







autoware.universe源码略读3.6--perception:detected_object_feature_remover/validation/detection_by_track
detected_object_feature_remover
官方文档对这个包的作用描述是
The detected_object_feature_remover is a package to convert topic-type from DetectedObjectWithFeatureArray to DetectedObjects.
所以相当于只是一个话题的类型转换,转换后就只剩下检测到的物体了。在构造函数里就是话题的发布和订阅了,具体的转换是在回调函数中调用convert函数,其实仔细看一下就知道,这里不过是把objs_with_feature的header和object对象拿出来了,然后单独变成了一个类型。整体非常简单,没啥好说的
detected_object_validation
这里是针对目标检测positive的结果进行判断和消除,文件分成了三个组成部分,第一个detected_object_filter应该是对检测到的物体进行一个整体的滤波操作,然后obstacle_pointcloud_based_validator和occupancy_grid_based_validator应该就是对应的两种判断方式,接下来分开来看一下
detected_object_filter
这里也分成了两种,第一种是object_lanelet_filter,看起来是根据地图进行的滤波,成员变量里包括了两个话题的订阅:地图订阅autoware_auto_mapping_msgs::msg::HADMapBin和检测到的物体订阅autoware_auto_perception_msgs::msg::DetectedObjects,而发布的话题则也是autoware_auto_perception_msgs::msg::DetectedObjects类型的目标,构造函数还是很简单的,就是加载了一些参数以及进行了话题订阅发布的初始化。
在地图回调函数mapCallback中,就是单纯的根据地图消息获得了地图以及道路这些变量
lanelet_frame_id_ = map_msg->header.frame_id;
lanelet_map_ptr_ = std::make_shared<lanelet::LaneletMap>();
lanelet::utils::conversion::fromBinMsg(*map_msg, lanelet_map_ptr_);
const lanelet::ConstLanelets all_lanelets = lanelet::utils::query::laneletLayer(lanelet_map_ptr_);
road_lanelets_ = lanelet::utils::query::roadLanelets(all_lanelets);
而目标的回调函数objectCallback则会复杂一些,首先物体的消息并没有是直接在地图中的,所以我们要先根据input_msg和已经有了的地图信息lanelet_frame_id_进行一个转换
if (!perception_utils::transformObjects(
*input_msg, lanelet_frame_id_, tf_buffer_, transformed_objects)) {
RCLCPP_ERROR(get_logger(), "Failed transform to %s.", lanelet_frame_id_.c_str());
return;
}
这样就把object的坐标系至少和地图统一上了,然后计算了一个大的凸包,看起来是把所有objects都考虑进去了的一个凸包(PS:这里用的是boost库,没有用common模块自己定义的)
const auto convex_hull = getConvexHull(transformed_objects);
接下来判断这个凸包与地图上的道路是否有相交的地方,具体是把所有有相交的路的对象放在了intersected_lanelets这个变量里
lanelet::ConstLanelets intersected_lanelets = getIntersectedLanelets(convex_hull, road_lanelets_);
接下来,就是遍历所有的objects来进行进一步地判断,具体的判断就是取出每一个object,然后如果是需要滤波的类型(由配置参数指定)就判断这个形状与之前提取出来的道路集合有没有相交的地方
if (filter_target_.isTarget(label)) {
Polygon2d polygon;
for (const auto & point : footprint.points) {
const geometry_msgs::msg::Point32 point_transformed =
tier4_autoware_utils::transformPoint(point, object.kinematics.pose_with_covariance.pose);
polygon.outer().emplace_back(point_transformed.x, point_transformed.y);
}
polygon.outer().push_back(polygon.outer().front());
if (isPolygonOverlapLanelets(polygon, intersected_lanelets)) {
output_object_msg.objects.emplace_back(input_msg->objects.at(index));
}
} else {
output_object_msg.objects.emplace_back(input_msg->objects.at(index));
}
然后我们可以看到,这里调用了isPolygonOverlapLanelets函数,在这里进一步调用的是boost::geometry::disjoint这个函数,这个函数是在完全不相交的时候返回true,所以这里是找到了那些相交的情况,所以这个文件的目的最后是找到了那些在地图中的objects
if (!boost::geometry::disjoint(polygon, lanelet.polygon2d().basicPolygon())) {
return true;
}
另一种滤波方式是object_position_filter,这个看起来是只是根据x,y坐标进行的一个objects滤波操作,所以只需要订阅和发布autoware_auto_perception_msgs::msg::DetectedObjects这一种消息就好了,然后这个x和y的坐标范围还是根据配置参数决定的,所以最后的判断只需要在回调函数里判断坐标在不在范围内就行了,值得一提的是这里的坐标没有经历过坐标转换,只是单纯的objects下的坐标,所以感觉这里更像是对物体大小的一种指定?
const auto & position = object.kinematics.pose_with_covariance.pose.position;
return position.x > lower_bound_x_ && position.x < upper_bound_x_ &&
position.y > lower_bound_y_ && position.y < upper_bound_y_;
obstacle_pointcloud_based_validator
这里根据官方文档的描述,If the number of obstacle point groups in the DetectedObjects is small, it is considered a false positive and removed. The obstacle point cloud can be a point cloud after compare map filtering or a ground filtered point cloud. 这里的障碍点云应该就是经过前面滤波过的点云?具体的回调函数在onObjectsAndObstaclePointCloud
回调函数里,首先也是进行了坐标的统一,把input_object和input_obstacle_pointcloud的坐标进行了统一
if (!perception_utils::transformObjects(
*input_objects, input_obstacle_pointcloud->header.frame_id, tf_buffer_,
transformed_objects)) {
// objects_pub_->publish(*input_objects);
return;
}
然后构建了一个KD树,把障碍点云作为了输入点云
pcl::search::Search<pcl::PointXY>::Ptr kdtree =
pcl::make_shared<pcl::search::KdTree<pcl::PointXY>>(false);
kdtree->setInputCloud(obstacle_pointcloud);
接下来遍历物体,然后每一个物体都计算了一个最大搜索半径getMaxRadius,这个半径的大小具体是根据几何形状计算出来的
if (object.shape.type == Shape::BOUNDING_BOX || object.shape.type == Shape::CYLINDER) {
return std::hypot(object.shape.dimensions.x * 0.5f, object.shape.dimensions.y * 0.5f);
} else if (object.shape.type == Shape::POLYGON) {
float max_dist = 0.0;
for (const auto & point : object.shape.footprint.points) {
const float dist = std::hypot(point.x, point.y);
max_dist = max_dist < dist ? dist : max_dist;
}
return max_dist;
然后调用KD树进行搜索,就是根据物体的位置在输入的障碍点云中搜索
kdtree->radiusSearch(
toPCL(transformed_object.kinematics.pose_with_covariance.pose.position),
search_radius.value(), indices, distances);
然后判断找到的点云在物体内的数量,这里更具体一点是调用了getPointCloudNumWithinPolygon函数,然后根据数量判断是否要移除
const auto num = getPointCloudNumWithinPolygon(transformed_object, neighbor_pointcloud);
if (num) {
(min_pointcloud_num_ <= num.value()) ? output.objects.push_back(object)
: removed_objects.objects.push_back(object);
} else {
output.objects.push_back(object);
}
在具体的getPointCloudNumWithinPolygon函数中,使用到了PCL的点云裁剪的这个功能,把形状外的点云裁剪掉,剩下的就是形状内的了
pcl::CropHull<pcl::PointXYZ> cropper; // don't be implemented PointXY by PCL
cropper.setInputCloud(toXYZ(pointcloud));
cropper.setDim(2);
cropper.setHullIndices(vertices_array);
cropper.setHullCloud(poly3d);
cropper.setCropOutside(true);
cropper.filter(*cropped_pointcloud);
至此,完成了第一种判断方式,当然这里还有一个debugger_的调试信息,就是把一些过程变量以及最后移除的物体之类的发布出去了
occupancy_grid_based_validator
这个看起来是根据栅格地图的特性来判断是否删除物体的一个模块,根据官方给的这个示意图来看,应该就是在空白栅格比较大的物体就给移除了?
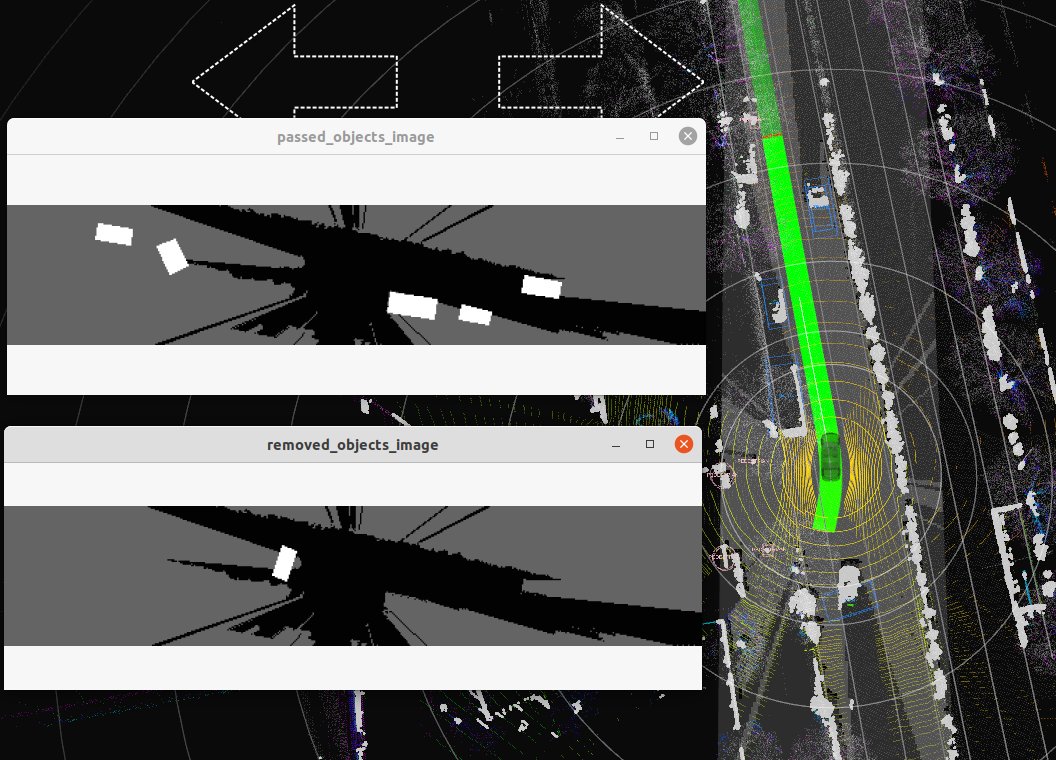
那么这里除了objects这个话题,还要订阅的就是~/input/occupancy_grid_map
在回调函数中,也是先进行了坐标的统一,先把物体和栅格地图的坐标进行了统一
if (!perception_utils::transformObjects(
*input_objects, input_occ_grid->header.frame_id, tf_buffer_, transformed_objects))
return;
然后fromOccupancyGrid这个函数,应该是根据栅格地图生成了一个图像,然后是把值限制在了0-100之间,也就是灰色。然后遍历objects,这里是只对CarLike的物体进行了一个mask的计算,看起来就是一个图片然后把物体在上边用白色标记出来了(和官方图对应上了),然后这里的判断标准是根据一个平均值来判断,大于阈值的话就加到输出里面
auto mask = getMask(*input_occ_grid, transformed_object);
const float mean = mask ? cv::mean(occ_grid, mask.value())[0] * 0.01 : 1.0;
if (mean_threshold_ < mean) output.objects.push_back(object);
OK我这里的理解是,计算的平均值就是栅格地图中mask非0区域的平均值,这样如果平均值小于阈值,就说明这个物体大部分都在没有栅格地图的区域,所以这个时候就给移除了。
detection_by_tracker
这个模块会将跟踪到的物体反馈给检测模块,以保持模块稳定并持续检测物体。官方给的示意图是

这里感觉挺复杂而且应该也挺重要的,下面来看下具体的内容:
TrackerHandler
这个类应该是负责跟踪的,这里将接收到的物体消息通过onTrackedObjects这个回调函数存入了objects_buffer_,这里每次都是把最新的放在前面,然后超过容量的时候就把队尾的,也就是最旧的删除了
// Add tracked objects to buffer
objects_buffer_.push_front(*msg);
// Remove old data
while (max_buffer_size < objects_buffer_.size()) {
objects_buffer_.pop_back();
}
然后还有一个estimateTrackedObjects,这里输入的是时间,所以应该是对objects的预测,会遍历objects_buffer_找到与输入事件最接近的一个target_objects_iter,然后对这个对象中的object进行遍历,根据物体的运动信息进行当前时刻的位姿的一个简单计算,作为预测的output
for (const auto & object : target_objects_iter->objects) {
const auto & pose_with_covariance = object.kinematics.pose_with_covariance;
const auto & x = pose_with_covariance.pose.position.x;
const auto & y = pose_with_covariance.pose.position.y;
const auto & z = pose_with_covariance.pose.position.z;
const float yaw = tf2::getYaw(pose_with_covariance.pose.orientation);
const auto & twist = object.kinematics.twist_with_covariance.twist;
const float & vx = twist.linear.x;
const float & wz = twist.angular.z;
// build output
autoware_auto_perception_msgs::msg::TrackedObject estimated_object;
estimated_object.object_id = object.object_id;
estimated_object.existence_probability = object.existence_probability;
estimated_object.classification = object.classification;
estimated_object.shape = object.shape;
estimated_object.kinematics.pose_with_covariance.pose.position.x =
x + vx * std::cos(yaw) * dt.seconds();
estimated_object.kinematics.pose_with_covariance.pose.position.y =
y + vx * std::sin(yaw) * dt.seconds();
estimated_object.kinematics.pose_with_covariance.pose.position.z = z;
const float yaw_hat = tier4_autoware_utils::normalizeRadian(yaw + wz * dt.seconds());
estimated_object.kinematics.pose_with_covariance.pose.orientation =
tier4_autoware_utils::createQuaternionFromYaw(yaw_hat);
output.objects.push_back(estimated_object);
}
所以这个类的作用就是对物体进行预测的,然后调用的时候直接调用函数就可以了
DetectionByTracker
这里就是根据跟踪结果来进行目标检测了,里面包含了刚才定义的类的成员变量TrackerHandler tracker_handler_,此外这里也是一个节点类,包含话题订阅和发布等等。在构造函数总,订阅了两个话题,一个是初始的objects,还有一个就是跟踪的objects。
在回调函数onObjects中,可以看到是先对物体进行了预测
const bool available_trackers =
tracker_handler_.estimateTrackedObjects(input_msg->header.stamp, objects);
然后把object坐标转换,并且利用toDetectedObjects函数转为被检测到的objects
if (
!available_trackers ||
!perception_utils::transformObjects(
objects, input_msg->header.frame_id, tf_buffer_, transformed_objects)) {
objects_pub_->publish(detected_objects);
return;
}
// to simplify post processes, convert tracked_objects to DetectedObjects message.
tracked_objects = perception_utils::toDetectedObjects(transformed_objects);
加下来分为了两种情况,这里先来了解一下这两种情况,一种是over segmentation,过度分割,比如明明是一辆车但是却被检测算法分割成了两个部分;另一种是under segmentation,欠分割,比如两个行人,但是检测出来给放在一起了

第一个是将跟踪得到的对象和初始对象进行合并,核心实现在函数mergeOverSegmentedObjects中,并且将合并后的对象进行发布
tier4_perception_msgs::msg::DetectedObjectsWithFeature merged_objects;
autoware_auto_perception_msgs::msg::DetectedObjects no_found_tracked_objects;
mergeOverSegmentedObjects(tracked_objects, *input_msg, no_found_tracked_objects, merged_objects);
debugger_->publishMergedObjects(merged_objects);
这里具体的函数自己加了几句注释吧
void DetectionByTracker::mergeOverSegmentedObjects(
const autoware_auto_perception_msgs::msg::DetectedObjects & tracked_objects,
const tier4_perception_msgs::msg::DetectedObjectsWithFeature & in_cluster_objects,
autoware_auto_perception_msgs::msg::DetectedObjects & out_no_found_tracked_objects,
tier4_perception_msgs::msg::DetectedObjectsWithFeature & out_objects)
{
constexpr float precision_threshold = 0.5;
constexpr float max_search_range = 5.0;
out_objects.header = in_cluster_objects.header;
out_no_found_tracked_objects.header = tracked_objects.header;
for (const auto & tracked_object : tracked_objects.objects) {
const auto & label = tracked_object.classification.front().label;
if (ignore_unknown_tracker_ && (label == Label::UNKNOWN)) continue;
// extend shape
autoware_auto_perception_msgs::msg::DetectedObject extended_tracked_object = tracked_object;
// 函数扩大了对象的形状,扩大的比例是 1.1
extended_tracked_object.shape = extendShape(tracked_object.shape, /*scale*/ 1.1);
pcl::PointCloud<pcl::PointXYZ> pcl_merged_cluster;
// 遍历 in_cluster_objects 中的每一个对象
// 对于每一个对象,函数首先计算其与跟踪对象的二维距离。如果距离大于最大搜索范围,那么就跳过这个对象
for (const auto & initial_object : in_cluster_objects.feature_objects) {
const float distance = tier4_autoware_utils::calcDistance2d(
tracked_object.kinematics.pose_with_covariance.pose,
initial_object.object.kinematics.pose_with_covariance.pose);
if (max_search_range < distance) {
continue;
}
// If there is an initial object in the tracker, it will be merged.
const float precision =
perception_utils::get2dPrecision(initial_object.object, extended_tracked_object);
if (precision < precision_threshold) {
continue;
}
pcl::PointCloud<pcl::PointXYZ> pcl_cluster;
pcl::fromROSMsg(initial_object.feature.cluster, pcl_cluster);
// 将对象的聚类添加到合并的聚类中
pcl_merged_cluster += pcl_cluster;
}
if (pcl_merged_cluster.points.empty()) { // if clusters aren't found
out_no_found_tracked_objects.objects.push_back(tracked_object);
continue;
}
// build output clusters
tier4_perception_msgs::msg::DetectedObjectWithFeature feature_object;
feature_object.object.classification = tracked_object.classification;
bool is_shape_estimated = shape_estimator_->estimateShapeAndPose(
label, pcl_merged_cluster,
getReferenceYawInfo(
label, tf2::getYaw(tracked_object.kinematics.pose_with_covariance.pose.orientation)),
getReferenceShapeSizeInfo(label, tracked_object.shape), feature_object.object.shape,
feature_object.object.kinematics.pose_with_covariance.pose);
if (!is_shape_estimated) {
out_no_found_tracked_objects.objects.push_back(tracked_object);
continue;
}
// 计算跟踪对象和新对象的二维 IoU,并设置为新对象的存在概率
feature_object.object.existence_probability =
perception_utils::get2dIoU(tracked_object, feature_object.object);
setClusterInObjectWithFeature(in_cluster_objects.header, pcl_merged_cluster, feature_object);
out_objects.feature_objects.push_back(feature_object);
}
}
除了合并对象之外,也有分割对象的操作
tier4_perception_msgs::msg::DetectedObjectsWithFeature divided_objects;
autoware_auto_perception_msgs::msg::DetectedObjects temp_no_found_tracked_objects;
divideUnderSegmentedObjects(
no_found_tracked_objects, *input_msg, temp_no_found_tracked_objects, divided_objects);
debugger_->publishDividedObjects(divided_objects);
这里也是对距离进行了判断,如果距离超过阈值,那就直接跳出判断了。当距离满足阈值的时候,对recall和precision进行判断,这里的概念在autoware.universe源码略读(1)–common中有提到过,也就是如果跟踪到的对象和初始的对象recall很高,但precision又很低,那说明这个很可能就是一个新的对象,所以这种情况下就是欠分割的了(is_under_segmented),如果是欠分割的,接下来就调用optimizeUnderSegmentedObject这个函数,对这种情况来进行优化。这个函数里是调用了另一个功能包,euclidean_cluster,里面也是直接用对应的函数来执行聚类的操作
std::vector<pcl::PointCloud<pcl::PointXYZ>> divided_clusters;
cluster.setTolerance(cluster_range);
cluster.setVoxelLeafSize(voxel_size);
cluster.cluster(pcl_cluster, divided_clusters);
迭代的过程是寻找最佳的分割对象。在每次迭代中,函数首先将被分割的聚类进行进一步的分割,然后在分割后的聚类中找到与目标对象的 IoU 最高的对象。如果当前迭代的 IoU 小于上一次迭代的 IoU,那么就结束迭代。所以总结起来,这个函数就是通过迭代的方式,不断优化被分割的对象,使其与目标对象的 IoU 最大。















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









