





系列文章目录
用于时间序列预测的通道对齐鲁棒混合变压器 ICLR2024
文章目录
摘要
最近的研究已经证明了Transformer模型在时间序列预测方面的强大功能。提高训练鲁棒性的信道无关策略是导致变压器成功的关键因素之一。然而,忽略CI中不同通道之间的相关性会限制模型的预测能力。在这项工作中,我们设计了一种特殊的变压器,即通道对准鲁棒混合变压器(简称CARD),它解决了CI型变压器在时间序列预测中的主要缺点。首先,CARD引入了一个通道对齐的注意结构,使其能够捕获信号之间的时间相关性和多个变量之间随时间的动态依赖性。其次,为了有效利用多尺度知识,我们设计了token混合模块来生成不同分辨率的token。第三,我们引入了一个鲁棒损失函数用于时间序列预测,以减轻潜在的过拟合问题。这个新的损失函数对基于预测不确定性的有限范围内预测的重要性进行了加权。我们对多个长期和短期预测数据集的评估表明,CARD显著优于最先进的时间序列预测方法。代码可从以下匿名存储库获得:https://anonymous.open.science/r/CARD-6EEC。
提示:以下是本篇文章正文内容
一、介绍
时间序列预测已成为天气预测、金融投资、能源管理和交通流量估计等各个领域的重要任务。深度学习模型的快速发展导致了时间序列预测技术的重大进步,特别是在多元时间序列预测方面。在为时间序列预测开发的各种深度学习模型中,变压器、cnn、RNN和基于mlp的模型由于能够捕获复杂的长期时间依赖性而表现出了出色的性能(例如,Zhou等人,2021;2022b;Wu et al., 2021;刘等,2022a;Challu et al., 2022;Zeng et al., 2023;Wu等人,2023b;张燕,2023;Nie et al., 2023;吴等人,2009;a;b;Liu et al., 2022c;Zhou et al., 2022a)。
对于多变量时间序列预测,通过利用不同预测变量之间的依赖性,即所谓的通道依赖(CD)方法,模型有望产生更好的性能。然而,最近的多项研究(如Nie et al. 2023;Zeng et al. 2023)表明,在一般的信道独立(CI)预测模型中(即所有时间序列变量都是独立预测的)优于CD模型。(Han et al., 2023)的分析表明,CI预测模型更具鲁棒性,而CD模型具有更高的建模能力。考虑到时间序列预测通常涉及高噪声水平,典型的基于变压器的CD设计预测模型可能会受到过拟合噪声的影响,从而导致性能受限。这些实证研究和分析提出了一个重要的问题,即如何建立一个有效的变压器,利用跨通道信息进行时间序列预测。
在本文中,我们提出了一种通道对齐鲁棒混合变压器,简称CARD,它有效地利用了通道(即预测变量)之间的依赖性,并缓解了时间序列预测中的过拟合噪声问题。与时间序列分析的典型变压器不同,该变压器仅通过对令牌的关注来捕获信号之间的时间依赖性,而CARD还跨不同的通道和隐藏维度进行关注,从而捕获预测变量之间的相关性,并在每个令牌内对齐本地信息。我们观察到相关方法已在计算机视觉中得到利用(Ding et al., 2022;Ali等人,2021)。此外,已知多尺度信息在时间序列分析中起着重要作用。我们设计了一个令牌混合模块来生成不同分辨率的令牌。特别是,我们建议将同一头部内的相邻标记合并为新标记,而不是在多头注意中合并不同头部上的相同位置。为了提高时间序列预测变压器的鲁棒性和效率,我们进一步在查询/键令牌上引入指数平滑层,并在处理不同通道之间的信息时引入动态投影模块。最后,为了缓解过拟合噪声的问题,在有限视界预测的情况下,引入了一个鲁棒损失函数,通过其不确定性对每个预测进行加权。整个模型体系结构如图1所示。我们通过将其与变压器和其他模型的最先进方法进行比较,验证了所提出模型在各种数值基准上的有效性。在此,我们总结了我们的主要贡献如下:
-
本文提出了一种bf通道对齐鲁棒混合变压器(CARD),它能有效鲁棒地对齐不同通道间的信息,并充分利用多尺度信息。
-
CARD在用于长期预测的7个基准数据集、用于短期预测的M4数据集和其他基于预测的任务中表现优异,优于最先进的模型。我们的研究证实了所提出模型的有效性。
-
我们开发了一个基于信号衰减的鲁棒损失函数,该函数利用信号衰减来增强模型专注于近期预测的能力。我们的经验评估证实,该损失函数在提高其他基准模型的性能方面也是有效的。
本文的其余部分结构如下。在第2节中,我们提供了与本研究相关的相关工作的总结。第3节给出了建议的详细模型架构。第4节通过高斯分布和拉普拉斯分布的极大似然估计描述了损失函数设计的理论解释。在第5节中,我们展示了长期/短期时间序列预测基准的数值实验结果,并进行了全面分析,以确定自关注方案对时间序列预测的有效性。此外,我们还讨论了消融和本研究中进行的其他实验。最后,在第六节中,对本文的结论和未来的研究方向进行了讨论。
二、相关工作
2.1 TRANSFORMERS FOR TIME SERIES FORECASTING
近年来,有大量的工作试图应用Transformer模型来预测长期时间序列(Wen et al., 2023)。我们在这里总结其中的一些。LogTrans (Li et al., 2019a)使用具有LogSparse设计的卷积自关注层来捕获局部信息并降低空间复杂度。Informer (Zhou et al., 2021)提出了一种带有蒸馏技术的ProbSparse自关注,以有效地提取最重要的关键字。Autoformer (Wu et al., 2021)借鉴了传统时间序列分析方法的分解和自相关思想。FEDformer (Zhou et al., 2022b)采用傅里叶增强结构获得线性复杂度。Pyraformer (Liu et al., 2022a)采用具有尺度间和尺度内连接的金字塔式注意力模块,同样具有线性复杂度。LogTrans避免了键和查询之间逐点的点积,但它的值仍然基于单个时间步长。Autoformer使用自相关来获得补丁级连接,但它是一种手工设计,不包括补丁中的所有语义信息。最近的一项工作PatchTST (Nie et al., 2023)研究了使用视觉变压器类型模型进行通道独立设计的长期预测。与我们提出的方法最接近的工作是Crossformer (Zhang & Yan, 2023)。这项工作设计了一个编码器-解码器模型,利用层次注意机制来利用跨维度依赖关系,并在我们在这项工作中使用的相同基准数据集中实现适度的性能。从模型架构的角度来看,与Crossformer不同的是,我们采用了仅编码的结构,并且通过轻量级的令牌混合模块来诱导多尺度信息,而不是像Crossformer那样显式地生成令牌层次结构。这些设计使CARD具有更好的鲁棒性和更高的数值性能。
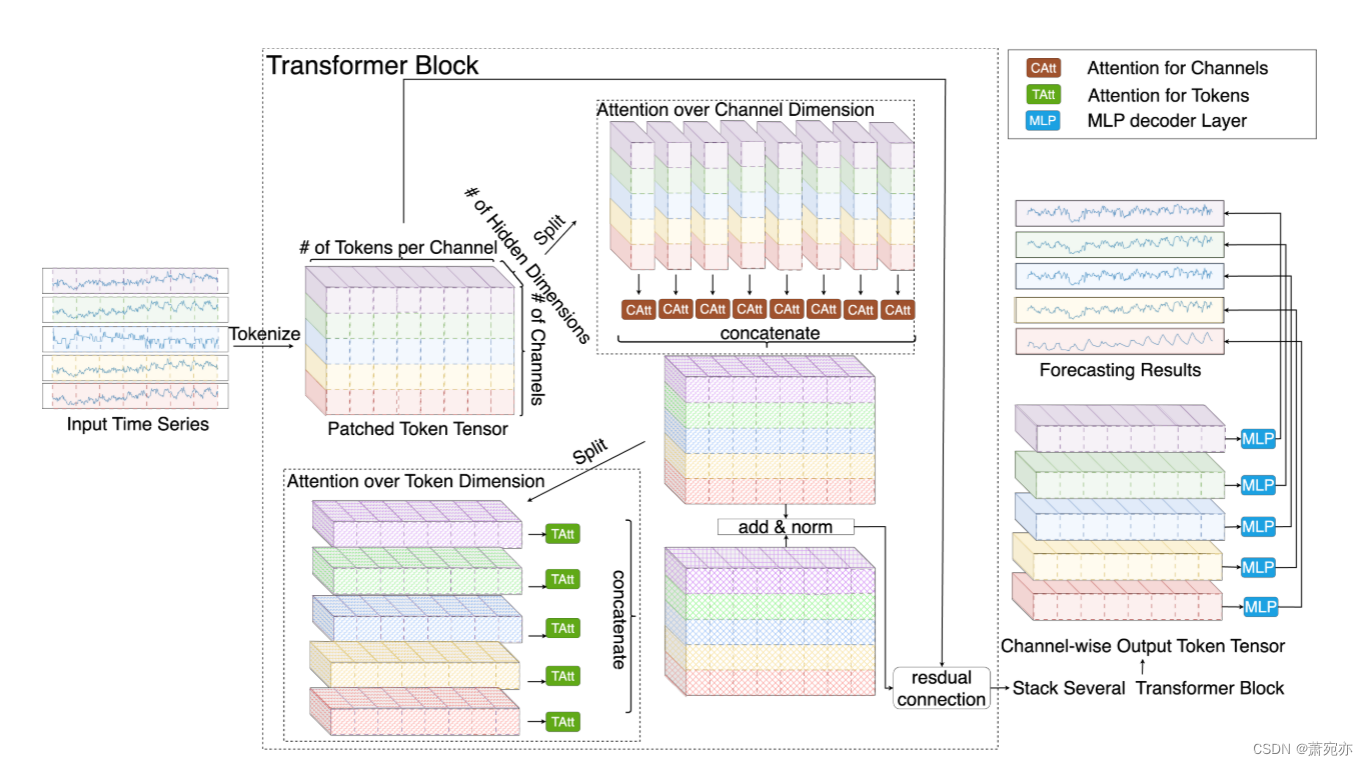
图1:CARD的体系结构示意图。
2.2用于时间序列预测的rnn、MLP和CNN模型
除变压器外,其他类型的网络也被广泛探索。例如(Lai et al., 2018;Lim et al., 2021;Salinas et al., 2020;Smyl, 2020;Wen et al., 2017;Rangapuram等人,2018;周等,2022a;Gu et al., 2022)研究了RNN/状态空间模型。特别是,(Smyl, 2020)考虑在预测任务中为RNN配备指数平滑和首次击败统计模型(Makridakis et al., 2018)。(Chen et al., 2023;Oreshkin et al., 2020;Challu et al., 2022;Li et al., 2023;Zeng et al., 2023;Das et al., 2023;Zhang et al., 2022)探索了用于时间序列预测的mlp型结构。CNN模型(如Wu et al. 2023b;Wen et al. 2017;Sen et al. 2019)使用时间卷积层提取子序列级信息。在处理多变量预测任务时,假设相邻协变量平滑或采用信道无关策略。
三、模型体系结构
图1展示了CARD的体系结构。设 a t ∈ R C a_t\in\mathbb{R}^C at∈RC为通道C≥1时时间序列在时刻t的观测值。我们的目标是使用L个最近的历史数据点(例如, a t − L + 1 , . . . , a t a_{t-L+1},...,a_t at−L+1,...,at)来预测未来的T步观测值。(例如, a t + 1 , . . . , a t + T a_{t+1},...,a_{t+T} at+1,...,at+T,其中L,T≥1。
3.1 TOKENIZATION
我们采用了修补的思想(例如,Nie等人,2023;Zhang & Yan 2023)将输入时间序列转换为token张量。令
A
=
[
a
t
−
L
+
1
,
.
.
.
,
a
t
]
∈
R
C
×
L
A=[a_{t-L+1},...,a_t]\in\mathbb{R}^{C\times L}
A=[at−L+1,...,at]∈RC×L为输入数据矩阵,S和P分别为步长和补丁长度。我们将矩阵A展开为原始令牌张量
X
~
∈
R
C
×
N
×
P
\tilde{X}\in\mathbb{R}^{C\times N\times P}
X~∈RC×N×P,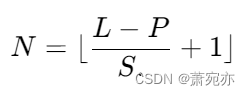
。在这里,我们将时间序列转换为几个P长度的片段,每个原始标记都保留了部分序列级语义信息,这使得注意力方案比普通的点对等物更有效。
然后,我们使用一个密集的MLP层
F
1
:
P
→
d
,
F_{1}:P\to d,
F1:P→d,,一个额外的令牌
T
0
∈
R
C
×
d
\mathbf{T}_0\in\mathbb{R}^{C\times d}
T0∈RC×d,位置嵌入
E
∈
R
C
×
N
×
d
\boldsymbol{E}\in\mathbb{R}^{C\times N\times d}
E∈RC×N×d,生成令牌矩阵如下:
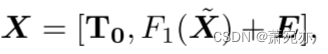
式中, X ∈ R C × ( N + 1 ) × d X\in\mathbb{R}^{C\times(N+1)\times d} X∈RC×(N+1)×d, d为隐维。与(Nie et al., 2023)和(Zhang & Yan, 2023)相比,我们的令牌构造引入了一个额外的T0令牌。T0标记类似于(Lim et al., 2021)中的静态协变量编码器,并允许我们有一个地方注入总结了该系列较长历史的特征。
我们考虑通过令牌张量X的线性投影生成Q、K和V:
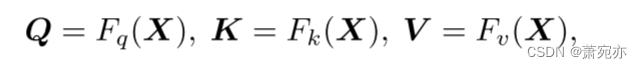
其中,
Q
,
K
,
V
∈
R
C
×
(
N
+
1
)
×
d
Q,K,V\in\mathbb{R}^{C\times(N+1)\times d}
Q,K,V∈RC×(N+1)×d和Fq, Fk, Fv为MLP层。
接下来我们将Q,K,V转换成 { Q i } , { K i } , { V i } \{Q_i\},\{K_i\},\{V_i\} {Qi},{Ki},{Vi},其中 Q i , K i , V i ∈ R C × ( N + 1 ) × d h e a d Q_i,K_i,V_i\in\mathbb{R}^{C\times(N+1)\times d_{\mathrm{head}}} Qi,Ki,Vi∈RC×(N+1)×dhead, i = 1,2,…,H。H和dhead分别是头的个数和头的尺寸。对于每个样本,token的总数为C(N + 1)。为了充分利用所有的跨通道信息,理想的注意力需要 O ( C 2 ( N + 1 ) 2 ) \mathcal{O}(C^{2}(N+1)^{2}) O(C2(N+1)2)计算成本,这可能非常耗时,并且在训练样本量有限的情况下容易导致过拟合。在本文中,我们考虑在每个维度上交替关注。
3.2 CARD ATTENTIONS OVER TOKENS
注意令牌时,我们将通道维上的 Q i Q_{i} Qi, K i K_{i} Ki, V i V_{i} Vi切成 { Q i c : } \{Q_i^{c:}\} {Qic:} { K i c : } \{K_i^{c:}\} {Kic:} { V i c : } \{V_i^{c:}\} {Vic:},其中 Q i c : , K i c : , V i c : ∈ R ( N + 1 ) × d h e a d Q_{i}^{c:},K_{i}^{c:},V_{i}^{c:}\in\mathbb{R}^{(N+1)\times d_{\mathrm{head}}} Qic:,Kic:,Vic:∈R(N+1)×dhead c = 1,2,…C。除了令牌中的标准注意力之外,我们还在隐藏维度中引入了一个额外的注意力结构,有助于捕获每个补丁中的局部信息。令牌和隐藏维度的注意力计算如下:
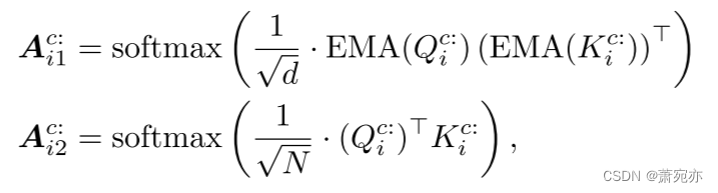
其中
A
i
1
c
:
∈
R
(
N
+
1
)
×
(
N
+
1
)
A_{i1}^{c:}\in\mathbb{R}^{(N+1)\times(N+1)}
Ai1c:∈R(N+1)×(N+1),
A
i
2
c
:
∈
R
d
h
e
a
d
×
d
h
e
a
d
A_{i2}^{c:}\in\mathbb{R}^{d_{\mathrm{head}}\times d_{\mathrm{head}}}
Ai2c:∈Rdhead×dhead, EMA表示指数移动平均
通过在
Q
i
c
:
Q_i^{c:}
Qic:和
K
i
c
:
K_i^{c:}
Kic:上应用EMA,每个查询令牌将能够在更多的关键令牌上获得更高的关注分数,因此输出变得更加健壮。在(Ma et al., 2023)和(Woo et al., 2022b)中也探讨了类似的技术。与文献不同的是,我们发现使用所有维度保持不变的固定EMA参数足以稳定训练过程。因此,我们的EMA不包含可学习的参数。
输出计算如下:
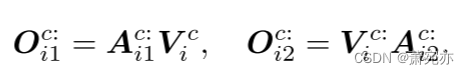
接下来,我们将应用提议的令牌混合模块来合并头部并生成捕获多尺度知识的令牌,详细讨论将推迟到第3.4节。然后使用批量归一化(ioffe&szegedy, 2015)到 O i 1 c : O_{i1}^{c:} Oi1c:和 O i 2 c : O_{i2}^{c:} Oi2c:来调整输出的比例。最后,利用残差连接结构生成注意块的最终输出。
每个通道的令牌总数约为 O ( L / S ) \mathcal{O}(L/S) O(L/S),令牌的注意力复杂度上限为 O ( C ⋅ d 2 ⋅ L 2 / S 2 ) \mathcal{O}(C\cdot d^{2}\cdot L^{2}/S^{2}) O(C⋅d2⋅L2/S2),小于普通逐点令牌构造的 O ( C ⋅ d 2 ⋅ L 2 ) \mathcal{O}(C{\cdot}d^{2}{\cdot}L^{2}) O(C⋅d2⋅L2)复杂度。在实践中,人们可以使用高效的注意力实现(例如,FlashAttention Dao等人,2022)来进一步获得接近线性的计算性能。
3.3 CARD ATTENTION OVER CHANNELS
我们首先通过式(2)计算 { Q i } \{\boldsymbol{Q}_{i}\} {Qi}, { K i } \{\boldsymbol{K}_{i}\} {Ki}和 { V i } \{\boldsymbol{V}_{i}\} {Vi},然后在令牌维上将它们切成 { Q i : n } \{Q_{i}^{:n}\} {Qi:n}, { K i : n } \{K_{i}^{:n}\} {Ki:n}和 { V i : n } \{V_{i}^{:n}\} {Vi:n},其中 Q i : n ~ , K i : n , V i : n ∈ R C × d h e a d Q_{i}^{:\tilde{n}},K_{i}^{:n},{V}_{i}^{:n}\in\mathbb{R}^{C\times d_{\mathrm{head}}} Qi:n~,Ki:n,Vi:n∈RC×dhead, n = 1,2,…, n + 1。由于协变量的潜在高维问题,香草方法可能会遭受计算开销和过拟合。以交通数据集(PeMS)为例,该数据集包含862个协变量。当将回看窗口大小设置为96时,对通道的关注将需要至少80倍于对令牌的关注的计算成本。充分的关注也会将大量的噪声模式合并到输出标记中,从而导致最终预测结果中的伪相关。在本文中,我们考虑使用动态投影技术(Zhu et al., 2021)将令牌“汇总”到第n个令牌维度的 K i : n K_{i}^{:n} Ki:n和 V i : n V_{i}^{:n} Vi:n,如图2所示。我们首先使用MLP层 F p k F_{pk} Fpk和 F p v F_{pv} Fpv将头部尺寸从头部投影到r≪C的某个固定r,然后我们使用softmax将投影张量 P k : n \boldsymbol{P}_{k}^{:n} Pk:n和 P v : n \boldsymbol{P}_{v}^{:n} Pv:n归一化如下:
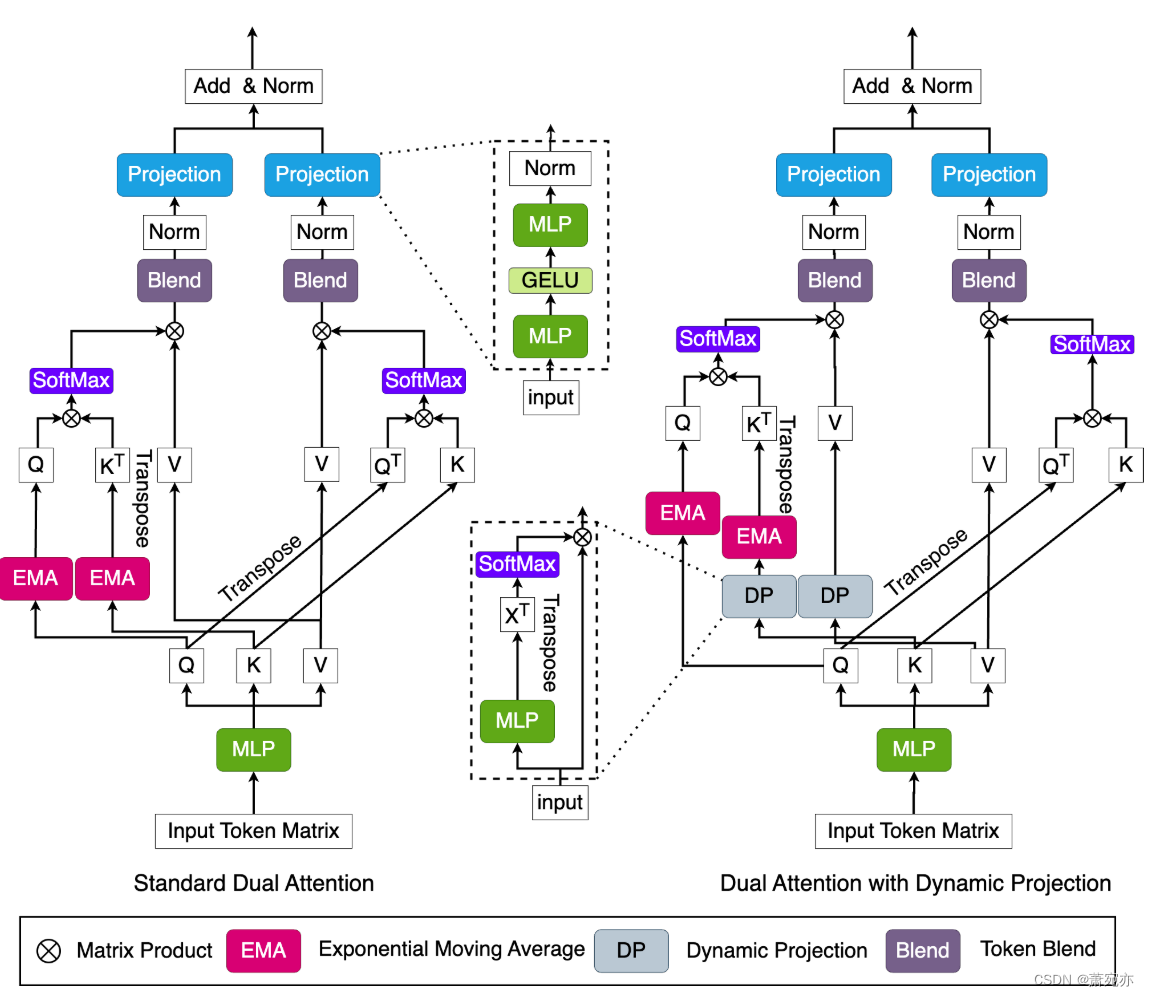
图2:CARD注意块的体系结构。
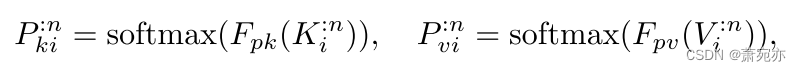
式中
P
k
i
:
n
,
P
v
i
:
n
∈
R
C
×
r
P_{ki}^{:n},P_{vi}^{:n}\in\mathbb{R}^{C\times r}
Pki:n,Pvi:n∈RC×r。接下来,“汇总”令牌由
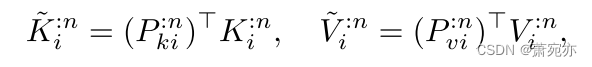
式中
K
~
i
:
n
,
V
~
i
:
n
∈
R
r
×
d
h
e
a
d
\tilde{K}_{i}^{:n},\tilde{V}_{i}^{:n}\in\mathbb{R}^{r\times d_{\mathrm{head}}}
K~i:n,V~i:n∈Rr×dhead。
最后,当n = 1,2,…时,将 Q i : n , K ~ i : n , V ~ : n Q_{i}^{:n},\tilde{K}_{i}^{:n}\mathrm{,}\tilde{V}^{:n} Qi:n,K~i:n,V~:n应用于(3)至(5)式生成输出。, n + 1。总计算代价的上界降为 O ( L / S ⋅ C ⋅ r ⋅ d 2 ) \mathcal{O}(L/S\cdot C\cdot r\cdot d^{2}) O(L/S⋅C⋅r⋅d2),小于标准注意力的 O ( L / S ⋅ C 2 ⋅ d 2 ) \mathcal{O}(L/S\cdot C^{2}\cdot d^{2}) O(L/S⋅C2⋅d2)代价。
3.4令牌混合模块
多尺度知识在预测任务中起着至关重要的作用,并显著提高了各种模型的性能。(例如,Xu et al., 2021;Zeng et al., 2023;Wang et al., 2023b;周等,20022b;Zhang & Yan, 2023)。这些作品大多是先将时间序列分解为季节和趋势分量,然后采用单独的结构分别处理季节和趋势分量。然而,这种方法虽然简单,但会导致更高的模型复杂度,这反过来又增加了计算成本,并容易出现过拟合问题。
在这项工作中,我们考虑使用专门设计的令牌混合机制来利用多尺度结构知识,而无需额外的计算成本。令牌混合模块通过合并同一头部内的相邻令牌来替换多头注意后的标准令牌重建,以生成下一阶段的令牌。多头注意力的输出令牌张量O具有形状为C×H× (N+1)×dhead的4d。token blend模块将首先合并第二和第三维度,并将O重塑为形状为C ×H(N + 1) × dhead的三维张量。然后将第二维解耦为三维,即H(N +1)→h1 × h2 × h3,其中h1 = Hh3, h2 = N+1, h3≥1。最终输出O使用h3 ×h1 ×dhead构造令牌维度。这里我们称h3为混合尺寸。当h3 = 1时,上述操作在标准变压器中产生相同的输出。当h3≥2时,输出将首先合并同一头部内相邻的token,这将创建代表更大范围内知识的token,即更低的分辨率。随着混合大小h3的增加,同一头部中的更多标记被合并,下一阶段的注意力模块可以有更多的机会捕获长期知识。图3显示了一个示例。通过在同一头部内合并时间上相邻的令牌,生成的新令牌包含了一段较长时间内的知识。通过增加对这些标记的关注,可以更有效地探索低分辨率的知识。我们的令牌混合模块也不同于(Zhang & Yan, 2023)中的分层相邻令牌合并过程。首先,(Zhang & Yan, 2023)在令牌级别进行合并,输出的粗级令牌序列具有更高的隐藏维数和更短的序列长度。我们考虑在头部级别合并,以保持相同的输出令牌序列形状。其次,(Zhang & Yan, 2023)中的合并大小固定为2,而我们允许更灵活的配置。因此,我们实现了一种隐式结构,增强了多尺度信息的提取,而不需要额外的显式信号解纠缠过程。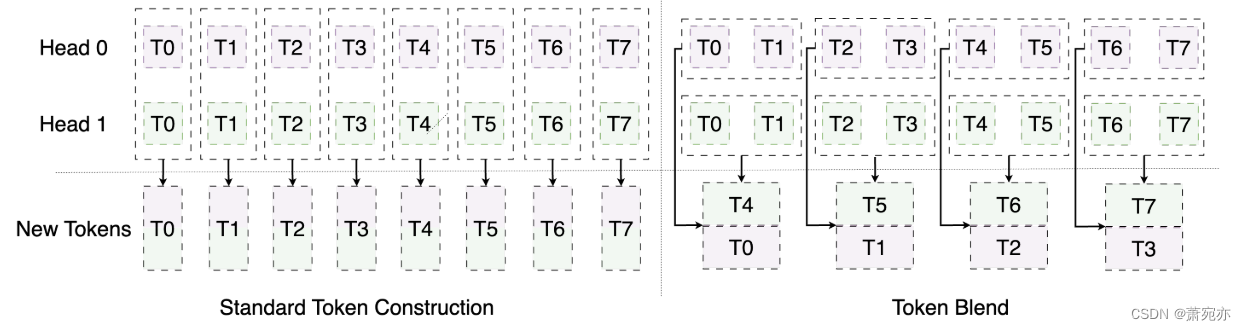
图3:CARD中令牌混合块的示例说明
四、基于信号衰减的损失函数
在本节中,我们将讨论损失函数的设计。在文献中,均方误差(MSE)损失通常用来衡量预测结果与地面真值观测值之间的差异。设
a
^
t
+
1
(
A
)
,
.
.
.
,
a
^
t
+
L
(
A
)
\hat{\boldsymbol{a}}_{t+1}(\boldsymbol{A}),...,\hat{\boldsymbol{a}}_{t+L}({\boldsymbol{A}})
a^t+1(A),...,a^t+L(A))和
a
t
+
1
(
A
)
,
.
.
.
,
a
t
+
L
(
A
)
\boldsymbol{a}_{t+1}(\boldsymbol{A}),...,\boldsymbol{a}_{t+L}(\boldsymbol{A})
at+1(A),...,at+L(A)为给定历史信息A,从t+ 1时刻到t+L时刻的预测值和实际观测值,总体客观损失变为:
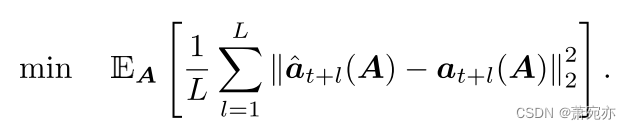
简单的MSE损失预测任务的一个缺点是,不同的时间步长误差的加权是相等的。在实际应用中,历史信息与远未来观测值的相关性通常小于与近未来观测值的相关性,这意味着远未来观测值具有更高的方差。因此,近期损失比远期损失对泛化改进的贡献更大。为了说明这一点,我们假设我们的时间序列遵循一阶马尔可夫过程,即
a
t
+
1
∼
N
(
G
(
a
t
)
,
σ
2
I
)
\boldsymbol{a}_{t+1}\sim\mathcal{N}(G(\boldsymbol{a}_{t}),\sigma^{2}I)
at+1∼N(G(at),σ2I),其中G是具有Lipschitz常数1,σ > 0和t = 1,2, …的平滑过渡函数然后,我们有
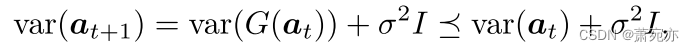
其中var(a)表示a的协方差矩阵。通过递归地使用式(9)从t + L到t,对于所有
l
∈
[
t
,
t
+
L
]
l\in[t,t+L]
l∈[t,t+L],我们有
当
a
t
a_{t}
at已经被观测到时,我们有var(at) = 0,公式(10)暗示
v
a
r
(
a
t
+
l
)
⪯
l
σ
2
I
.
\mathrm{var}(\boldsymbol{a}_{t+l})\preceq l\sigma^{2}I.
var(at+l)⪯lσ2I.。如果我们在高斯分布上使用负对数似然估计,我们会得到以下近似损失函数:
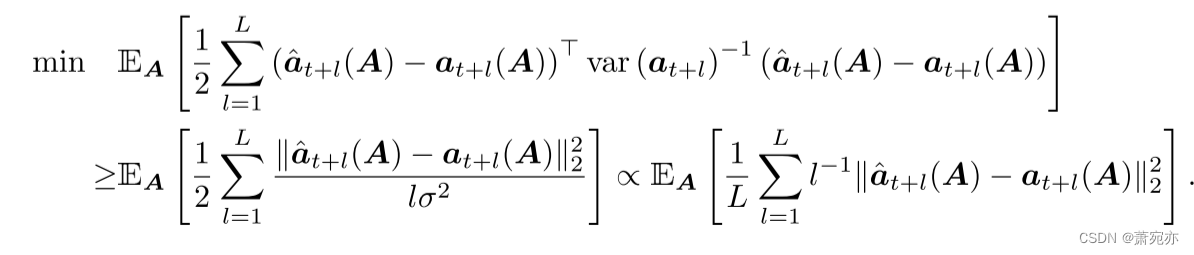
将式(11)与式(8)比较,远期损失按比例缩小,以解决高方差问题。由于平均绝对误差(MAE)比平方误差对离群值更有弹性,我们建议以以下形式使用损失函数: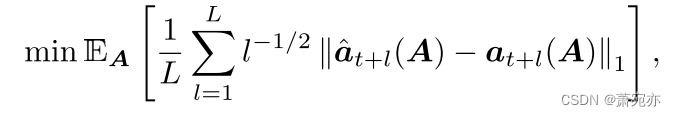
式(11)将高斯分布替换为拉普拉斯分布,可得式(12)。
五、实验
5.1长期预测
数据集 我们在七个现实世界的基准上进行了实验,包括四个电力转换温度(ETT)数据集(Zhou et al., 2021),其中包括两个小时和两个15分钟数据集,一个10分钟天气预报数据集(Wetterstation),一个小时电力消耗数据集(UCI),一个小时电力消耗数据集(weterstation)。以及每小时交通道路占用率数据集(PeMS)。
基线和实验设置 我们使用以下最近流行的模型作为基线:FEDformer (Zhou et al., 2022b)、etformer (Woo et al., 2022b)、FilM (Zhou et al., 2022a)、LightTS (Zhang et al., 2022)、MICN (Wang et al., 2023b)、TimesNet (Wu et al., 2023b)、Dlinear (Zeng et al., 2023)、Crossformer (Zhang & Yan, 2023)和PatchTST (Nie等,2023)。我们使用(Wu et al., 2023b)中的实验设置,应用可逆实例归一化(RevIN, Kim et al., 2022)来处理数据异质性,并将回看长度保持为96以进行公平比较。每个设置重复10次,报告平均MSE/MAE结果。完整结果总结在附录的表8中。关于模型配置和模型代码的更多细节可以分别在附录C和附录D中找到。
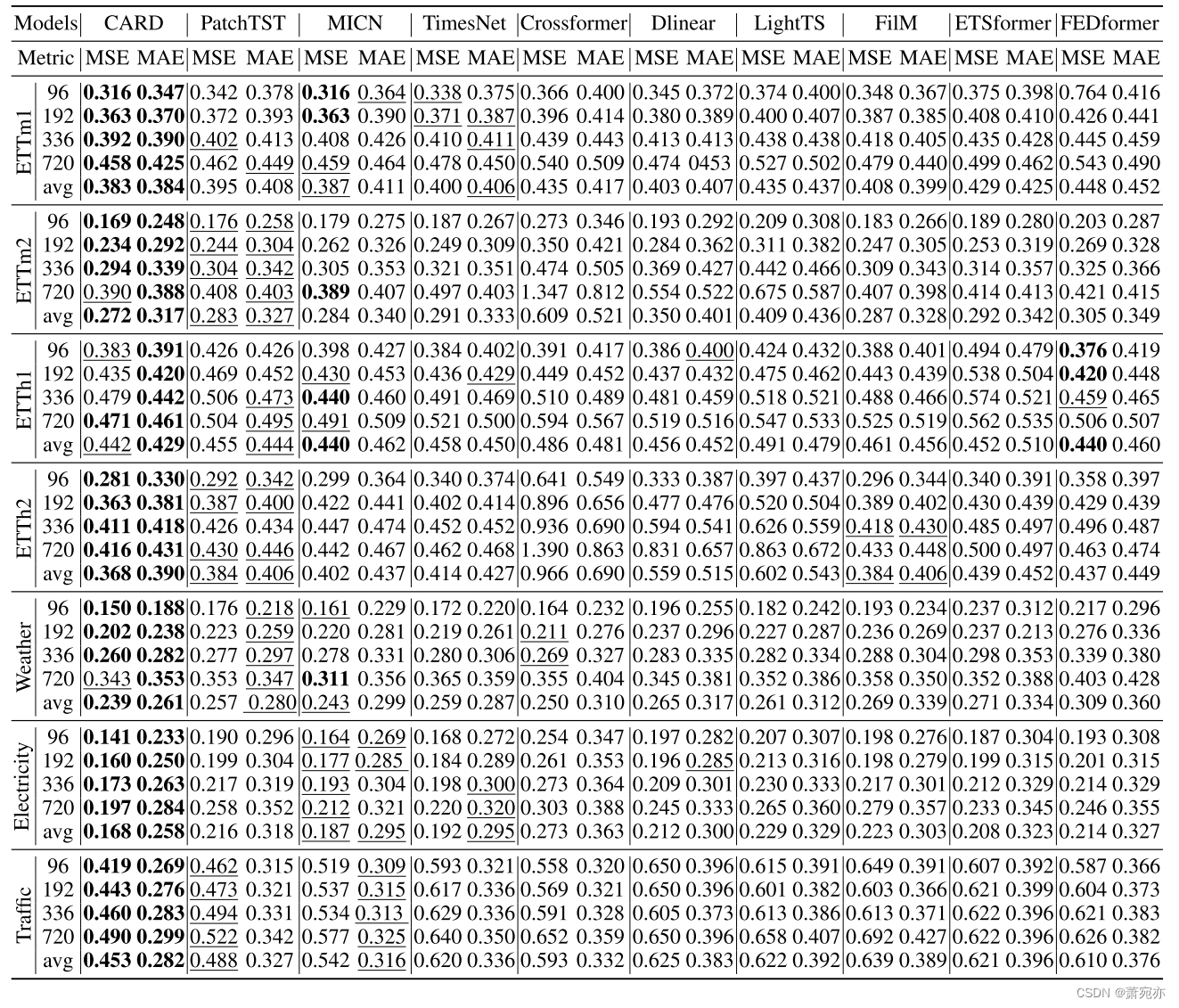
结果 总结如表1所示。关于四个不同产出水平的平均表现,CARD在MSE和MAE的7分中分别获得6分和7分的最佳表现。在单长度实验中,CARD在MSE度量中达到82%的最佳结果,在MAE度量中达到100%的最佳结果。
对于复杂协变量结构的问题,所提出的CARD方法明显优于基准。例如,在电力(321个协变量)中,CARD在每个预测水平实验中平均降低了9.0%以上的MSE/MAE,从而始终优于次优算法。通过利用21个天气协变量和862个交通协变量,我们实现了MSE/MAE的大幅降低,降低幅度超过7.5%。这突出了CARD在整合广泛协变量信息以改进预测结果方面的卓越能力。此外,Crossformer (Zhang & Yan, 2023)采用了整合跨通道数据的类似概念来提高预测精度。值得注意的是,与Crossformer相比,CARD在6个基准数据集上显著降低了超过20%的MSE/MAE,这表明我们的注意力设计在利用跨通道信息方面更加有效。同样重要的是要注意,虽然Dlinear在使用基于mlp的模型的任务中表现出强大的性能,但CARD仍然在所有基准数据集中始终将MSE/MAE降低5%至27.5%。
最近的作品,如(Zeng et al., 2023;Nie et al., 2023)的研究表明,增加回溯长度可以提高性能。在我们的研究中,我们还在附录F中报告了具有较长回溯长度的CARD的数值性能,并且在延长输入序列时,CARD也始终优于所有基线模型,在所有基准数据集中显示出显着降低的MSE误差。
5.2 m4短期预测
M4数据集(Makridakis et al., 2018)包含100k个时间序列。它涵盖了商业、金融和经济等各个领域的时间序列数据,采样频率从每小时到每年不等。我们遵循(Wu et al., 2023b)中建议的测试设置。有关数据集、训练过程和基线模型的详细信息可在附录B中找到。
结果总结在表2中。我们提出的模型在所有任务中始终优于基准测试。具体来说,我们比最先进的基于mlp的N-BEATS方法(Oreshkin et al., 2020)在SMAPE减少方面高出1.8%。我们还分别比基于变压器的最佳方法PatchTST (Nie et al., 2023)和基于cnn的最佳方法TimesNet (Wu et al., 2023b)在SMAPE减少方面分别高出1.5%和2.2%。由于M4数据集只包含单变量时间序列,我们模型中对通道的关注在这里起着非常有限的作用。因此,良好的数值性能表明,注意隐藏维度和标记混合的CARD设计在单变量时间序列场景下也是有效的,可以显著提高预测性能。
表1:长期预测任务。回溯长度设置为96。在4个不同的预测层{96、192、336、720}上对所有模型进行了评价,并报告了10次重复的平均MSE/MAE结果。最好的模型用黑体字表示,第二好的模型用下划线表示。
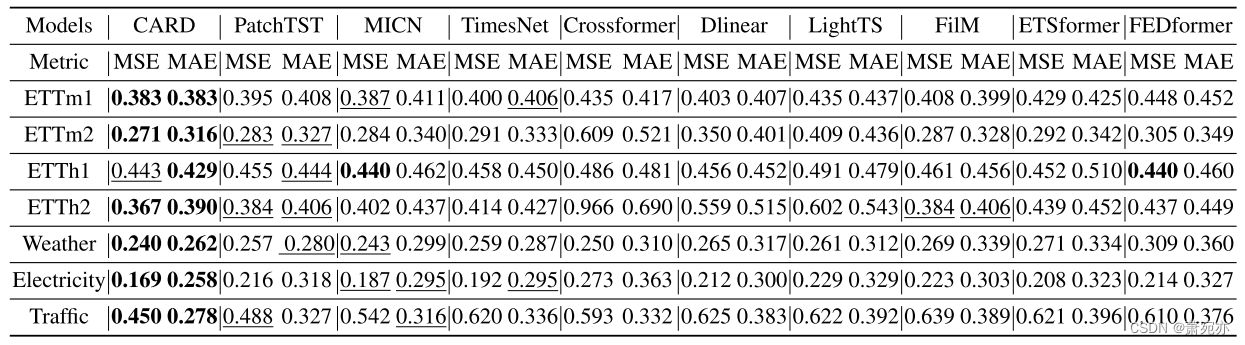
表2:M4数据集上的短期预测任务。报道了10次重复的平均结果。最好的模型用黑体字表示,第二好的模型用下划线表示。
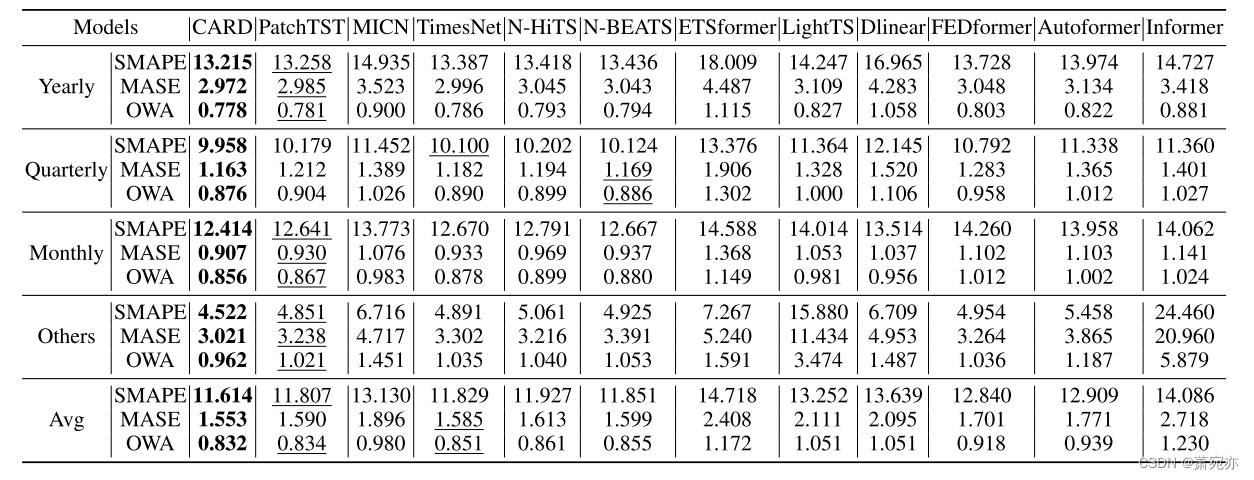
5.3基于重构的异常检测
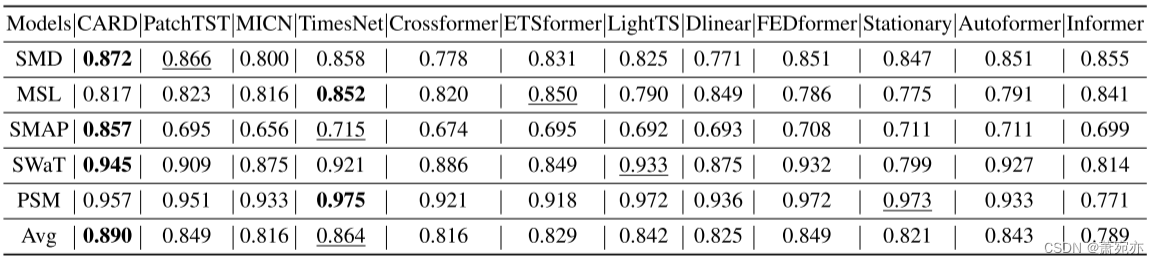
基于重构的异常检测可以看作是预测输入本身的任务。在以往的研究中,重构是无监督点表示学习的经典任务,重构误差是一个自然的异常准则。我们遵循(Wu et al., 2023a)中的实验设置,并考虑五种广泛使用的异常检测基准。结果总结在表3中。CARD在F1得分上比现有最佳成绩平均高出3%。特别是CARD在SMAP任务上实现了14.2%的显著提升。这些事实表明CARD可以在时间序列上产生有意义的表示。
表3:异常检测。F1成绩报告。最好的模型用黑体字表示,第二好的模型用下划线表示。
5.4基于信号衰减的损失函数的增强效果
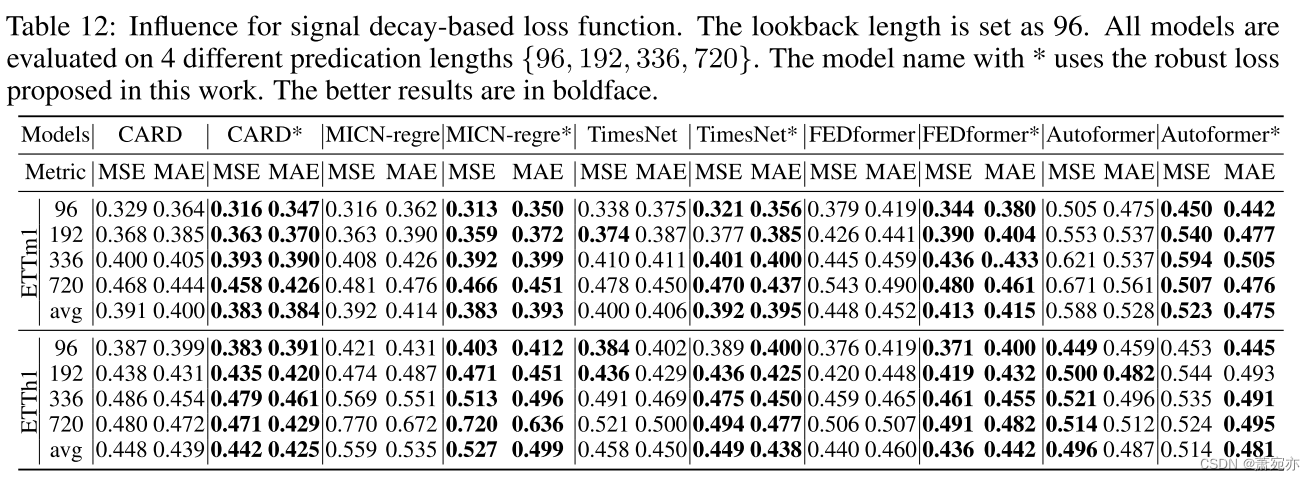
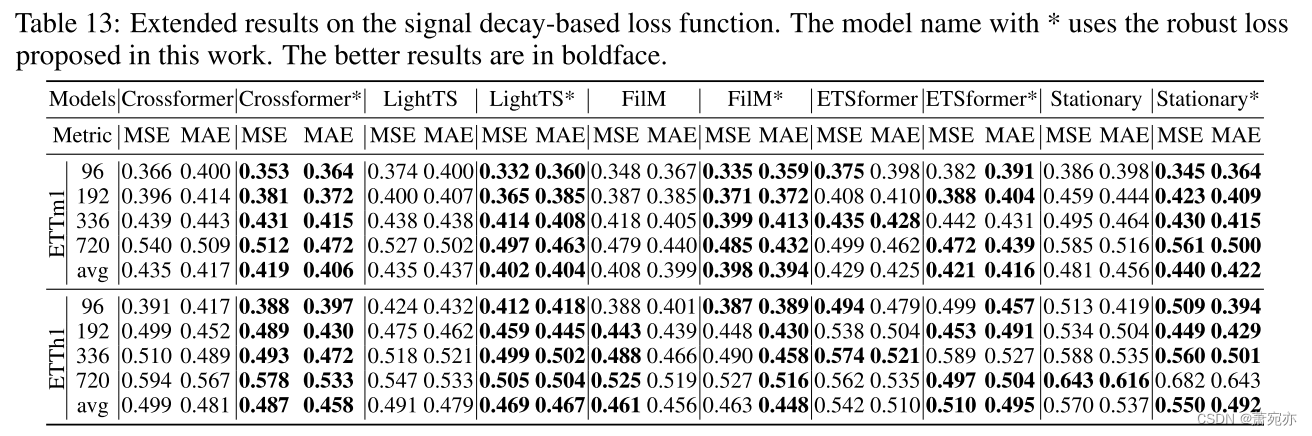
在本节中,我们介绍了我们提出的基于信号衰减的损失函数的增强效果。与之前长期序列预测模型训练中广泛使用的MSE损失函数相比,我们的方法在最新的最先进的基线模型(包括Transformer、CNN和MLP架构)中产生了3%到12%的MSE降低,如表4所示。我们提出的损失函数特别支持FEDformer和Autoformer这两种严重依赖频域信息的算法。这与我们的信号衰减范式一致,该范式承认频率信息在时间范围内携带方差/噪声。我们的新损失函数可以被认为是这项任务的首选,因为它比普通的MSE损失函数性能更好。更详细的讨论推迟到附录的H节。
表4:对信号衰减损失函数的影响。回溯长度设置为96。所有模型在4种不同的预测长度{96,192,336,720}上进行评估。报告平均结果,完整的表推迟到附录中的表12。带*的模型名称使用了本文提出的鲁棒损失。较好的结果用黑体字显示。

5.5令牌混合尺寸的影响
在本节中,我们通过改变混合大小来测试令牌混合模块的效果。结果总结在图4中。当将混合大小设置为1时,令牌混合模块减少到Transformer文献中的标准令牌混合方法,并且我们观察到MSE/MAE中的测试误差增加。在使用较大的混合尺寸时,利用了多尺度信息,从而减小了误差。然而,在某些情况下,进一步增加共混尺寸可能会损害性能。我们推测,由于数据集的性质,只有一些知识尺度对预测有用。更高的混合尺寸可能会使知识变得平滑。

图4:token混合尺寸的实验。混合大小在1、2、4、8和16中变化。
5.6其他实验
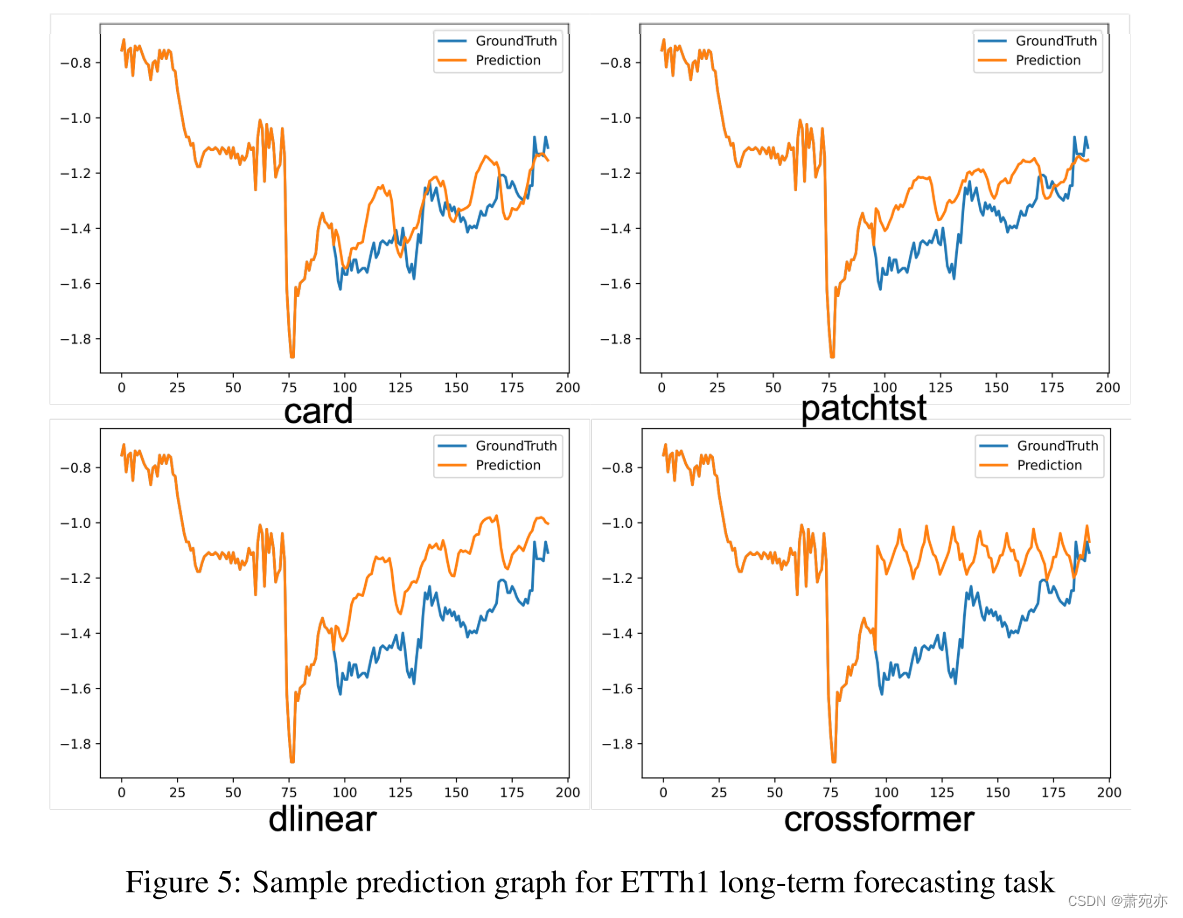
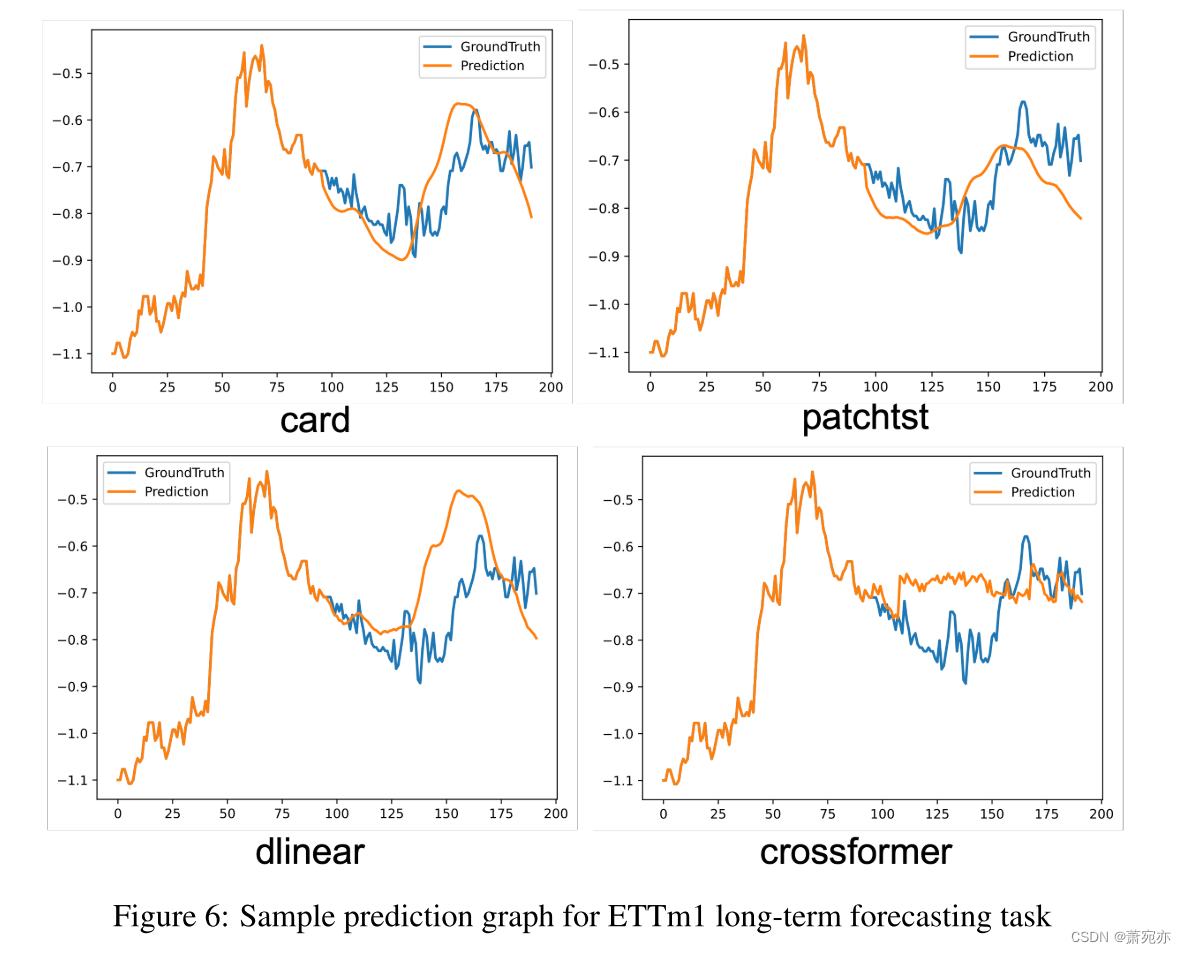
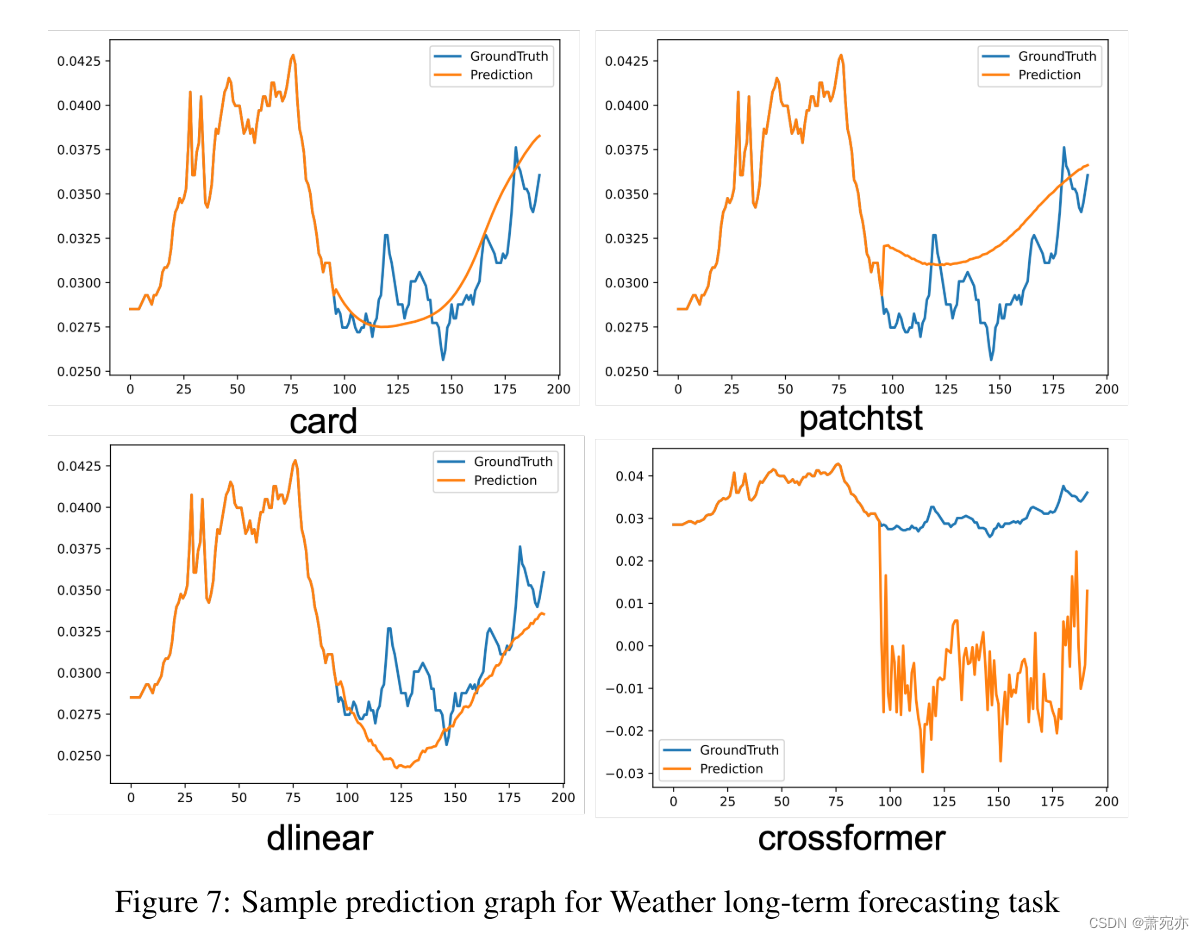
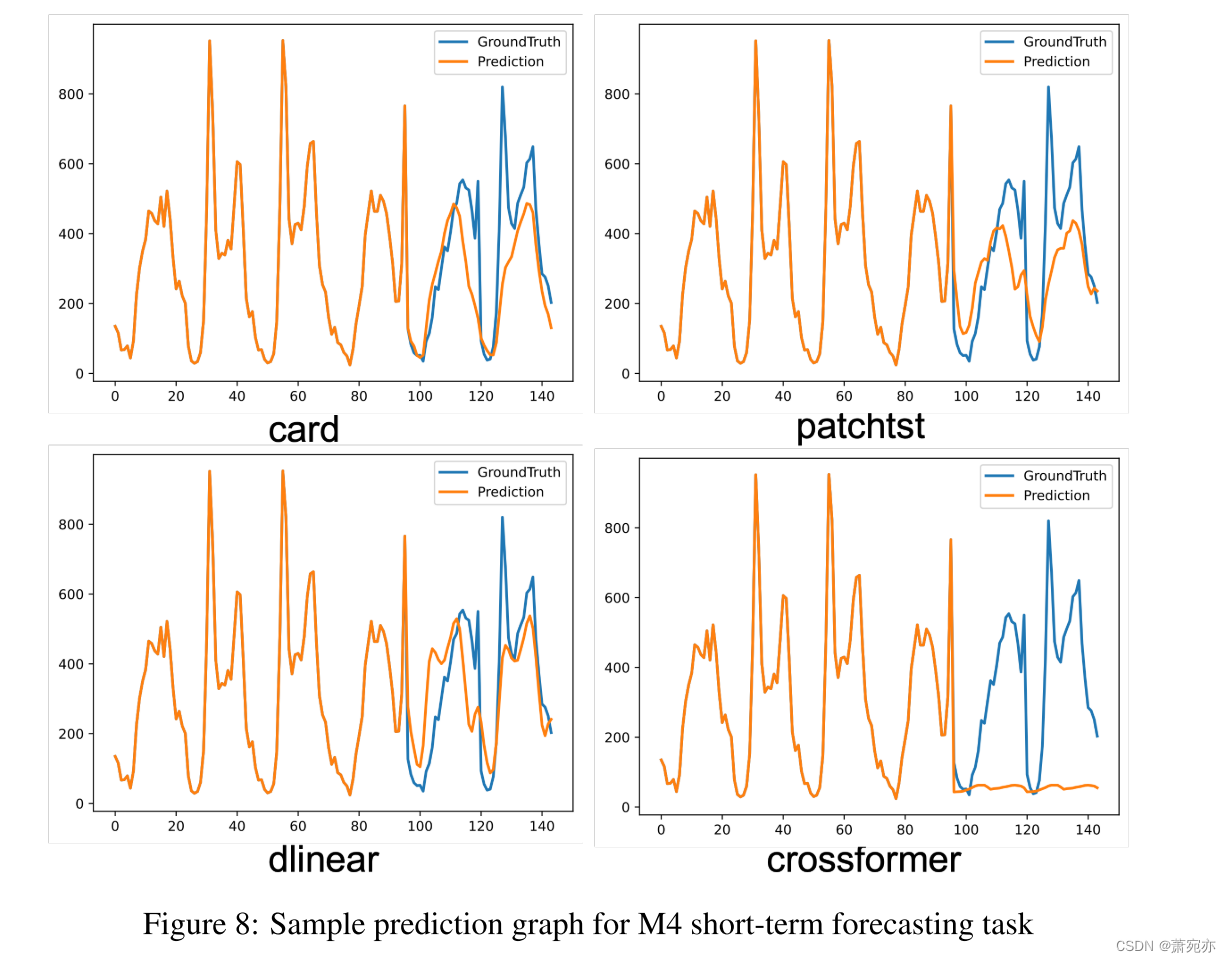
我们进行了一系列实验,使用消融和架构变体来评估我们提出的模型中的每个组件。我们的研究结果表明,信道分支对减小mse误差的贡献最大,如附录N.2所示。此外,我们对顺序/并行注意力混合设计的实验(详见附录N.1)表明,我们的模型设计是首选方案。在附录A和L中可以找到视觉辅助工具和注意图,它们有效地展示了我们对协变量信息的准确预测和利用。另一个值得注意的实验,关于训练数据大小的影响,在附录O.1中给出。该研究表明,对于受分布变化影响的一半数据集,使用70%的训练样本可以显著提高性能。此外,附录J给出了误差条统计表,说明CARD的稳健性。
六、结论与未来工作
在本文中,我们提出了一种新的Transformer模型CARD,用于时间序列预测。CARD是一种依赖于通道的模型,可以有效地跨不同变量和隐藏维度对齐信息。CARD通过同时关注令牌和通道来改进传统的变压器。注意机制的新设计有助于探索每个令牌中的本地信息,使其更有效地进行时间序列预测。我们还提出了一个令牌混合模块来利用时间序列中的多尺度信息知识。此外,我们引入了一个鲁棒损失函数来缓解过拟合噪声的问题,这是时间序列分析中的一个重要问题。正如通过各种数值基准所证明的那样,我们提出的模型优于最先进的模型。
A VISUALIZATION
B数据集
表5总结了长期预测数据的统计细节
M4短期预测数据集 每个实验重复10次,报告对称平均绝对百分比误差(SMAPE)、平均绝对比例误差(MASE)和总加权平均值(OWA)的平均值。我们使用N-BEATS (Oreshkin等人,2020)、N-HiTS (Challu等人,2022)、Informer (Zhou等人,2021)、Autoformer (Wu等人,2021)和7条长期预测基线对模型进行基准测试。表6总结了短期预测M4数据集的统计细节。
C模型配置
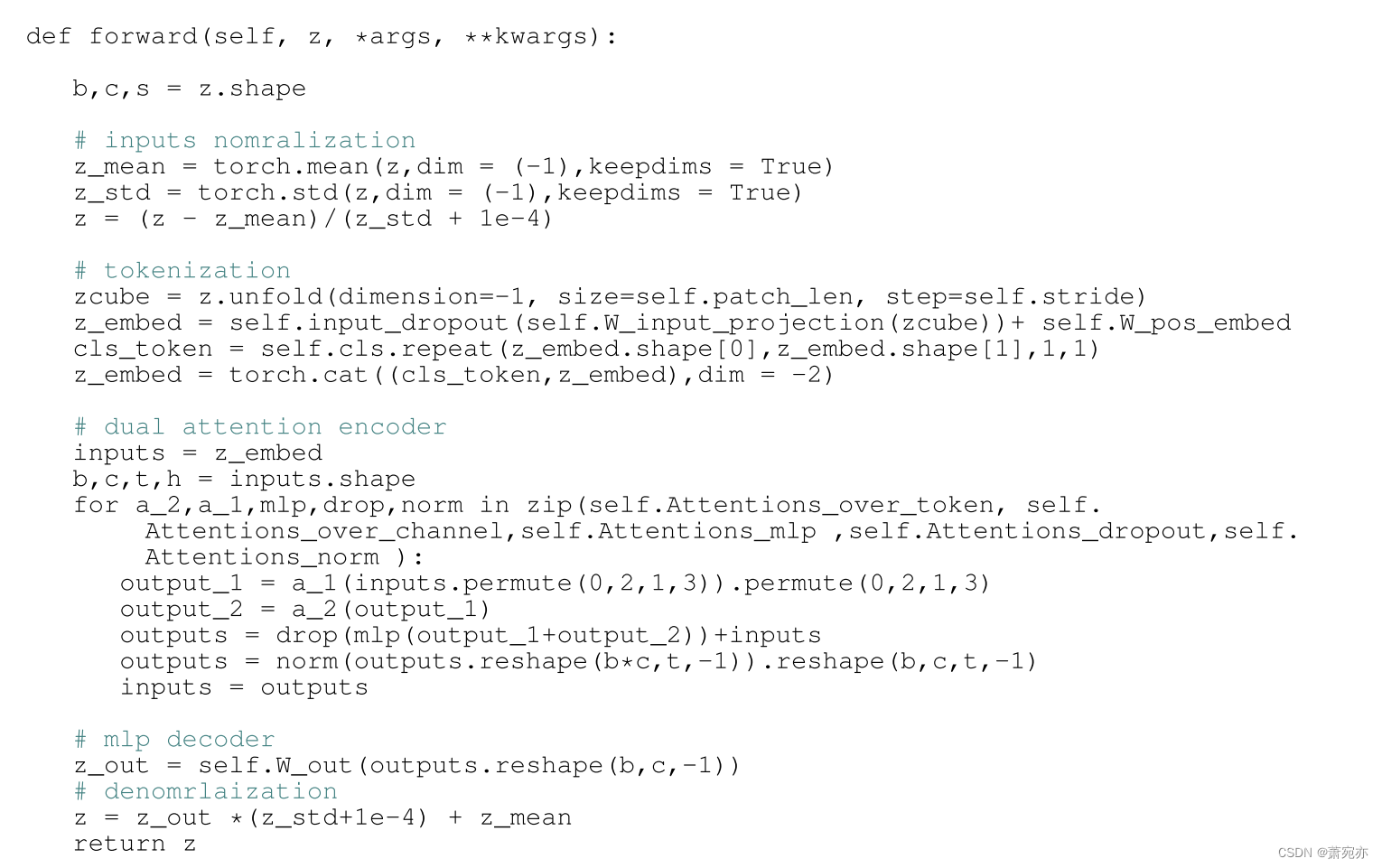
对于所有实验,我们使用可逆实例归一化(RevIN, Kim et al., 2022)来处理数据异质性。正如(Olivares et al., 2023)和(Salinas et al., 2020)所建议的,当数据具有某些模式时,其他标准化方法也很有用。我们希望将对它们的详细分析推迟到未来的研究中。此外,采用线性热身后余弦学习率衰减的Adam优化器(Kingma & Ba, 2017)作为训练方案。我们使用最多8个NVIDIA Tesla V100 sxm2 -16 gb gpu来训练所提出的模型。在所有实验中,我们将编码器块数、头部尺寸和动态投影尺寸分别固定为2、8和8。训练历元设置为100。默认批处理大小为128,并根据GPU内存限制进行调整。表7总结了配置的其他细节。
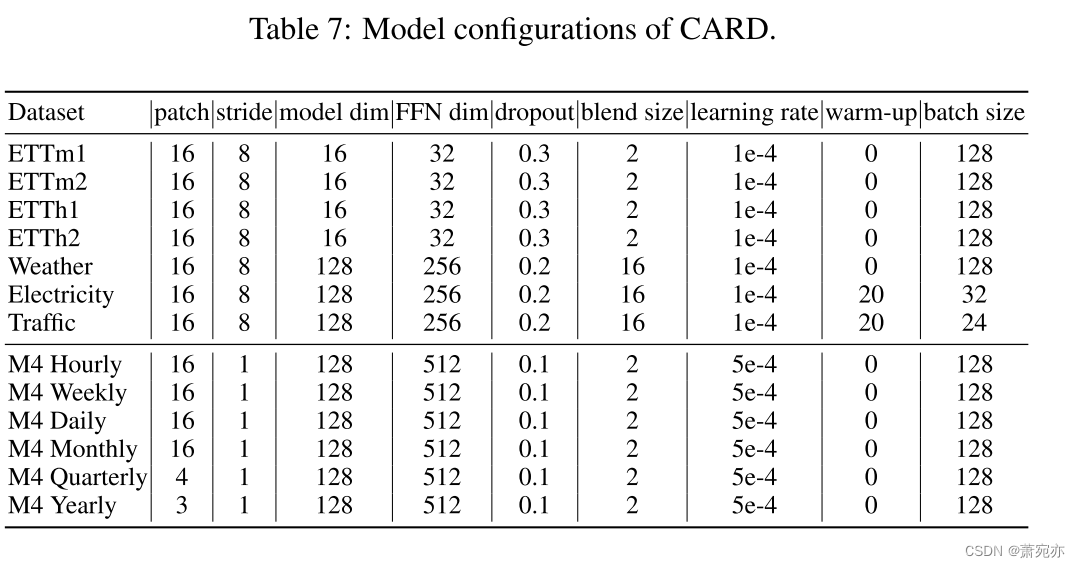
D CARD的体系结构和关键部件的源代码

E 以96个输入长度对卡在长期预报中的数值结果进行了推广
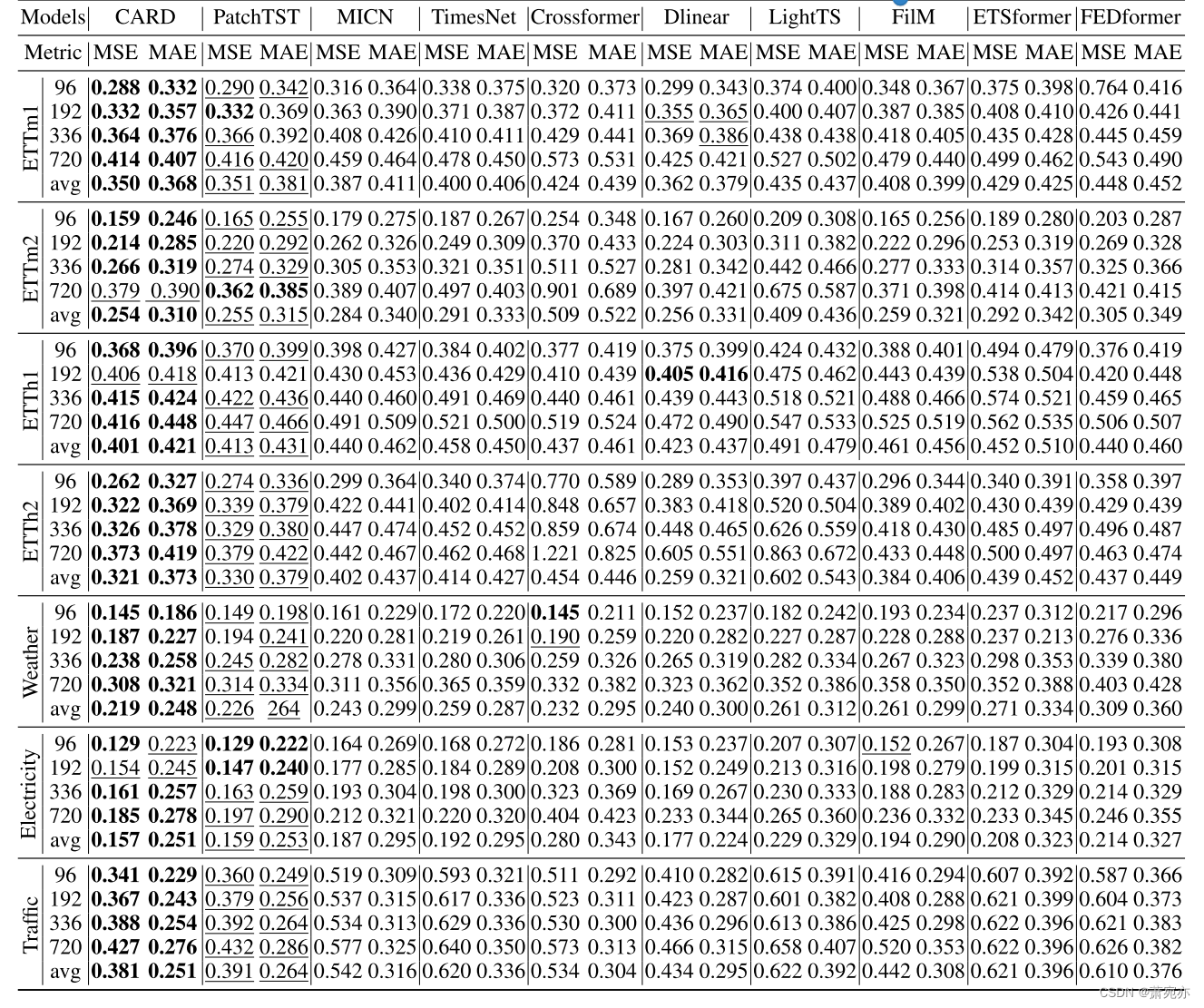
我们使用以下最近流行的模型作为基线:FEDformer (Zhou等人,2022b)、ETSformer (Woo等人,2022b)、FilM (Zhou等人,2022a)、LightTS (Zhang等人,2022)、MICN (Wang等人,2023b)、TimesNet (Wu等人,2023b)、Dlinear (Zeng等人,2023)、Crossformer (Zhang等人,2023)和PatchTST (Nie等人,2023)。我们使用(Wu et al., 2023b)中的实验设置,应用可逆实例归一化(RevIN, Kim et al., 2022)来处理数据异质性,并将回看长度保持为96以进行公平比较。每个设置重复10次,报告平均MSE/MAE结果。
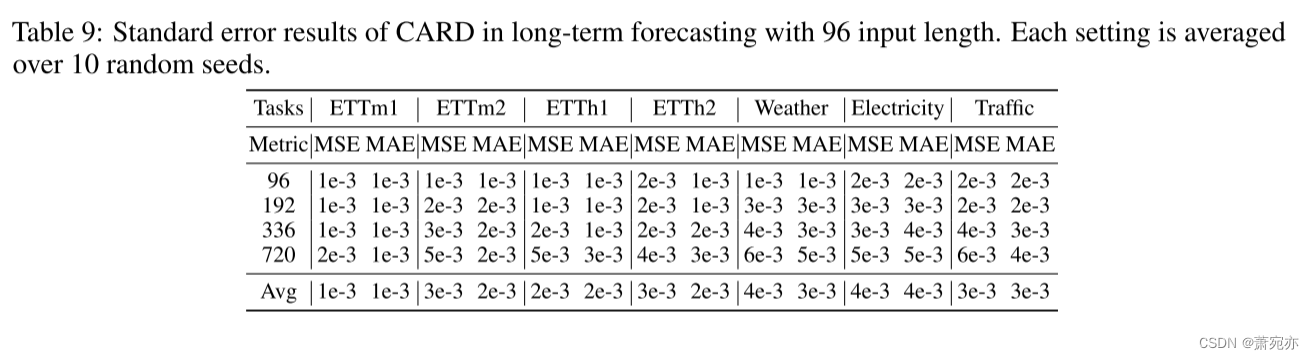
在本节中,我们报告5.1节中长期预测实验的全部结果。MSE/MAE结果汇总于表8,标准误差报告于表9。CARD在MSE中取得了23/28的最佳成绩,在MAE中取得了所有的最佳成绩。这意味着CARD可以在广泛的预测范围内改善基线。CARD的标准差在1e-3量级,说明我们提出的框架是非常稳健的。自变换器(Xu et al., 2021)、非平稳变压器(Liu et al., 2022b)、Pyraformer (Liu et al., 2022a)、LogTrans (Li et al., 2019b)和Informer (Zhou et al., 2021)等更多基线可以在(Wu et al., 2023b)的表2和表13中找到。CARD在所有预测范围内始终优于这些模型,为了简洁起见,我们省略了它们。
表8:长期预测任务。回溯长度设置为96。所有模型都在4个不同的预测层{96,192,336,720}上进行了评估。最好的模型用黑体字表示,第二好的模型用下划线表示。
F通过改变输入长度在所有基准数据集上进行实验,以获得基线文献中报告的最佳结果
在本节中,我们报告具有720输入长度的建议模型。我们遵循(Nie et al., 2023)中使用的实验设置。对于每个基准,我们报告文献中最好的结果,或者对输入长度进行网格搜索,以建立强大的基线。在单长度实验中,CARD在MSE度量中达到89%的最佳结果,在MAE度量中达到86%。就平均性能而言,CARD在所有七个数据集中都达到了最佳结果。
表10:长期预测任务。所有模型在4种不同的预测长度{96,192,336,720}上进行评估。最好的模型用黑体字表示,第二好的模型用下划线表示。
G扩展了m4短期预测结果
标准误差如表11所示。由于SAMPE得分未归一化,我们观察到其绝对值在1e-2量级,而MASE和OWA保持在1e-3量级,这与长期预测实验相同。将SAMPE用相应的均值归一化后,SMAPE的标准误差也会减小到1e-3的量级。表11:CARD在M4短期预测中的标准误差结果。用相应的平均值归一化的结果在括号中报告。每个设置平均超过10个随机种子。
H基于信号的损失函数的扩展结果
5.4节实验的全部结果见表12和表13。此外,我们还进行了切换到第4节中考虑的两种形式以外的衰减函数的实验。结果总结在表14中。在表14中,我们考虑以下衰减函数:f(t) = t−1/4,f(t) = t−1/3,f(t) = t−1,f(t) = t−2,f(t) = t−3。在ETTm1任务中,我们发现f(t) = t - 1/4和f(t) = t - 1/3的衰减函数给出了类似的MSE性能,并且与平方根衰减相比,平均MAE性能略差(差0.001)。在ETTh1任务中,f(t) = t−1/4,f(t) = t−1/3,f(t) = t−1与平方根衰变相同。在实践中,我们认为,当无法获得关于数据集的进一步信息/假设时,不“衰减”快于f(t) = t - 1的函数可能是候选选择。对于缓慢衰减的函数(例如,f(t) = t - 1/4和f(t) = t - 1/3),当它接近平方根衰减时,在单个任务中可以观察到轻微的性能改善。这表明所提出的损失对于慢衰减函数具有鲁棒性。
我们还提供了一个实例来说明所提出的基于信号的损失函数的合理性。我们考虑一个1D自回归模型xt+1 = βtruext + ϵt,其中ϵt ~ N(0,1), βtrue∈(0,1),|xt|≤1。我们想用xt来预测xt+1和xt+2。简单的损失函数如下:
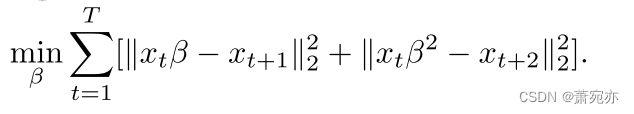
















 7757
7757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









