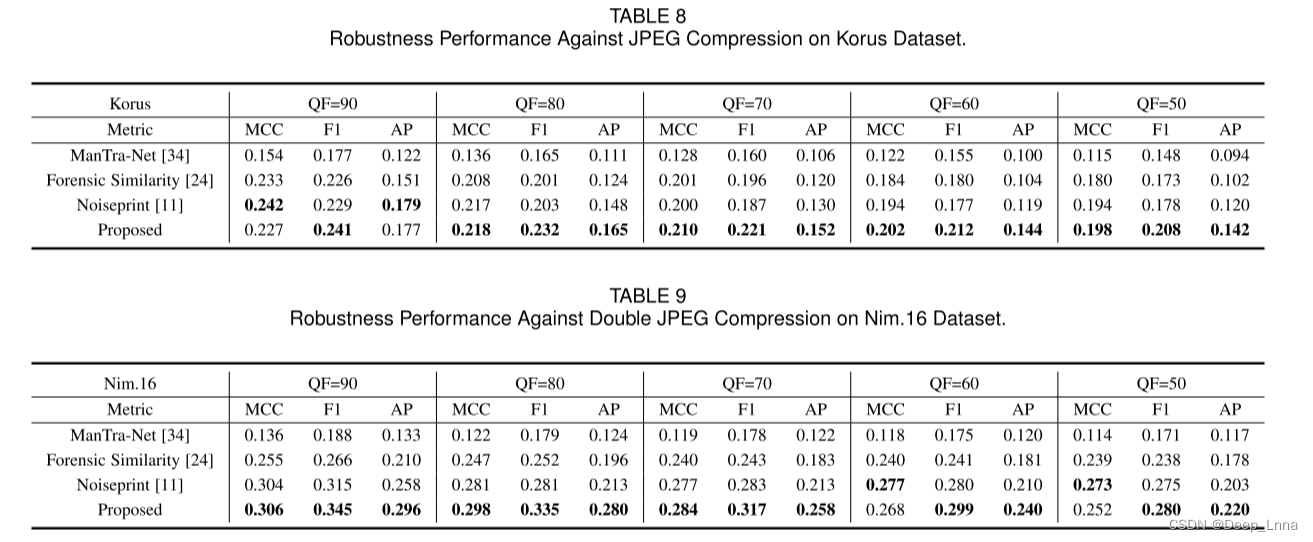
为了进一步验证我们的方法对JPEG压缩的鲁棒性,我们在Korus和nim16数据集上比较了性能,其中图像压缩的QF=50, 60, 70, 80, 90。考虑到在大多数社交网络中,图像压缩通常采用QF≥70的方式,如Facebook (QF=71)和微信(QF=70),因此可以将QF<70视为现实情况下的极端压缩场景。我们将我们的方法与基于深度学习的前三种方法(ManTraNet、Forensic Similarity和Noiseprint)在MCC、F1和AP方面进行比较,如表8和表9所示。尽管如表5、表6和表7所示,在包含未压缩图像的Korus数据集上,Forensic Similarity和Noiseprint的性能优于我们,但在经过测试的qf条件下,我们的方法仍然在JPEG压缩(包括极端压缩场景)中获得了最佳的鲁棒性能。此外,由于Nim.16数据集包含了QF=75、95、99,100的JPEG压缩图像,因此,在Nim.16数据集上,该方法对双JPEG压缩的性能也优于其他同类方法。
对图像Resize的鲁棒性
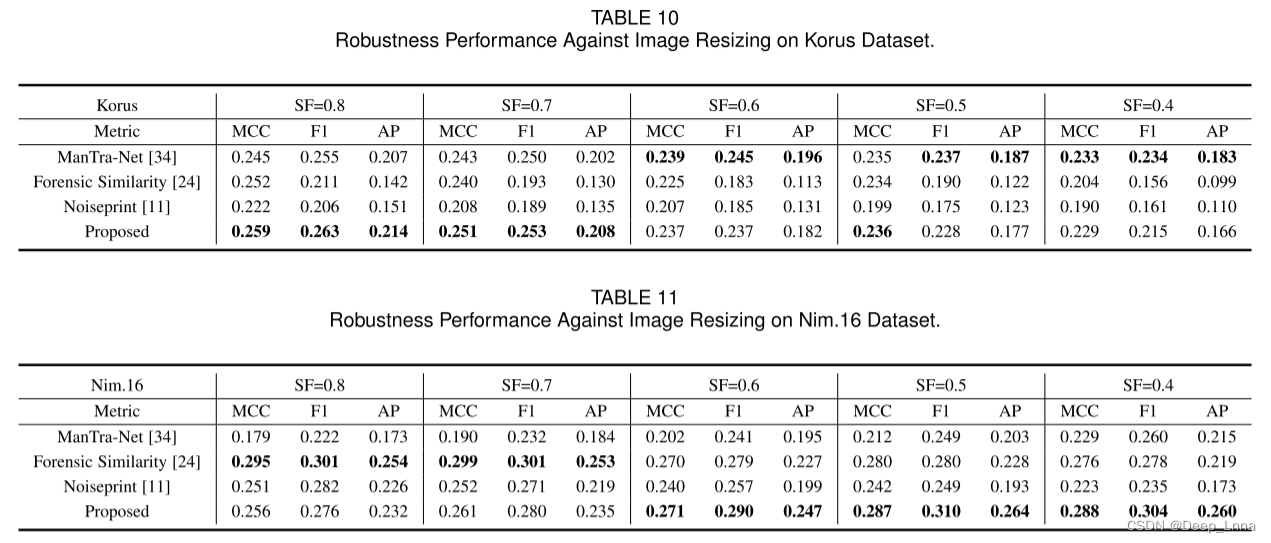
在Korus和Nim16数据集上,利用尺度因子(SFs)在0.4 ~ 0.8的范围内调整图像的大小,并对MCC、F1和AP的鲁棒性进行评价。如表10和表11所示,在Korus数据集SF=0.7、0.8和nim16数据集SF=0.4、0.5、0.6时,我们的方法在抗降尺度变换方面优于其他方法,并且在抗尺度攻击方面与其他测试的SF具有竞争性能。
总结
本文提出了一种自监督域自适应网络,它将骨干网与压缩近似网络(ComNet)相结合,用于抗JPEG图像伪造定位。我们没有使用各种真实的JPEG压缩图像进行数据扩充,而是通过自监督学习训练的ComNet来近似JPEG压缩操作来生成JPEG代理图像。JPEG代理图像具有更强的JPEG压缩可泛化特性,并将其应用于领域自适应策略,以缓解未压缩图像与JPEG代理图像之间的领域转移,对JPEG压缩具有更好的鲁棒性。在多个公共数据集上进行了大量的实验,结果表明该方法具有较好的泛化能力。















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









