






Mixup-Explainer: Generalizing Explanations for Graph Neural Networks with Data Augmentation
作者:Jiaxing Zhang*, New Jersey Institute of Technology; Dongsheng Luo*, Florida International University; Hua Wei, Arizona State University
Accepted by SIGKDD2023 !

背景与贡献
现有的解释器在对图神经网络的输入进行解释时,通常会生成输入的一个重要子图作为解释,同时通过Graph Information Bottleneck(图信息瓶颈) Objective对解释子图进行优化。但是,现有方法在进行解释时忽略了解释子图的分布偏移问题,即子图的分布与原图数据集不同(不同的节点数量与差异的拓扑结构)。因此,通过GIB直接对解释子图进行优化是存在问题的。
本文(MixupExplainer)主要有以下贡献:
本文第一次指出了图分类任务的可解释性上的分布偏移问题(Out-Of-Distribution)。这个问题在现有的方法与解释器框架中广泛存在。
本文提出了一种图混合框架:这个框架基于mix-up方法改进而来,可以直观且有效的缓解分布偏移问题,并且与GIB目标相结合,提升解释质量。
本文的框架是可泛化的,这意味着可以在各种图解释器上应用该框架并对各种图神经网络产生解释,并取得性能提升。本文在GNNExplainer与PGExplainer应用了此框架,取得了最高达35.5%的提升。
论文地址:https://arxiv.org/abs/2307.07832
代码地址:https://github.com/jz48/MixupExplainer
问题定义
问题定义:假设有一个图神经网络 以及一个图输入 ,post-hoc instance-level 图解释器的目标是找到一个可以解释对所做的预测的解释子图 。
例如:在下图中,左图是一个来自于Mutag数据集的分子。假设有一个训练好的图分类器在MUTAG任务上对此分子做出预测,那么预测的结果(标签)取决于该分子是否包含 与分子。所以,左图解释应当是右图中的子图.
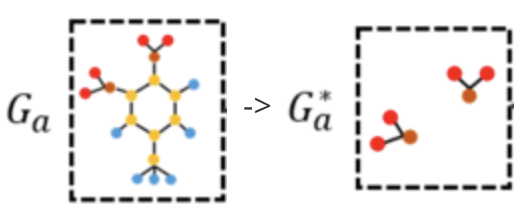
现有方法与其面临的挑战
现有的图解释器,例如GNNExplainer(基于边权优化),PGExplainer(基于全局理解的参数化生成边权)通常使用GIB objective对解释子图(边权)进行优化。
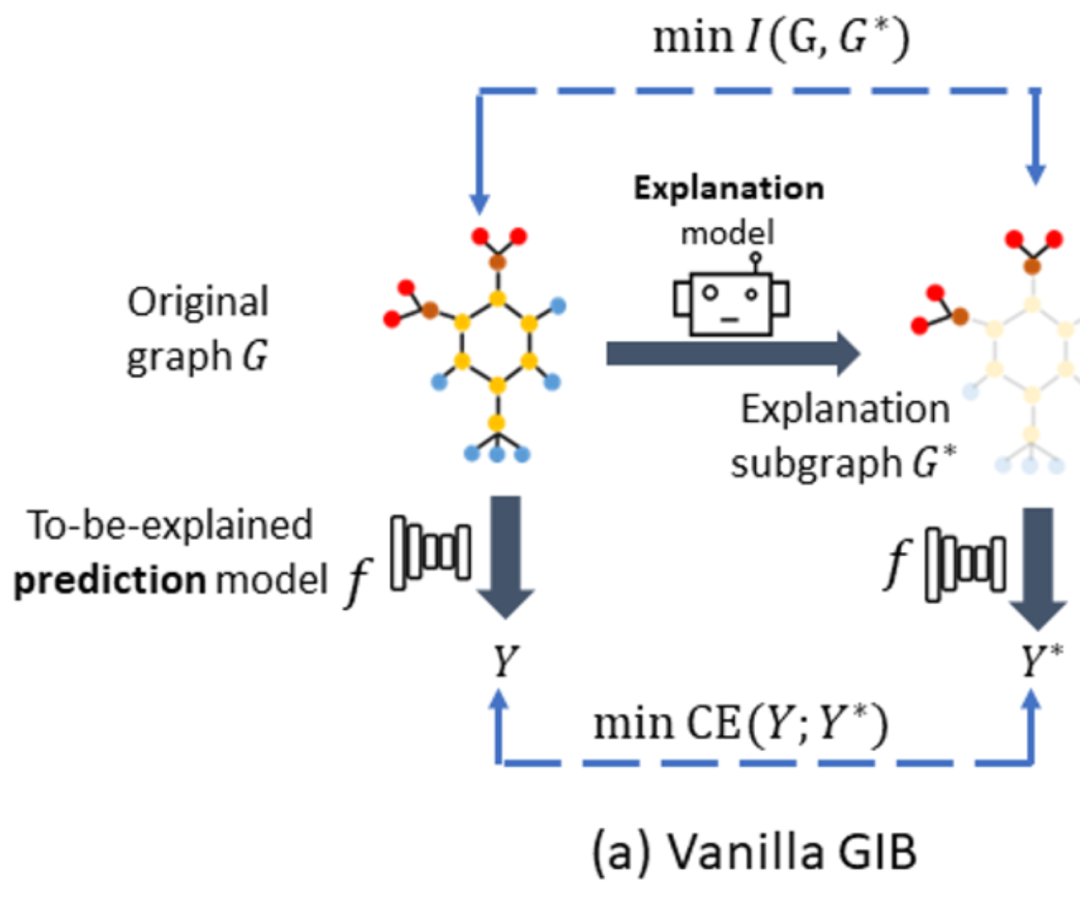
即如下公式:
其中是待解释的原图,是解释子图,是原图的标签。该目标致力于产生一个尽可能小的同时又包含尽可能多的标签信息的解释。该目标一方面优化的大小(现有方法通常认为解释是一个小而紧密的子图);另一方面提高与标签的共有信息,即这个解释子图包含着的使得图神经模型做出正确的预测的标签信息。由于是一个图结构而是一个值,所以无法直接估计。又由于,其中是一个恒量且独立于解释过程,所以公式(1)可以转换为如下形式:
由于在解释上的标签信息的条件熵仍然是难以计算的,所以现有方法通常进行如下近似:
其中,。通过计算与的交叉熵,现有方法得以近似得到。
但是,现有的方法忽略了子图的分布偏移问题。如下图所示:
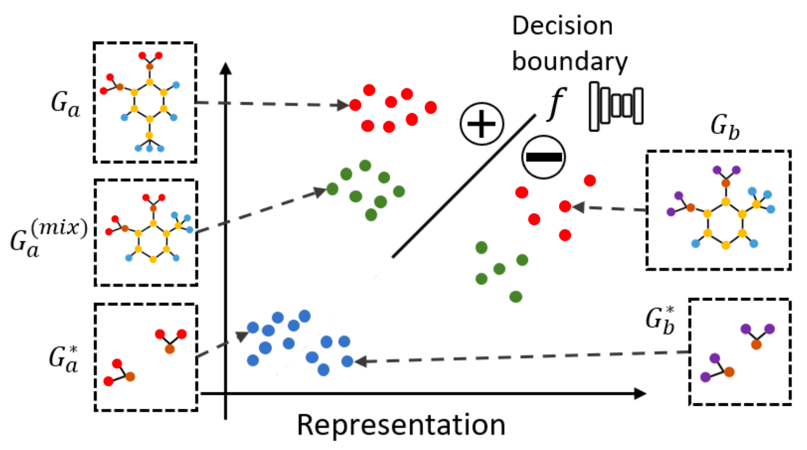
这张图中,红点代表着原图,蓝点代表着解释子图。可以看到,蓝点的分布相较于红点在分布空间上有着较大的偏移。这个偏移会导致 , 即图中的黑色实线段无法对蓝点做出合理的预测,因为它是在红点所在的集合上被训练的。由于无法对做出正确的预测,那么当使用计算交叉熵时,也就无法得出正确的结果。所以,由于分布偏移问题的存在,现有工作无法准确且有效的通过公式(3)优化解释子图。
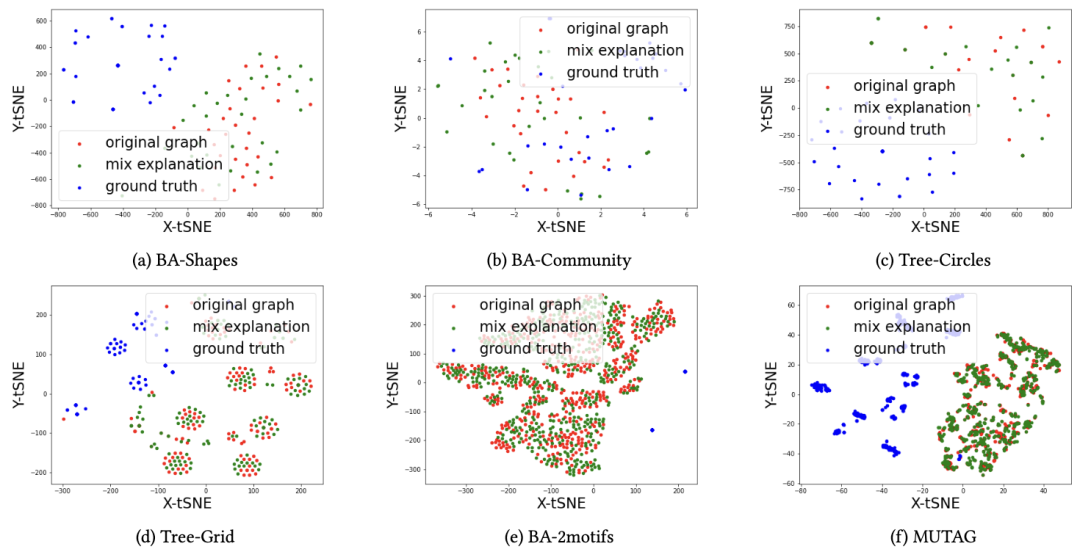
本文在上图中展示了对分布偏移问题在六个数据集上的可视化结果:红点是原图通过GNN模型产生的嵌入式向量的二维分布,而蓝点是解释子图的分布。可以观察到,蓝点的分布相较于红点出现了明显的偏移,无论是在形状上还是距离上。为了解决这个问题,本文提出了一种图混合方法(mix-up approach),如上图所示,绿点所代表的混合图有效的恢复了解释子图的分布。
本文的解决方案:Mix-up框架
推广GIB
为了解决在现有的GIB目标中存在的分布偏移问题,本文通过引入与标签信息无关的子图对GIB进行推广。这么做是出于如下考虑:给定一张图以及与之对应的标签,除了解释子图会包含重要的标签信息以外,原图的剩余部分也包含了有用的分布信息。即会保证与之连接的标签子图不会被分类到错误的标签。所以,给定一个满足,GIB目标可以被推广到如下形式:
可以证明推广的GIB具有如下性质:
公式(4)中的推广GIB与公式(2)中的原生GIB具有等效性。
该性质可以通过条件熵的定义得证。给定条件,可得。即原生GIB的优化解与推广GIB是相同的。与此同时,本文的方法的优势是可以通过引入一个合适的去最小化分布距离。这使得解释器可以在优化过程中避免分布偏移问题。
在此基础上,本文将 进一步近似为 ,其中是通过待解释模型得到的预测标签。特别的,当是一个空图时,该推广目标会退化为原生目标。本文的新的目标函数被定义如下:
Mix-up approach
针对以上挑战,本文提出了一种可泛化的mix-up框架进行应对。如下图所示,在产生了解释子图以后,将其与另一张随机选取的图中的基图(即与标签无关的部分)进行混合。这样既可以保留该解释应有的标签信息,也将该解释的分布恢复到了原图所在的分布空间。
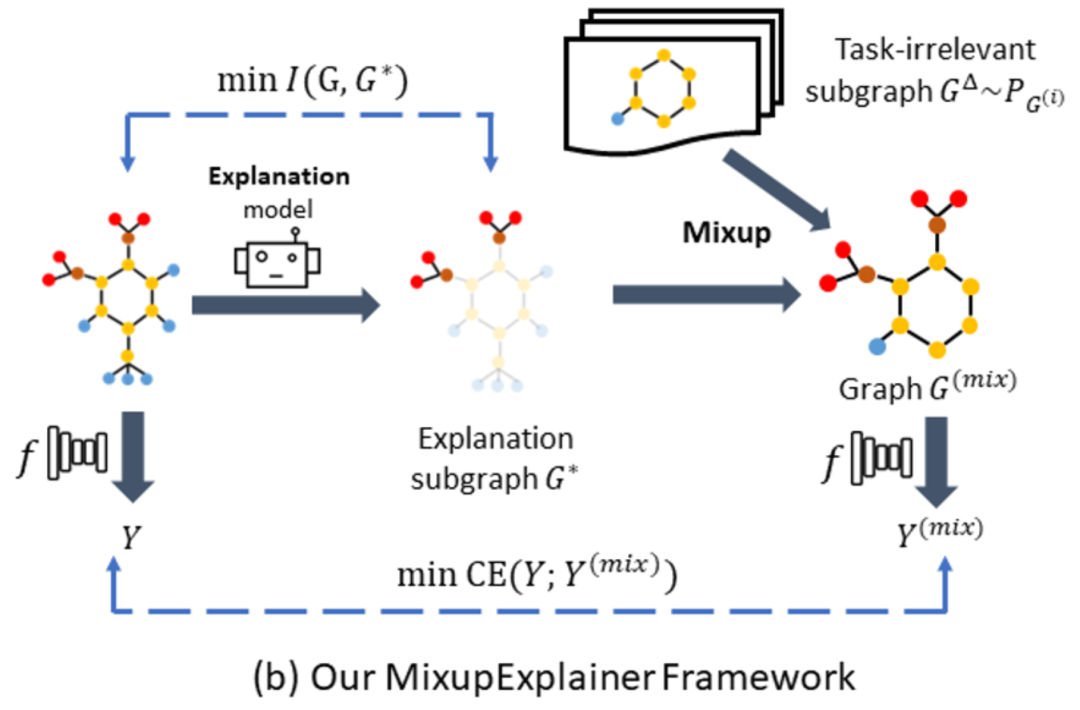
与现有方法的解释器框架不同的是,本文的框架除了依旧通过最小化与的结构互信息约束解释子图的大小以外,还通过优化(即公式(5)中的)与之间的标签互信息来优化解释子图。本文通过构造混合图在不引入额外的标签信息的情况下来恢复的分布,进而使得可以准确的估计的标签信息,亦即的标签信息。
图混合操作是一个非参数化的过程,不影响子图的产生与梯度的传播。本文的mix-up方法可以用以下公式说明:
其中,代表邻接矩阵(边权默认为1),而代表一张图的邻接矩阵所对应的边权矩阵。其中,代表解释子图的边权,代表标签无关的基图的边权。该公式意味着将一个解释子图 与一个标签无关的基图 混合起来,从而正确的计算交叉熵。
对Mix-up方法有效性的理论证明
这一节将从理论上证明mix-up方法可以减少解释子图与原图之间的分布偏移。
命题1:给定原图,对应的解释子图和生成的混合图,有.
证明如下:图可以被视作。其中,代表对图的预测值产生重要贡献的解释子图,而代表原图中包含了与标签信息无关的点和边的基图。虽然不贡献标签信息,但是对原图的分布存在影响。假设与分别独立的服从分布与,可以随机的从数据集中采样。现在有与,二者都服从分布。根据公式(6)可以取得如下混合结果:
可知. 即的分布与相同,进而可得:
数据集与实验结果
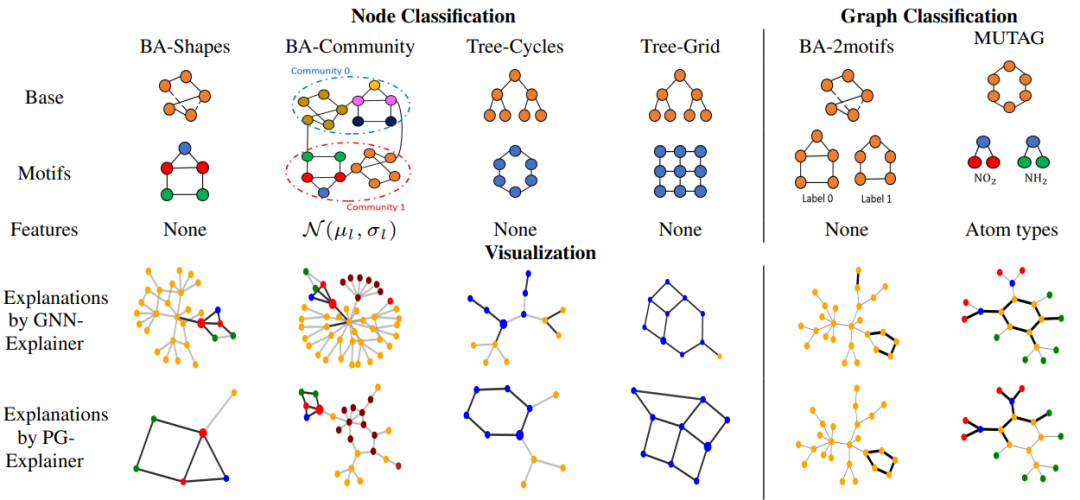
实验所用的数据集如下图所示,其中,MUTAG是真实数据集,其他五个数据集为人造数据集。BA-Shapes, BA-Community, Tree-Cycles和Tree-Grid为节点分类任务,而BA-2motifs和MUTAG为图分类任务。下图表展示了六个数据集的构造与特征,并举例展示了两种基线方法的效果:
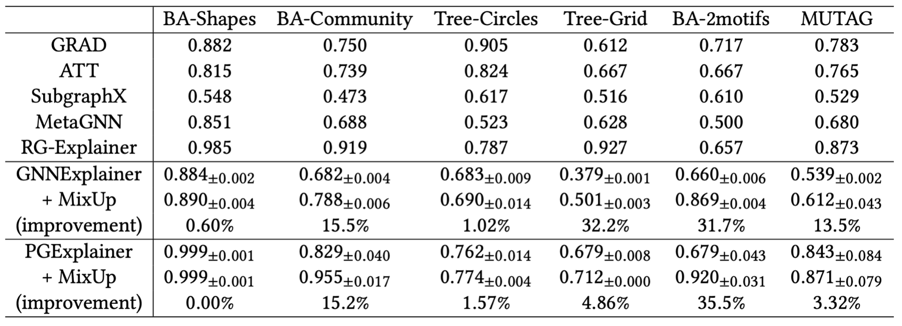
实验对比了GNNExplainer(+mix-up),PGExplainer(+mix-up)与多个基线的性能表现并展示在下面的表格中。可以看到,mix-up方法在所有数据集上都对基准方法产生了提升。并且在部分数据集中取得了最佳效果。在BA-2motifs数据集上,mix-up版本的PGExplainer相较于普通版本的PGExplainer,在各种参数与设定相同的情况下,取得了高达35。5%的性能提升。这有力的说明了mix-up方法的有效性。
总结
这个工作介绍了一种可以应用于各种图解释器的mix-up框架。该框架可以有效的缓解子图的分布偏移问题并提升解释器的性能表现。
Reference
[1]. J. Zhang, D. Luo, and Hua Wei. "MixupExplainer: Generalizing Explanations for Graph Neural Networks with Data Augmentation". In Proceedings of 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD), 2023.
[2]. Github repository with datasets and code for Mixup-Explainer: https://github.com/jz48/MixupExplainer
















 2786
2786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









