






CFATransUnet:用于二维医学图像分割的通道交叉融合关注和转换器
摘要
医学图像分割目前面临的挑战是如何有效地提取和融合远距离和局部语义信息,减轻或消除编码和解码过程中的语义间隙。为了缓解上述两个问题,我们提出了一种新的u型网络结构,称为CFATransUnet,以Transformer和CNN块为骨干网络,配备信道交叉融合注意和变压器(CCFAT)模块,其中包含信道交叉融合变压器(CCFT)和信道交叉融合注意(CCFA)。具体来说,我们使用Transformer和CNN块来构建编码器和解码器,以充分提取和融合远程和局部语义特征。CCFT模块利用自注意机制将不同阶段的语义信息重新整合到跨层的全局特征中,以减少不同层次特征之间的语义不对称。CCFA模块基于全局视角,以网络学习的方式自适应获取每个特征通道的重要性,增强有效的信息抓取,抑制非重要特征,以减轻语义差距。CCFT与CCFA的结合可以更有力地指导不同层次特征的有效融合,具有全局视角。编码器和解码器的一致架构也减轻了语义差距。实验结果表明,所提出的CFATransUnet在四个数据集上达到了最先进的性能。代码可在https://github.com/CPU0808066/CFATransUnet上获得。
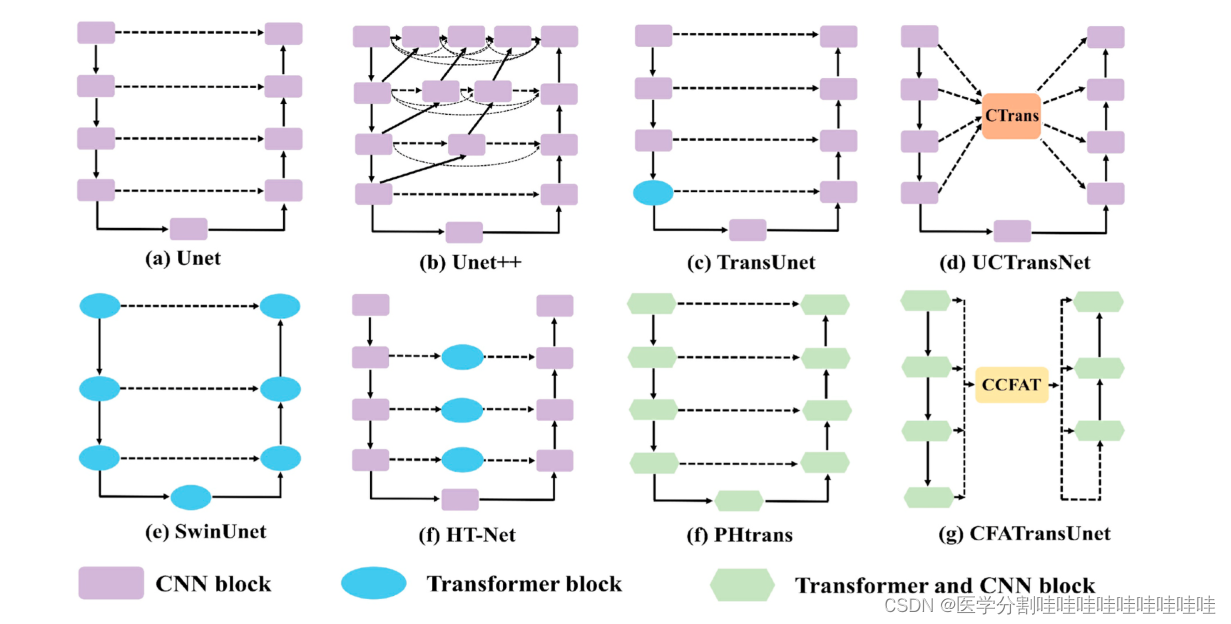
图1所示。常见u型网络结构。
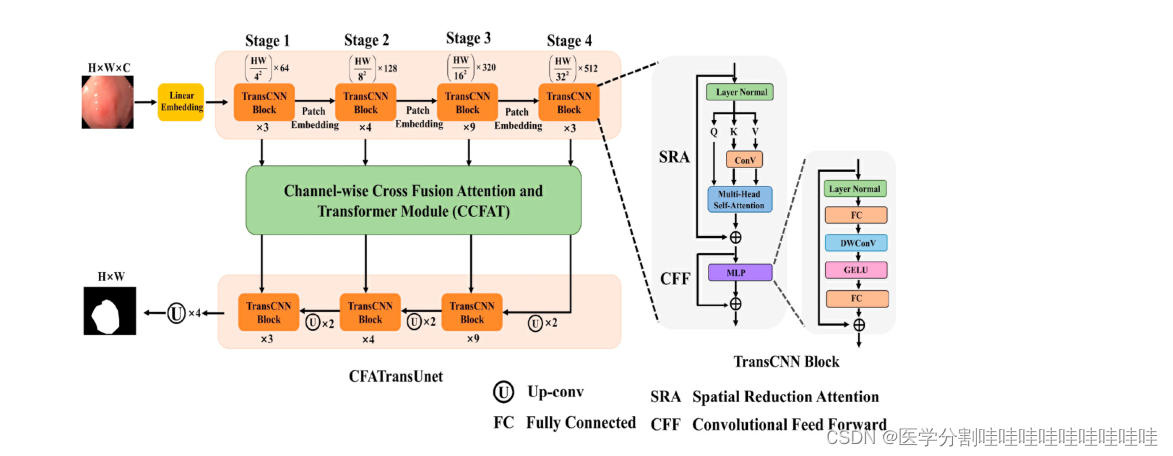
图2所示。拟议的CFATransUnet的说明。
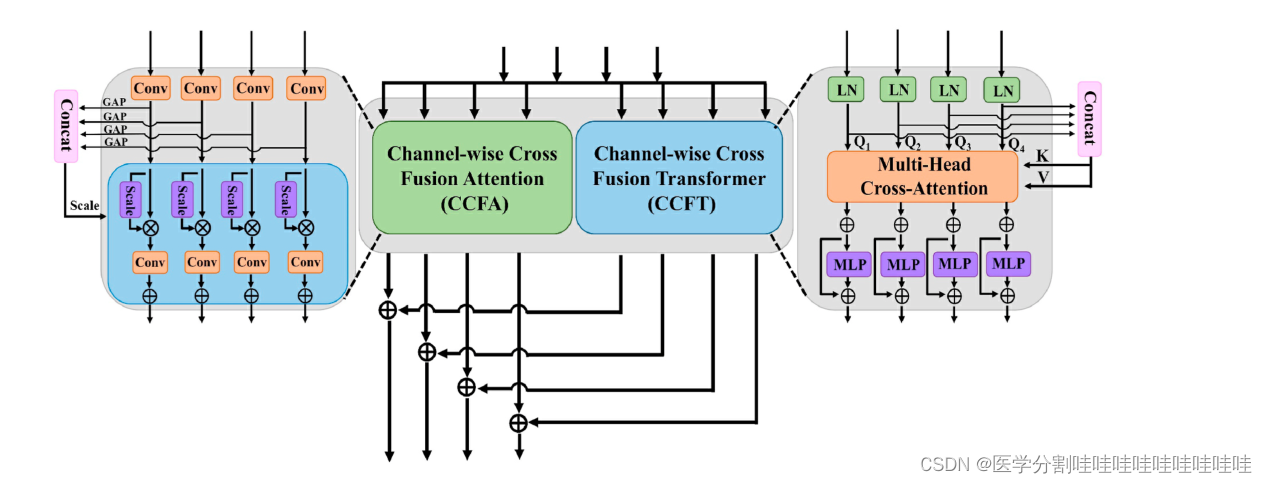
图3所示。信道交叉融合注意和变压器(CCFAT)模块的说明。
3 方法
3.1概述
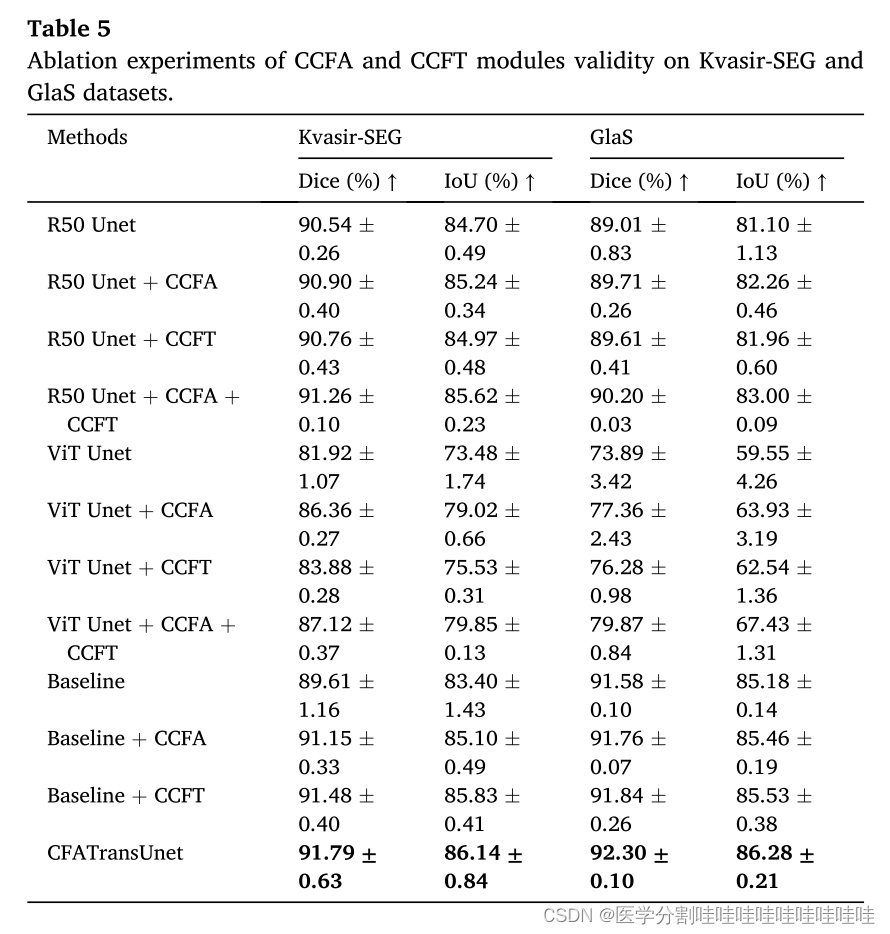
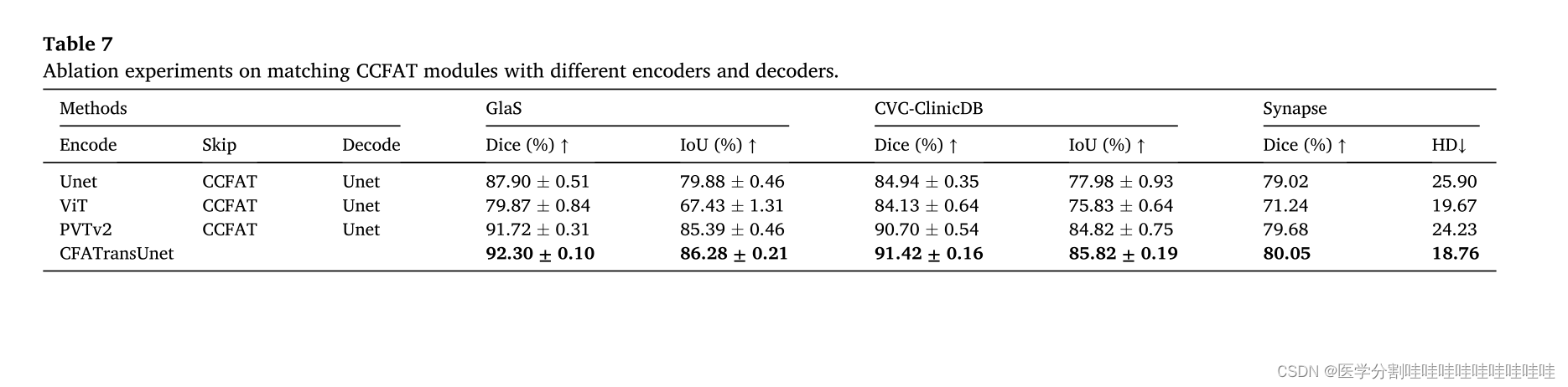
图2显示了提出的CFATransUnet的总体结构,这是一个基于编码和解码的U型网络架构。我们采用PVTv2的基本块[41]作为主干组件,并使用预训练参数。Channel-wise Cross Fusion Attention and Transformer (CCFAT)模块被用作跳过连接的替代方案,以消除多层次特征之间的语义差距。CCFAT模块包含CCFT和CCFA,它们共同引导多尺度特征自适应融合,捕获有效信息,抑制无关噪声。与UCTtansNet相比,本文提出的CFATransUnet有以下差异和改进[25]。(1)使用更强大的特征提取模块(TransCNN块)形成网络结构进行编解码。(2)提出了两种成分(CCFA和CCFT)来消除语义缺口不同的功能。(3)在CCFT前馈网络中,引入DWconV结构,进一步提取局部特征。此外,CFATransUnet只执行一次CCFT,因为我们发现多次执行CCFT不会带来明显的性能提升,反而会增加太多的计算开销。
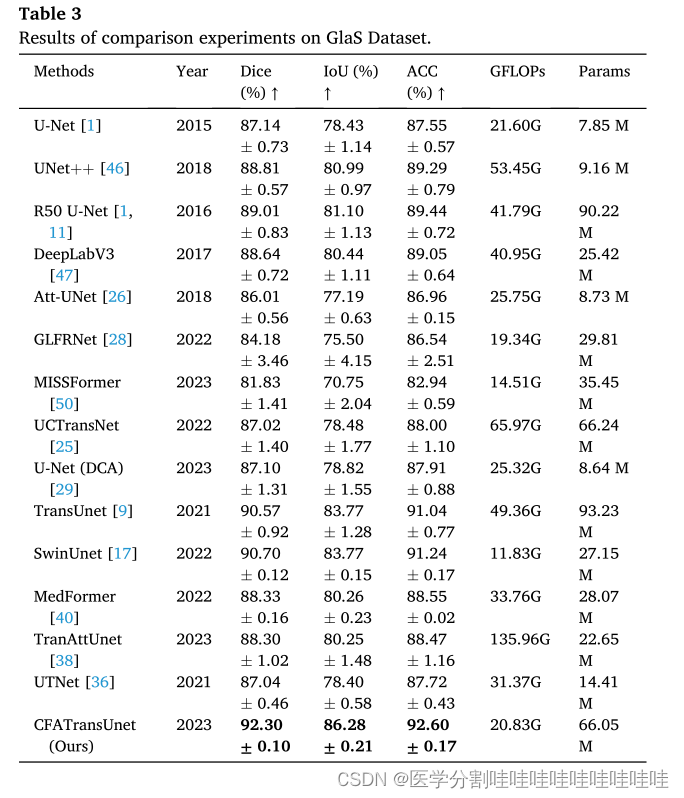
表1 Kvasir-SEG数据集对比实验结果。

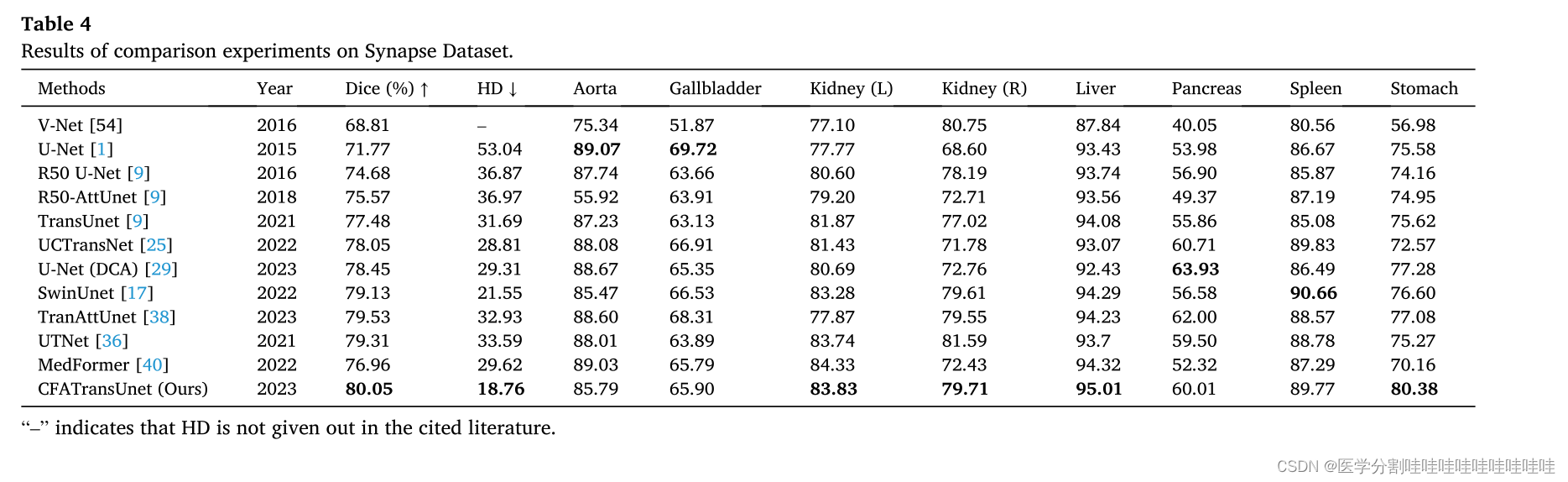
表2 CVC-ClinicDB数据集对比实验结果。

3.2 编码器-解码器
PVTv2中的基本单元[41]作为CFATransUnet编码器和解码器的组成部分,称为TransCNN块。ViT具有较高的计算复杂度,并且没有设计分层特征提取结构,限制了其在像素密集型任务中的应用[40]。PVT_v2采用低秩投影来减少大型特征映射的计算量,设计了分层特征提取结构,引入深度可分卷积来增强局部特征提取能力[22,41]。编码器分四个阶段提取层次特征。首先,将原始医学图像X0∈RC×H×W输入到网络中,经过线性嵌入层后变为Xl∈R(H4×W4)×Cl。经过编码器的四个阶段,输出的平面化特征图为Xi∈R (H 2i+ 1x W 2i+1) ×Ci(i = 1,2,3,4)。Xi表示平面化特征图,Ci表示通道数,H和W为空间分辨率。我们考虑了性能和模型大小,在PVT-v2-B3中只使用了部分预训练参数。每个编码器阶段重复的TransCNN块的数量分别为3、4、9和3。受Unet和SwinUnet的启发,我们保持了解码器和编码器的一致结构以及预训练参数,以减轻解码和编码之间的语义差距。对于通过TransCNN块的特征映射,主要遵循两个过程:(1)线性空间约简多头自注意;(2)卷积前馈网络。
3.2.1 线性空间还原多头自注意
首先将特征映射通过层法向层,然后进行线性映射得到Q、K、V,然后在进行头部注意力计算前对K、V进行卷积运算降低空间分辨率,减少了较高的计算成本。上述过程可表述如下:
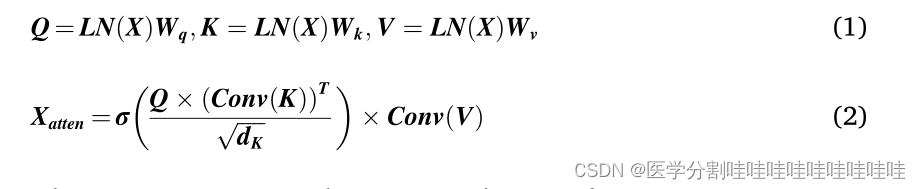
式中LN为Layer Normalization, X为输入特征映射,Wq, Wk, Wv∈RC×C为投影矩阵。Q、K、V分别为查询、键和值,σ(⋅)表示softmax函数,∑,∑,dk,√表示近似归一化,Xatten为线性空间约简后的多头部自关注特征映射。
卷积前馈网络。将深度卷积(DWconv)与多层感知器(MLP)相结合,构成卷积前馈网络。为了提高网络在不显著增加计算成本的情况下提取局部信息的能力,引入了DWconv。
3.3. CCFT:通道交叉融合transformer
如图所示,CCFT (Channel-wise Cross Fusion Transformer, CCFT)模块是CCFAT模块的组成部分之一,它分三步实现多级特征交叉融合。首先,将编码器不同阶段的扁平特征Xi∈R (H 2i+1× W 2i+1) ×Ci(i= 1,2,3,4)的空间分辨率缩减到相同大小,并通过线性化得到Q, K, V转换。然后,来自四个不同阶段的Ki和Vi分别连接并输入多头通道交叉注意(MHCCA)模块。MHCCA与原来的多头自注意(MHSA)的显著区别在于,自注意操作是沿着通道而不是空间维度进行的。最后,应用MLP块来提供非线性。MLP模块与上面描述的卷积前馈网络保持相同的结构,包括一个层归一化、两个线性变换、一个DWconv和一个GELU激活函数,这与UCTransNet不同。上述过程可表述如下:


其中嵌入是将不同大小的要素地图的空间分辨率降低到相同的大小,在本研究中,空间分辨率均匀降低7×7。WQ、WK、WV∈RC×C为投影矩阵。QI、KI和Vi分别是从不同的阶段特征获得的查询、关键字和值。K∑、V∑是KI、Vi连接不同阶段的结果。̅̅̅̅̅̅√CΣ表示近似归一化,Mi表示经过MHCCA后的结果。VΣT是VΣ的转置。
3.4. CCFA:渠道交叉融合关注
通道交叉融合注意(CCFA)模块是CCFAT的另一个模块,它从全局的角度自适应地学习不同阶段的通道特征的权重,使网络能够聚焦于感兴趣的区域,并抑制无关区域的影响,如图3所示。CCFA的输入与CCFT一样,是编码器不同阶段的特征图xi∈R(H2 i+1×W2 i+1)×Ci(i=1,2,3,4)。主要的计算过程分为三个步骤。首先,将不同阶段的特征送入卷积层,并将信道维度转换为相同的大小。在本研究中,转换后的通道数Ct为512。其次,通过平均拼层得到不同阶段的特征描述子Fi∈Rct×1×1(i=1,2,3,4)。将特征描述符Fi连接在一起,然后进行归一化操作,以获得全局特征描述符G。最后,将全局描述符乘以每个通道特征,然后使用卷积运算恢复通道数并将其连接到原始通道数作为残差输入。上述流程可按如下方式制定:

其中Conv是一个卷积运算。GAP表示全局平均池化。φ(⋅)为sigmoid函数。G表示全局特征表示。Ai是CCFA模块的输出。
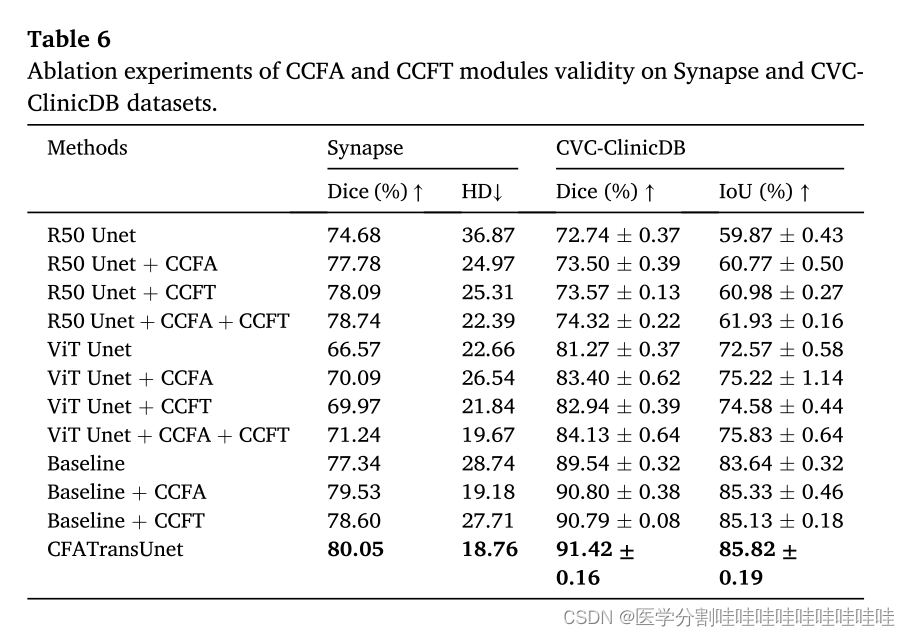
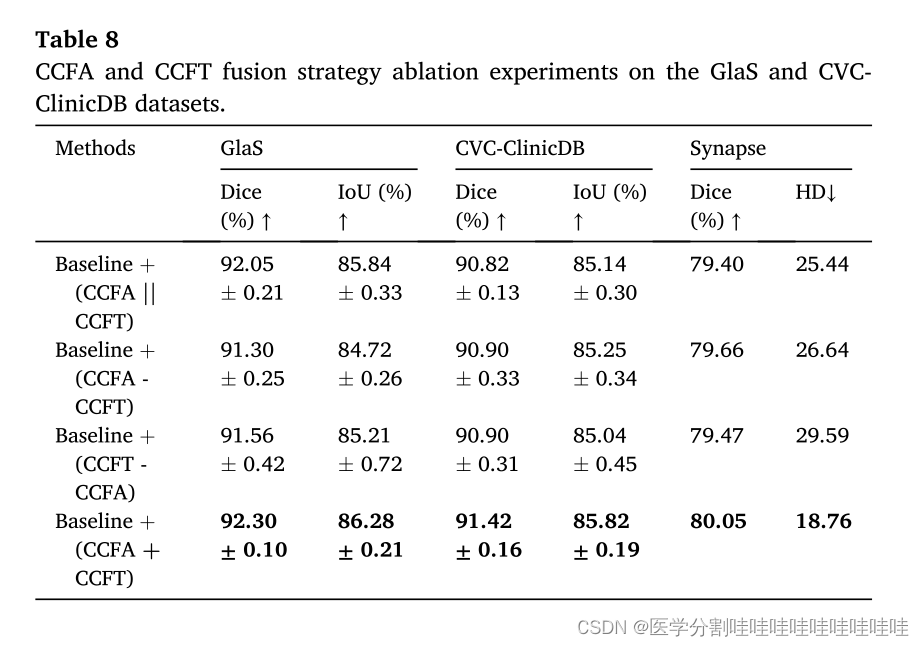
CCFA和CCFT的输出结果加在一起,并提供给解码器的相应级。















 6039
6039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









