







在之前的文章中关于策略涉及内容较多,有基于iv、随机森林筛选策略规则,有xgb挖掘规则的,今天手把手教大家如何用python实现决策树的策略规则挖掘的。
一.项目案例
策略规则的制定与实际业务是分不开的,通常规则策略是使用一系列的逻辑判断将客户进行区分,使得每个区间中的客户风险有显著性的差异。如:用户的银行征信分数低,则认为风险过高,不予通过;否则认为用户在这一维度上的风险较低,进入下一条规则。
树模型比通常的规则引擎更加灵活,它可以结合多个维度的数据对客户进行区分,比如本文介绍的决策树模型,在二分类的任务下,决策树模型输出的结果更加通俗易懂,并且可以快速的在实际业务中得到应用。接下来通过案例来说明决策树模型在实际中的应用。
某金融公司的借贷业务分为信用类和抵押类,最近抵押类业务受到市场环境及疫情影响,逾期2期及以上客户比例正在逐步上升,现已高达12.5%,现在公司急需制定一条简单的策略规则,将逾期率指标快速的降低至可控范围内。
本案例中采用决策树回归算法,根据现有的客户数据,通过分析贷款金额(amount)和贷款期限(years)的数据,在公司现有的策略规则下,添加如下拒绝规则可以降低逾期率:
1.拒绝贷款金额高于6126.5元的客户,可以将逾期率降低至10.2%。
2.拒绝贷款金额高于6126.5元以及贷款期限高于29个月的客户,可以将逾期率降低至9.2%。
二.数据
2.1.数据展示
案例数据,数据总量为800条,其中逾期客户有100条,占比12.5%;未逾期客户700条,占比87.5%;
字段说明:
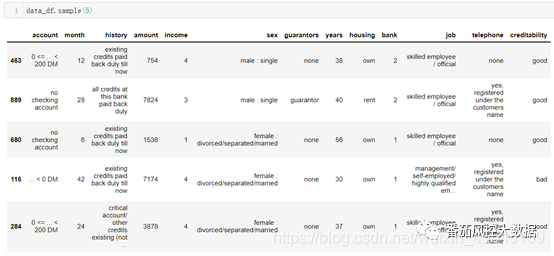
数据预览:
2.2.描述性统计分析
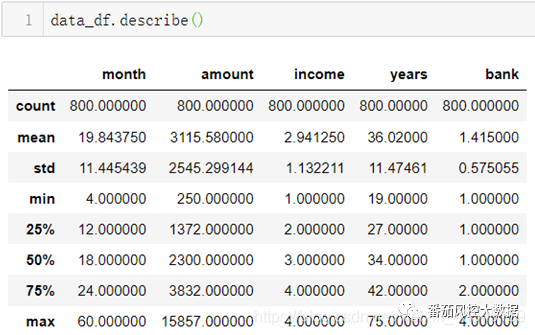
从上图中可以看到:该公司的金融产品,贷款期限(month)均值为19个月,贷款金额(amount)均值为3115.58元,客户的平均年龄(years)为36岁。
2.3.定义Y标签
数据中的creditability字段内容为:bad和good,决策树算法接受的是数值型数据,需要将creditability字段中的bad转为1,good转为0。代码如下:

三.决策树算法
3.1.概念
常见的决策树算法有ID3,C4.5,CART分类树,CART回归树等,每种算法都有不同的适用场景,这里使用CART回归树算法进行规则的挖掘。简单的介绍一下CART算法。
CART(Classification And Regression Tree)采用的核心概念是GINI系数。计算方法,如下图:

GINI系数反映的是某个特征的“纯度”,GINI系数越小,说明特征对数据划分越明显。比如:当婚姻数据中,未婚的客户全部为逾期客户,那未婚特征的GINI系数为0。只需要用婚姻数据就可以将客户很好的区分开来。
3.2.计算步骤
针对不同类型的数据,CART有着不同的计算逻辑:
数值型数据,比如:收入
1.对数据去重,并按照升序进行排列,将相邻的两个数据取算数平均值。比如:10,20,30,40,等等。
2.将10,20,30作为划分区间的界限计算GINI系数。计算小于10,小于20,小于30,小于40,等等对应的GINI系数。
3.找出最小GINI系数,将该均值作为新的数据放到原始数据中。继续第1,2步,直到符合结束条件。最小为小于20的GINI系数,将20放回源数据中,重复第1,2步。
4.结束条件:计算出的最小GINI系数小于指定的阈值,决策树的深度大于指定的深度。
分类型数据,比如:婚姻状况
1.对于分类型数据,该特征已经划分完成,不需要在额外划分数据。婚姻状况分为未婚,已婚,离婚,其他。
2.计算所有组合的GINI系数。
3.找出最小的GINI系数,将这几类数据合并为一个新的类,继续第1,2步,直到符合结束条件。
4.结束条件:计算出的最小GINI系数小于指定的阈值,决策树的深度大于指定的深度。
四.规则挖掘
4.1.代码
调用sklearn中的决策树回归模型,设定树的最大深度为2层。将amount(贷款金额)、month(贷款期限)作为x,将creditability(客户信誉)作为y标签。使用graphviz对输出结果进行可视化展示。源代码如下:

4.2.可视化结果分析
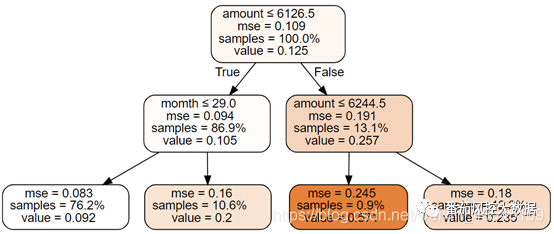
字段解释:
Mse:均方误差,均方误差越小,模型效果越好
Samples:样本占总体比例
Value:标签为1的数据占该分类的比例
根据决策树分析结果,做出如下规则:
1.如果拒绝amount大于6126.5的客户,可以使负样本占比下降至0.105(value值从0.125降到0.105),拒绝该部分的客户占整个数据集为13.1%,所以未来可能会损失13.1%的客户。
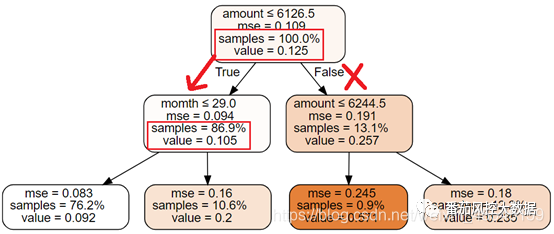
2.如果拒绝amount小于等于6126.5以及month>29客户,可以使整体的负样本占比下降至0.092(value值从0.125降到0.092),拒绝该部分的客户占整个数据集为23.8%,所以未来可能会损失23.8%的客户。
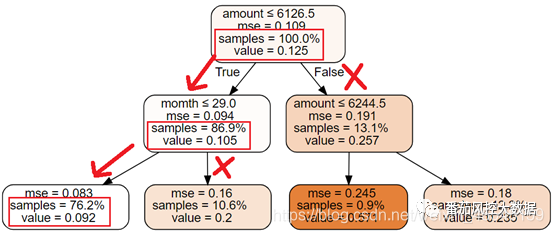
综上分析,该公司可选用上述的两条策略规则降低逾期率。
五.结论
通综合分析,我们发现最终挖掘的拒绝规则的业务原因有以下方面:
受市场环境及疫情影响,贷款金额较高的抵押类客户,会出现抵押物套现的风险,导致逾期率上升。另一方面,对于贷款期限较长的客户,由于疫情影响,资金周转会出现问题,也会导致逾期率上升。所以,对于这类用户,应该严加管控,根据现有数据,结合决策树算法结果,在策略中加入上述规则,可以降低逾期率。
但拒绝大额借款及长期限客户,意味着公司将获得较低的利润,所以还需结合定价、利润等业务指标结合进行综合分析,从而得出最优的策略规则。
关于本文中所涉及到的数据集跟代码目前已经上传至番茄风控大数据,各位数据分析、模型、策略的小伙伴们,如果要跟着本文中的步骤实操演练,欢迎移步到番茄风控下载学习!
~原创文章
…
end














 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









