







论文地址:https://arxiv.org/pdf/2110.02910.pdf
欢迎关注小编知乎:戴鸽
一篇全文47页的ICLR文章,真的看不完。作者提出了一种新的等变子图聚合网络(ESAN)来改善图网络的表达能力,使之能完成WL测试。与以前的工作最大的差异在于在解决问题的同时也能减小运算空间和内存消耗,并且也能够通过与GCN,GIN这种常见网络结合,提高它们的准确率。
Introduction
一直以来message-passing机制都认为是图神经网络的基本,但有时这种机制并不能完全通过WL同构图测试。在以往的工作中虽然有很多解决这个问题的方法,但作者认为他们都不够高效,消耗空间。因此,作者设计了一种新型等变子图聚合网络(Equivariant Subgraph Aggregation Networks ,ESAN)。大体思路是找到可区分的子图。对这些子图进行编码,可以发现这些编码能够产生更好的表达能力。这个区别可以通过下图示例表示: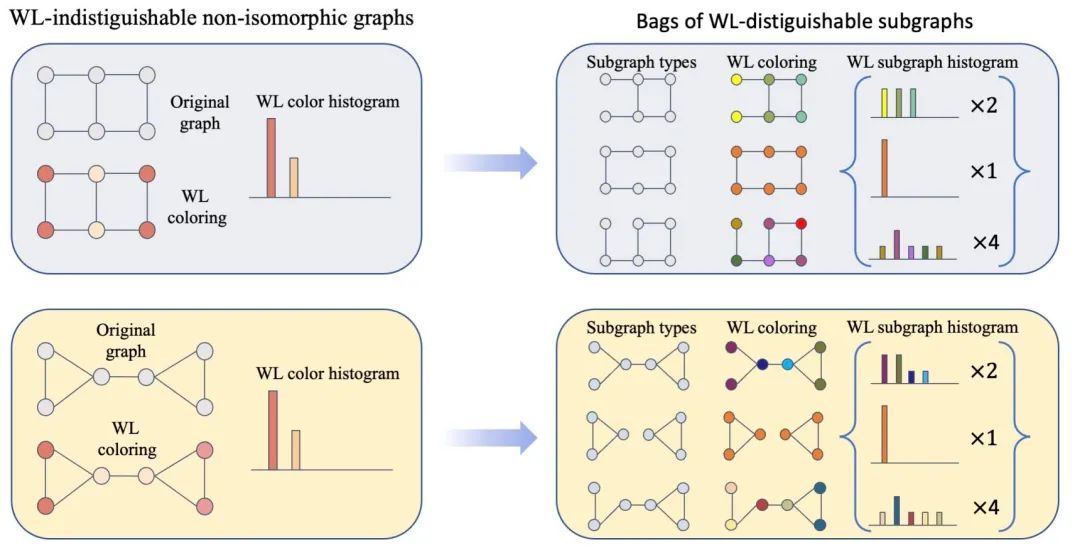 左边表示图无法通过WL测试。右边表示如果删除边得到一些子图,改变了图本身的结构,将这些结构看做包信息,这些包信息就能够极大区分图上的不同节点。作者认为一个图是可以看做由若干子图拼接出来的,因此最好的方法是设计一个同时能区分子图,又能融合这些子图的网络。ESAN的设计包括两个基本的结构,第一个是独立处理每个子图的孪生网络,第二个是一个信息共享模块,用来做子图信息共享和聚合。其中,引出一个新问题,怎么去初始化这些被选择的子图?因此,子图选择策略也是一个重点。
左边表示图无法通过WL测试。右边表示如果删除边得到一些子图,改变了图本身的结构,将这些结构看做包信息,这些包信息就能够极大区分图上的不同节点。作者认为一个图是可以看做由若干子图拼接出来的,因此最好的方法是设计一个同时能区分子图,又能融合这些子图的网络。ESAN的设计包括两个基本的结构,第一个是独立处理每个子图的孪生网络,第二个是一个信息共享模块,用来做子图信息共享和聚合。其中,引出一个新问题,怎么去初始化这些被选择的子图?因此,子图选择策略也是一个重点。
Method
按照常规套路,先定义一个图,叫做,假设这个图可以分解为一堆子图,表示成一个包在图上的预测可以看做是基于这个集合的预测,即。因此,这里就可以展开成两个问题:1. 怎么定义? 2.怎么采样子图?
首先考虑怎么定义这个映射关系。对于这群子图,作者采用DSS-GNN为基础的图网络。由于子图的产生是一系列选择动作变化得到的结果,如图所示: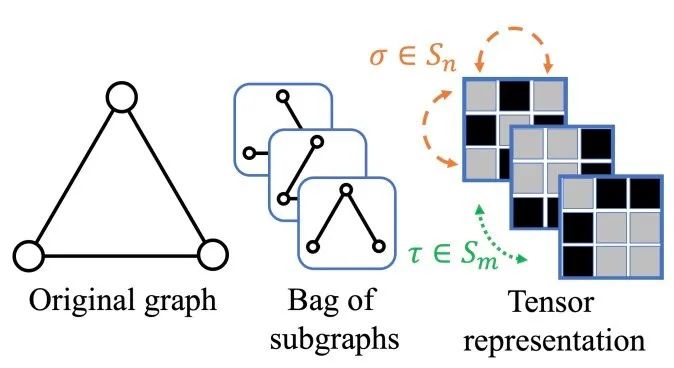 假设左图会被分解成几个小子图,那么可以通过最右边展示的矩阵相互交叉得到一些连接关系的组合。简单来说,就是选择一些可以用来表示选择边的动作来模拟这个过程。这里作者记这个过程为。m表示子图的个数,n表示节点的个数。这套动作可以映射成,将子图分割开以后,自然就要考虑如何刻画这些子图。这里采用了DSS-GNN的结构,如图所示:
假设左图会被分解成几个小子图,那么可以通过最右边展示的矩阵相互交叉得到一些连接关系的组合。简单来说,就是选择一些可以用来表示选择边的动作来模拟这个过程。这里作者记这个过程为。m表示子图的个数,n表示节点的个数。这套动作可以映射成,将子图分割开以后,自然就要考虑如何刻画这些子图。这里采用了DSS-GNN的结构,如图所示: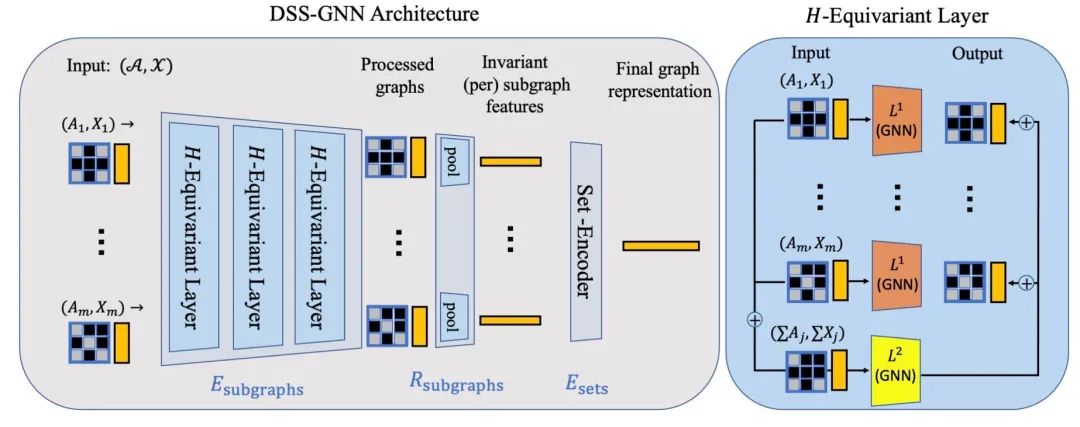
首先说明等变层。这里采用了孪生网络的方式来共享子图成分,具体来说,这里有两个图编码器,分别用和表示,每层更新方法为:
402 Payment Required
作用为更新单独子图信息,作用为共享子图之间的信息。另外,如果这里,就是这个网络的一个变种,DS-GNN,之后的实验有对比这个变种的效果。之后就可以把这些等变层组装起来了,如左图所示,式子可以写成:
表示把等变层联系到一起结果,可以看做
402 Payment Required
, 表示子图的readout结果,为402 Payment Required
, 为图最终的编码结果,将分割的m个子图压缩,写作 。其次,考虑如何采样合适的子图。设为图的集合,为他的幂集。此时,选择策略表示为:。在这个工作中作者考虑了4中节点选择策略,包括点删除,边删除,两种中心网络(EGO&EGO+)。注意这里的点删除指的是单纯移除这个点上的所有边,因此图大小仍旧保持为n。EGO指中心网络,以某一个点为中心,采样其周围的k-hop,而变种EGO+则会将中心节点链接特殊标识。采样子图的个数也是有讲究的。在训练过程中每一轮会从子图集合中选择一个小的子图集合,写作,在实验中,采样个数是一个超参,作者建议为
402 Payment Required
。Analysis
这里只选取少量的分析结果。首先作者认为这个框架是高效的,因此少不了复杂度分析: 指最大节点度数,如果是稀疏图的话这个值就会很低,因此其他方法在稀疏图上可能不能占便宜。如果实现定义了节点选择策略,那么。这个时候就和GSN一样了。但是GSN需要额外的预处理操作,而本文的方法不需要,因此从这个层面上来说,本文的方法还是很高效的。
指最大节点度数,如果是稀疏图的话这个值就会很低,因此其他方法在稀疏图上可能不能占便宜。如果实现定义了节点选择策略,那么。这个时候就和GSN一样了。但是GSN需要额外的预处理操作,而本文的方法不需要,因此从这个层面上来说,本文的方法还是很高效的。
另外作者分析了网络对强正则图(Strongly regular graph,SR graph)的功效。如果采用点删除或者EGO+的策略,模型是可以区分带不同参数的强正则图。而如果是边删除的方法,则可以达到区分带相同参数的强正则图的目的。
Experiment
实验部分是做了相当多的东西的。主要实验如图所示: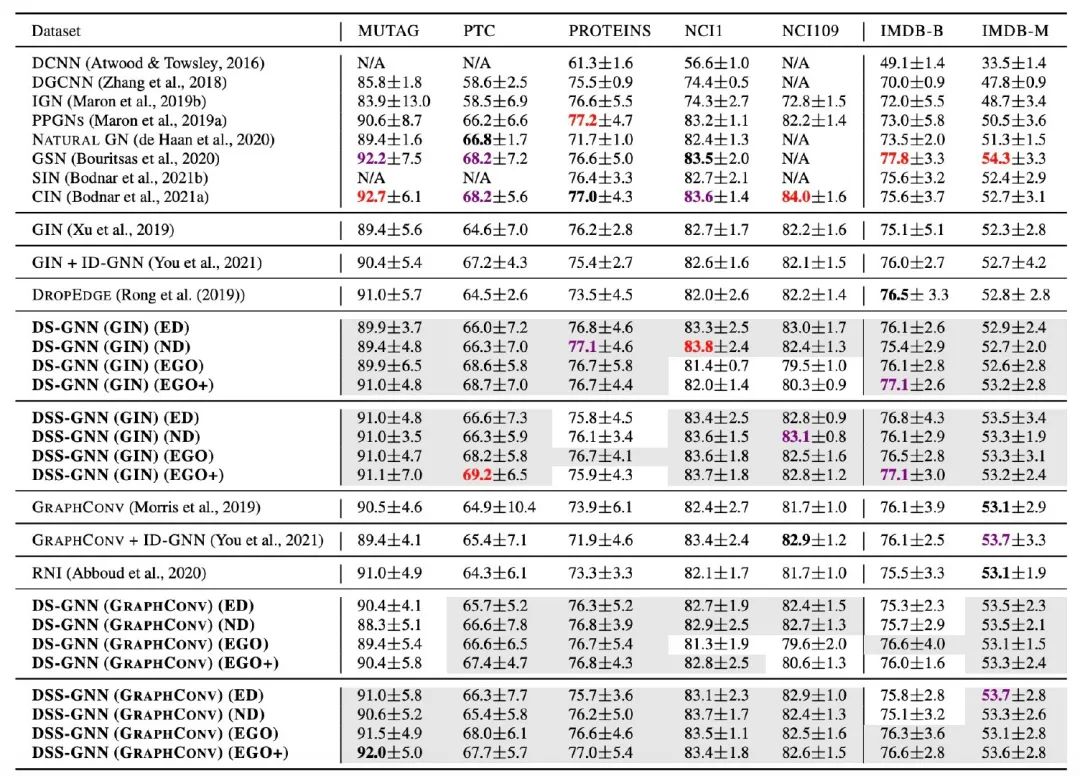
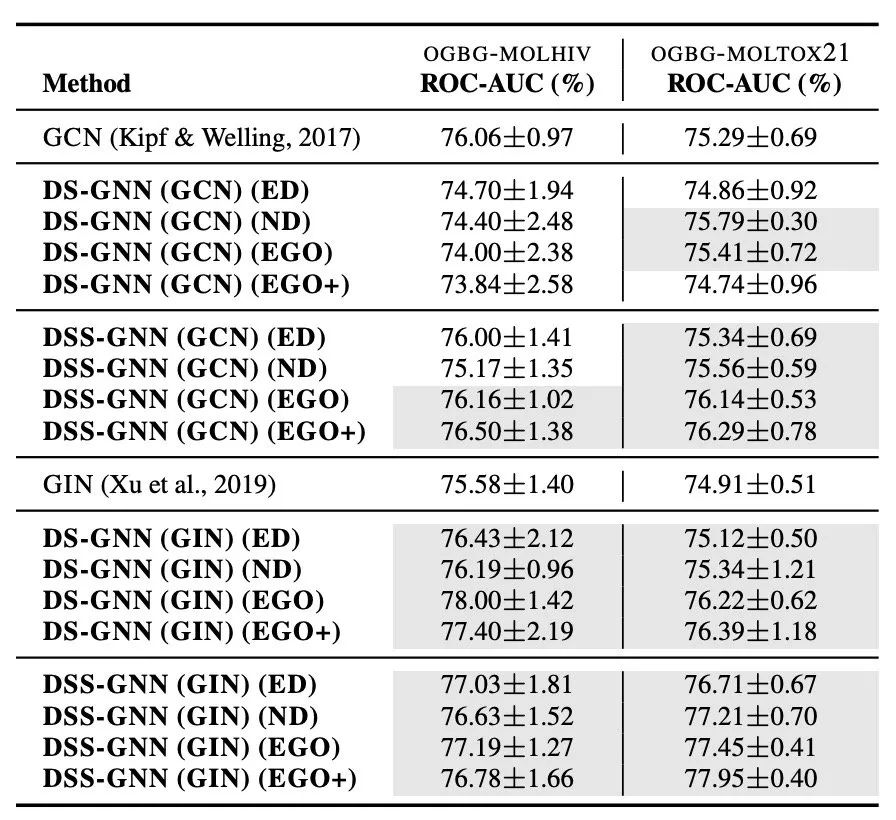 灰色格子标识作者使用了这套框架以后,模型能在原有基础框架上改进有所提高效果。红色表示最好的结果,紫色表示次好,黑色表示第三好的结果。另外,之前有说道每一次epoch去多少个子图,这个在附录里作者也有分析。实际上对于不同的数据集子图采样的个数是没有一个规律可循的。RDT-B这个数据集似乎太大了,作者就放过了几个实验指标。
灰色格子标识作者使用了这套框架以后,模型能在原有基础框架上改进有所提高效果。红色表示最好的结果,紫色表示次好,黑色表示第三好的结果。另外,之前有说道每一次epoch去多少个子图,这个在附录里作者也有分析。实际上对于不同的数据集子图采样的个数是没有一个规律可循的。RDT-B这个数据集似乎太大了,作者就放过了几个实验指标。 还有一个比较了当模型达到最优的结果时,模型用了多少的参数量:
还有一个比较了当模型达到最优的结果时,模型用了多少的参数量: 比较有意思的是PTC和IMDB两个数据集反而会用更少的参数,因此,ESAN这种结构实际上并不是单纯的引入参数量,把结果硬生生拉上去的。(实验真的太多了,有需要的可以自行阅读,震撼.jpg)
比较有意思的是PTC和IMDB两个数据集反而会用更少的参数,因此,ESAN这种结构实际上并不是单纯的引入参数量,把结果硬生生拉上去的。(实验真的太多了,有需要的可以自行阅读,震撼.jpg)
Conclusion
虽然文章展示了模型在图分类任务上取得了良好效果,但是作者仍然说明了一些欠缺的问题。比如,这个方法解决问题的主要思路还是增加了标准消息传递机制的计算复杂度。因此,在后续的工作中,作者提出了几点可以继续深入的方向:1)更好的子图选择策略,用来提高分类准确率;2)更高阶的子图表征方法,使得结构信息能更完善地被捕捉;3)对网络更理论的分析,尤其是不同子图选择方法和聚合函数的分析。















 1984
1984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









