






众所周知(并不是),图神经网络通常遵循message passing框架,即:沿着节点之间的边进行信息的传播,并更新节点表示。
上述方式是保持图上结构的好方法,也在很多任务上得到了验证。
但是,最近一篇文章发现:无需message passing,只要简单的MLP就可超越GNN!

本文和目前GNN的最大差异如下图所示:
目前的GNN都是用邻接矩阵A来指导消息传播和聚合过程,后面接一个任务loss,如分类的cross entropy loss
本文则是将节点属性通过MLP来映射为其表示,而邻接矩阵A仅仅用来作为loss,指导优化过程。这里设计了所谓的Neighboring Contrastive Loss 来进行优化。简单来说就是:距离比较近的节点,其表示优化成相似的;距离比较远的节点,其表示优化成不相似的。

具体是怎么做的呢?
首先明确一下,节点的表示是否应该相似。如果节点 在节点 的r-hop范围内,则认为两者应该相似。
相似节点和不相似节点表示分别拉近和推开。 分别代表节点 的表示。
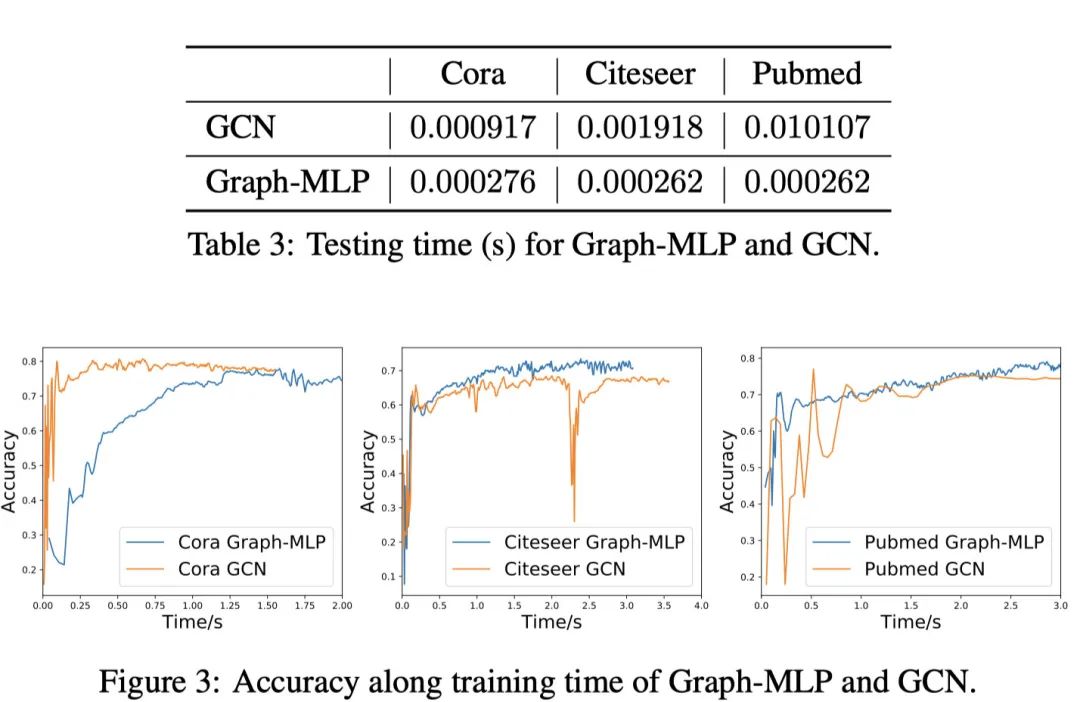
其实到这里,本文的核心设计基本就说完了。下面看看实验结果,简而言之:Graph-MLP又快又好。
另外,Graph-MLP对于噪音连接也更加鲁棒。随机对图结构加上噪音之后,GCN的表现会大幅度的下降,而Grpah-MLP基本保持稳定。

最后,其实本文的做法在先前的Graph Embedding已经有一些了。例如,18ICLR DEEP GAUSSIAN EMBEDDING OF GRAPHS_UNSUPERVISED INDUCTIVE LEARNING VIA RANKING 就是直接将节点属性映射为一个表示(高斯分布),然后基于节点之间的距离远近来进行优化。
















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









