







 提出MVSS-Net++,一种针对图像操纵检测的多视图多尺度监督网络,利用卷积广义平均池化(ConvGeM)模块改善特征提取与反向传播效率,实现在像素级与图像级检测的平衡。
提出MVSS-Net++,一种针对图像操纵检测的多视图多尺度监督网络,利用卷积广义平均池化(ConvGeM)模块改善特征提取与反向传播效率,实现在像素级与图像级检测的平衡。
发布于TPAMI2022
原文链接:https://arxiv.org/pdf/2112.08935v3.pdf
源码链接:https://github.com/dong03/MVSS-Net
本文只对于和MVSS不同的部分进行介绍,具体MVSS的内容见另一篇博客:https://blog.csdn.net/weixin_45366180/article/details/127643547?spm=1001.2014.3001.5501
主要贡献
- 为了将像素级操纵检测转换为图像级预测,我们提出了一种名为卷积广义平均池化(ConvGem) 的新模块代替之前使用的global max pooling (GMP),新模块有效地克服了 GMP 的两个缺点,即反向传播图像尺度损失的瓶颈以及缺乏考虑积极响应的数量和空间分布的能力。提出了更好的模型 MVSS-Net++。
- 对当前模型如何对通过屏幕截图重新捕获的操纵图像做出反应进行了初步研究,这是图像在互联网上传播时的常见操作。测试其鲁棒性。
提出的模型
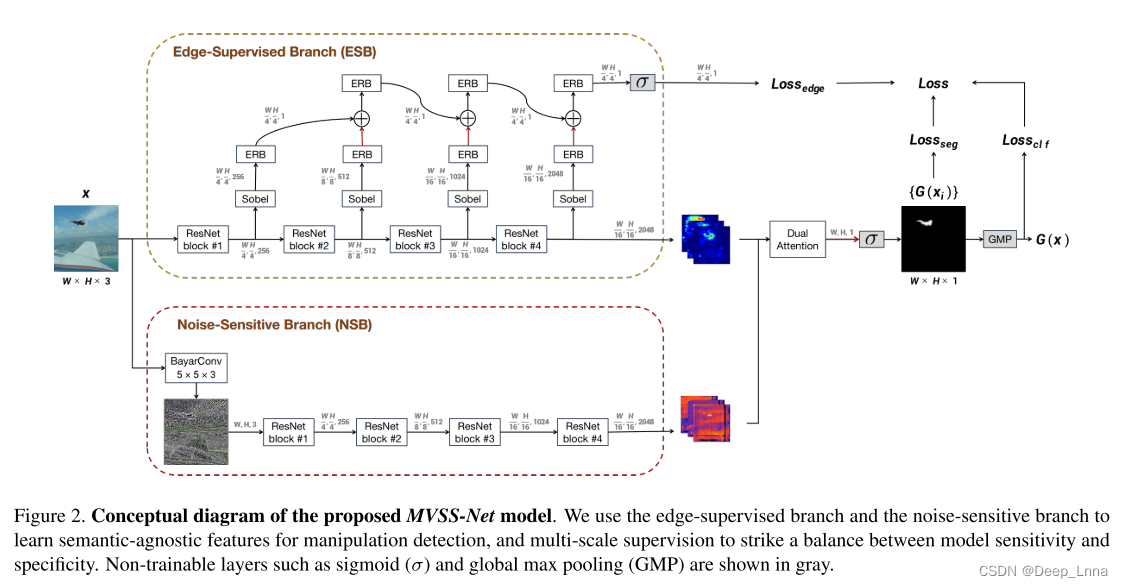
下图是MVSS模型。
下图是MVSS++模型。
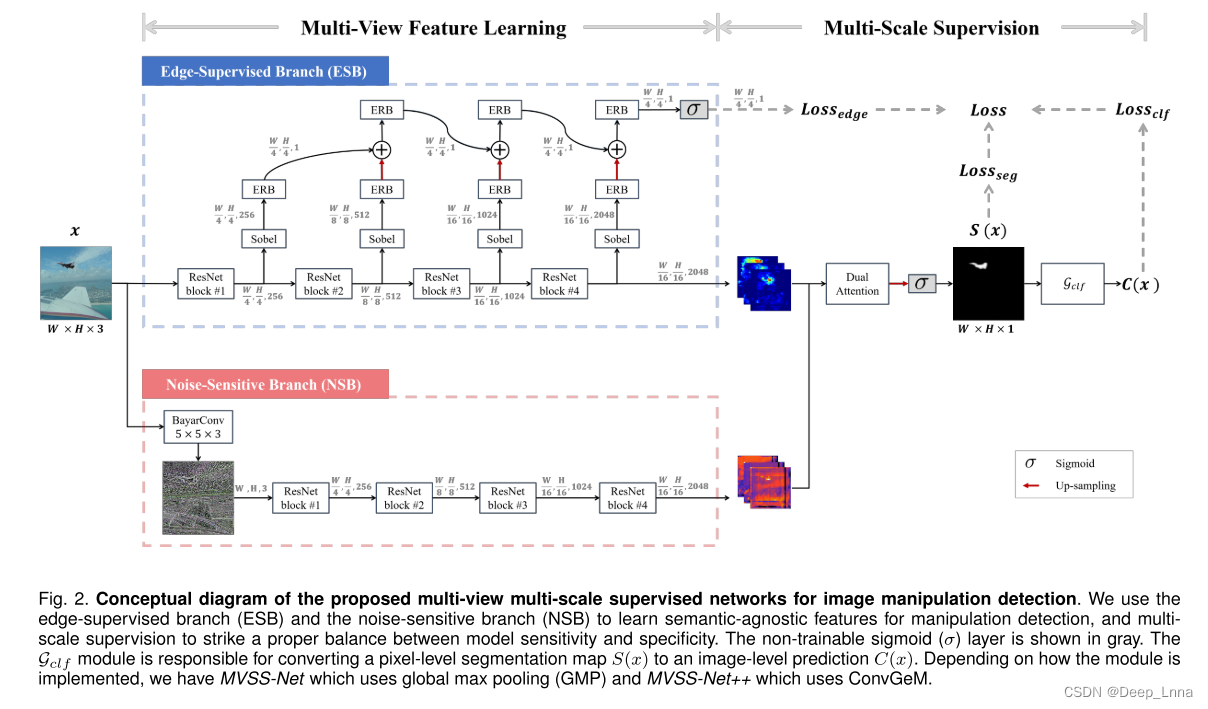
本文的目的是训练一个多头的神经网络G(即不仅确定图像是否被操纵,而且确定其被操纵的像素)。
- 语义分割头 G s e g G_{seg} Gseg:像素级操作的概率S(x)。
- 图像分类头 G c l f G_{clf} Gclf:图像被操纵的概率C(x),根据像素级的证据,我们从分割图中得到C(x)。
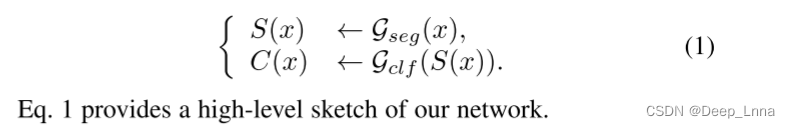
为了提取可推广的操作检测特征,G被设计成同时接受输入图像的原始RGB视图和额外噪声视图。 为了在检测灵敏度和特异性之间取得适当的平衡,多视点特征学习过程由像素、边缘和图像三个尺度的标注共同监督。 这就产生了多视图多尺度监督网络(MVSS-NET)。
用于图像级预测的ConvGeM
Global Max Pooling (GMP)将 S(x) 的最大值作为 C(x),即C(x) = S i ∗ , j ∗ S_{i∗,j∗}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









