






简要介绍
- 背景:联邦学习在边缘计算中大范围的使用
- 存在的问题:
1.数据不平衡,每个边缘结点存储的数据大小由500MB到50GB不等;
2.边缘动态性,户外的边缘结点很可能会由于网络状况不能工作;
3.资源限制,如更新模型频繁的数据传输需要带宽资源 - 方法:自适应异步联邦学习(AAFL)
与现有的算法不一样的是,他每次是选择一个或者多个随机模型来更新。服务器将仅从一小部分 (fraction)边缘节点按照它们在每个epoch的到达顺序聚合本地更新模型,并根据实时系统情况(如网络资源和状态)自适应地确定不同epoch的最佳 fraction values。AAFL 可以有效应对同步障碍问题,避免模型聚合的长时间等待。 - 主要贡献:
1.设计了一种自适应的异步联邦学习(AAFL)
2.提出一种基于深度强化学习的经验驱动的算法,能自适应的确定每个epoch的最佳 fraction value。实现更快的训练和更低的网络管理复杂性。
3.证明了提出的算法的高效性。(这也算贡献?)
该部分介绍了一般联邦学习的工作机制。提到的两种,同步和异步。
- 普通同步联邦学习:
每次是选择所有模型或特定数目的进行聚合。但由于边缘结点异构性导致训练时间差别太大,等待时间会有最长的训练时间决定。另外很难确定聚合泉河模型时的最佳模型模型个数。 - 普通异步联邦学习:
通过随机选择一个本地模型来更新,可以应对问题的第二点边缘动态性。虽然他不用等最久的模型训练时间,但他每个epoch只能聚合一个本地模型,会导致需要更多的epoch,更多的训练时间才能达到相同的效果。加上资源的限制,频繁的数据交只互会需要更大的带宽。
前言和问题的提出
联邦学习
该部分介绍了联邦学习的学习机制优点等
提到了三个经典的损失函数,文中只是简单的额提到,下面做出补充:
- 线性回归 z = w ∗ x + b z=w^*x+b z=w∗x+b,一般预测连续的值,损失函数用均方差表示 f i ( w ) = 1 2 ( x i T w − y i ) 2 f_i(w)=\frac{1}{2}\left(x_i^{\mathbb{T}}w-y_i\right)^2 fi(w)=21(xiTw−yi)2
- 逻辑回归
z
=
w
∗
x
+
b
z=w^*x+b
z=w∗x+b 和
y
=
1
1
+
e
−
z
y=\frac{1}{1+\mathrm{e}^{-z}}
y=1+e−z1,预测的变量y一般是离散的值。本质是将线性回归进行一个变换,该模型的输出变量范围始终在 0 和 1 之间。损失函数用对数似然表示
L ( w ) = ∏ [ p ( x i ) ] y i [ 1 − p ( x i ) ] 1 − y i L(w)=\prod[p(x_i)]^{y_i}[1-p(x_i)]^{1-y_i} L(w)=∏[p(xi)]yi[1−p(xi)]1−yi => J ( w ) = − 1 N l n L ( w ) J(w)=-\frac{1}{N}ln L(w) J(w)=−N1lnL(w) ,由于是求的最大似然函数 L ( w ) L(w) L(w)是期望最大,求的是梯度上升的,所以损失函数需要加负号 − 1 N -\frac{1}{N} −N1
详细文章 - 支持向量机 求解最大的软间隔
视频 和 详细文章
自适应异步联邦学习
主要介绍了聚合的机制
以Fig 2进行说明。并对于该机制存在的延迟,设计延迟补偿机制
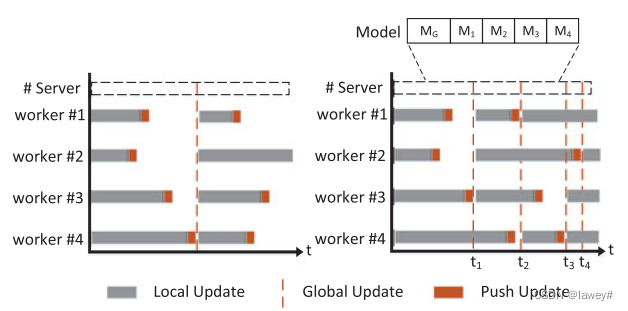
左侧为同步联邦学习,需全部的worker完成上传才会进行聚合
右侧为AAFL,每次会选择实时环境(包括资源、损失值)确定
α
\alpha
α,
α
t
∈
{
1
n
,
2
n
,
…
,
1
}
\alpha_t\in\{\frac{1}{n},\frac{2}{n},\ldots,1\}
αt∈{n1,n2,…,1},所以每次确定的模型数量则是
α
⋅
n
\alpha \cdot n
α⋅n
如图所示,在t1时刻,会对#1,#2,#3进行聚合,这样相比同步FL会更快一些。
但是会有一个问题,如t3-t4时刻#2此时上传的模型是根据第一次聚合的全局模型进行训练的,但此时全局模型已经是第三个版本了,这是对于#2机存在staleness过时,这里是3 - 1 = 2,为了加上最新模型的影响,PS对于收到的#2发来的M2还需要进一步的处理,具体来说是 M 2 = ζ x ⋅ M 2 + ( 1 − ζ x ) ⋅ M G M_2=\zeta^x\cdot M_2 + (1-\zeta^x)\cdot M_G M2=ζx⋅M2+(1−ζx)⋅MG,x代表#2的staleness
Fig 3:该图对比由于边缘动态性出现问题(网络失去连接、系统故障等)时,同步FL和AAFL的情况。认为AAFL即时有部分的worker出现故障,也能根据自身算法随机选择 α ⋅ n \alpha \cdot n α⋅n个模型进行全局模型的聚合
收敛性证明
该部分证明了一番。。。。
结论就是:1.收敛的边界与
α
\alpha
α和训练的epoch的个数
T
T
T有关。2.
α
\alpha
α和
T
T
T越大,最佳间隔Gap将会越小。
问题的提出
定义了具有资源约束的自适应异步联邦学习 (AAFL-RC) 问题,即在资源受限和会收敛保证的情况下,找到 α \alpha α和 T T T,来达到训练时间最短。
资源消耗分为两类。一类是本地更新带来的消耗 g k g_k gk,k表示资源的种类;一类是模型交换带来的消耗 b k b_k bk。
总的本地更新和模型交换消耗分别是: T ⋅ n ⋅ g k T\cdot n\cdot g_k T⋅n⋅gk、 ∑ t = 1 T ( α t + 1 ) ⋅ n ⋅ b k \sum_{t=1}^T(\alpha_t+1)\cdot n\cdot b_k ∑t=1T(αt+1)⋅n⋅bk。括号内需要 + 1 是因为PS每次会将全局模型发送给每个边缘节点,既接收全局模型的消耗。
-
问题的数学描述:
目的用最短的训练时间达到收敛。
不等式1,达到的收敛门限值
不等式2, B k B_k Bk是全部的消耗,即所有的资源使用不得超过 B k B_k Bk
不等式3,每个epoch需要在聚合时,需要至少 α ⋅ n \alpha \cdot n α⋅n个模型提交
不等式4,为1或者为0,表示模型i是否在轮次t中参加聚合
不等式5,确定的 α \alpha α取值 ,i/n -
问题的解决方案:
使用深度强化学习DRL。
然后提到一点是,根据第二个不等式发现 α \alpha α和 T T T是相关。先确定 α \alpha α,然后由此确定 T T T。
AAFL-RC的算法设计
深度强化学习智能体
以Fig. 4进行介绍
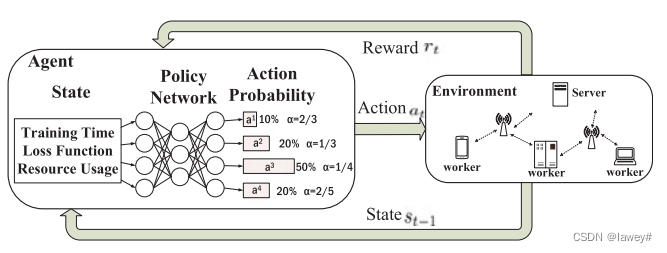
DRL系统由Agent和Env组成。Agent由状态,动作,奖励组成。
-
状态State: s t = ( t , H t , w t , F t , △ F t , F , b t , G t ) s_t = (t,H_t,w^t,F_t, \triangle F_t,\mathcal F,b_t,\mathcal G_t) st=(t,Ht,wt,Ft,△Ft,F,bt,Gt),各个分量分别代表,轮次、训练时间、模型参数、损失函数、 △ F t = F − F t \triangle F_t=\mathcal F-F_t △Ft=F−Ft、 F \mathcal F F收敛的程度、资源消耗、资源剩余
-
动作Action:如图所示,由神经网络输入state产生一组动作集合 π \pi π。对每种 α \alpha α有一个概率。 π ( a t ∣ s t ; θ ) → [ 0 , 1 ] \begin{aligned}\pi(a_t|s_t;\theta)& \to[0,1] \end{aligned} π(at∣st;θ)→[0,1], θ \theta θ是网络的参数。
-
奖励Reward:下面是动作后产生奖励的公式。其中注意的是,当 ∣ △ F t ∣ |\triangle F_t| ∣△Ft∣变小时,奖励会增大,但是根据公式会发现有问题,其实没有问题。因为 △ F t \triangle F_t △Ft是一个负值,是一个较大的数不断接近 F \mathcal F F的,可由第一点中 △ F \triangle F △F的计算公式知道。
r t = − Υ H t − H ‾ t − 1 H ‾ t − 1 + △ F t F − b t G t , t < T , r_t=-\Upsilon^{\frac{H_t-\overline{H}_{t-1}}{\overline{H}_{t-1}}}+\frac{\triangle F_t}{\mathcal{F}}-\frac{b_t}{\mathcal{G}_t},\quad t<T, rt=−ΥHt−1Ht−Ht−1+F△Ft−Gtbt,t<T,
关于一个epoch的最后一个奖励计算,要么是资源耗尽,要么时达到收敛门限:r T = { L T + C if F ( w T ) ≤ F and G T ≥ 0 , L T − C otherwise. r_T=\left\{\begin{array}{lr}\mathcal{L}_T+\mathcal{C}&\textrm{if}F(w^T)\le\mathcal{F}\textrm{ and }\mathcal{G}_T\ge0,\\ \mathcal{L}_T-\mathcal{C}&\textrm{otherwise.}\end{array}\right. rT={LT+CLT−CifF(wT)≤F and GT≥0,otherwise.
表示当最后一步不是正常结束,则会减去一个 C C C,让奖励减少,Agent知道好做出下一个决定。
如果当前动作的奖励与其他动作的奖励相比较大,则该动作在下一个 epoch 中被选中的概率会增加。否则会减少。然后文章在3.1提到了 R t = ∑ d = 0 T − t γ d r t + d R_t=\sum_{d=0}^{T-t}\gamma^dr_{t+d} Rt=∑d=0T−tγdrt+d奖励的计算。
在这个公式中,下标 t+d 表示从时期 t 开始的未来回报。这个公式计算了从时期 t 开始的总累积回报,其中每个未来时期的回报都乘以一个折扣因子。以下解释来自New Bing:
这意味着,随着时间的推移,每个时期的回报将乘以一个折扣因子,以便更多地关注近期回报。这是强化学习中常用的技术,用于平衡对即时回报和未来回报的关注。
实际上,未来的回报 rt 是未知的,因此无法直接计算 Rt。在强化学习中,通常使用一种称为时间差分学习(TD learning)的技术来估计 Rt。这种方法利用了马尔科夫决策过程(MDP)的性质,即未来时期的回报与当前时期的状态和动作有关。因此,可以使用当前时期和下一时期的信息来估计 Rt。















 8988
8988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











