






一、赛事介绍
- 主要内容:是一个面向多媒体深度伪造检测的竞赛,旨在检测不同类型的深度伪造内容,包括视频、图像、和音频。该比赛的目标是提高模型在多样化数据上的泛化能力和检测精度。
- holding时间:2024.06.17~2024.08.22
- 赛道:image track和multi-media track(本文主要基于多模态方向的track展开)
- 数据集构成:训练集、验证集与测试集
-
训练集与验证集的分布比较有规律,fake的数据集基本上是因为有阴影、脸部扭曲或者是嘴部变形(类似下图)

-
测试集的分布就比较阴间了(甚至出现动物,所以在决赛阶段都需要做增强并再训练)
-

-
二、如何区分Deepfake?
区分Deepfake内容与真实内容是一个挑战性的任务,但随着技术的发展,已经有一些方法可以用来检测Deepfake。以下是一些常见的检测Deepfake的方法:
- 视觉不一致性检查:
光线和阴影:检查视频中的光线和阴影是否自然,Deepfake内容可能在光线变化和阴影上存在不一致。
面部特征:观察面部特征是否在不同角度和表情下保持一致,Deepfake可能在某些角度下出现面部扭曲或异常。
眨眼和眼球运动:人类在说话时会自然眨眼和移动眼球,Deepfake可能无法准确模拟这些细节。 - 图像质量分析:
分辨率不一致:Deepfake视频可能在某些部分分辨率较低,尤其是当面部被合成到不同背景上时。
模糊和锐化:检查图像中是否有不自然的模糊或过度锐化的区域。 - 生物特征检测:
心跳和呼吸:通过分析视频中的心跳和呼吸模式,可以检测出与人类生理特征不符的情况。
面部微表情:人类的面部微表情很难被Deepfake技术完美复制,检测微表情的不自然可能揭示Deepfake。
一致性检查:
口型和声音:检查视频中人物的口型是否与声音匹配,Deepfake可能在这方面存在不一致。
身体动作:分析身体动作是否协调,Deepfake可能在模拟复杂的身体动作时出现不自然的情况。 - 深度学习检测工具:
专门的深度学习模型:已经有一些深度学习模型被训练来专门检测Deepfake内容,这些模型可以识别视频中的异常模式。
根据上述不同的识别模式,可以设计不同的模型
三、模型pipeline
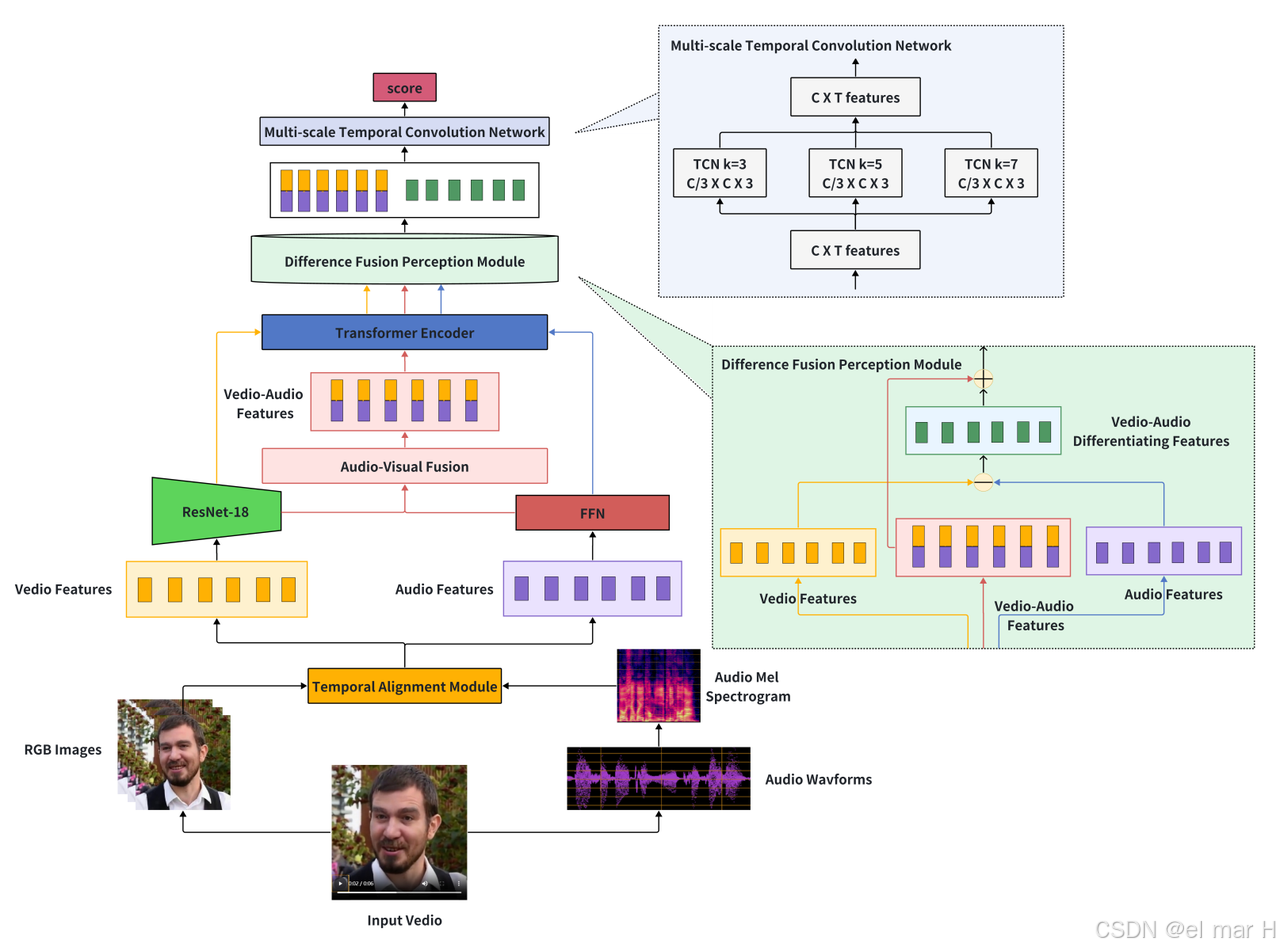
(一)、数据集处理
我们的模型处理视频、音频和图像数据,其中涉及对视频帧、音频片段及面部特征(嘴部区域)的提取与处理。以下是数据集处理流程的详细说明:
1. 数据集类:FakeAV
在代码中,我们实现了一个继承自torch.utils.data.Dataset的FakeAV类,用于加载和预处理数据。该类初始化时需要提供视频、图像、音频数据的路径以及样本的采样率。
class FakeAV(data.Dataset):
def __init__(self, video_path, images_path, wav_path, data_path, sample_rate, train=True, number_sample=1):
super(FakeAV, self).__init__()
...
2. 视频与图像预处理
- 视频帧通过
cv2读取,使用自定义的mouth_extractor对嘴部区域进行提取(最终的展示没有这个部分,但是实际上尝试过这种操作),并调整大小以确保一致性。 - 为了增强模型对不同数据尺度的鲁棒性,我们对图像应用了
GroupScale、GroupRandomHorizontalFlip等数据增强技术,并进行了标准化处理。
self.vision_transform = torchvision.transforms.Compose([
GroupScale(224),
GroupRandomHorizontalFlip(is_flow=False),
Stack(roll=(True)),
ToTorchFormatTensor(div=(True)),
GroupNormalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
3. 音频处理
- 音频数据使用
librosa加载,并通过AudioParser进行梅尔频谱图的转换。我们还实现了一个同步模块syncronize,确保视频和音频的时间序列对齐。
self.audio_transform = AudioParser(n_fft=512, feature='melspectrogram', sample_rate=self.sample_rate)
4. 时间同步
视频和音频帧需要根据帧数进行对齐,确保每一帧视频对应着合适的音频片段。我们通过计算音频每帧的时间跨度并与视频帧进行对齐,来实现音视频同步。
def syncronize(self, video, audio, mouth):
audio_seg_per_frame = audio.shape[-1] / len(video)
syncronize_indices = []
for i in range(len(video)):
s = int(np.floor(i * audio_seg_per_frame))
e = int(np.floor((i + 1) * audio_seg_per_frame))
e = e + 4 - (e - s) # 必须取4个索引
ind = np.arange(s, e)
assert len(ind) == 4, "错误"
syncronize_indices.append(ind)
syncronize_indices = np.array(syncronize_indices)
audio = audio[:, syncronize_indices]
return audio, video, mouth
5. 数据增强与填充
在训练过程中,视频和音频的长度可能不同。为了确保模型的输入一致性,我们对短的视频和音频进行填充,直到达到最大帧数。
if length < self.max_len:
video_pad = video[-1].unsqueeze(0).repeat(self.max_len - length, 1, 1, 1)
video = torch.cat((video, video_pad), dim=0)
audio_pad = audio[-1].unsqueeze(0).repeat(self.max_len - length, 1)
audio = torch.cat((audio, audio_pad), dim=0)
mouth_pad = mouth[-1].unsqueeze(0).repeat(self.max_len - length, 1, 1, 1)
mouth = torch.cat((mouth, mouth_pad), dim=0)
你的network.py代码展示了一个结合视觉、音频和嘴部特征的多模态深度学习网络结构,用于深度伪造检测或其他相关任务。让我们逐步解析代码并提供一些细节上的补充说明:
(二)、网络结构概览
- 视觉编码器(
self.vis_enc):使用了预训练的ResNet-18模型来提取视频帧的视觉特征。 - 音频编码器(
self.aud_enc):音频输入通过一个全连接前馈网络(FFN)进行处理,提取音频特征。 - Transformer(
self.transformer):用于融合视觉(视频)、嘴部(嘴部图像)和音频特征。它接受多个模态的特征,经过多层Transformer处理,输出综合的特征。 - 时序卷积网络(
self.tcn):该模块用于进一步处理由Transformer输出的时序特征,捕捉跨时间步的复杂依赖关系。
1. 细节解析
视觉编码器:ResNet-18
self.vis_enc = resnet18(inchannel=3)
weight = torch.load('pretrained_models/resnet18-f37072fd.pth', map_location=torch.device('cpu'))
self.vis_enc.load_state_dict(weight)
- ResNet-18:在这里,
resnet18是一个标准的ResNet-18模型,用于提取视频和嘴部图像的特征。你加载了一个预训练的ResNet模型权重,用于初始化网络。这样做可以加速训练过程,并且利用了在ImageNet等大规模数据集上训练好的视觉特征。
音频编码器:FFN(前馈神经网络)
self.aud_enc = FFN()
- 音频特征提取:音频特征通过一个前馈神经网络(FFN)进行提取。FFN通常包括多个全连接层和激活函数。这里没有采用复杂的卷积或循环结构,而是选择了一个简化的结构,可能是基于音频输入的特征较为简单。
多模态Transformer
self.transformer = AudioVisualTransformer(image_size=224, patch_size=0, num_classes=1, dim=512, depth=3, heads=4, mlp_dim=512, dim_head=128, dropout=0.1, emb_dropout=0.1, max_visual_len=300, max_mouth_len=300, max_audio_len=300)
- Transformer模型:Transformer在多模态学习中起到了重要作用,通过并行化的注意力机制处理不同模态的特征。
dim:表示嵌入维度(512),即每个输入的特征向量的维度。depth:表示Transformer的层数(3),即Transformer堆叠的深度。heads:注意力头的数量(4),即每个注意力层中并行注意力计算的数量。max_visual_len、max_mouth_len、max_audio_len:分别表示视频、嘴部和音频序列的最大长度,确保输入到Transformer中的序列长度统一。
多尺度时序卷积网络(TCN)
self.tcn = MultiscaleMultibranchTCN(
input_size=backend_out,
num_channels=[hidden_dim * len(tcn_options["kernel_size"]) * tcn_options["width_mult"]]* tcn_options["num_layers"],
num_classes=num_classes,
tcn_options=tcn_options,
dropout=tcn_options["dropout"],
relu_type=relu_type,
dwpw=tcn_options["dwpw"],
)
- TCN:时序卷积网络(Temporal Convolutional Network)在处理时序数据时非常有效,能够捕捉到长时间依赖性。在本模型中,它用于进一步对Transformer输出的多模态时序特征进行建模。
kernel_size:不同尺度的卷积核(3, 5, 7),用于提取不同时间尺度下的特征。num_layers:卷积层的数量(4层)。dropout:为了防止过拟合,使用了dropout层。
2. forward函数:模型的前向传播
def forward(self, video, mouth, audio, bs, length, train=True):
vid_emb = self.vis_enc(video) # 视觉特征
n, d = vid_emb.shape
vid_emb = vid_emb.reshape(-1, d, Config.max_len) # 适配最大长度
mouth_emb = self.vis_enc(mouth) # 嘴部特征
n, d = mouth_emb.shape
mouth_emb = mouth_emb.reshape(-1, d, Config.max_len) # 适配最大长度
aud_emb = self.aud_enc(audio) # 音频特征
b, t, d = aud_emb.shape
aud_emb = aud_emb.reshape(b, d, Config.max_len) # 适配最大长度
cls_emb = self.transformer(vid_emb, mouth_emb, aud_emb, length) # Transformer融合模态特征
cls_emb = self.tcn(cls_emb, bs, length) # TCN建模时序信息
return cls_emb
- 视觉和嘴部特征提取:通过ResNet-18对视频和嘴部图像进行编码,得到视觉特征。
- 音频特征提取:音频通过前馈神经网络(FFN)提取特征。
- Transformer融合:将视觉、嘴部和音频特征输入Transformer进行融合,得到跨模态的特征表示。
- TCN建模时序信息:最终,Transformer的输出进入TCN,进一步捕捉时序上的依赖关系,输出最终的分类结果
(三)、训练过程:
-
初始化模型:
model = network() model = model.to(torch.device(Config.device))- 创建
network模型实例并将其移动到指定的设备(例如GPU或CPU)。
- 创建
-
数据加载:
train_data = FakeAV(video_path=Config.video_path, images_path=Config.images_path, wav_path=Config.wav_path, data_path=Config.data_path, sample_rate=Config.sample_rate) train_loader = data.DataLoader(dataset=train_data, num_workers=Config.workers, batch_size=Config.batch_size, shuffle=True, pin_memory=True, persistent_workers=True) dev_data = FakeAV(video_path=Config.val_video_path, images_path=Config.val_images_path, wav_path=Config.val_wav_path, data_path=Config.val_data_path, sample_rate=Config.sample_rate) dev_loader = data.DataLoader(dataset=dev_data, num_workers=Config.workers, batch_size=Config.batch_size, shuffle=False, pin_memory=True, persistent_workers=True)- 加载训练集和验证集。通过
FakeAV数据集类加载视频、嘴部图像、音频和其他必要数据,配置DataLoader以便在训练和验证过程中按批次加载数据。
- 加载训练集和验证集。通过
-
损失函数和优化器:
criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=Config.lr)- 定义损失函数为
CrossEntropyLoss(适用于分类任务)。 - 定义优化器为
SGD(随机梯度下降),并设置学习率为Config.lr。
- 定义损失函数为
-
启动训练过程:
trainer(train_loader, dev_loader, model, optimizer, criterion)- 调用
trainer()函数开始训练。传入训练和验证数据加载器、模型、优化器和损失函数。
- 调用
四、模型的缺点:
1. 跨模态对齐过于简单
- 问题:模型虽然使用了视频、音频和嘴部图像作为输入,但它的跨模态对齐方式较为简单。具体而言,两个模态(视频和音频)都分别使用了独立的Transformer处理,缺乏深入的跨模态交互和对齐。
- 影响:这种方法假设视频和音频特征在处理时是独立的,而忽略了这两种模态在实际情况中的紧密关联。例如,视频中的嘴部动作和音频中的语音信号应该有非常强的对应关系。如果忽略这一点,可能会导致模型无法充分捕捉音视频之间的关联,从而影响模型的跨模态融合效果。
2. 缺乏跨模态注意力机制
- 问题:在当前模型架构中,视频和音频特征分别经过自己的Transformer处理(通过
AudioVisualTransformer处理视频和音频特征),但没有通过显式的跨模态注意力机制(cross-modal attention)来加强它们之间的联系。也就是说,模型并未直接学习音频和视频之间的交互信息。 - 影响:如果没有有效的跨模态注意力机制,视频和音频的特征处理可能无法相互影响,导致它们的融合较为表面,无法捕捉到音视频之间的细微联系。这对于深度伪造检测尤为重要,因为视频和音频中的伪造痕迹往往是高度相关的,缺乏跨模态交互可能会影响模型的检测精度。
3. Transformers 没有深度跨模态融合
- 问题:虽然使用了
AudioVisualTransformer来处理音频、嘴部和视频的特征,但是该Transformer仅限于从单一模态的自注意力机制中提取信息。没有明确的跨模态特征融合机制来鼓励模态间的信息共享。 - 影响:单一模态的Transformer处理方式虽然能够从每种模态中提取出有效特征,但缺乏对多模态信息的深入融合。这意味着,尽管每个模态都可以通过Transformer自我建模,但模型未能对多模态数据的联合特性进行有效的建模,从而影响多模态任务的性能。
4. 缺乏多模态学习中的信息互补性利用
- 问题:跨模态学习的一个重要优势是利用各模态间的信息互补性。例如,视频中的面部表情变化可能与音频中的语音波形或口型紧密相关。当前模型通过独立的Transformer处理视频和音频后,缺乏对这些模态间互补信息的有效整合。
- 影响:这种模型架构无法充分利用音视频特征之间的互补性,从而可能会限制模型在跨模态任务中的表现,尤其是在复杂的深度伪造检测任务中。
5. 可能的长时依赖捕捉不足
- 问题:虽然Transformer能够处理长时依赖,但由于缺乏跨模态的深度融合,它可能无法有效捕捉音视频特征之间的跨时长关联。
- 影响:深度伪造视频可能包含长时段的音频-视频不一致,尤其是在嘴部动作与音频内容不同步的情况下。若跨模态特征没有有效结合,Transformer捕捉到的时序特征可能无法准确对齐不同模态的信息。
改进建议:
- 跨模态注意力机制:可以在
AudioVisualTransformer中引入跨模态自注意力机制(cross-modal self-attention),使得音频和视频特征之间可以直接交互。通过这种方式,模型能够在处理音频或视频时,考虑到其他模态的影响。 - 联合训练与对齐模块:可以设计一个专门的跨模态对齐模块(如多模态对齐网络或对抗训练),专门处理模态间的对齐问题,进一步强化模态间的联系。
- 增强的Transformer架构:可以采用更复杂的Transformer架构,如多模态融合Transformer,或将视频和音频的模态信息通过共享的Transformer网络进行联合建模。
- 信息互补利用:通过设计信息融合机制(如共享表示层、互补特征融合等),加强音频和视频特征在深度伪造检测中的协同作用。
备注
这个比赛是博主七八月份在中邮消费金融有限公司实习的时候和同事一起做的,时间有点久了,公司的前辈们都超棒,性格很好而且富有学识!!

















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









