






本来是打算先写Anaconda虚拟环境的,不过正好在更新了Ollama之后遇到了新的问题,虽然Ollama不是最高效运行LLM的范式,但还是相对方便和友好的,特别是如果只是个人或小组使用,并发需求不是那么大时,仍然是一个不错的选择。此外,Ollama可以响应请求后自动挂载、卸载模型文件,这一点还是非常方便的,例如在使用Dify编辑工作流时,首先使用MiniCPM-V来识别图像,之后让Deepseek-R1或Qwen-QwQ来推理时,Ollama在运行MiniCPM-V之后,将其卸载,并重新挂载Deepseek-R1或Qwen-QwQ。这次的坑比较意外,因为在更新之前,我使用Ollama挂载本地的gguf模型运行正常,但更新后的第二天,突然发现模型回答出现【乱码】【拒绝回答】【中途停止】【答非所问】【非必要补全】等情况。卸载重新安装后,问题依旧。最后发现是因为Ollama更新后对挂载gguf模型文件的modelfile格式要求有变化,在重新编辑modelfile后,问题解决。既然说到更新和卸载重装,索性把这部分一起写一下。
一、Ollama的更新和卸载
Ollama初始安装还是非常简单的,Mac和Windows系统下载即可,Linux则可以使用官方提供的脚本命令自动运行脚本,但Linux下的卸载和更新比较麻烦一些,下面仅适用于Linux系统。
注意:正常更新不需要卸载旧的版本,只是单独介绍两个操作而已。
1.卸载
第一步,停止移除Ollama服务:
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service第二步,删除所有Ollama文件:
sudo rm $(which ollama)第三步,移除模型文件和用户(组)
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama最后,删除安装目录
sudo rm -rf /usr/local/lib/ollama2.更新
安装官方文件,建议在更新前删除旧的Ollama库,但是实测,直接升级也并没有问题。
sudo rm -rf /usr/lib/ollama升级只需要再次运行安装脚本即可:
curl -fsSL https://ollama.com/install.sh | sh二、Modelfile的编写
之前在挂载gguf格式的模型文件时,只需要在相同目录下,创建一个modelfile,在其中写一条语句注明文件路径,Ollama就可以正确挂载和调用,但这样写其实是不规范的,具体的规范写法应当参考这篇文档。
因为Ollama中默认使用Ollama run {{Modelname}}命令运行的模型大多数是Q4量化的,如果对精度有要求,且显存容量允许时,完全可以使用Q8或fp16等更高精度模型,这时就可以通过HuggingFace(或镜像站)或者魔搭社区等网站下载对应模型文件,之后编写modelfile以便用Ollama挂载。(如果能够正确访问Hugging Face,HuggingFace中可以生成Ollama run 语句的,但因为我的模型文件是以前已经下载好的,下面就以DeepSeek-R1蒸馏Qwen14BQ6量化模型为例,介绍如何编写modelfile。
最开始一行还是和以前一样,首先要写FROM 语句,定义Create模型时使用的基本模型文件:
FROM ./ollama-model.gguf接下来就是最重要的,之前可以非必填,现在需要填写的TEMPLATE提示模板,格式如下:
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""下面可以定义参数如温度、top_k、top_p等值,格式如下:
PARAMETER <parameter> <parametervalue>不同模型modelfile的写法不一样,具体可以参考Ollama网站模型页面中的这里,template对应TEMPLATE,params对应PARAMETER:
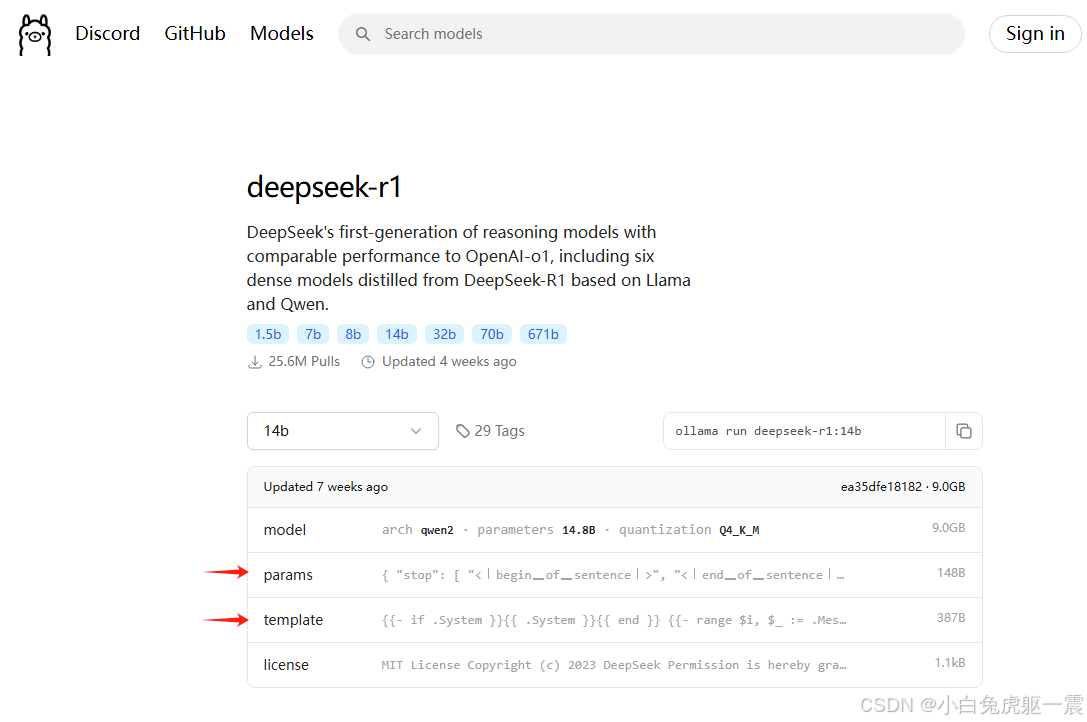
下面以文件名为DeepSeek-R1-Distill-Qwen-14B-GGUF_Q6_K_L的文件为例,提供一个完整的modelfile,以供参考。
FROM ./DeepSeek-R1-Distill-Qwen-14B-Q6_K_L.gguf
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>之后,使用下面的命令创建模型就可以正确使用了:
ollama create Deepseek-R1-14B-Q6 ./Modelfile
ollama run Deepseek-R1-14B-Q6三、总结
Ollama更新后,需要使用正确的modelfile才能正常创建和使用gguf格式的模型文件,如果在回答中出现【乱码】【拒绝回答】【中途停止】【答非所问】【非必要补全】等问题,可以尝试使用以上办法进行解决。

















 4587
4587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









