






0.引言
为了发小论文,最近重新整理了一下深度学习的一些基础知识。我发现哪怕是一些最基础的代码(比如题目中的Mnist数字集的识别),刚学的时候对着教材抄代码以为自己都搞懂了,后面才发现其实简单的代码里还藏着很多初学时候搞不懂的知识点。翻了一下CSDN上关于Mnist识别的教程里面,基本都是告诉你是什么该怎么做,但往往没有告诉你为什么要这么做,这可能导致初学者看着教程懂了要怎么干,但是关掉教程却发现什么也没学到。基于此我想写这一个blog帮助一些人工智能特别是深度学习的初学者更好的理解这个相当于‘hello world’的程序实现过程。
话不多说,马上开始吧。
0.1本文环境
本文代码的实现需要你电脑里有以下几个工具包:
Python 3.8
Keras 2.3.1
Numpy 1.20.3
Matplotlib 3.4.2
限于篇幅这几个包怎么装怎么用我就不多说了(都是非常常用的包,相关资料应该全网到处都有)
1.简述
1.1功能介绍
Mnist是一个非常非常经典也是非常非常基础的数据集,大多数初学机器学习的人都是从这个数据集开始的,所以说Mnist也被称为机器学习里的“Hello World”。它是一个包括了60000个手写数字的数字集,来源于美国一个简称为Nist的研究所,由250个不同的人手写而来。本程序的功能就是识别Mnist里手写数字到底对应阿拉伯数字里的几。
我们先简单看看Mnist里的数字,下图是Mnist的前四个手写数字。
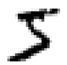

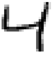
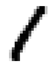
你可能觉得识别这些数字非常简单是不是,但在人工智能特别是机器学习技术发展之前,怎么教会电脑识别这些数字曾经是困扰科学家很久的问题,而识别的准确率也一直不理想。但现在最先进的算法识别这一数据集的准确率已经高于99%,今天介绍的几行代码实现的算法准确率也在高于98%。这就是人工智能的魅力。
1.2程序流程
麻雀虽小,五脏俱全(笑),该程序的流程包括:
1.数据导入
2.数据预处理
3.构建网络
4.训练模型
5.模型评估
下面就一步一步用代码实现吧~~~
2.代码实现及超详细解释
2.1数据导入
代码:
>>> (train_images,train_labels),(test_images,test_labels)=mnist.load_data()
仅仅这一行代码就从keras的库里加载完了mnist数据集。这一数据集由四个numpy数组构成,分别是train_images、train_labels、test_images、test_labels。为了便于理解,我们多打几行代码以更清楚的认识这一数据集。首先我们来call一下train_images的shape。
>>> train_images.shape
(60000, 28, 28)
可以看到train_images是一个三维的张量(tensor),第一维是图片的数量,也就是它是由6w张图片构成的数据集;2.3维是它的像素,每张图片像素都是28*28。
我们再来call一下train_images的第10个元素。
>>> train_images[9]
回应太长了就不粘贴了,刚学python的同学可能会问为什么第十个元素为什么用train_images[9],那是因为python是从0开始计数的。train_images里的每一个元素都是一个二维的张量,每一维的长度都是28,对应28个像素。
有人可能会问我怎么把某个元素call出来看看到底在图片里长什么样子啦,那我们就来call一下好了。
>>>digit = train_images[9]
>>>plt.imshow(digit, cmap=plt.cm.binary)
>>>plt.show()
那第十张图片就是长这个样子了(可以看得出美国佬写数字真的和我们很不一样额有没有)。

那到这里应该大家都对这个数字集认识的蛮深了有没有,那接下来就要对这个数字集做一些预处理,把它变成机器学习模型能够学习的样子。
2.2数据预处理
代码:
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
我们先来看前俩行代码的意思。np.reshape可以把一个数组重塑为另一个格式,具体的用法可以用下面的代码更详细的看到。
>>>help(np.reshape)
np.astype可以重新定义数组里元素保存的格式,同样可以用下面代码更详细的浏览其用法(后面某个key word的用法介绍我就不重复了)。
>>>help(np.astype)
前两行代码可以把train_images重塑为网络期望的形状并对其进行缩放来预处理数据,以便所有值都在[0,1]区间内。例如,以前,我们的训练图像存储在(60000,28,28)类型uint8为[0,255]区间的形状数组中。我们将其转换为一个值在0到1之间float32的形状数组(60000, 28 * 28)。3,4两行的功能也是类似的。
5,6行的代码的功能是把标签里的离散的数转化成一个数组。比如,train_labels本来是一个离散的取值区间在[0,10]里的整数,但是这个数在网络模型里并不表示大小,它仅仅是一个标签,比如train_labels[0]在转化前就是一个标签整数7,在转化后就变成了一个array,[0,0,0,0,0,0,0,1,0,0],它只有在表示序列7的第8位是1,其他都是0。
到此,数据的预处理完毕。
2.3构建网络
代码:
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
我们来看一下每一行的意思。首先第一行models.Sequential()就等于告诉python,我要开始叠积木了,然后你就要一层一层定义你的网络。这个网络通常由通常由输入层、多层隐藏层、输出层构成,下面这张图能帮你更好的理解机器学习的神经网络(深度学习也是类似的,你可以理解隐藏层很深很深的机器学习就是深度学习)。
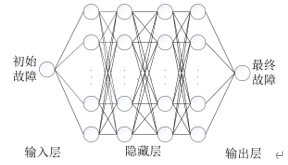
这种图是从我的小论文里截来的啦,初始故障和最终故障在这里就应该对于初始数据和预测数据,但是我懒得重新画图了就不改了啊,大家应该都能理解。
本网络只有一个隐藏层。前一层的数据乘以一个系数矩阵再通过一个非线性函数传递到下一层,这个系数矩阵就是机器学习算法要求的最佳解。那什么是最佳解呢?这里就要定义一个损失函数。常用的损失函数就是categorical_crossentropy,它具体的函数定义可以在keras的官网上搜到。
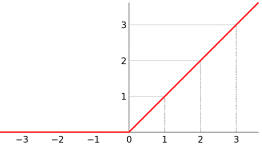
2.3行就是每一层的定义,那因为我们这个网络比较简单,只有一个隐藏层和一个输出层,所以需要定义的就只有2层。第一层中,512代表这个层有几个神经元,relu代表它用的非线性函数是relu(非常经典的机器学习常用非线性函数),函数图像大概就长下面那样。
第二次同理,softmax函数,设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是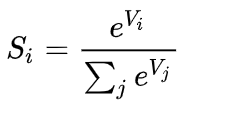 。
。
接下来就要定义网络的优化器、损失函数和监控指标。
损失函数:如何在网络将能够测量在训练它的性能数据,并且将因此如何能够引导自己在正确的方向。
优化器:通过网络将基于它看到的数据和自我更新的机制丧失功能。
监控指标:在这里,我们只关心准确性(正确分类的图像的比例)。
以上,网络构建已经完成。
2.4训练网络
代码:
network.fit(train_images, train_labels, epochs=5, batch_size=128)
一行就搞定了,特别简单是不是?这就是keras厉害的地方,它高度封装了很多算法和模块,,而这些也是初学者最难搞懂的部分。事实上,这一部分内容很多资深工程师也搞得不是很懂。但现在,利用keras我们只需要一行代码就搞定,下面讲解这行代码。
Net.fit就表示,你告诉电脑,我们要开始训练网络了。
这一个算法在训练网络时,并不是训练一遍就完成的。举个例子,我们在上完课之后,在考试之前,通常还有很多模拟考,这些模拟考帮助算法训练以找到更好的参数,使得损失函数最小。举行‘模拟考‘的次数,就对应代码里的epochs。事实上,epochs的次数也不是越多越好,就像举行太多的‘模拟考‘不仅浪费时间(算法耗时长),也会导致同学们沉浸在老题里,失去解新题的能力(过拟合)。在本程序了,eopchs取到5。
训练样本较大的时候(60000),把数据一股脑丢进去是不现实的,在每个epochs里,我们把数据一批一批丢到网络里去训练,每批丢的数据量就对应batch_size,代表我们每次丢128个数据进行训练,等训练完再丢128个。
训练完之后网络之后,如果你的代码没有错,你将会看到如下显示:
Epoch 1/5
469/469 [==============================] - 2s 4ms/step - loss: 0.2581 - accuracy: 0.9258
Epoch 2/5
469/469 [==============================] - 2s 4ms/step - loss: 0.1051 - accuracy: 0.9688
Epoch 3/5
469/469 [==============================] - 2s 4ms/step - loss: 0.0697 - accuracy: 0.9790
Epoch 4/5
469/469 [==============================] - 2s 4ms/step - loss: 0.0509 - accuracy: 0.9841
Epoch 5/5
469/469 [==============================] - 2s 4ms/step - loss: 0.0378 - accuracy: 0.9887
313/313 [==============================] - 0s 648us/step - loss: 0.0721 - accuracy: 0.9783
最终得到的准确率位97.83%。那有人可能要问,我怎么能看到训练的结果呢?敲入:
label_predict=network.predict(train_images)
我们来看看前4个图片的预测结果到底是多少。

没错就是5 0 4 1,这和开头的图片就对上了!!
突然不想写了,就这样草草的结束吧!!如果我能有兴趣,可能会再写一下更复杂的神经网络和训练集,有缘再见吧!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









