






【功能模块】
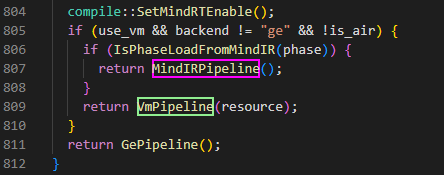
查看mindspore源码,路径mindspore/ccsrc/pipeline/jit/pipeline.cc,发现有两个pipeline路线,分别对应后端是GE还是VM。
基于mindspore1.7.0 GPU RTX3080 cuda11.7
【操作步骤&问题现象】
1、在开启图算融合和save_graphs的情况下,跑了一个简单的自组合算子的python代码,生成了许多IR文件;
2、查看mindspore/ccsrc/pipeline/jit/pipeline.cc的代码,主要分为Vmpipeline和Gepipeline,分别对应后端是Ge还是Vm。对比生成的所有IR文件的名称,发现走的应该是Vmpipeline;
3、请问后端为Ge意思是使用到了图引擎吗?VM的具体含义是什么?
4、如何设置或者添加相关代码使得走GePipeline?
5、请问图算融合的代码在哪一部分?图算融合不应该默认会使用Ge层吗?为什么不走Gepipeline?
希望能够对两个Pipeline做一个解析说明,便于更好的理解源码,谢谢!
【截图信息】
pipeline.cc
图算融合优化也是在VmPipeline里面,代码总入口是
graphkernel::GraphKernelOptimize(mindspore/ccsrc/common/graph_kernel/adapter/graph_kernel_optimization.cc)
不同后端的调用点分别在:
AscendGraphOptimization::HardWareOptimization(mindspore/ccsrc/plugin/device/ascend/hal/hardware/ascend_graph_optimization.cc)
GPUKernelExecutor::OptimizeGraph(mindspore/ccsrc/plugin/device/gpu/hal/hardware/gpu_device_context.cc)
CPUKernelExecutor::OptimizeGraph(mindspore/ccsrc/plugin/device/cpu/hal/hardware/cpu_device_context.cc)















 2058
2058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









