







考虑带宽资源限制,自适应的调整每个训练周期中参与全局模型聚合的本地更新模型的比例 at
1. 论文信息
Adaptive Asynchronous Federated Learning in Resource-Constrained Edge Computing,IEEE Transactions on Mobile Computing
发表时间:2023-2-1,CCFA
2. introduction
2.1.1. 背景:
资源受限的边缘节点下的异步 FL
2.1.2. 挑战:
- 数据不平衡:边缘节点上的数据量在时间和空间上差异显著
- 边缘动态性:边缘节点可能受系统崩溃、断电、网络因素影响无法工作
- 资源约束:边缘节点与远程参数服务器之间的带宽受限,频繁发送和接收更新模型需要巨大的资源成本
2.1.3. 贡献点:
- 设计了一种用于边缘计算的自适应异步联邦学习(AAFL)机制,并证明了AAFL的收敛性。
- 提出了基于深度强化学习(DRL)的经验驱动算法,针对AAFL中单学习任务和多学习任务两种情况,自适应确定每个历元的最优 a (参加 Server 端全局聚合的模型更新数量的比例),实现更少的训练时间和带宽资源使用,降低网络管理复杂度。
- 在典型模型和数据集上进行大量实验,表明所提算法的有效性。具体来说,与最先进的解决方案相比,在资源有限的情况下,AAFL可以减少约70%的训练时间,提高约28%的训练精度
3. 问题描述:System model/架构/对问题的形式化描述
3.1. AAFL

AFL 不需要等待所有的本地模型更新到位就可以进行全局聚合
AAFL 与 AFL 相比 增加了自适应调节 全局模型聚合前需要的本地模型更新数 (at*n)
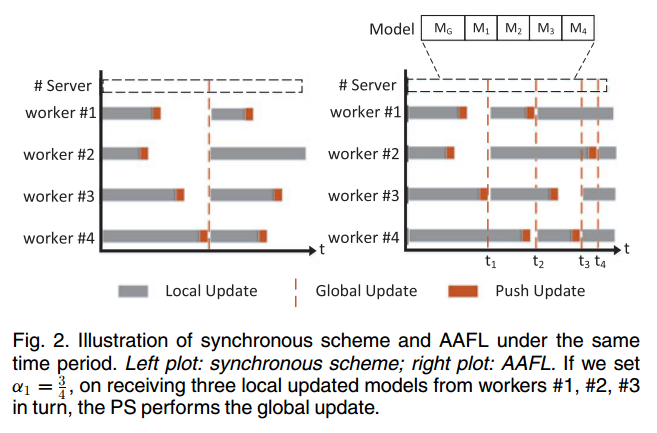
展示了相同时间下 同步 FL 和 AAFL 的训练过程。AAFL将比同步方案收敛得更快,具有更多的全局更新,能有效地利用资源。
![]()

展示了 AAFL 对边缘动态的处理
AAFL 收敛性证明结论:
- 收敛界 (即最优性间隙) 与 at 的值和 epoch 数 T 有关
- at 和 T 越大,越接近最优解,但随着 at 和 T 增大,本地更新数 和 训练的 epoch 数增多,需要更多的通信资源(本文中资源只考虑 带宽 ),但是资源有限,可能会违反资源约束
AAFL-RC (adaptive asynchronous federated learning with resource constraints )
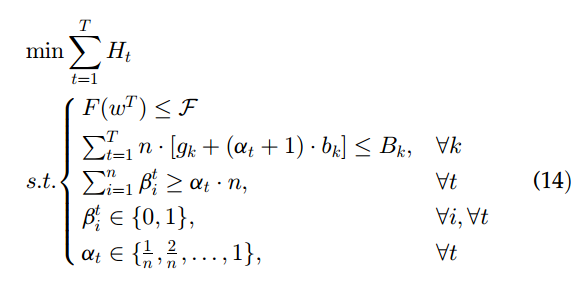
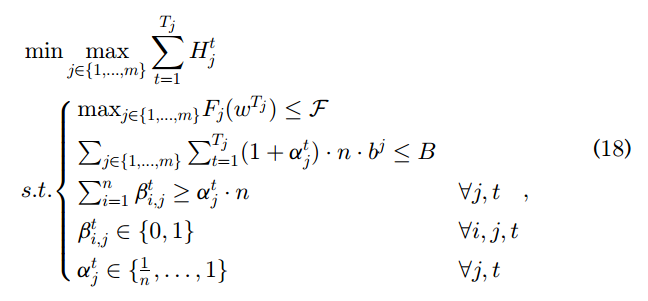
3.2. DRL
DRL 通过 Agent 与 Environment 的交互,实现最大化累积折扣奖励的期望值,自适应地确定联邦学习中每个训练周期参与全局模型聚合的本地更新模型的比例。
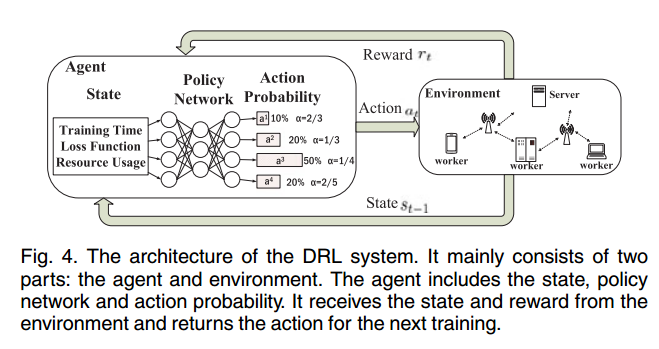
在每个 epoch 中,Agent 中的 Policy Network 接收状态 st-1 (例如,完成时间、损失函数和资源使用情况),根据策略 p 从 Action Probability 中选择一个动作 at 。和环境交互后,给出反馈 reward ,并修改 agent 的状态,直到实现最大化累积折扣奖励的期望值
4. 解决方法
执行流程:一般有伪代码

挑战问题怎么解决:使用 DRL 中的 A3C 算法训练,通过 agent 与 FL 环境的交互学习如何选择最优的本地更新模型聚合比例 at,实现在资源受限的情况下最小化模型训练的完成时间并保证模型的收敛性。
Actor Network 负责生成给定状态下的动作,而 Critic Network 负责评估当前策略下的状态或状态-动作对的价值
任务消耗的资源越多,agent 得到的奖励越少。
5. 效果:
5.1. 实验设置
当网络中有多个学习任务时,我们测量所有任务的最大损失和最小准确率来评估训练性能。
5.2. 对比实验(仿真实验)
5.2.1. Training the DRL Agent.
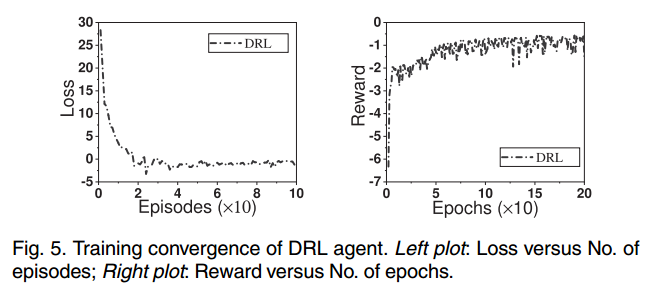
在强化学习中,一个episode是指 agent 与 environment 之间的一次完整交互,从episode开始到结束的整个过程。而一个 epoch 可以包含多个 episode
左图:在DRL训练过程的早期阶段,训练损失下降很快。这是因为DRL agent 没有FL环境的信息,损失值较大。由于 agent 的高效探索,可以在模型训练过程中迅速将损失最小化。在不到 20 episodes 之后,训练损失趋于稳定,这意味着DRL agent 学会了适应FL环境。
右图:在DRL训练集中,reward 随着epoch增加而增加,并逐渐趋于稳定。因为DRL模型能够学习更好的 policy 以获得更好的 reward 。
5.2.2. Single Learning Task
5.2.2.1. 第一组
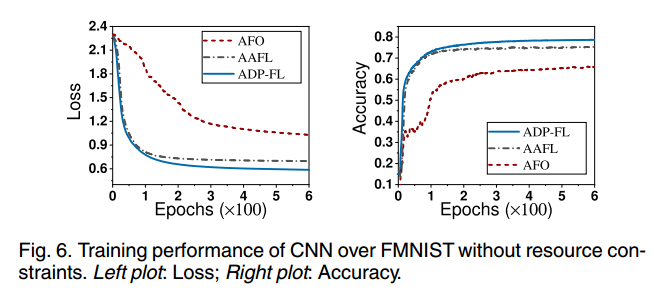
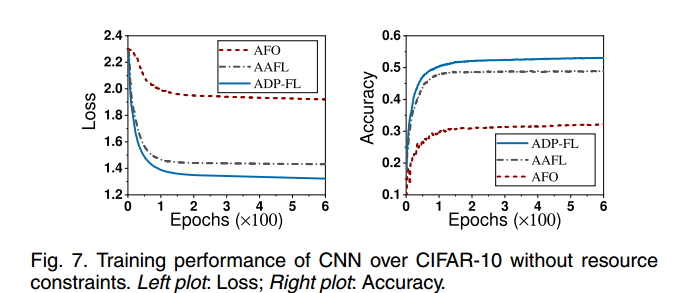
第一组模拟评估了在没有资源约束的情况下分类模型(例如CNN)的性能。我们训练了每组模型和数据集,包括CNN在FMNIST上和CNN在CIFAR-10上,对所有三种解决方案(即AFO, ADP-FL和AAFL)进行了600次epoch的训练。从图6和图7可以看出,AAFL与采用同步方案的ADPFL的训练性能相似。此外,随着训练次数的增加,AAFL的训练效果优于AFO。例如,当CNN训练在FMNIST数据集上运行600个epoch时,AAFL的准确率约为75%,而ADP-FL和AFO的准确率分别约为78%和65%。我们可以得出结论,与AFO相比,我们提出的AAFL框架可以将分类模型的准确率提高约10%
5.2.2.2. 第二组
具有资源约束的分类模型(例如CNN)的性能。
- 时间约束

在实践中,一些培训任务往往需要在规定的时间内完成。我们用有限的完成时间约束(例如1800年代)在FMNIST上训练CNN。由于同步障碍,每个epoch的完成时间主要取决于这些工人的最大培训时间,这将导致较长的完成时间。因此,ADPFL不能在给定的完成时间约束内实现收敛。由图8可知,在相同的时间约束下,AFO的平均训练次数是AAFL和ADP-FL的4倍。然而,AFO的训练性能(如损失或准确性)比AAFL差,AAFL的训练性能优于ADP-FL。例如,在固定的时间约束下,AAFL的损耗为0.74,而AFO和ADP-FL的最小损耗分别约为1.03和0.79。因此,AAFL、AFO和ADP-FL的准确率分别约为74%、65%和71%。因此,与AFO和ADP-FL相比,AAFL的准确率分别提高了9%和3%。
- 带宽约束
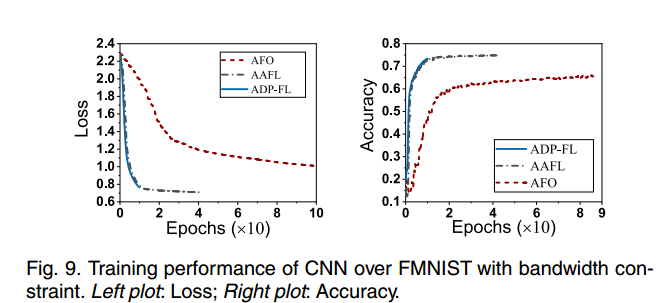
参数服务器和worker之间的通信会造成巨大的带宽消耗。我们在有限带宽约束(例如10Gb)下测量CNN在FMNIST上的训练性能。如图9所示,AAFL比AFO和ADPFL都能达到更高的精度。例如,使用AAFL的CNN在FMNIST上的准确率约为74%,而使用AFO和ADP-FL的准确率分别约为66%和72%。因此,与AFO和ADP-FL相比,所提出的AAFL框架可以分别提高约8%和2%的精度。
5.2.2.3. 第三组
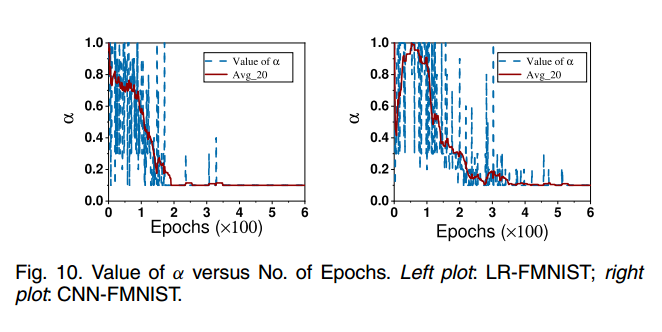
AAFL中a参数随 epoch 数的增加而变化。在AFO (a¼0:1)和ADP-FL (a¼1)中,a的值是固定的,AAFL 算法可以根据环境自适应调整a的值。在训练开始时,参数服务器会聚合更多的局部更新,从而加快模型的收敛速度。当模型趋于收敛时,全局模型聚合所需的局部更新较少,从而节省了大量的网络资源(如网络带宽)。在图10中,AAFL的a值随着训练次数的增加而减小,趋于稳定
5.2.2.4. 第四组
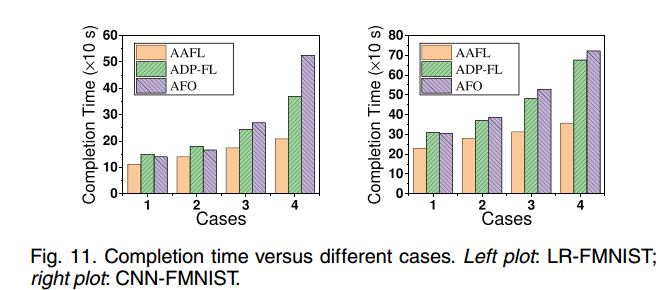
测试了三种解决方案在 worker 处具有不同数据分布的完成时间。worker 上的数据量总是动态变化的。在四种情况下,所有解决方案的完成时间都有所增加。然而,AAFL的增长速度比其他两个基准慢得多。相比之下,AAFL比AFO和ADP-FL所需的完成时间更短。例如,由图11的右图可知,AAFL的完成时间约为340秒,而ADP-FL和AFO分别需要690秒和750秒左右。换句话说,与ADP-FL和AFO相比,AAFL可以分别减少约51%和55%的完成时间。
5.2.2.5. 第五组
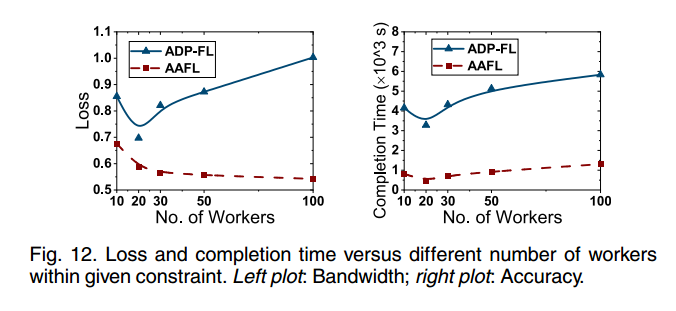
观察了在给定带宽预算(例如5Gb)下,不同数量的 worker 对训练性能的影响(CNN与FMNIST)。
采用五种不同数量的 worker (如10、20、30、50、100)来测试损失值和完成时间。从图12的测试结果可以看出,当人数超过20人时,两种方案的培训效果几乎没有提高,甚至更差。例如,在图12的左图中,我们在给定的带宽预算下测试了两种方案的损失值。在AAFL中,随着边缘计算中工作人员数量的增加,参数服务器将在每个epoch中聚合更多(不是全部)本地更新。因此,全局训练模型可以很好地实现收敛,损失值逐渐减小。然而,更多的 worker 也会带来更多的资源消耗和等待时间。ADP-FL会减少总训练次数,导致训练效果不佳。
此外,从图12右图的测试结果可以看出,当边缘节点数大于20时,AAFL和ADP-FL的完成时间逐渐增加。因此,选择20作为仿真中参与模型训练的 worker 数限制
5.2.3. Multiple Learning Tasks
5.2.3.1. 第六组
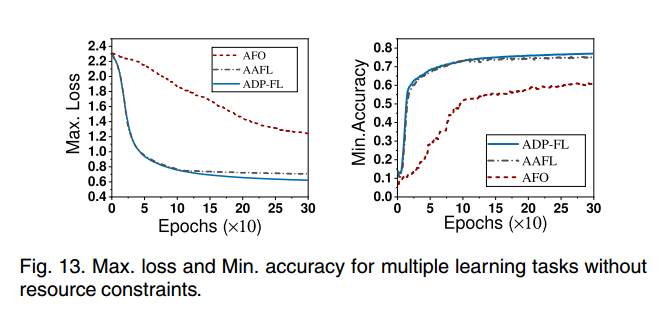
观察了在没有资源约束的情况下多个学习任务的性能。在三个不同的数据集上运行两个模型,分别包括LR在FMNIST上,CNN在FMNIST上和CIFAR-10上。每个学习任务执行300次epoch。图13显示了三种学习任务的最大损失和最小准确率。从这个图中可以看出,AAFL比ADP-FL的训练性能稍差(例如,损失或准确性),但优于AFO。例如,给定300个训练周期,AAFL的准确率约为75%,而AFO和ADP-FL的准确率分别约为61%和77%。
5.2.3.2. 第七组
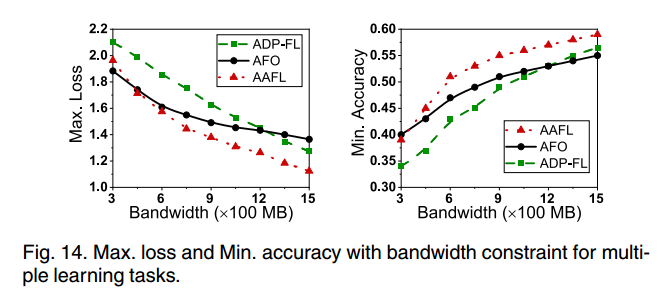
在有限带宽约束下测试了多个学习任务的性能。
在图14中,通过将三种解决方案的带宽约束从300 Mbps更改为1,500 Mbps,最大损耗变小,最小精度提高。
与其他两个基准相比,我们提出的AAFL框架可以实现更小的损耗和更高的精度。
例如,当带宽约束为900 Mbps时,AAFL的最小精度约为55%,而ADP-FL和AFO的最小精度分别约为49%和51%。换句话说,与ADP-FL和AFO相比,AAFL可以分别提高大约6%和4%的最小精度
5.2.3.3. 第八组
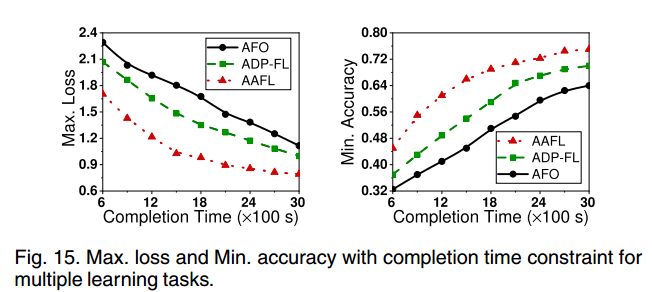
在有限完成时间约束下的多个学习任务的性能。通过将完成时间限制从600秒更改为3000秒来测试三个学习任务。从图15可以看出,AAFL的最小精度明显高于ADP-FL和AFO。例如,当完成时间约束为1800秒时,AAFL对三个学习任务的最低准确率为69%,而AFO和ADP-FL的最低准确率分别约为51%和59%。因此,我们与AFO和ADP-FL相比,AAFL框架的最小精度分别提高了18%和10%。这些结果表明,在资源约束下,与两个基准相比,AAFL可以显著提高分类精度。
5.2.4. 结论
综上所述,即使在网络中存在数据不平衡和边缘动态的情况下,AAFL机制与现有方案相比,完成时间减少了约55%。此外,在资源约束下,与AFO和ADP-FL相比,AAFL可以提高最大损失值和最小分类精度
5.3. 对比试验(实际工作台)
结论:在不同的数据分布情况下,与基准相比,AAFL 机制在模型训练方面取得了更好的性能(如损失、时间和带宽)。
6. (备选)自己的思考
- DRL 本身是需要 一个总代理 和多个子代理,这个结构和 FL 本身就很像。感觉这种自适应的调整某些参数的解决方法中 一大类 就是 找和 AFL 相似的架构 应用到 FL 中
- 这篇实验很多,证明也很多,打算快做实验的时候再好好盘点一下
- 问题:DRL 模型训练的时间是在 FL 训练之前还是同时
- 之前对这种模型训练的概念很模糊, DRL 模型训练的时候需要 FL 的实际环境,如果作者先训练好 DRL 的模型,再放到 FL 环境下进行使用,文章应该会针对这点做单独说明吧,所以我认为是在进行 DRL 训练的同时进行 FL 训练(可不可以理解为一起训练这种情况 是分开训练的 预训练?)
- 输入 输出 训练



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











