




来源:Cornell University Computational Optimization Open Textbook:SLP
目录
4.应用
1.介绍
Sequential linear programming (SLP)序列线性规划也叫successive linear programming,是一个用于解决非线性规划问题non-linear programming (NLP)的数学规划方法。SLP能通过泰勒级数展开将NLP转化为一系列线性规划问题linear programming(LP),LP可以通过单纯形法或求解器求得解。SLP 最早被称为近似规划法approximation programming,由Shell Oil Company的 R. Griffith 和 R. Stewart 于 1961 年开发。SLP可以在不使用通常昂贵的 NLP 求解器且不使用高阶信息的情况下解决 NLP 问题。SLP不一定是最快的NLP求解算法,在 1994 年的 79 个设计问题的集合中,它的性能与带移动渐近线moving asymptotes的凸近似方法convex approximation差不多,比 CONLIN (一个基于凸近似的对偶优化器)差。但它只需使用LP求解器,从成本效益来看更优越,因此至今仍在使用。
2.理论和方法
2.1 问题形式
2.1.1 NLP问题形式
一个通用的NLP问题形式如下,是决策变量,f(x)是目标函数,要求最小化,g(x)和h(x)为约束,x取值有上下界。
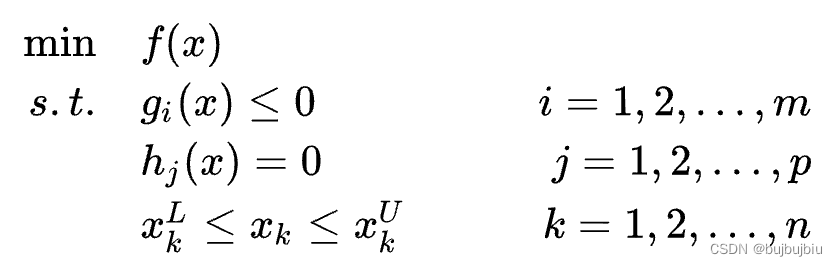
2.1.2 SLP问题形式
将NLP问题中的所有约束和目标函数用在点处的一阶泰勒展开式代替,转换成SLP问题。这要求 NLP 问题中的函数必须是可微的,SLP 算法才能工作。求解SLP问题获得一个新解
,这个新解可能是 NLP 的不可行解,但是不可行的程度会随着迭代次数的增加而降低。
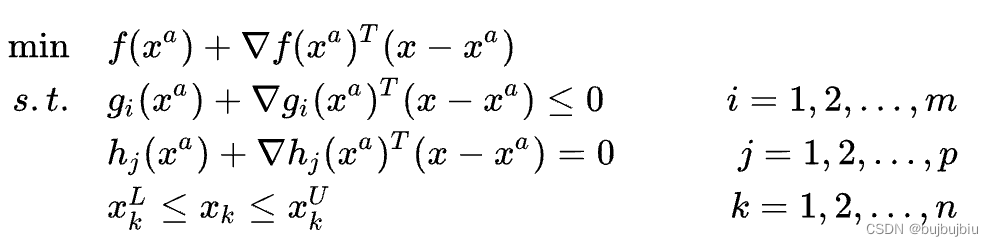
如果NLP的最优解是可行域的一个顶点,那么SLP就会收敛。但是通常情况下不能保证 SLP 会收敛,因为它没有考虑超基本变量superbasic variables,因此在具有许多超基本变量的问题或最优解不在顶点的问题上表现不佳。
超基本变量(superbasic variables)是线性规划中的一个概念,用于描述最优解中的变量状态。在线性规划问题最优解中,有些变量取值是非零的,被称为基本变量(basic variables),而另一些变量的取值为零,则被称为非基本变量(nonbasic variables)。超
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









