







论文标题:Convolutional MKL Based Multimodal Emotion Recognition and Sentiment Analysis
摘要
本文针对多模态情绪识别和情感分析的问题,提出了一种新的方法(深度卷积神经网络)从文本和视频的模态提取特征。并且设计了一个Multiple Kernel Learning(多核学习,MKL)分类器来对不同模态的特征进行训练,得出相应的情感分类结果。实验结果表明,作者提出的方法在不同数据集上的多模态情感识别和情感分析方面的表现显著优于现有水平。
文章主要的贡献:
1、针对视频特征提取,作者提出来一种时间卷积神经网络,将t时刻和t+1时刻的每一对图像组合成一张图像,用来捕捉视频序列的时间信息。
2、作者提出使用RNN来捕获静态图像中固有的空间结构信息。
3、提出MKL来融合三种模式。
4、作者使用CNN从一个监督分类器变成了一个可训练的特征提取器。
CRMKL模型
作者设计了一个卷积循环多核学习(CRMKL)模型,该模型结合了音频、视频和文本中的情感特征。特别是在视频模态,CRMKL模型可以将RNN、CNN和MKL相结合。模型结构图如下:
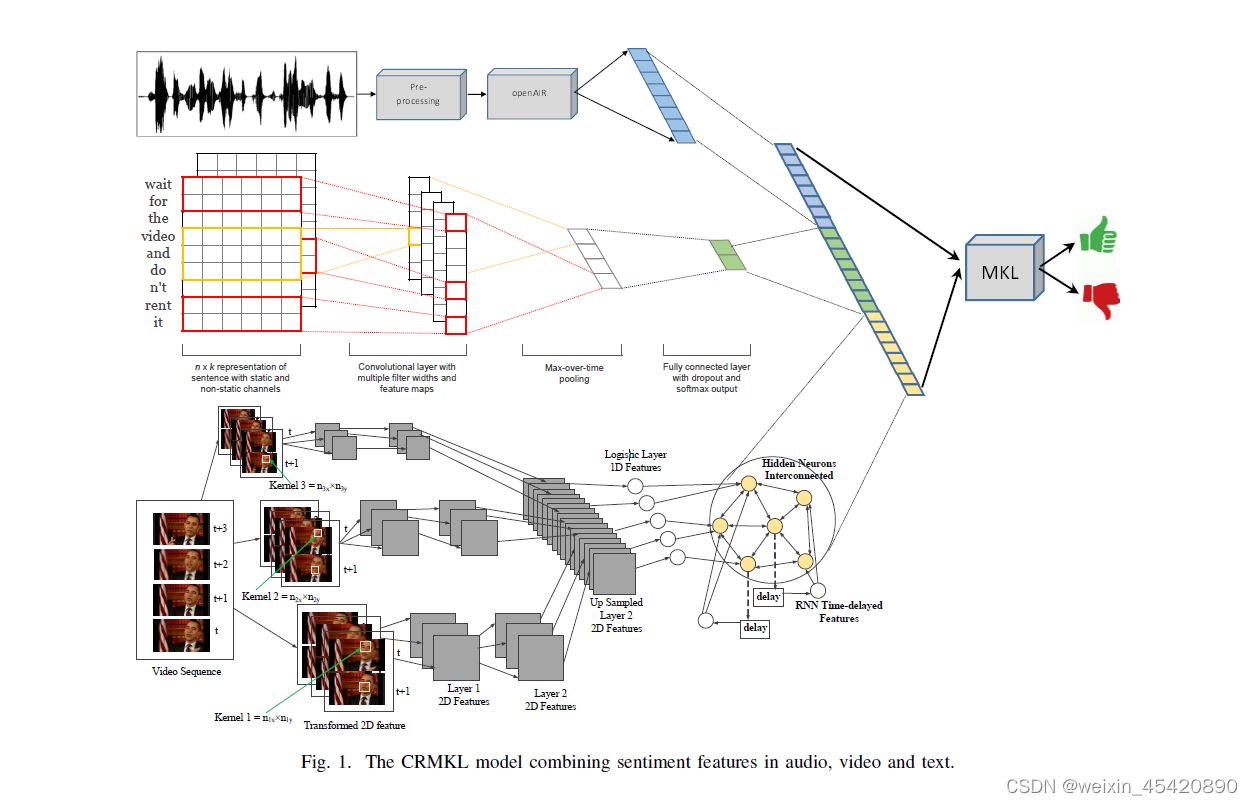
针对于不同的模态,作者使用了不同的方法来提取特征。
视频模态
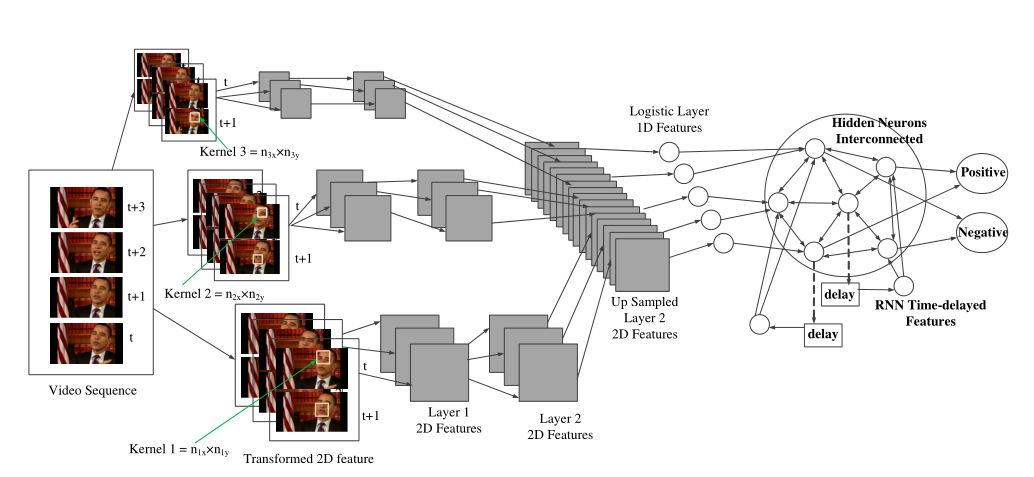
对于视频特征提取,作者首先将t时刻和t+1时刻的每一对连续图像转换为单个图像,然后使用不同维度的Kernel来从转换后的输入中学习第1层的2D特征。
同样,第二层也使用不同维度的核来学习二维特征。上采样层将不同核大小的特征转化为均匀的2D特征。接下来,使用逻辑层神经元为RNN准备输入。
这里有一个相互连接的神经元层,可以使用延迟状态对长时间延迟进行建模。最终输出层将每个视频图像分类为“正”或“负”。
实验时,第一个卷积层包含100个大小为10×20的核,下一个卷积层包含100个大小为20×30的核,然后是300个神经元的逻辑层和50个神经元的循环层。卷积层与池化层交织,维度为2×2。
文本模态
对于文本模态,作者使用CNN来提取特征,每个RBM层都以无监督的方式进行训练,然后可以使用已知标签的数据集子集对完整的深度模型进行微调。在每一层中以无监督的方式学习的特征可能不是最好的分类,但可以用来训练最先进的分类器。
作者提出为每个单词构建306维向量,其中,使用word2vec字典为每个单词提供300维;用6个基本词性(名词、动词、形容词、副词、介词、连词)编码为6维二元向量。
在特征提取时,使用7层的CNN,分别为输入层、卷积层、最大池化层、卷积层、全连接层、输出层。特征提取自CNN的倒数第二全连接层。作者将CNN的最后一层输出层仅用于训练,但在实际决策时,将其替换为更复杂的分类器,如SVM或MKL。
音频模态
作者使用开源软件openSMILE来自动提取音频特征,得到6373个feature。
深度CNN在音频、视频和文本分类方面表现出了良好的性能。与其使用单个大的隐藏神经元层,深度模型有几个小的隐藏神经元层。由于每一层都是独立的,这大大降低了复杂性。因此,在本文中,作者为每个模态,即音频、视频和文本,构建了一个深度CNN。
使用MKL将三个深度CNN学习到的每一组特征结合起来。就可以减少输入维度的数量,并对MKL的特征进行分组。
实验结果
下表展示了在MOUD数据集上获得的10倍交叉验证结果,我们可以看到,使用了CRMKL模型进行视频特征提取,比当前的技术水平提高了27%的准确率。另外使用CNN来提取文本模态的特征所取得的效果也比当前技术优秀。
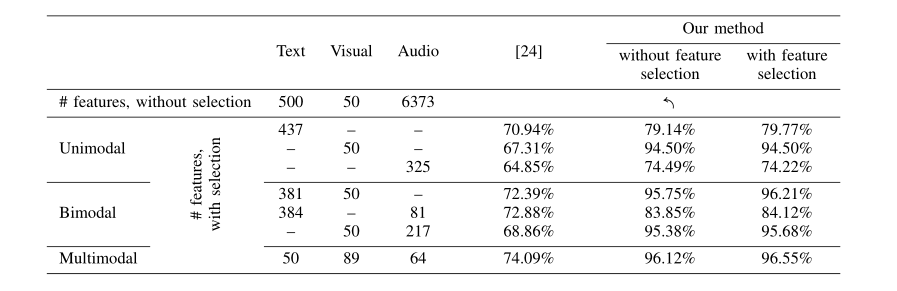
下表为作者在IEMOCAP数据集上的实验结果,与单模态相比,本文使用特征级融合方法融合不同模态所取得的效果明显优于单模态。
●文本分类器可以很好地识别愤怒、快乐和中性的实例。然而,愤怒和悲伤的例子很难用文本线索区分彼此。其中一个可能的原因是,这两个类别都是否定的,许多相似的词被用来表达它们。
●在音频情态的情况下,我们观察到悲伤和中性类别比文本情态的准确性,但对快乐和愤怒类别则没有。分类器把许多快乐的实例错误地归类为愤怒的实例。然而,分类器在区分悲伤和愤怒方面表现得很好。我们还观察到,一些快乐的人被归类为中性。
●与其他两种方式相比,视觉方式产生了最好的准确性。虽然愤怒和悲伤的脸可以被有效地分类,但分类器在愤怒和悲伤的脸之间显示出一些混淆。尽管在快乐面孔和中性面孔之间观察到高度的混淆,但中性面孔与其他类别的区分也更准确。
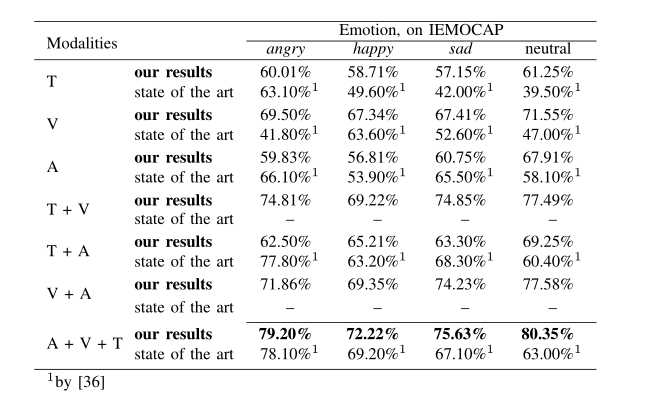
本文着重采用不同的方法对视频与文本特征的提取,而音频特征提取使用的方法则不够突出,因此,T+V的表现明显优于T+A和A+V。
总结
随着网络上发布的视频越来越多,从视频中提取情感和极性对于社交媒体营销、品牌定位和财务预测等任务变得越来越重要。
因此,本文提出了一种融合文本、声调和面部表情的多模态情感识别和情感分析方法。特别是,作者描述了一种新的时间深度卷积神经网络的视觉和文本的特征提取,并使用多核学习(MKL)融合从不同的模式提取的异构特征。















 1239
1239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









