










 本文介绍了一种新的注意力机制——坐标注意力,它结合了位置信息于通道注意力中,增强模型对空间信息的理解,尤其在ImageNet分类及下游任务中表现优秀。该机制易于集成到MobileNetV2等架构,计算负担小,提升了模型性能。
本文介绍了一种新的注意力机制——坐标注意力,它结合了位置信息于通道注意力中,增强模型对空间信息的理解,尤其在ImageNet分类及下游任务中表现优秀。该机制易于集成到MobileNetV2等架构,计算负担小,提升了模型性能。
原文链接:
https://paperswithcode.com/paper/coordinate-attention-for-efficient-mobile
源码链接:
https://github.com/houqb/CoordAttention
摘要简介:
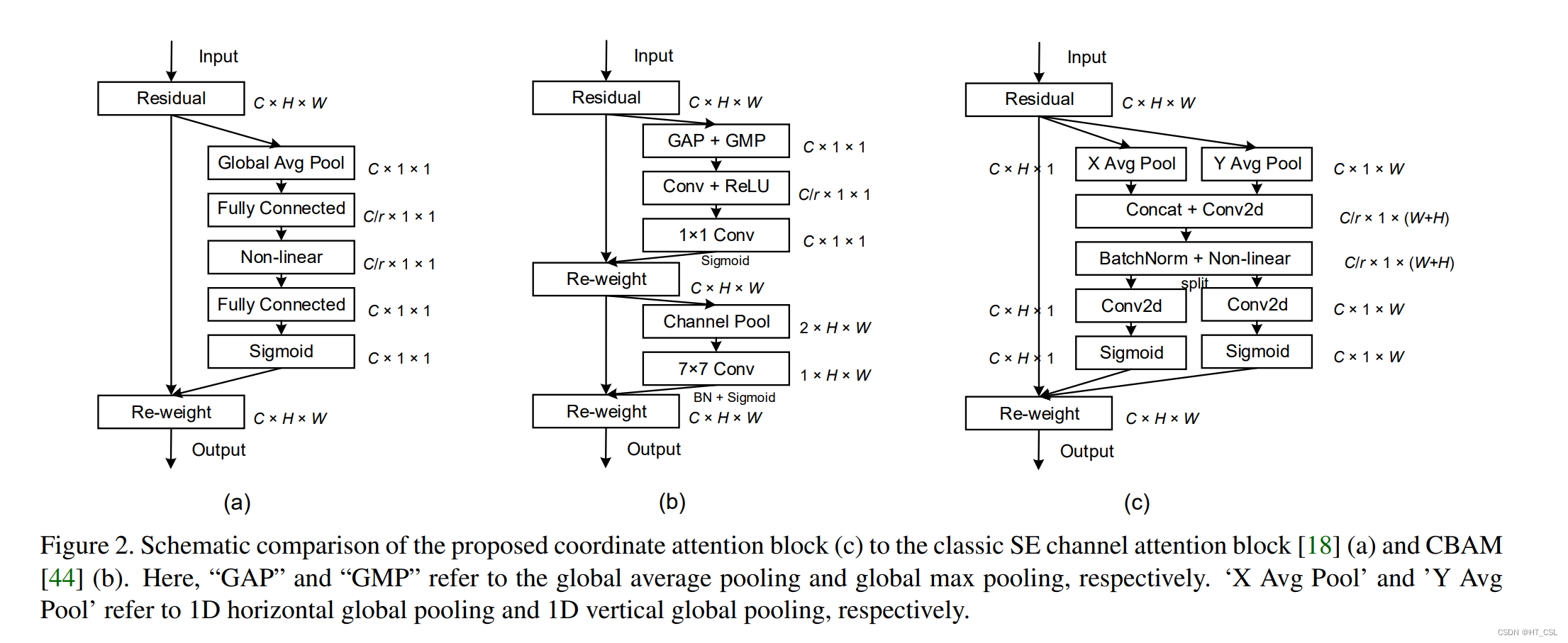
最近的研究表明,在移动网络设计中,通道注意力对于提升模型性能非常有效。但现有的研究常常忽略了位置信息,这对于生成精确的空间注意力图来说是非常重要的。在本文中,我们提出了一种创新的注意力机制,我们称之为“坐标注意力”。这个机制将位置信息融入通道注意力中,从而提升了模型的感知能力。
与常规通道注意力机制不同,坐标注意力并不是简单地将特征张量转换为一个特征向量。而是将其分解为两个一维的特征编码过程,这两个过程各自沿着不同的空间方向来聚合特征。这样,我们既可以捕捉到一个空间方向上的长距离依赖关系,又能保留另一个方向上的精确位置信息。
然后,我们利用这些信息生成一对能够感知方向和位置的注意力图,它们可以互补地应用到输入特征图上,从而增强对感兴趣对象的表示。这个新的注意力机制不仅简单,而且非常容易集成到现有的移动网络架构中,如MobileNetV2、MobileNeXt和EfficientNet,而不会显著增加计算负担。
通过实验验证,我们发现这种坐标注意力机制不仅在ImageNet分类任务上表现出色,而且在更复杂的下游任务,如目标检测和语义分割上,也展现出了更好的性能。
模型结构:
Pytorch版源码:
#CA CVPR 2021 Coordinate Attentions
#除了通道数还得要宽高信息,比如,16,256,256
import torch
from torch import nn
class CA_Block(nn.Module):
def __init__(self, channel, h, w, reduction=16):
super(CA_Block, self).__init__()
self.h = h
self.w = w
self.avg_pool_x = nn.AdaptiveAvgPool2d((h, 1))
self.avg_pool_y = nn.AdaptiveAvgPool2d((1, w))
self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel // reduction, kernel_size=1, stride=1,
bias=False)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(channel // reduction)
self.F_h = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,
bias=False)
self.F_w = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,
bias=False)
self.sigmoid_h = nn.Sigmoid()
self.sigmoid_w = nn.Sigmoid()
def forward(self, x):
x_h = self.avg_pool_x(x).permute(0, 1, 3, 2)
x_w = self.avg_pool_y(x)
x_cat_conv_relu = self.relu(self.conv_1x1(torch.cat((x_h, x_w), 3)))
x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([self.h, self.w], 3)
s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))
s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
out = x * s_h.expand_as(x) * s_w.expand_as(x)
return out
if __name__ == '__main__':
input = torch.randn(2, 32, 512, 512)
b, channel, h, w = input.shape
CA = CA_Block(channel, h, w)
output = CA(input)
print(output.shape)
















 1878
1878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









