







 本文介绍了一种处理连续动作优化问题的算法——Normalized Advantage Functions (NAF)。NAF通过引入新的网络结构,解决了传统Q-learning在面对连续动作空间时的局限性。文章详细解释了NAF如何将Q值分解为状态值函数V和动作价值函数A,以及其执行过程。
本文介绍了一种处理连续动作优化问题的算法——Normalized Advantage Functions (NAF)。NAF通过引入新的网络结构,解决了传统Q-learning在面对连续动作空间时的局限性。文章详细解释了NAF如何将Q值分解为状态值函数V和动作价值函数A,以及其执行过程。
本文是在https://blog.csdn.net/acl_lihan/article/details/104076938的基础上进行了部分改动,加上了一点个人理解,原博客写的非常好,不妨一同查阅。
普通的Q-learning比policy gradient比较容易实现,但是在处理连续动作(比如方向盘要转动多少度)的时候就会显得比较吃力。
因为如果action是离散的几个动作,那就可以把这几个动作都代到Q-function去算Q-value。但是如果action是连续的,此时action就是一个vector,vector里面又都有对应的value,那就没办法穷举所有的action去算Q-value。
本文就介绍一个用来处理连续动作的算法Normalized Advantage Functions(NAF)
当然,最常见的处理方法还是不使用Q-learning而使用actor-critic
一、NAF算法
设计一个新的网络来解连续动作的最优化问题。
先给出概念如下,后面再讲具体的。
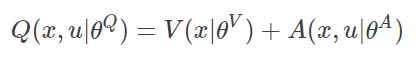 (公式3-1)
(公式3-1)
此时Q value 由状态值函数V与动作价值函数 A 相加而得。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2641
2641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









