







在番茄知识星球前边的系列文章中,曾给大家写过一篇关于数据降维PCA方法的应用与实现,可以在建模样本字段数量较多的情形下,有效解决特征维度较低的问题,从而提升模型的训练效率与性能效果。因此,特征降维的方法在数据建模过程中应用较为广泛,本质上可以优化建模特征变量池的结构。但是,在实际场景中,针对样本特征从多维到低维的过渡,我们常用的并非只有PCA(主成分分析),其实效果较好的还有另外一种方法,那就是线性判别分析LDA。本文将为大家具体介绍下数据降维LDA的原理逻辑与实现方法,并结合实际场景描述下LDA实现的综合效果。
1、LDA算法原理
LDA(linear discriminant analysis):线性判别分析,是一种常用的特征数据降维方法,应用目的是在保持目标分类的前提条件下,将特征数据投影至低维空间,以较大程度减少数据计算的复杂度。LDA是通过线性变换的原理思想,对样本数据实现降维的过程,这和PCA(主成分分析)的数据处理方向保持一致。但是,PCA是一种无监督的降维方法,不会考虑样本数据分类信息的模式,投影后方差最大的方向即为数据信息的主成分;而LDA是一种有监督的降维方法,会对样本数据进行模式分类,其中类指的是目标变量的取值分布,LDA要求样本数据类别之内的方差最小,而类别之间的方差最大,以保证投影后不同分类间的数据距离尽可能大。
LDA算法的数据降维流程主要把控以下几个步骤:
(1)输入降维前的数据集data,以及特征降维的维度数量n;
(2)算出类内散度矩阵Si与类间散度So,得到矩阵Si-1So;
(3)算出Si-1So最大的n个特征值和对应n个特征向量,得到投影矩阵W;
(4)对数据集每一个特征xi,转换为新的特征WTxi,得到降维后数据data*。
2、LDA与PCA对比
LDA(线性判别分析)与PCA(主成分分析)作为样本数据特征降维最经典的两种算法,在场景应用目标上是完全一致的,也就是将特征变量从高维向低维的转换,在功能实现方面自然有很多相似之处,但由于二者的核心算法思想不同,在具体数据处理方面仍然有较明显的差异,下面我们针对特征降维过程,简单描述下LDA与PCA的相同点与差异点。
(1)LDA与PCA的相同点:都可以实现对特征数据的降维处理;算法原理均假设样本数据符合高斯分布;降维过程均使用了矩阵特征分解的思想。
(2)LDA与PCA的差异点:LDA是有监督降维方法,而PCA是无监督降维方法;LDA降维最多降到目标类别数k-1的维度数,而PCA无限制;LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向;LDA不仅可以用于降维,还可以实现分类,而PCA仅能实现降维。
以上便是LDA与PCA的主要区别,在实际应用过程中,需要结合样本数据情况与场景具体需求,例如数据是否目标变量、特征维度数量是否有约束等。
3、LDA实现方法
在python环境,可以通过调用sklearn库LinearDiscriminantAnalysis()函数实现LDA,具体如图1所示,这里简要介绍下其中部分重要参数的设置与功能。

图1 LDA降维参数
图1 LDA降维参数
(1)solver: 算LDA超平面特征矩阵使用的方法,可供选择的方法包括奇异值分解“svd”、最小二乘”lsqr”、特征分解“eigen”,默认值“svd”;在实际应用中,当特征数量较多时建议使用“svd”,而特征数量较少时建议使用“eigen”;
(2)shrinkage:正则化参数,可以提升LDA分类的泛化能力,当采用LDA实现降维时,此参数无意义,默认值None,即不进行正则化;
(3)priors:类别权重,当LDA用于分类时可指定不同类别的权重,LDA实现降维时参数无意义;
(4)n_components:LDA降维时特征降到的维度数,取值范围为[1,类别数k-1]之间的整数,默认值None,当采用LDA实现分类时参数无意义;
(5)store_covariance:布尔值,默认值False,当取值为True时,需要额外算出每个类别的协方差矩阵;
(6)tol:浮点数,指定用于svd算法中判断迭代收敛状态的阈值。
4、LDA场景应用
通过上文介绍,我们大体熟悉了LDA的算法流程与应用特点,以及在具体的实现方法,为了说明LDA针对特征降维过程的输出效果,接下来我们围绕具体的实例数据,采用LDA来完成样本数据的特征降维。本文选取的样本数据包含5000条样本与16个特征字段,部分样例如图2所示,其中ID为样本主键,X01~X14为特征变量,取值类型为数值型;Y为目标变量,取值分别为0、1、2、3,具体分布如图3所示。
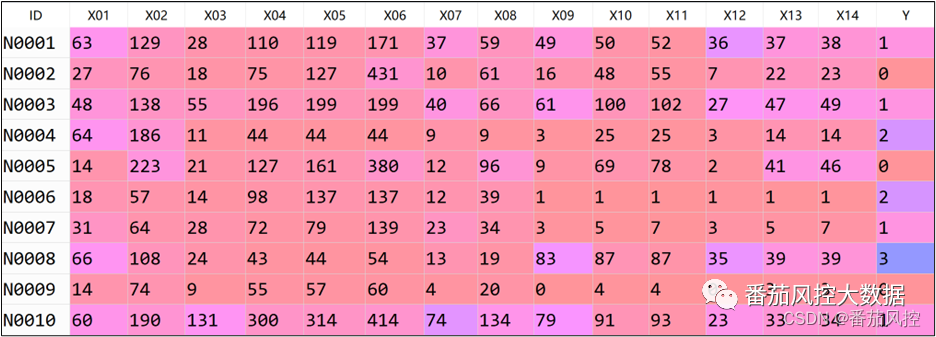
图2 样本数据
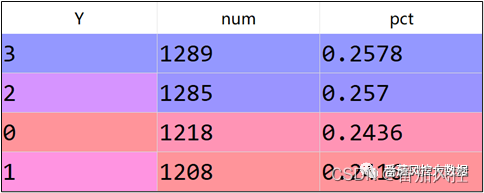
图3 目标分布
根据以上数据样例可知,样本包含目标变量Y,满足LDA特征降维的有监督前提条件。由于变量Y的取值类别数为4,则采用LDA实现的特征降维数量最多为3,具体特征降维过程如图4所示,输出的特征数据df_v3结果样例如图5所示。

图4 特征降维实现
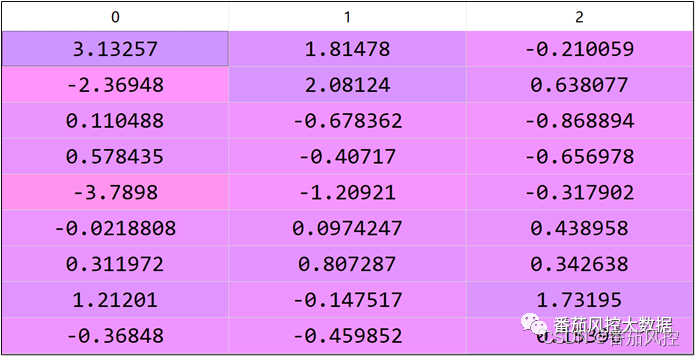
图5 特征降维数据
当获取了特征降维的数据之后,就可以根据建模具体需要,采用新特征字段对原有目标变量进行拟合,从而得到相关分类或回归模型。这里需要注意的是,我们在特征降维时,是将所有原始特征X01~X14作为输入,从而得到3个新的降维字段。在实际应用过程中,降维数据的输入特征可以是部分字段,可以结合原始特征变量的分布信息,选择部分性能较差的字段来实现特征降维,最终将新降维特征与原有部分性能较好的特征汇总,来进一步训练拟合模型,具体情况需要结合实际场景而定。
此外,从上图的特征降维数据结果看出,虽然新特征字段是由原始特征池衍生加工而来,但变量的具体含义无法与原始特征标签进行有效联系,这也是特征降维处理的一个特点,对于降维后的特征理解,是难以从实际业务角度进行解释的。但是,这里需要说明一个观点,我们采取LDA或PCA进行特征降维时,并不是为了得到业务解释性更强的特征变量,而是为了将原有较多特征的维度信息,缩小到较少特征维度的数据分布上,这对模型训练的拟合效果具有很好的促进作用,不仅减少了模型变量拟合的复杂度,而且提高了模型训练过程的迭代效率,同时在某种程度上也可以有效提升模型的区分度与稳定度。
因此,特征降维在模型开发任务的数据处理过程中,根据实际场景需要可以发挥出重要的价值,我们有必要掌握好采用LDA(线性判别分析)与PCA(主成分分析)来实现样本特征的数据降维,这也是数据分析或数据建模的能力的需要,为了便于大家对LDA特征降维处理的进一步熟悉与理解,本文额外附带了与以上内容同步的python代码与样本数据,供大家参考学习,详情请移至知识星球查看相关内容。
…
~原创文章















 2269
2269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









