




文章目录
一、基本思想
1、基本介绍
1、critic
Q-learning 是 value-based 的方法,在这种方法中我们不是要训练一个 policy,而是要训练一个critic网络。critic 并不直接采取行为,只是对现有的 actor π \pi π,评价它的好坏。

2、状态价值函数 V π ( s ) V^{\pi}(s) Vπ(s)
V π ( s ) V^{\pi}(s) Vπ(s)是对于actor π \pi π, 给定状态s,期望得到的累积收益,即在遇到游戏的某个 state 后,采取策略为 π \pi π的actor 一直玩到游戏结束,所能得到的 reward 之和。
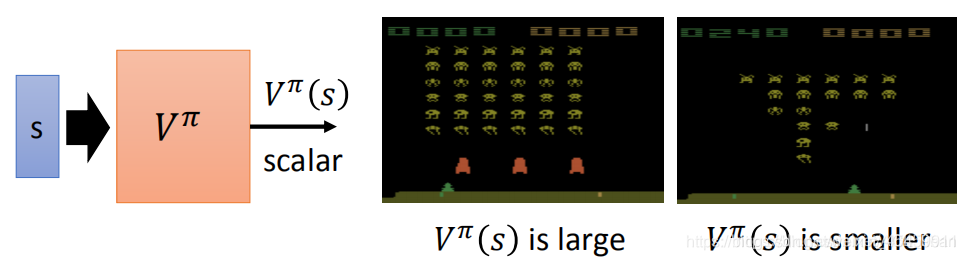
V π ( s ) V^{\pi}(s) Vπ(s)的输入是某个state,输出是一个scalar标量。所以该值取决于状态s和actor π \pi π。
2、状态价值函数 V π ( s ) V^{\pi}(s) Vπ(s)的评估
有两种方法:
1、基于蒙特卡洛的方法Monte-Carlo (MC)
critic 观察 π \pi π 进行游戏的整个过程, 直到该游戏回合结束再计算累积收益(通过比较期望收益和实际收益G,来训练critic)
Tip: 有时一个游戏回合可能会很长,这个等到游戏回合结束再计算收益的方法训练起来会花费过长的时间,因此引入另外一种方法 Temporal-difference(TD)
2、时序分差方法Temporal-difference (TD)

即,时序分差算法计算的是两个状态之间的收益差——通过比较期望差异与实际差异r之间的差别来训练critic。
3、MC与TD比较
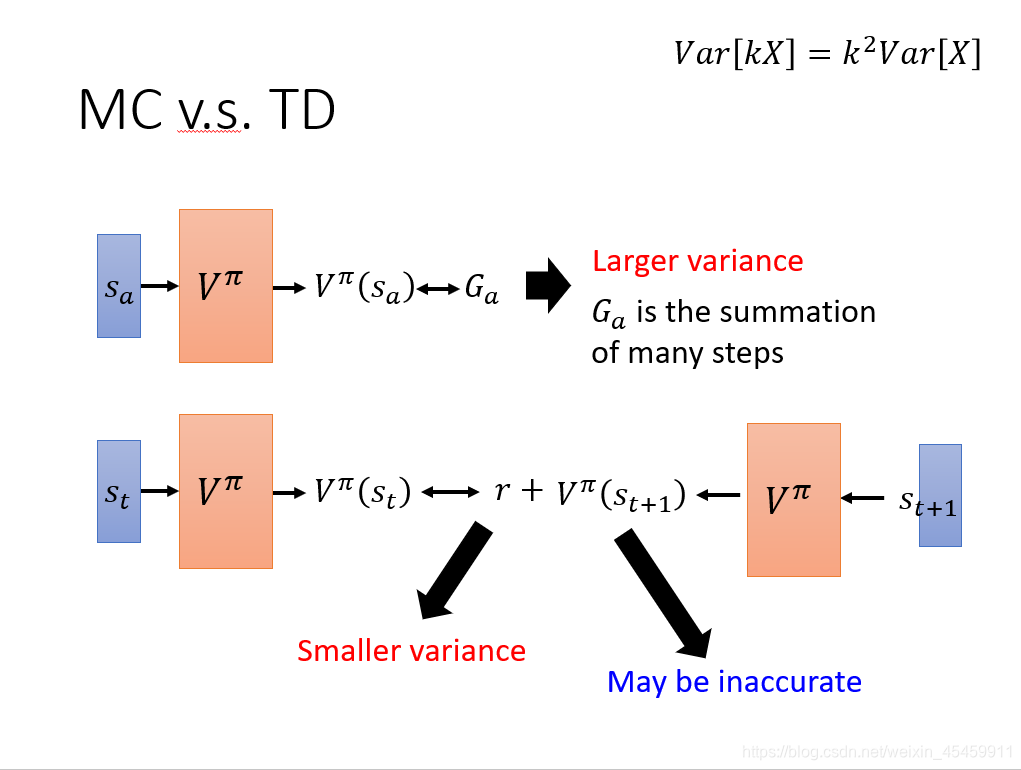
MC 方法的问题在于最后得到的Ga的方差很大(Ga是 在遇到 的情况下使用策略 π \pi π的actor一直玩游戏直到结束得到的实际 reward,是一个随机变量,因为游戏是有随机性的,所以每一次得到Ga是不一样的)。
假设Ga是k步 reward 的求和,而根据公式 V a r [ k x ] = k 2 V a r [ x ] Var[kx]=k^2Var[x] Var[kx]=k2Var[x] ,最终会相差k^2倍。所以最后Ga的方差很大,即每次算出来的 V π ( S a ) V^\pi(S_a) V
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2725
2725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









