










原文链接:
https://arxiv.org/abs/1807.06521
摘要简介:
他们提出了一种名为“卷积块注意力模块”(CBAM)的注意力模块,这是一个简单但高效的工具,专门用于增强前馈卷积神经网络的功能。当接收到一个中间特征图时,CBAM能够沿着通道和空间这两个维度独立地推断出注意力图。随后,这些注意力图会与输入的特征图相乘,实现自适应的特征优化。
由于CBAM是一个轻量级且通用的模块,它可以毫不费力地集成到任何CNN架构中,几乎不增加额外的计算负担。更值得一提的是,CBAM可以与基础CNN无缝衔接,进行端到端的训练。
为了验证CBAM的有效性,他们在ImageNet-1K、MS COCO检测和VOC 2007检测等多个大型数据集上进行了广泛的实验。实验结果表明,CBAM在各种模型中的分类和检测性能均得到了显著的提升,这充分展示了其广泛的适用性。
模型结构:
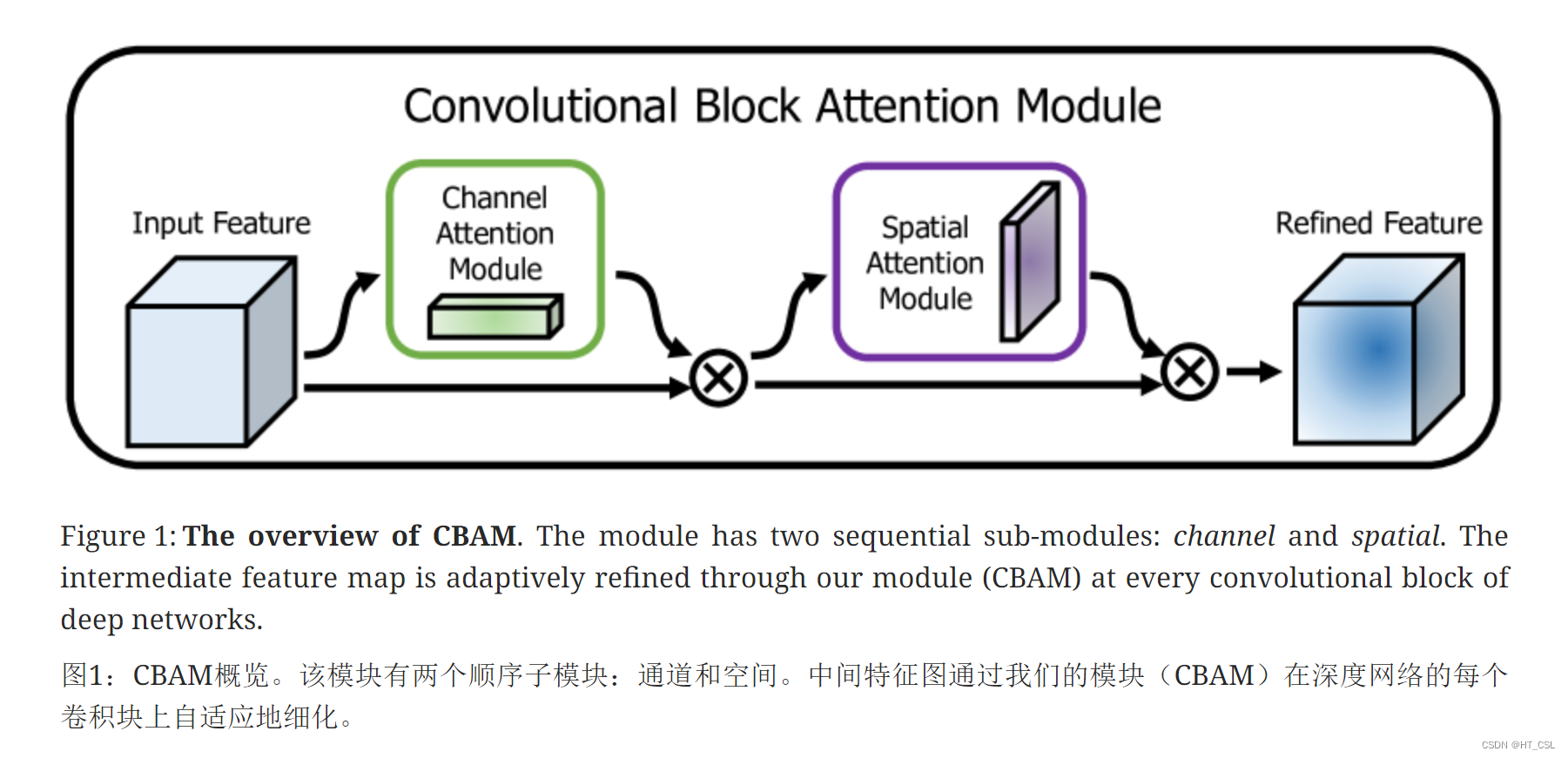
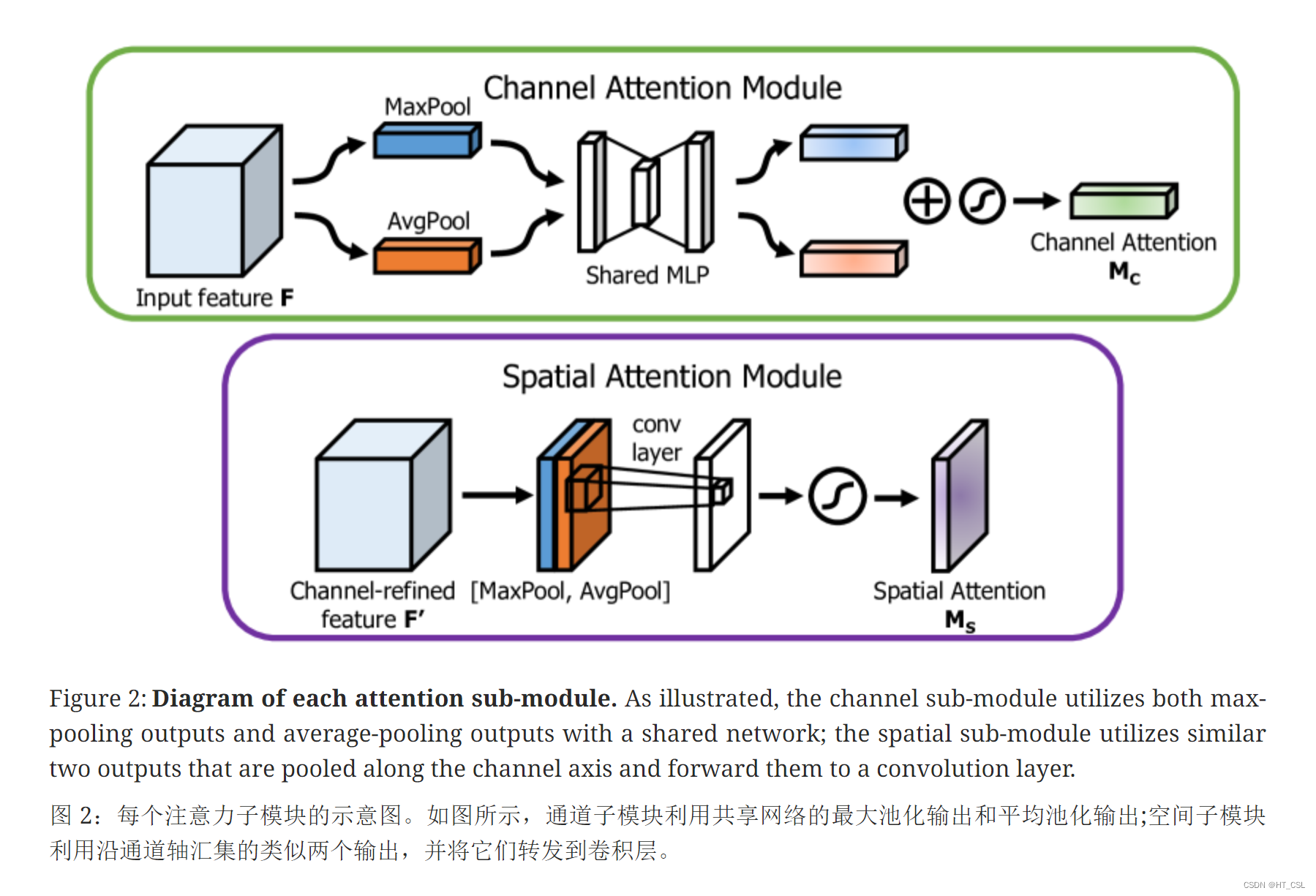
Pytorch版源码:
import torch
import torch.nn as nn
#CBAM,通道注意力机制+空间注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x*self.channelattention(x)
x = x*self.spatialattention(x)
return x
if __name__ == '__main__':
input = torch.randn(2, 32, 512, 512)
CBAM = cbam_block(channel=input.size(1), ratio=8, kernel_size=7)
output = CBAM(input)
print(output.shape)














 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









