







一、YOLOV3
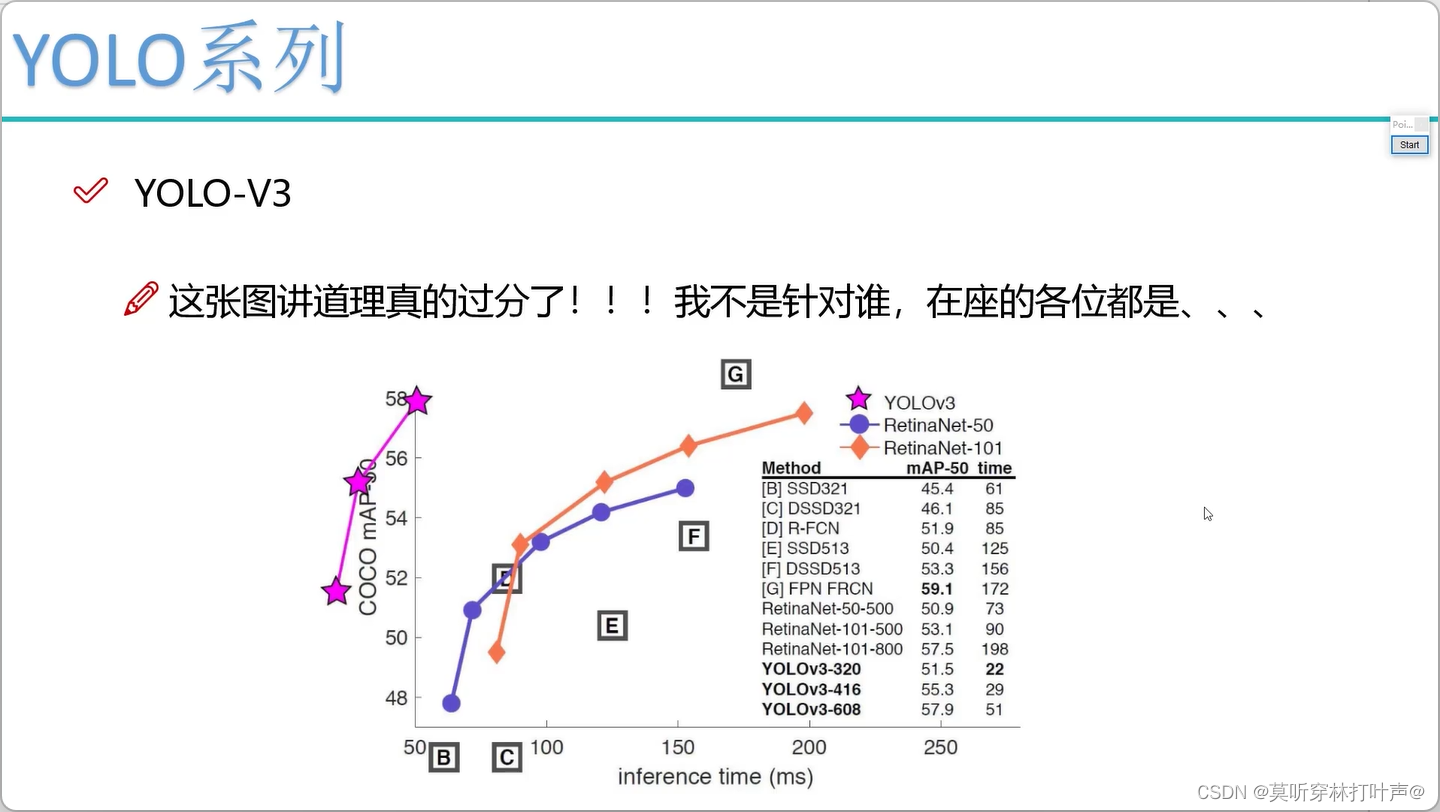

- 多scale
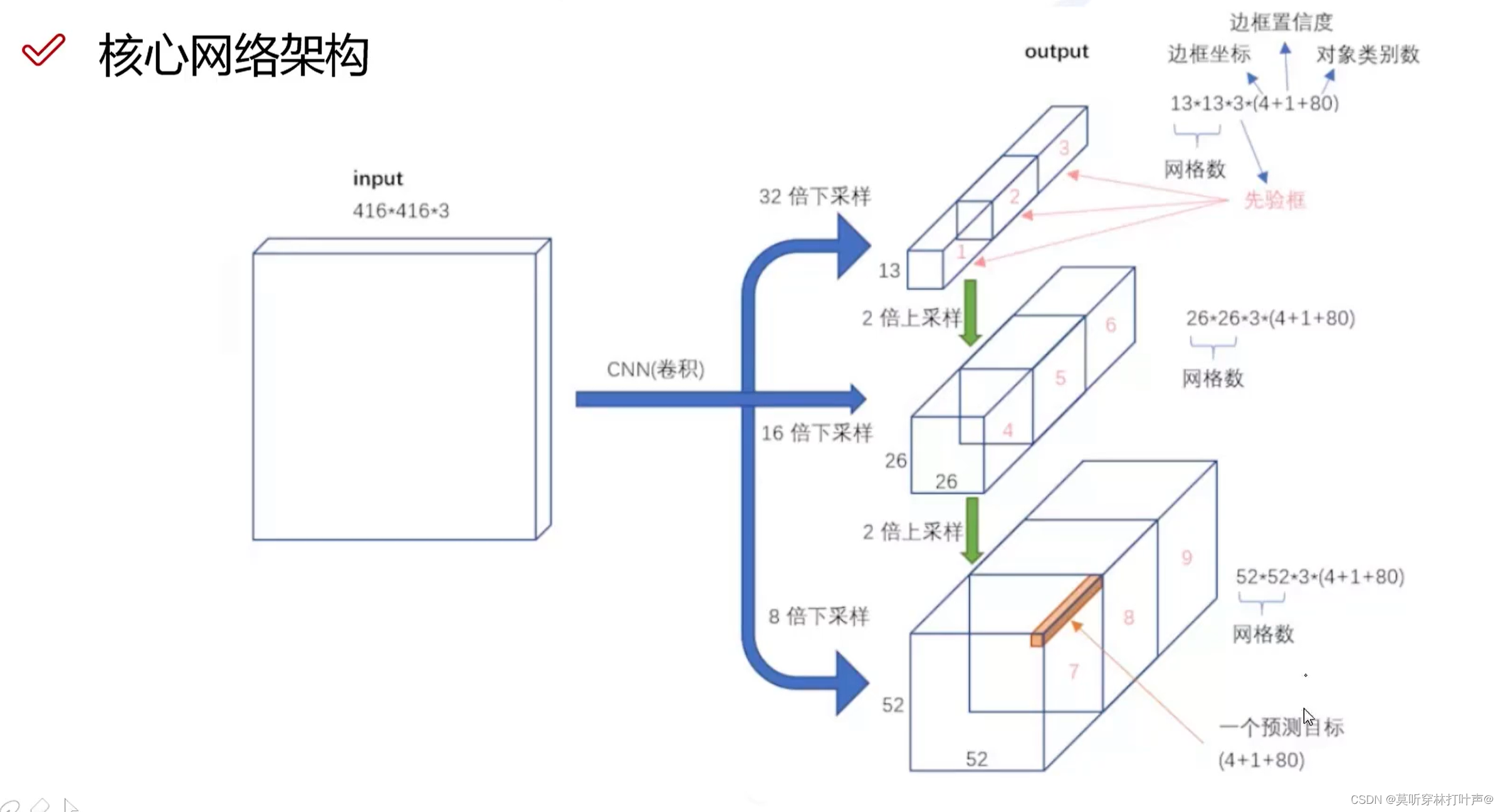
三种scale:
为了检测到不同大小的物体,设计了3个scale。
特征融合不好。
感受野大的特征图预测大的,中的预测中的,小的预测小的。各自预测各自的,不用做特征融合。
三个候选框:
每个特征图三个候选框。
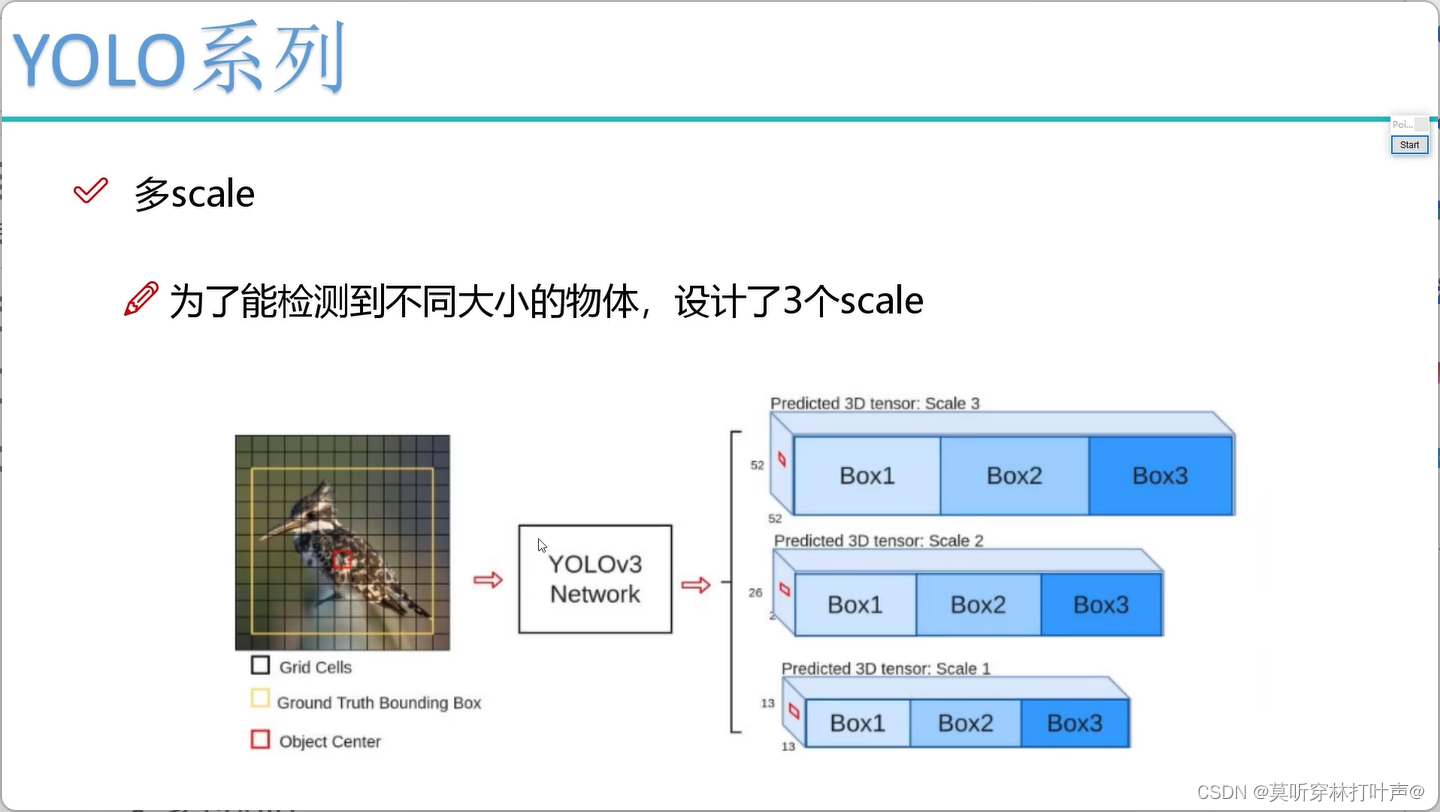
怎么得到大中小的特征图?
不能单独拎出来,要两两进行联系,做一些特征融合。
这两不适合YOLO:
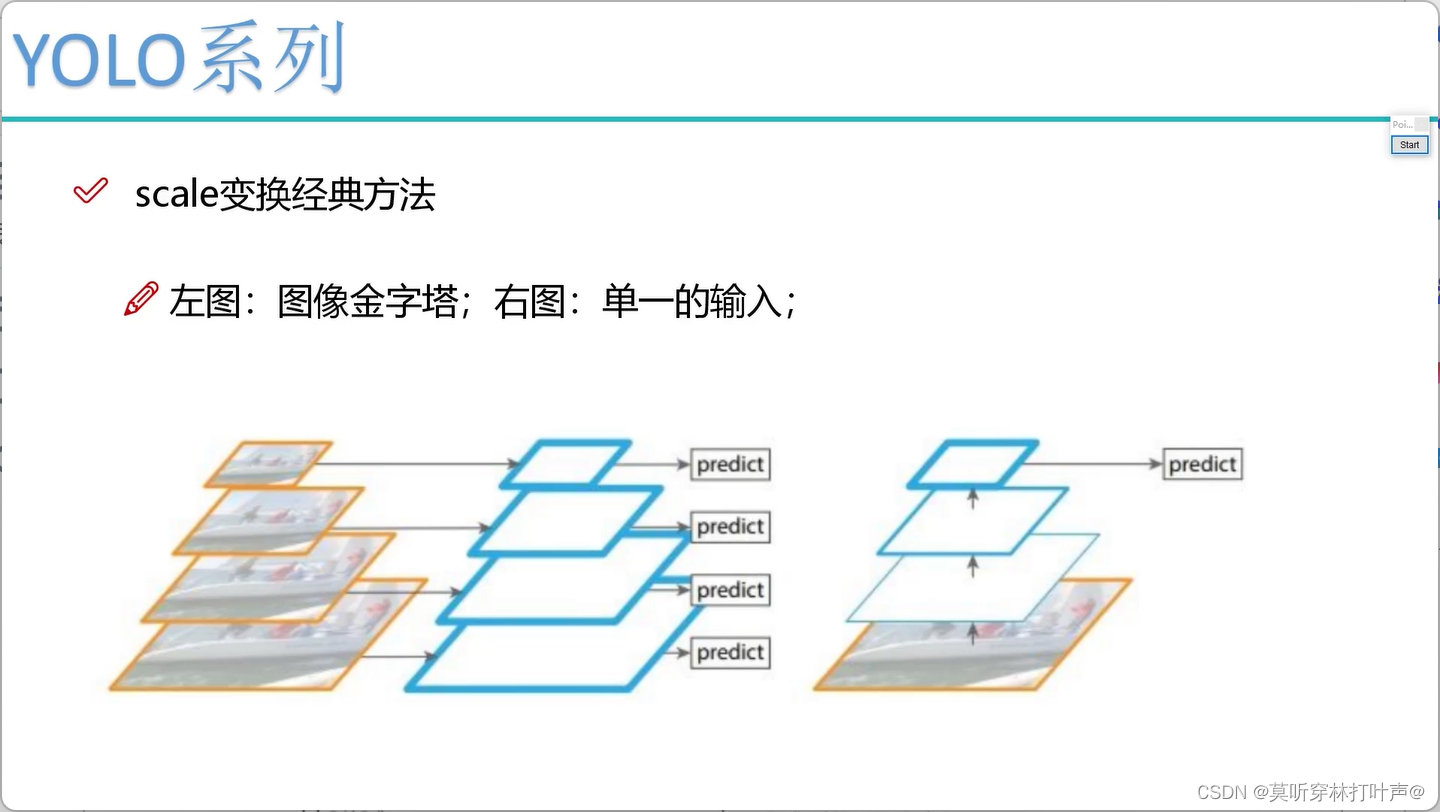
右图是YOLOV3的核心思想:
13×13做一个上采样(插值),变成26×26,跟中间的26×26进行融合。
26×26做一个上采样(插值),变成52×52,跟最前面52×52进行融合。

- 残差连接
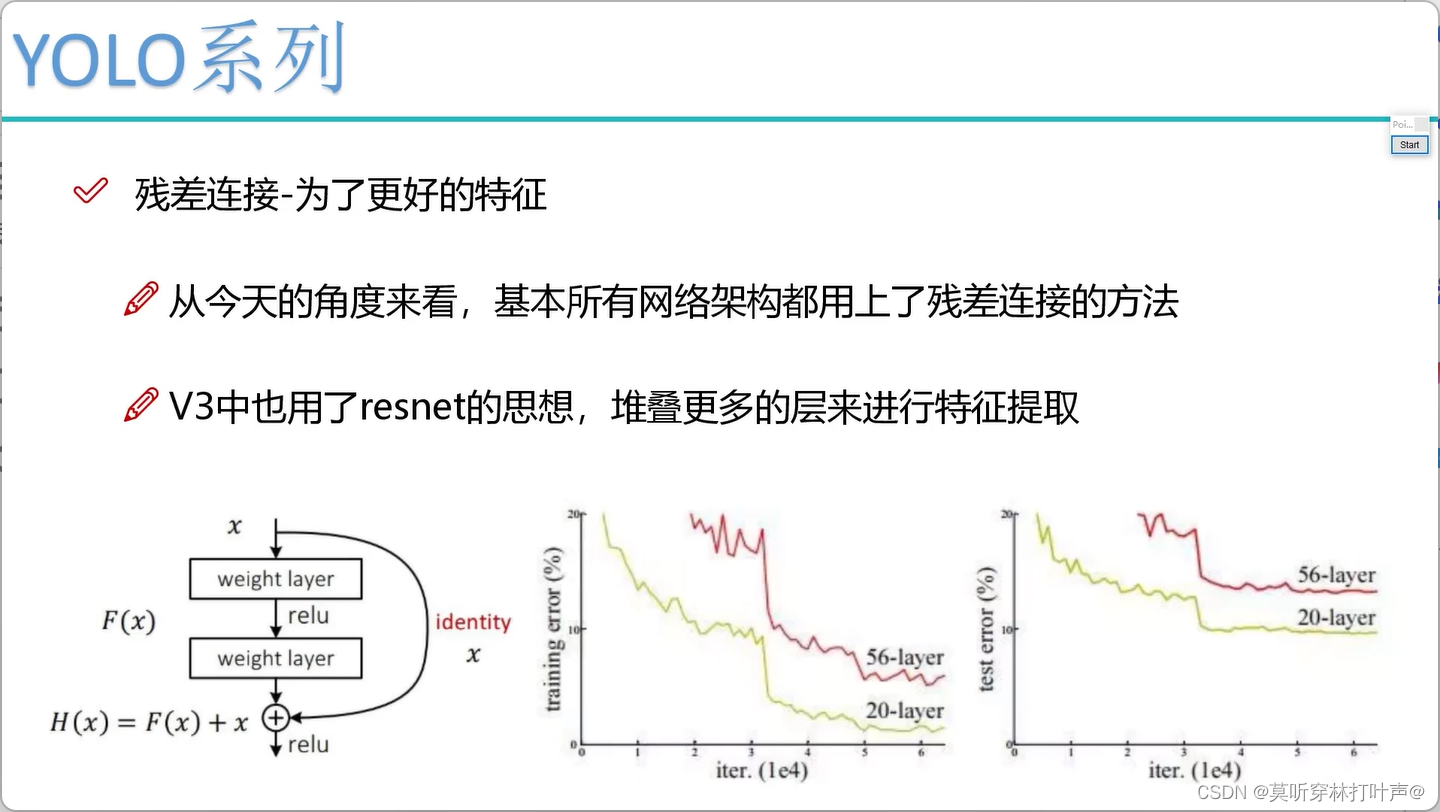
我们都知道,网络越深,效果越差。
采用残差连接,两种方案,效果更差的话,就把残差块学成0,使用一致性映射x。残差肯定不会原来的差。
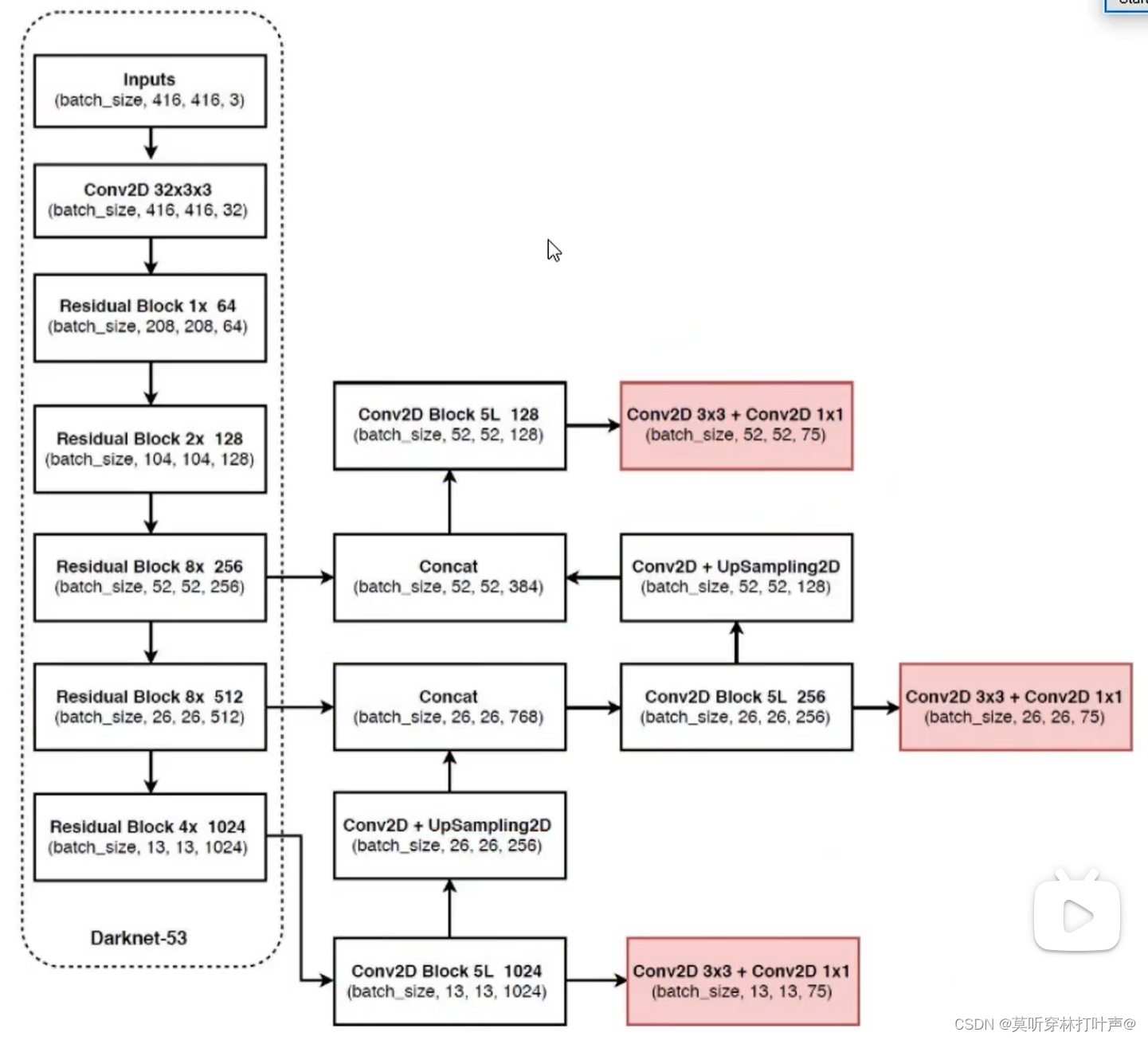
核心的网络架构
- 池化也不要了,特征图怎么变成原来的1/2?需要下采样的时候卷积层的stride=2
- 残差网络那篇论文的残差块没有池化层,之前看竟然没有发现。。。
- 得到感受野大的特征图13×13×75(用作提取大的),将13×13×1024做上采样,变成26×26×256(这个用作特征融合)
- 26×26×256与26×26×512进行特征融合,得到26×26×768,降采样得到26×26×256(这个用作特征融合),最后得到中的特征图26×26×75
- 26×26×256上采样得到52×52×128,与52×52×256特征融合得到52×52×384,最后得到小的特征图52×52×75
- 75会变,看你输入图片的大小

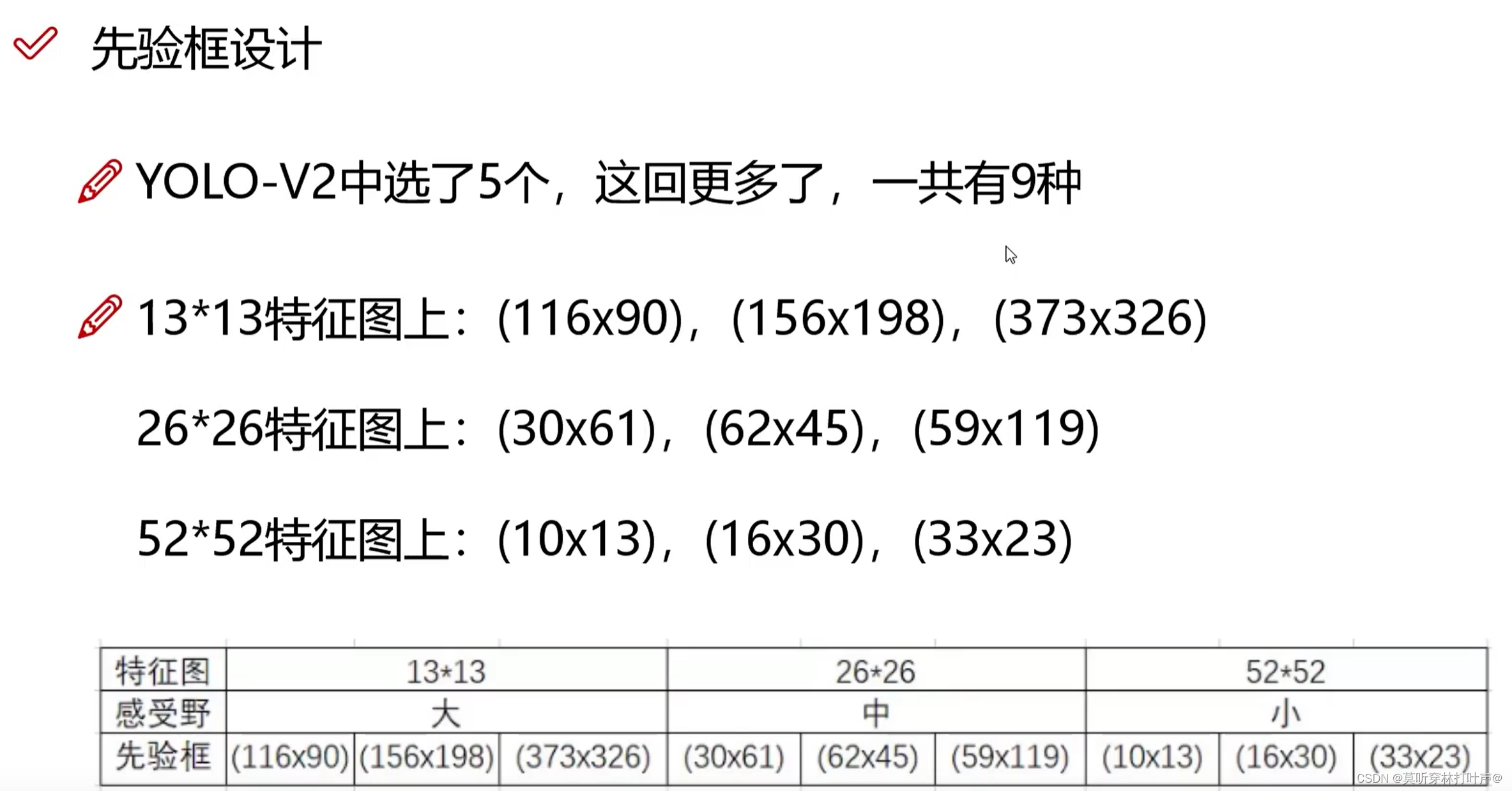
- 先验框设计
V2中用聚类给预测5个,V3先分三类。

- softmax层的改进

softmax不能做多标签的分类,V3做的也不是多标签的分类,而是对每一个类别进行二分类。如下:
判断是个猫的概率是0.8,是个狗的概率是0.2。。。。
设置一个阈值,比如是0.7,大于0.7的则属于这个类。


















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











