







本文内容总结自 字节跳动青年训练营 第五届后端组
一、规则引擎是什么
规则引擎是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并且使用预定义语义模块编写业务决策。接受数据输入,解释业务规则,并且根据业务规则做出业务决策
比如说抖音、pdd上的各种优惠、满减券都是通过规则引擎生成出来的。规则引擎独立在应用程序代码之外,只要应用程序对其输入一定的条件,他就会生成出对应的决策和规则
在这种情况下,规则引擎:
- 解决了开发人员为了修改业务细节而重复编码的问题
- 业务决策和服务本身解耦,提高了服务的可维护性
- 缩短开发路径,提高效率
规则引擎主要应用场景有:
- 风控对抗:规则引擎通常是风控系统的核心,使得产品和研发人员你可以不断调整和优化对抗策略,以实现最好的黑灰产识别效果
- 活动策略运营:比如各大电商的优惠策略
- 数据分析和清洗:数据引擎可以很方便德实现对数据的整理、清洗和转换。数据分析师可以根据不同的需求来自定义数据处理规则。
二、规则引擎的组成部分
-
数据输入
支持接受使用预定义的语义编写规则作为策略集。也就是通过输入一定格式的数据,就可以使用规则引擎输出决策和规则 -
规则理解
能够按照预先定义的语法、优先级等正确理解业务规则所表达的语义,其中对规则的理解不可以出现二义性 -
规则执行
根据执行输入的参数对策略集中的规则进行正确的解释和执行
三、编译原理的基本概念
设计规则引擎需要一些编译原理的概念,因此需要先了解一些编译原理的概念
规则引擎的编译三部曲:
- 理解:
分为词法分析和语法分析,词法分析是把源代码字符串转化为词法单元Token;语法分析是在词法分析基础上是被出表达式的语法结构 - 执行
表达式抽象语法结构是树状结构的,抽象语法树一定是唯一确定的,不可以有二义性 - 输入输出
验证执行结果是否为合适的数据类型。同时在规则执行过程中,需要使用输入的参数值来计算语法树中的标识符节点值的过程
3.1 词法分析
词法分析会将源代码字符串转化为词法单元Token。

识别token需要使用到有限自动机,该状态机在任何一个状态,给予输入的字符,都能够做到一个确定状态的转换。其任意输入都对应着唯一的输出,也就是幂等的,这排除了他的二义性
3.2 语法分析
语法分析是在词法分析的基础上,识别表达式的语法结构的过程

我们可以将语句中的某些关键字提炼出来,将其以树状的结构组织起来,从而实现对它们的语法的分析。使用树状结构来实现表达式的切分,这一点在数据结构这门课中有学习到,如果忘记了可以去回顾一下
这种表达式切分形成的树状结构称为抽象语法树,其中每一个节点就是一个语法单元
在构建抽象语法树之前,还需要了解一些概念:
上下文无关语法
也就是编程语言句子不需要结合上下文就可以判断正确性,可以使用巴克斯范式BNF表达。现在的编程语言都是上下文,比如:
r := a+b
就是一个上下文无关语法,因为无论上下文是何种情况,r=a+b的执行流程都是一样的。其中BNF的表达式示例如下
exp : add;
add : add '+' mul | mul //加法表达式
mul : mul '*' pri | pri // 乘法表达式
pri : string | bool | number | identifer //基础表达式
其中add : add ‘+’ mul | mul中,第一个add表示这是加法的BNF,第二个add表示为加数,第一个mul表示+运算符可以使用加数+乘数的形式(这个解释并不是太好)。
介绍完BNF之后,需要介绍递归下降算法,这是一个自顶向下构造语法树的算法,我们用实际例子进行讲解:
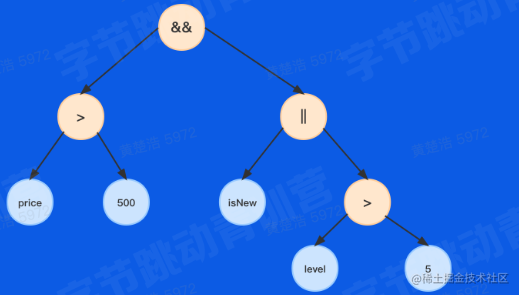
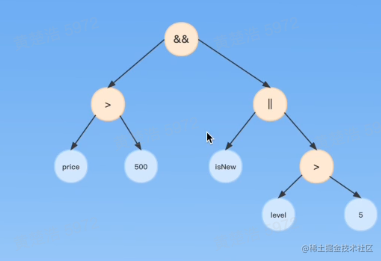
完成对
price>500 && (isNewUser || userLevel>5)
的语法解析
首先我们写出需要用到的BNF
exp : log;
log : log ('&&' | '||') cmp | cmp // 逻辑表达式
cmp : cmp '>' add | add // 比较表达式
add : add '+' mul | mul //加法表达式
mul : mul '*' pri | pri // 乘法表达式
pri : const | id | (exp)
其中优先级从上到下依次降低。
首先判断第一个token,也就是price
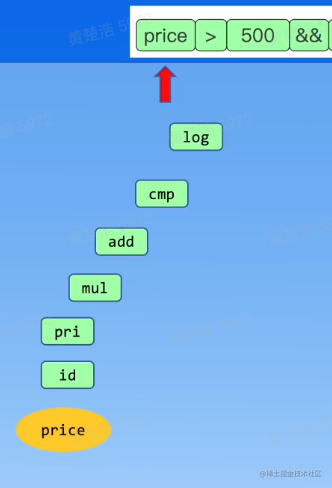
发现既不是逻辑表达式,也不是比较表达式,也不是加法,也不是乘法,也不是基础表达式,那么则是一个普通的标识符
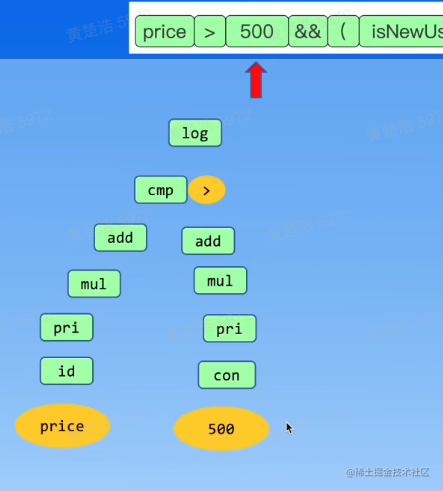
接下来继续向下,下一个token为大于号>。我们上面递归到了底部,然后开始向上回溯,回溯到cmp的时候,符合要求,那么判断其是一个比较表达式。然后判断下一个token,为常量500,向下递归,发现其是一个常量,此时的递归下降算法图示如下
重复刚才的回溯步骤,发现下一个token是&&,是一个逻辑表达式。一直递归,到了最后其语法树如下:
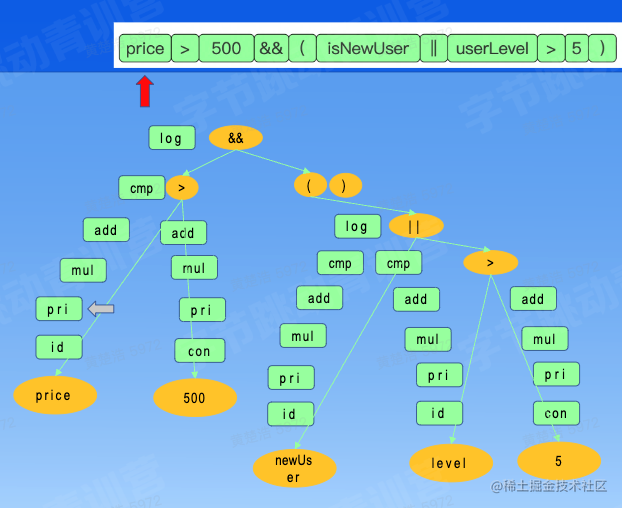
最后将未命中的去除,得到最终的语法树
3.3 语法检查
类型综合
根据子表达式的类型构造出父表达式的类型,例如,表达式a+b的类型是根据a和b的类型定义的。比如:int a=10,int b=20,这是两个子表达式,那么a+b父表达式肯定是int型的。这也可以检查出不合法的父表达式,比如说string s=“str”, a=10,那么s+a则会被判断为非法
类型检查可以发生在表达式编译阶段,也就是构造语法树阶段,也可以发生在执行时阶段。编译时检查需要提前声明参数类型,而运行时检查可以根据执行时输入的值进行类型检查















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









