







【强化学习论文解读 1】 NAF
1. 引言
本文介绍一篇2016年发表在ICML的文章:Continuous Deep Q-Learning with Model-based Acceleration。
论文传送门:Continuous Deep Q-Learning with Model-based Acceleration
论文有两个亮点,一是提出了一种用于连续动作版本的 Q-learning 算法,将其命名为 normalized adantage functions (NAF),它是常用的policy gradient算法和actor-critic算法的替代品,文中也说明了它在很多任务上比DDPG算法表现地更好;二是提出Imagination Rollouts方法扩充replay buffer的样本,从而用学到的模型来加速model-free算法的样本利用效率。
2. 论文解读
2.1 背景
在现实物理世界中,比如机器人和自动驾驶领域,model-free算法采样的复杂性很大(尤其是使用高维函数近似器),在当时(论文发表之前)很多学者采取的做法是使用特定任务表征(task-specific representations )的高效model-free算法,或者用model-based算法优化策略。
特定任务表征的model-free算法虽然能够提升算法效率,但是需要较多的领域知识;而model-based算法虽然也能够提升算法效率,但是它限制了策略最多也就和学到的模型一样好。
对于许多现实世界的任务来说,表征一个好的策略可能比学习一个好的模型更容易。例如,一个简单的机器人抓取行为可能只需要在正确的时刻关闭手指,而相应的动力学模型需要学习经历摩擦接触的刚体和可变形体的复杂性。因此,作者希望通过降低样本的复杂性,将model-free算法的通用性引入现实世界领域。
在本文中,提出了两种互补的技术来提高连续控制领域中深度强化学习的效率。第一种技术就是用于连续动作领域的变种Q-learning,也就是NAF,第二种技术就是提出Imagination Rollouts方法,将NAF和已学到的(环境)模型合并,从而在保持model-free方法优势的同时,可以加速算法训练。
2.2 NAF算法原理
和actor-critic算法(如DDPG算法需要actor网络和critic网络)不同,NAF算法仅需要一个网络进行估计。正是因为更简单的优化目标和值函数参数化的选择,使得NAF在连续控制领域中使用大型网络结构时具备更好的样本效率,训练也更加迅速。
在本文中,各符号及其含义为:
状态变量 x ∈ X \boldsymbol{x} \in \mathcal{X} x∈X,动作变量 u ∈ U \boldsymbol{u} \in \mathcal{U} u∈U,环境 E E E,即时奖励 r ( x , u ) r(\boldsymbol{x}, \boldsymbol{u}) r(x,u),累积奖励 R t = ∑ i = t T γ ( i − t ) r ( x i , u i ) R_{t}=\sum_{i=t}^{T} \gamma^{(i-t)} r\left(\boldsymbol{x}_{i}, \boldsymbol{u}_{i}\right) Rt=∑i=tTγ(i−t)r(xi,ui),初始状态分布 p ( x 1 ) p\left(\boldsymbol{x}_{1}\right) p(x1),环境动力学分布 p ( x t + 1 ∣ x t , u t ) p\left(\boldsymbol{x}_{t+1} \mid \boldsymbol{x}_{t}, \boldsymbol{u}_{t}\right) p(xt+1∣xt,ut), 当前策略 π \pi π,当前策略的某状态 x t \boldsymbol{x}_{t} xt的状态访问频率 ρ π ( x t ) \rho^{\pi}\left(\boldsymbol{x}_{t}\right) ρπ(xt)。
强化学习的目标是最大化回报,回报即:
R = E r i ≥ 1 , x i ≥ 1 ∼ E , u i ≥ 1 ∼ π [ R 1 ] R=\mathbb{E}_{r_{i \geq 1}, \boldsymbol{x}_{i \geq 1} \sim E, \boldsymbol{u}_{i \geq 1} \sim \pi}\left[R_{1}\right] R=Eri≥1,xi≥1∼E,ui≥1∼π[R1]
在强化学习算法中,描述动作价值的Q函数的表达式为:
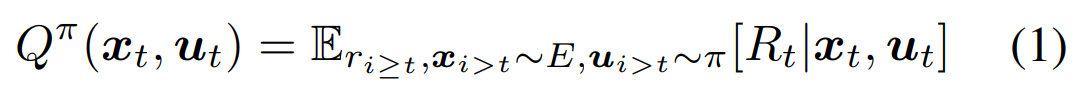
而通常用一个神经网络来估计Q函数,Q网络的参数记为 θ Q \theta^{Q} θQ,而网络训练的loss函数为:
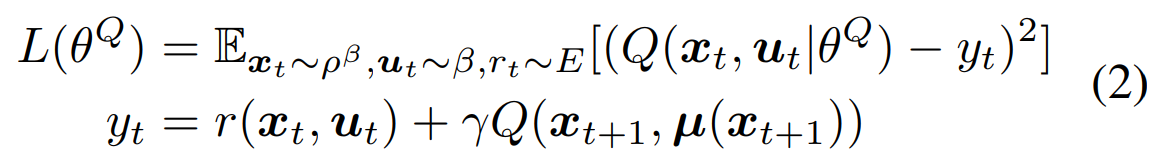
此loss函数是最小化bellman error的,其中:
β
\beta
β代表随机探索策略,
ρ
β
(
x
t
)
\rho^{\beta}\left(\boldsymbol{x}_{t}\right)
ρβ(xt)代表此策略的某状态
x
t
\boldsymbol{x}_{t}
xt的状态访问频率,
μ
(
)
\mu()
μ()代表完全贪婪策略策略,即:
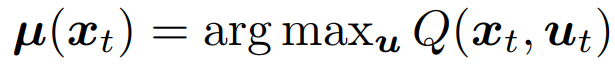
借鉴Dueling DQN的思想,作者将Q拆为advantage function A和 value function V两部分相加.
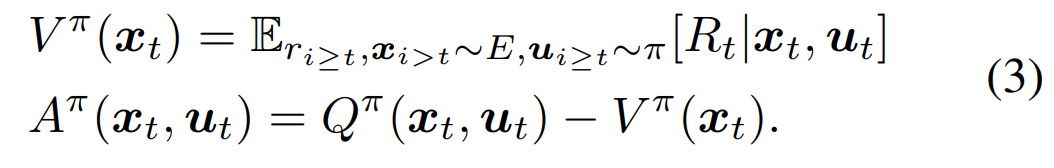
作者构建了一个神经网络(这就是NAF算法网络),其output为一个value function项
V
(
x
)
V(\boldsymbol{x})
V(x)和一个advantage项
A
(
x
,
u
)
A(\boldsymbol{x}, \boldsymbol{u})
A(x,u),而advantage项被参数化为状态的非线性特征的二次函数,即:
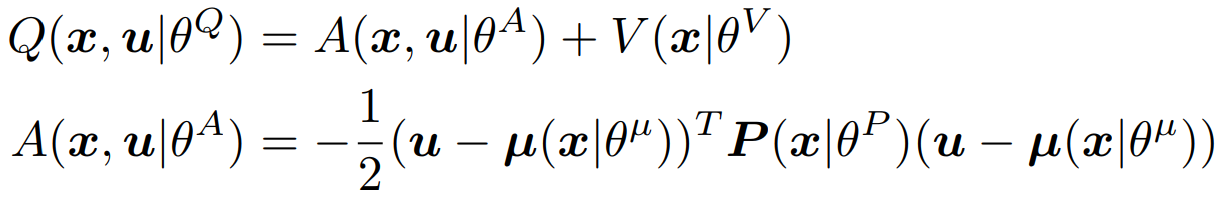
其中: P ( x ∣ θ P ) \boldsymbol{P}\left(\boldsymbol{x} \mid \theta^{P}\right) \quad P(x∣θP)是与状态相关的正定矩阵,而正定矩阵可以被一个下三角矩阵表示出来,即: P ( x ∣ θ P ) = \boldsymbol{P}\left(\boldsymbol{x} \mid \theta^{P}\right)= P(x∣θP)= L ( x ∣ θ P ) L ( x ∣ θ P ) T \boldsymbol{L}\left(\boldsymbol{x} \mid \theta^{P}\right) \boldsymbol{L}\left(\boldsymbol{x} \mid \theta^{P}\right)^{T} L(x∣θP)L(x∣θP)T。 L ( x ∣ θ P ) \boldsymbol{L}\left(\boldsymbol{x} \mid \theta^{P}\right) L(x∣θP)是下三角矩阵,而此下三角矩阵的元素来自于神经网络的线性层输出。
可以看到这种Q网络的表示比一般的Q网络限制更多,因为它要求Q函数是关于动作 u \boldsymbol{u} u的二次型。想要采取一个动作 u \boldsymbol{u} u最大化Q值,那么只能让 u \boldsymbol{u} u取此状态下的完全贪婪策略动作 μ ( x ∣ θ μ ) \boldsymbol{\mu}\left(\boldsymbol{x} \mid \theta^{\mu}\right) μ(x∣θμ),这也体现了原始Q-learning的思想。(作者也说道,一般来说,优势函数A不需要是二次的,探索其他参数形式,如多模态分布是future work)
可以看到NAF算法中,神经网络的输出有三部分:一是状态价值 V ( x ∣ θ V ) V\left(\boldsymbol{x} \mid \theta^{V}\right) V(x∣θV),它是一个标量;二是完全贪婪策略下的动作 μ ( x ∣ θ μ ) \boldsymbol{\mu}\left(\boldsymbol{x} \mid \theta^{\mu}\right) μ(x∣θμ),它是一个矢量,其维度等于动作维度;三是下三角矩阵 L ( x ∣ θ P ) \boldsymbol{L}\left(\boldsymbol{x} \mid \theta^{P}\right) L(x∣θP)中的元素,其维度与动作维度有关,若动作维度为 n n n,那么此矩阵的维度为 ( 1 + n ) ∗ n / 2 (1+n)*n/2 (1+n)∗n/2。通过这三部分输出,结合公式,即可算出动作的Q值。
NAF算法的伪代码如下所示,为了保证网络的收敛效果,采用了target networks和replay buffers的技巧:

值得注意的是,正如前面所述,Q网络的输出是三部分,因此在更新Q网络的时候,就已经更新了 V ( x ∣ θ V ) V\left(\boldsymbol{x} \mid \theta^{V}\right) V(x∣θV)、 μ ( x ∣ θ μ ) \boldsymbol{\mu}\left(\boldsymbol{x} \mid \theta^{\mu}\right) μ(x∣θμ)、 L ( x ∣ θ P ) \boldsymbol{L}\left(\boldsymbol{x} \mid \theta^{P}\right) L(x∣θP)的值。可以看到replay buffer中的数据在反复地用,Q网络更新以后,旧的数据还能用来更新,因此NAF是一个off-policy的方法。
以下是NAF算法和DDPG算法的效果对比图:
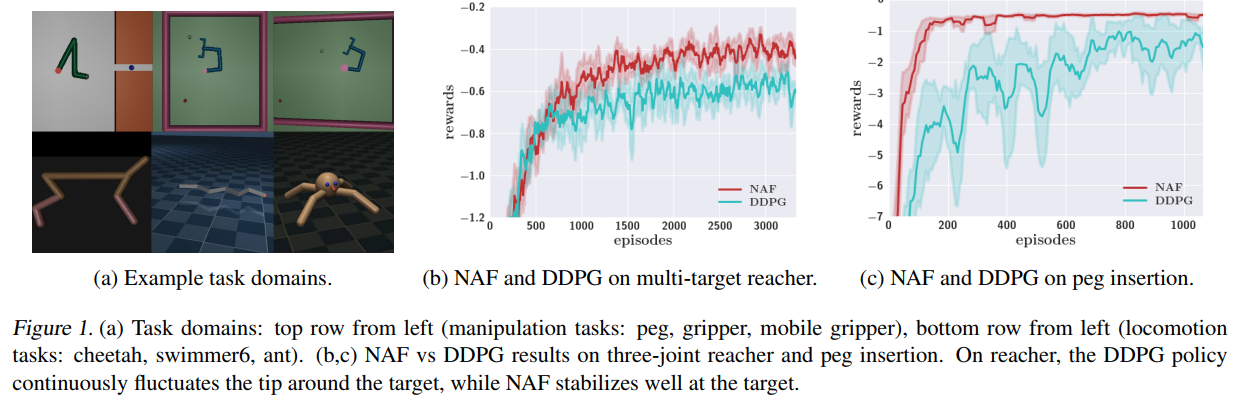
以及部分实验结果:

2.3 Imagination Rollouts方法
Imagination Rollouts是通过learned model,生成on-policy的样本,类似于Dyna-Q方法。它想结合model-free的通用性与model-based的高效性(因为model-based方法可以用模型来生成很多样本,从而减少与环境的交互)。
虽然NAF算法有一些超越actor-cirtic这种在连续动作领域的model-free方法的好处,但是论文作者并不满足,他们想要进一步地利用learned model来提升样本利用率。(实际上就是扩充数据)
首先作者做了简单的尝试,他们用iLQG算法(有模型方法,具体iLQG方法的介绍可以参考:有模型的强化学习—LQR与iLQR)去生成好的轨迹,然后去扩充replay buffer,但是发现这样做对Q-learning算法的效果提升很小。作者认为Q-learning只是看好的动作是不够的,一定要经历过差的动作才能知道哪个动作好,哪个动作差(生活小哲理,hhhh)。
虽然这个道理很简单,但是在现实世界中,比如机器人和自动驾驶领域,这种差的动作会带来极大的危险。如何避免这一问题呢?一种方法是仍然允许大量的on-policy探索,用learned model去生成synthetic on-policy trajectories,而这个synthetic samples 作者将它称为imagination rollouts 。将这些synthetic samples加入到 replay buffer中可以有效地增加Q-learning的经验数据。
而这种特殊的方法在现实世界中 常用planned iLQG trajectories 和 on-policy trajectories 混合出 real-world rollouts(这通常还需要一些用实验确定的混合系数),然后用 learned model 对 real-world rollouts 访问的每个状态,生成额外的 synthetic on-policy rollouts 。这种方法可以看成是Dyna-Q算法的变种,Dyna-Q算法只能用于小型离散控制领域,而此方法可以用于连续控制领域。
带Imagination Rollouts的NAF算法如下所示:

在一些场合中,甚至可以用 off-policy iLQG 控制器(考虑safety-critic)来生成全部的或者大多数的real rollouts,以此来保证安全。
作者在用Imagination rollouts的时候,发现当learned model不准确时,Imagination rollouts会引起很大的偏差。作者发现,比如learned model是一个非线性神经网络,用它去拟合动力学,训练起来非常困难(也就是learned model不准确),然后作者发现使用iteratively refitted time-varying linear models(此方法是2014年Levine提出的)作为learned model去学,能够产生更好的结果。iteratively refitted time-varying linear models 并不是针对所有状态和动作去学习一个好的全局模型(global model),而是想要在最新的样本集中学习一个好的局部模型(local model),此模型也有一些附加假设,即:初始状态为确定性的或者低方差的高斯分布,以及要求所有状态和动作都是连续的。
同时作者还发现,当Q网络的估计很不准确时,model-based 的方法可以带来训练的好处,但是一旦Q网络的估计准确时,on-policy方法(也就是model-free)收集到的数据会更好,会超越model-based控制器。基于这点观察,作者就设置了在一个指定迭代次数时,关掉Imagination rollouts,不再为replay buffer生成synthetic samples。
下图展示了混合使用 off-policy iLQG experience 和 imagination rollouts 在 the three-joint reacher 上的效果:
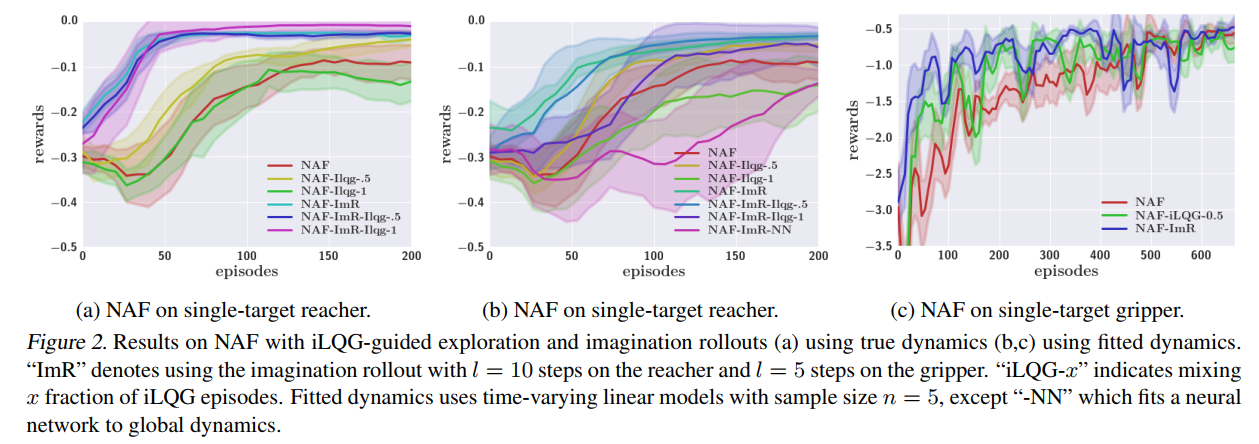
3. 总结
总结一下全文,为什么之前的Q-learning不能用于连续动作,而NAF可以?
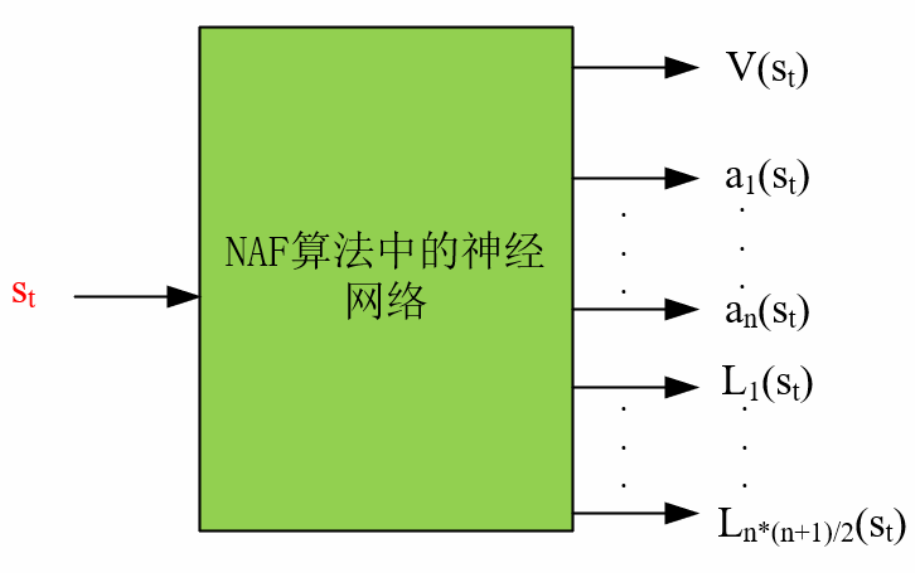
在DQN算法中,神经网络的输出维度是离散动作的数量,每一个输出值代表动作的Q值,那么最大Q值对应的动作就是当前状态需要采取的动作。而对于连续的动作,神经网络的动作输出只能是动作的维度,输出值代表动作在那个维度的取值,这样没法知道当前动作的好坏,以及不知道Q值最大的动作是什么,而NAF算法就解决了这一问题。
如下图所示,NAF网络的输入为当前状态 s t s_t st,假设连续动作的维度为 n n n,那么输出为当前状态价值 V ( s t ) V(s_t) V(st)、连续动作在那一维的取值 a i ( s t ) ( i = 1 … n ) a_i(s_t) (i=1 \dots n) ai(st)(i=1…n)、下三角矩阵的元素 L k ( s t ) ( k = 1 … n × ( n + 1 ) / 2 ) L_k(s_t) (k=1 \dots n\times(n+1)/2) Lk(st)(k=1…n×(n+1)/2)。
其中 a i ( s t ) a_i(s_t) ai(st)就是当前状态的最优动作,它能让Q值最大,并且对于任何一个动作,它都能够通过神经网路三部分输出反解出其Q值,这也是NAF的妙处。(当然论文作者也承认自己用了很强的一个假设,即A是二次型的假设)
















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









