









视频:11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
Vision Transformer学习笔记_linear projection of flattened patches-CSDN博客
一、embedding 层
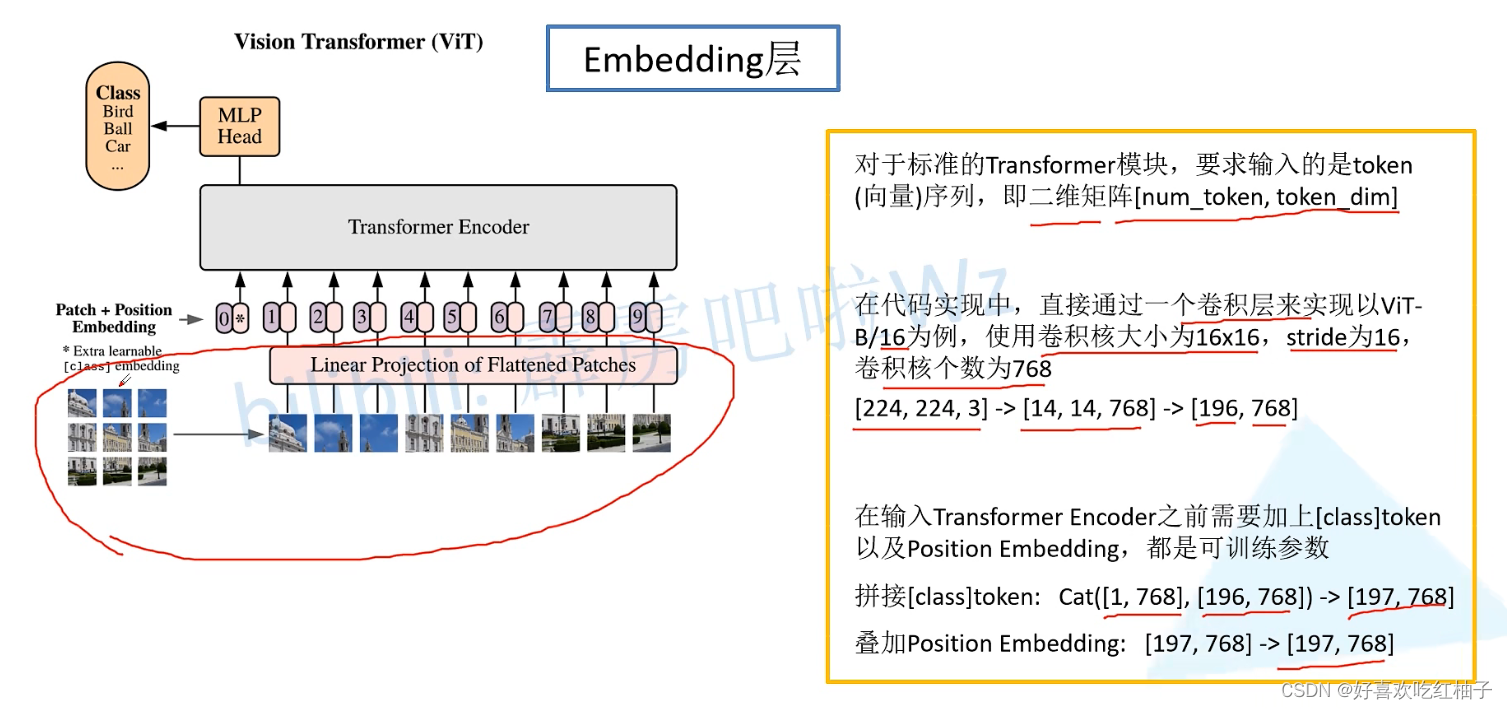
对于标准的Transformer模块,要求输入的是token (向量)序列,即二维矩阵[num_token,token_dim];
在代码实现中,直接通过一个卷积层来实现以ViT一 B/16为例,使用卷积核大小为16x16,stride为16, 卷积核个数为768;
- [224, 224, 3] -> [14, 14, 768] -> [196, 768]
在输入Transformer Encoder之前需要加上[class]token 以及Position Embedding,都是可训练参数
- 拼接[class]token: Cat([1,768],[196,768])->[197,768]
- 叠加Position Embedding: [197,768]->[197,768]
在这里我画了一个图来解释一下整体过程:

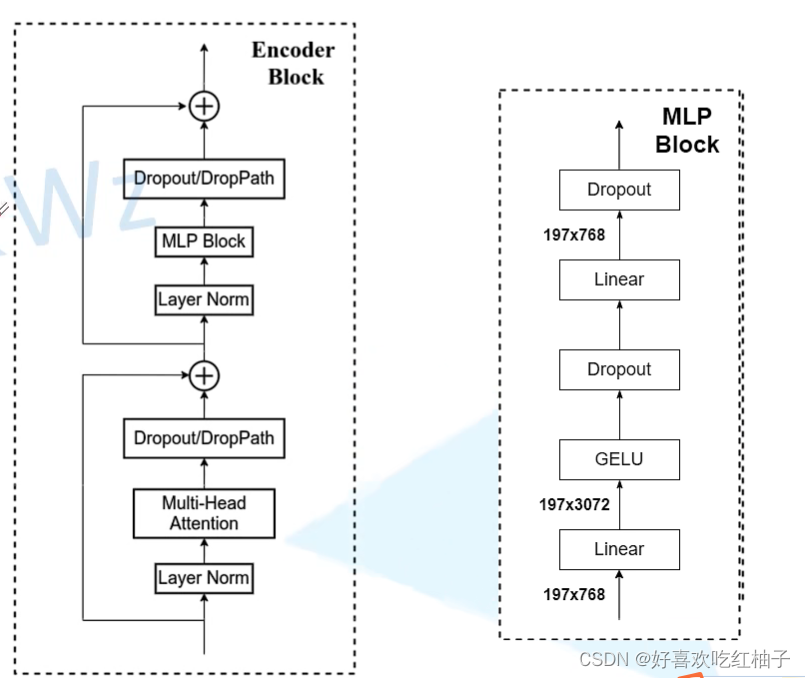
二、Encoder层
主要完成机制就是多头注意力机制。
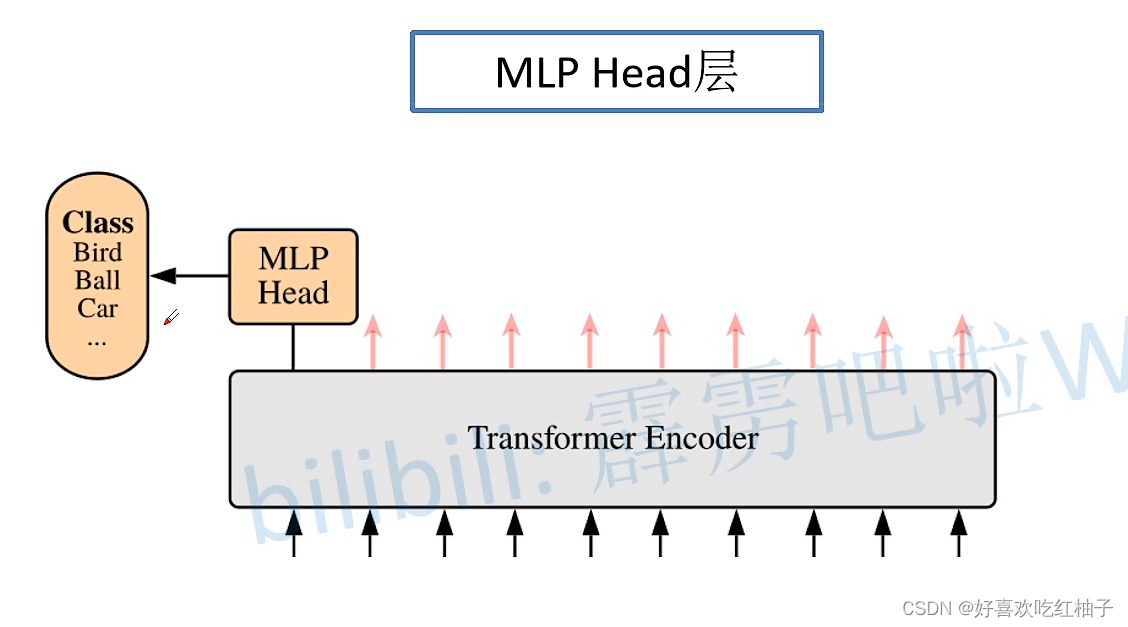
三、 MLP Head层
把class token从最终结果[197,768]中切片拿出来,对其进行linear全连接(简单理解),如果需要类别概率的话,可以再接一个softmax
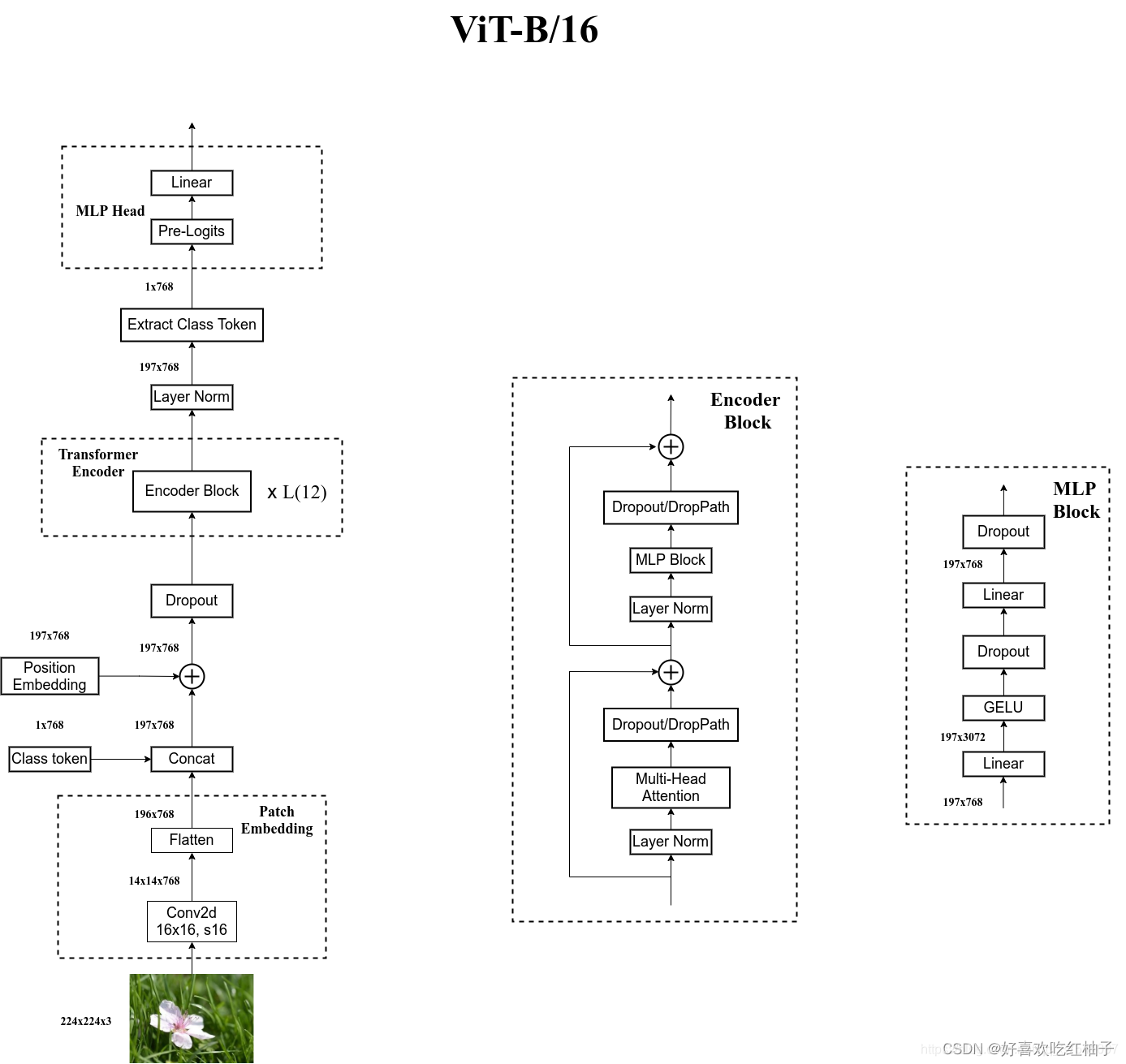
借用我导的图片来总结一下
四、代码实现
4.1 数据集
使用的数据集为苹果树叶数据集,共有5788张,5个类,分别是苹果树叶的三种疾病类(各1000张)、一个healthy类(1645张)和一个无关类(1143张)


4.2 训练过程
使用patch=16、输入图像为224*224的vit在imagenet21k上预训练过的模型进行了实验,实验设置80%的训练集和20%的测试集
- train.py文件需要修改的数据集路径和预训练权重
 参数设置: epoch=10,batchsize=8,最终的训练结果准确率达到96.7%
参数设置: epoch=10,batchsize=8,最终的训练结果准确率达到96.7%
训练过程:

生成的权重文件:

4.3 预测过程
- predict.py文件需要修改的预测图片的路径以及训练的权重路径

- 测试结果如下:


















 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









