





系列文章目录
PatchAD:用于时间序列异常检测的基于补丁的 MLP 混合器
文章目录
摘要
异常检测是时间序列分析的一个重要方面,旨在识别时间序列样本中的异常事件。这项任务的核心挑战在于有效学习缺少标签的场景中正常和异常模式的表示。以前的研究主要依赖于基于重建的方法,限制了模型的表征能力。此外,目前大多数基于深度学习的方法都不够轻量级,这促使我们设计更高效的异常检测框架。在本研究中,我们介绍了 PatchAD,这是一种新颖的基于多尺度补丁的 MLP-Mixer 架构,它利用对比学习进行表征提取和异常检测。具体来说,PatchAD 由四个不同的 MLP Mixer 组成,专门利用 MLP 架构来实现高效率和轻量级架构。此外,我们还创新地设计了双项目约束模块,以减轻潜在的模型退化。综合实验表明,PatchAD 在多个现实世界的多元时间序列数据集上取得了最先进的结果。我们的代码是公开的。
提示:以下是本篇文章正文内容
一、介绍
时间序列异常检测是数据分析的关键方面,专注于识别时间序列数据中明显偏离正常行为的异常模式 [Belay et al., 2023; Choi 等人,2021]。这个过程在多元时间异常检测中变得更加复杂,其中涉及多个通道维度。在大规模传感技术快速发展和数据存储能力增强的推动下,时间异常检测在各个领域得到了广泛应用。例如,在物联网(IoT)领域,它用于监控传感器数据中的异常事件[Yang et al., 2021]。在医疗保健领域,它在监测人的生理数据方面发挥着至关重要的作用,从而有助于及早发现健康问题[Cook et al., 2020]。
然而,从广泛而复杂的时态数据中提取异常现象面临着巨大的挑战。首先,由于现实世界异常的多样性和不断发展的性质,准确定义异常的表示是很困难的。例如,在不同情况下,机械异常可能表现为高温或波动。其次,时间序列数据中的异常事件的标签可能不存在或难以获取。第三,时间序列数据固有的高维性和时间依赖性是复杂的。虽然典型的方法涉及将不同的时间点分类为正常或异常,但仅依赖单个时间点通常是不可行的。
由于神经网络强大的表征能力,出现了大量基于深度学习的技术[Munir et al., 2019;张等人,2022]已被提出用于时间序列异常检测,展示了卓越的性能并吸引了研究界的极大兴趣。虽然监督和半监督方法解决了标记数据稀缺的问题,但无监督技术[Zhou et al., 2019; Su et al., 2019] 因其无需严格标签要求即可操作的能力而受到关注。虽然 [Xu et al., 2022] 设计了六种不同的异常注入方法来以自我监督的方法训练模型,但 [Carmona et al., 2021] 利用异常值暴露和混合来构建自我监督任务。
基于重建的方法作为典型和常见的无监督方法,涉及学习历史数据的表示并将在测试过程中无法准确重建的样本识别为异常[Park et al., 2018]。由于其清晰的概念和管理复杂数据表示的能力,这种方法经历了快速发展。然而,由于其强大的重建能力,这些方法擅长恢复异常数据,这对基于重建的方法提出了挑战。核心问题是这些方法无法有效地对正常数据和异常数据进行清晰的建模,从而使它们准确识别异常的能力变得复杂化。
最近,对比学习因其简单而卓越的性能而受到关注,在计算机视觉等领域被证明是有效的[Chen et al., 2020]。在时间序列异常检测中,多种方法已经开始结合对比学习来增强模型表示能力。尽管如此,这些方法往往忽视了为对比学习量身定制的网络结构的设计。它们要么没有明确地对通道间依赖关系进行建模 [Yang et al., 2023],要么仅依赖于关注时间信息的基本 MLP 或 Transformer [Zhou et al., 2022],主要考虑点级特征 [Audibert et al., 2020]。然而,训练和推理速度差、架构复杂以及缺乏轻量级功能是高性能技术的一些缺点。 [Zeng et al., 2022] 最近表明,MLP 结构也可以在时间序列任务上产生出色的性能。此外,他们忽略了对比学习中的模型退化问题,这意味着模型在训练过程中可能会退化或崩溃。
在本文中,我们提出了 PatchAD,这是一种新颖的基于 Patch 的 MLP 架构,专为时间序列异常检测而设计。 PatchAD 利用对比学习来解决时间序列异常检测的复杂性。受[Yang et al., 2023]的启发,我们假设正常时间序列点具有相似的潜在模式,表明正常时间点之间存在很强的相关性。相反,异常点很难与其他异常点或正常点建立联系。因此,正常数据在不同视图中表现出一致的表示,而异常数据则难以保持一致的表示。这一基本原则构成了我们异常检测方法的核心。
具体来说,我们引入了一种新颖的多尺度修补和嵌入方法。该方法将输入数据沿时间维度分解为不重叠的补丁,使模型能够从包含更丰富语义信息的特征中学习,超越简单的点级特征。为了解决不同的时间尺度,使用了不同的子模型,每个子模型侧重于不同的补丁大小。为了捕获时间数据表示的不同视图,我们提出了不同的补丁混合器编码器来学习补丁间、补丁内和通道间连接之间的混合关系。我们利用共享的 MixRep Mixer 来统一表示特征空间。为了防止退化,我们不仅构建了多样化的编码器,还引入了双项目约束机制来防止模型陷入过于简单的解决方案,从而大大提高了其表示能力。
我们提出的 PatchAD 的主要贡献可以总结如下:
• 新颖的PatchAD 模型采用对比学习框架进行创新构建,擅长管理多种异常类型。这是通过创建补丁间编码器和补丁内编码器来实现的,它们生成补丁间和补丁内视角。
• PatchAD 采用名为“多尺度修补和嵌入”的策略,集成了专门用 MLP 构建的多尺度子序列模块。这种设计旨在促进语义更丰富的特征的学习。
• 双项目约束机制专门设计用于对模型施加约束,降低其对简单、琐碎解决方案的敏感性,从而增强其表达能力。
• 八个数据集的综合实验结果强调了 PatchAD 的功效。这些结果凸显了其与 SOTA 时间序列异常检测方法相比的优越性能。
二、 Preliminaries
在本节中,我们对时间序列异常检测的形式表示、相关方法和对比学习进行初步阐述。这些是研究问题的基本要素,也是我们工作的动力。
2.1 问题表述
在本文中,我们考虑无监督环境下长度为 T 的多元时间序列:
X
=
(
x
1
,
x
2
,
⋯
,
x
T
)
,
(
1
)
\mathcal{X}=(x_1,x_2,\cdots,x_T),\quad\quad\quad(1)
X=(x1,x2,⋯,xT),(1)
其中 x t ∈ R C x_t\in\mathbb{R}^C xt∈RC 表示 C 维通道特征,例如来自 C 传感器或机器的数据。目标是使用 X t r a i n \mathcal{X}_{train} Xtrain训练模型,并在另一个长度为 T’ 的序列 Xtest 上提供预测 Y t e s t = ( y 1 , y 2 , ⋯ , y T ′ ) \mathcal{Y}_{test}=(y_{1},y_{2},\cdots,y_{T'}) Ytest=(y1,y2,⋯,yT′)。这里, y t y_{t} yt∈ {0, 1},其中1表示该时间点异常,0表示正常点。
2.2 时间序列异常检测
存在多种用于时间序列异常检测的方法,包括统计方法、经典机器学习方法和深度学习技术。统计方法涉及移动平均线和自回归积分移动平均线(ARIMA)模型。经典的机器学习方法包括基于分类的方法,例如一类支持向量机 (OCSVM) [Scholkopf 等人,2001] 和支持向量数据描述 (SVDD) [Tax 和 Duin,2004]。深度学习方法包括 DAGMM、OmniAnomaly [Su et al., 2019]、USAD [Audibert et al., 2020]、LSTM-VAE [Park et al., 2018] 和 DeepAnT,它们在正常数据上进行训练并检测异常通过使用重建误差进行推断。一些技术 [Kim et al., 2023]、[Chen et al., 2022] 利用了自注意力机制,并展示了有希望的检测结果。认识到基于重建的假设所带来的局限性,[Li et al., 2021a] 等研究工作引入了基于平滑度约束的序列变分自动编码器模型,而 [Xu et al., 2021] 提出了用于时间建模的先验和序列关联,两者都实现了增强的性能。
2.3 时间序列的 MLP 混合器
MLP 混合器最初被提出作为计算机视觉的一种新颖架构 [Tolstikhin et al., 2021],近年来引起了广泛关注。最近,有分析表明 MLP Mixers 可以有效处理顺序数据,并在其他领域找到应用,例如时间序列预测。具体来说,工作原理类似于 [Nie et al., 2023; Kong et al., 2023]专注于预测任务,特别是多步时间序列预测,利用 MLP 混合器的功能来实现改进的预测结果。他们的实验表明,MLP Mixer 在长序列时间序列预测 (LSTF) 方面超越了现有的基于 Transformer 和 LSTM 的方法。据我们所知,目前在时间序列异常检测中还缺乏 MLP Mixer 的应用。
2.4 对比学习
对比学习因其通过对比正负对来训练模型的能力而在各个领域引起了相当大的关注。目标是驱动模型在学习的表示空间中使正对更加靠近,同时将负对推开。此外,BYOL [Grill et al., 2020] 和 SimSiam [Chen and He, 2021] 等方法已经在无需显式构建负对的情况下展示了先进的性能。最近,[Eldele et al., 2021] 和 [Pranavan et al., 2022] 等研究探索了将对比学习整合到时间序列分析中。另一方面,[Yang et al., 2023] 将自注意力与对比学习相结合,在时间序列异常检测方面取得了最先进的结果。
三、方法
3.1 整体架构
图1说明了patchad的总体结构。PatchAD采用多个尺度的补丁大小。我们使用单一尺度来举例说明其架构。PatchAD是一个l层网络,每一层由不同的模块组成:MLP Mixers、Project head和ReWeight,形成了它的结构。我们设计了四种不同类型的MLP Mixers: Channel Mixer, Inter Mixer, Intra Mixer和MixRep Mixer,每个都致力于学习各种通道,补丁间,补丁内关系和统一的表示空间。Project head用于防止模型收敛到琐碎的解决方案,而ReWeight模块管理跨不同层的权重。
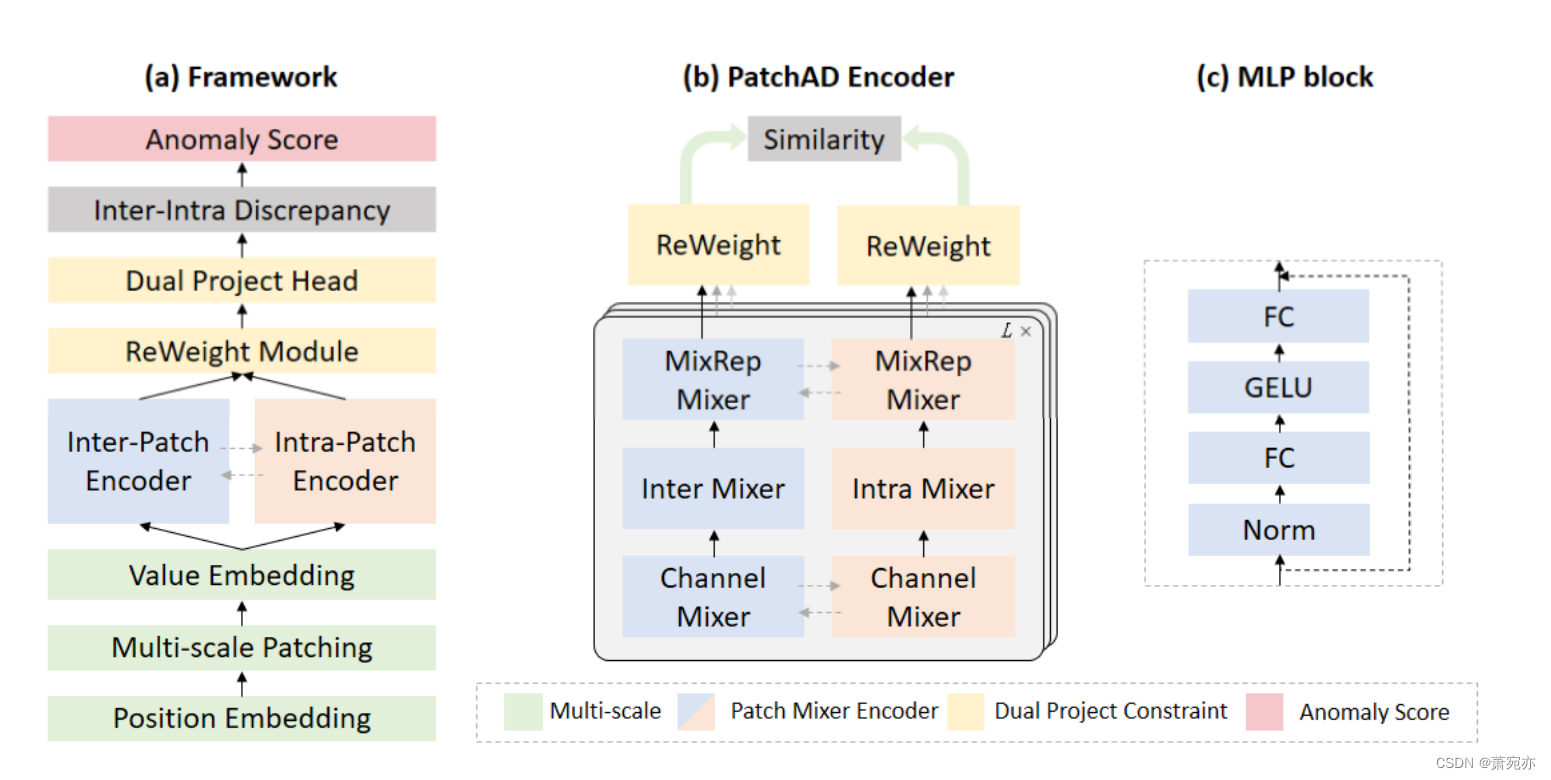
Figure 1: The workflow of the proposed PatchAD framework.
我们设计的重点在于四个不同的MLP混频器。受[Yang等人,2023]的启发,我们利用各种MLP Mixers从输入中学习不同的表示。法线点在不同的视图中共享一个共同的潜在空间,而异常,由于稀缺和缺乏特定的模式,很难与法线点共享一个连贯的表示。因此,正常点在不同的视图中表现出较小的差异,而异常点则表现出较大的差异。PatchAD利用内部差异来模拟这种关系。
3.2多尺度修补与嵌入
为了增强时间序列中的时间上下文表示,我们采用了Transformer位置编码。考虑到不同序列长度在时间序列分析中的重要性,我们在PatchAD中引入了多尺度补丁。这使得PatchAD能够专注于不同序列长度的特征。此外,融合多尺度信息有助于弥补修补过程中的信息损失。将C个通道长度为T的输入数据变换成大小为p的patch,可以看作是将时间序列数据划分为N个不重叠的patch块,称为 Patching ( ⋅ ) . \operatorname{Patching}(\cdot). Patching(⋅).。因此,将C × T维的原始数据转换为C ×N ×P。
X = P a t c h i n g ( P E ( X ) ) , X C × T → X C × N × P , ( 2 ) \mathcal{X}=\mathrm{Patching}(\mathrm{PE}(\mathcal{X})),\mathcal{X}^{C\times T}\to\mathcal{X}^{C\times N\times P},\quad(2) X=Patching(PE(X)),XC×T→XC×N×P,(2)
式中PE(·)为位置嵌入。
PatchAD采用两个值嵌入,即VE(·),从框架内两个不同的角度促进特征。VE(·)是一个单一的线性层。
X i n t e r = V E ( X ) , X C × N × P → X C × N × D , X i n t r a = V E ( X ) , X C × N × P → X C × P × D . ( 3 ) \begin{aligned}\mathcal{X}_{inter}&=\mathrm{VE}(\mathcal{X}),\mathcal{X}^{C\times N\times P}\to\mathcal{X}^{C\times N\times D},\\\mathcal{X}_{intra}&=\mathrm{VE}(\mathcal{X}),\mathcal{X}^{C\times N\times P}\to\mathcal{X}^{C\times P\times D}.\end{aligned}\quad(3) XinterXintra=VE(X),XC×N×P→XC×N×D,=VE(X),XC×N×P→XC×P×D.(3)
3.3 Patch Mixer Encoder
PatchAD由L个Patch Mixer层组成。该编码器结合了四个不同的MLP混频器,以提取跨不同维度的特征。图1©展示了我们设计的MLP模块。它由两个完全连接的层组成,一个归一化层,一个GELU非线性激活层,并利用从输入到输出的残差连接。这可以表示为:
X = F C ( G E L U ( F C ( N o r m ( X ) ) ) ) + X . ( 4 ) \mathcal{X}=\mathrm{FC}(\mathrm{GELU}(\mathrm{FC}(\mathrm{Norm}(\mathcal{X}))))+\mathcal{X}.\quad\quad(4) X=FC(GELU(FC(Norm(X))))+X.(4)
以下是PatchAD中使用的不同类型的MLP混频器:
- 通道混频器使PatchAD能够捕获不同通道之间的相关性。
- Inter Mixer使PatchAD能够捕获patch之间的表示,从而促进全局表达式的学习。
- Intra Mixer使PatchAD能够捕获patch内的表示,从而促进局部表达式的学习。
- MixRep Mixer允许PatchAD将两个不同的视图嵌入到相同的表示空间中。
如图所示,PatchAD由一个patch间编码器和一个patch内编码器组成,生成的表示为
N
∈
R
C
×
N
×
D
\mathcal{N}\in\mathbb{R}^{C\times N\times D}
N∈RC×N×D,
P
∈
R
C
×
P
×
D
\mathcal{P}~\in~\mathbb{R}^{C\times P\times D}
P ∈ RC×P×D,分别表示patch间视图和patch内视图。值得注意的是,通道混音器The Channel Mixer和MixRep混音器The
MixRep Mixer共享权重,而内部混音器The Inter Mixer和内部混音器The
Intra Mixer有自己的权重。这种设计有助于PatchAD学习视图之间的差异,防止模型退化。
3.4 Dual Project Constraint
为了防止模型收敛到琐碎的解,每一层的输出都需要受到Dual Project Head的约束。先前的研究表明,采用类似的结构可以有效地防止模型收敛到平凡的解决方案。例如,SimCLR [Chen等人,2020]使用投影头,将图像的增强视图映射到潜在空间,并在训练过程中促进更平滑的收敛。投影头包括两层MLP连接,不包括非线性层和归一化层。因此,对于patch间和patch内编码器,我们都可以推导出投影表示 N ′ ∈ R C × N × D \mathcal{N}^{\prime}\in\mathbb{R}^{C\times N\times D} N′∈RC×N×D和 P ′ ∈ R C × P × D \mathcal{P}^{\prime}\in\mathbb{R}^{C\times P\times D} P′∈RC×P×D。这个计算可以表示为:
N ′ = F C ( F C ( N ) ) , P ′ = F C ( F C ( P ) ) . ( 5 ) \mathcal{N}'=\mathrm{FC}(\mathrm{FC}(\mathcal{N})),\mathcal{P}'=\mathrm{FC}(\mathrm{FC}(\mathcal{P})).\quad(5) N′=FC(FC(N)),P′=FC(FC(P)).(5)
为了合并来自不同层的输出并防止模型退化,我们使用了一个简单的ReWeight模块来为各个层分配不同的权重。考虑L层 { N 1 , N 2 , ⋯ , N L } \{\mathcal{N}_{1},\mathcal{N}_{2},\cdots,\mathcal{N}_{L}\} {N1,N2,⋯,NL}和 { P 1 , P 2 , ⋯ , P L } , \{\mathcal{P}_{1},\mathcal{P}_{2},\cdots,\mathcal{P}_{L}\}, {P1,P2,⋯,PL},的表示,我们可以得到最终结果:
N l = α l ⋅ N l , α l = S o f t m a x ( α ) , (6) P l = β l ⋅ P l , β l = S o f t m a x ( β ) . \begin{aligned} &\mathcal{N}_{l} =\alpha_{l}\cdot\mathcal{N}_{l},\alpha_{l}=\mathrm{Softmax}(\alpha), \\ &&\text{(6)} \\ &\mathcal{P}_{l} =\beta_l\cdot\mathcal{P}_l,\beta_l=\mathrm{Softmax}(\beta). \end{aligned} Nl=αl⋅Nl,αl=Softmax(α),Pl=βl⋅Pl,βl=Softmax(β).(6)
引入ReWeight可以更好地平衡来自不同层的输出,从而提高性能。
3.5 Objective Function
补丁间编码器和补丁内编码器可以表示两种不同的视图,分别表示为N和p。为了量化这些表示之间的差异,我们利用基于Kullback-Leibler散度(KL散度)的比较损失函数,称为内部差异。考虑到数据中异常的稀缺性和共享隐藏模式的正常样本的丰富性,相似的输入应该产生相似的表示。
N和P的损失函数定义如下:
L
N
{
P
,
N
}
=
∑
K
L
(
N
,
S
t
o
p
G
r
a
d
(
P
)
)
(7)
+
KL
(
StopGrad
(
P
)
,
N
)
,
L
P
{
P
,
N
}
=
∑
K
L
(
P
,
S
t
o
p
G
r
a
d
(
N
)
)
(
8
)
+
KL
(
StopGrad
(
N
)
,
P
)
,
\begin{aligned} &\mathcal{L}_{\mathcal{N}}\{\mathcal{P},\mathcal{N}\} =\sum\mathrm{KL}(\mathcal{N},\mathrm{Stop}\mathrm{Grad}(\mathcal{P})) \\ &&&\text{(7)} \\ &+\operatorname{KL}(\operatorname{StopGrad}(\mathcal{P}),\mathcal{N}), \\ &\mathcal{L}_{\mathcal{P}}\{\mathcal{P},\mathcal{N}\} =\sum\mathrm{KL}(\mathcal{P},\mathrm{Stop}\mathrm{Grad}(\mathcal{N})) && (8) \\ &+\operatorname{KL}(\operatorname{StopGrad}(\mathcal{N}),\mathcal{P}), \end{aligned}
LN{P,N}=∑KL(N,StopGrad(P))+KL(StopGrad(P),N),LP{P,N}=∑KL(P,StopGrad(N))+KL(StopGrad(N),P),(7)(8)
式中KL(·||·)表示KL发散距离,StopGrad表示梯度停止,用于异步优化两个分支。综合损失定义为
L c o n t = L N − L P l e n ( N ) . ( 9 ) \mathcal{L}_{cont}=\frac{\mathcal{L}_{\mathcal{N}}-\mathcal{L}_{\mathcal{P}}}{len(\mathcal{N})}.\quad\quad\quad\quad\quad(9) Lcont=len(N)LN−LP.(9)
由于N和P之间的尺寸不匹配,需要对两者进行初始上采样以实现可比性。对于补丁间视图,只有补丁之间存在差异,我们在补丁内复制最终N。相反,对于显示斑块内点之间异常的斑块内视图,我们将其复制多次以获得最终p。这也解决了引入多尺度的必要性,因为它补偿了上采样期间的信息损失
为了防止模型退化,我们用来自投影头的附加约束增强原始损失函数,定义为:
L p r o j = L N ′ − L P l e n ( N ) + L N − L P ′ l e n ( N ) . ( 10 ) \mathcal{L}_{proj}=\frac{\mathcal{L}_{\mathcal{N}^{\prime}}-\mathcal{L}_{\mathcal{P}}}{len(\mathcal{N})}+\frac{\mathcal{L}_{\mathcal{N}}-\mathcal{L}_{\mathcal{P}^{\prime}}}{len(\mathcal{N})}.\quad\quad(10) Lproj=len(N)LN′−LP+len(N)LN−LP′.(10)
最终的PatchAD损失由上述两部分组成,其中有一个约束系数用来控制约束的强度:
L
=
(
1
−
c
)
⋅
L
c
o
n
t
+
c
⋅
L
p
r
o
j
.
(
11
)
\mathcal{L}=(1-c)\cdot\mathcal{L}_{cont}+c\cdot\mathcal{L}_{proj}.\quad\quad(11)
L=(1−c)⋅Lcont+c⋅Lproj.(11)
3.6 Anomaly Score
假设不同视图之间的正态点共享隐藏模式,而异常点表现出较大的差异,则可以将两视图之间的差异作为异常评分。最终异常评分可表示为:
AnomalyScore
(
X
)
=
∑
KL
(
N
,
P
)
+
KL
(
P
,
N
)
.
(
12
)
\operatorname{AnomalyScore}(\mathcal{X})=\sum\operatorname{KL}(\mathcal{N},\mathcal{P})+\operatorname{KL}(\mathcal{P},\mathcal{N}).\quad(12)
AnomalyScore(X)=∑KL(N,P)+KL(P,N).(12)
基于上述异常分数,我们设置了一个超参数σ来确定一个点是否被认为是异常。如果超过阈值,则将其标识为异常值。
y i = { 1 , AnomalyScore ( X i ) ≥ σ 0 , AnomalyScore ( X i ) < σ . (13) \left.y_i=\left\{\begin{matrix}1,\text{AnomalyScore}(\mathcal{X}_i)\geq\sigma\\0,\text{AnomalyScore}(\mathcal{X}_i)<\sigma.\end{matrix}\right.\right.\quad\text{(13)} yi={1,AnomalyScore(Xi)≥σ0,AnomalyScore(Xi)<σ.(13)
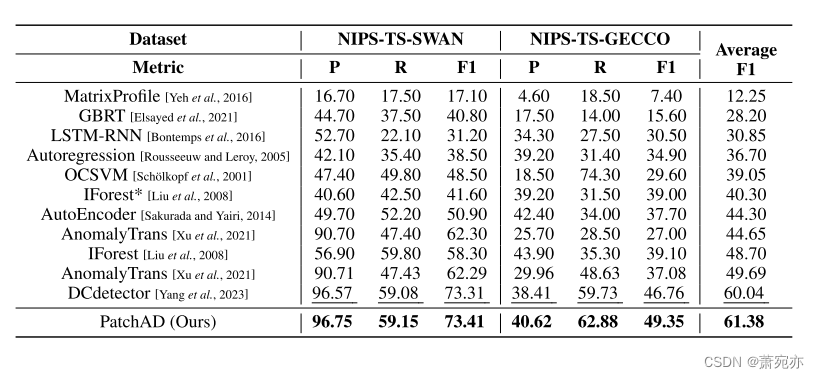
表1:四个数据集的综合比较结果。P、R和F1分别代表准确率、召回率和F1得分。所有结果以%表示,最好的用粗体表示,次优的用下划线表示。
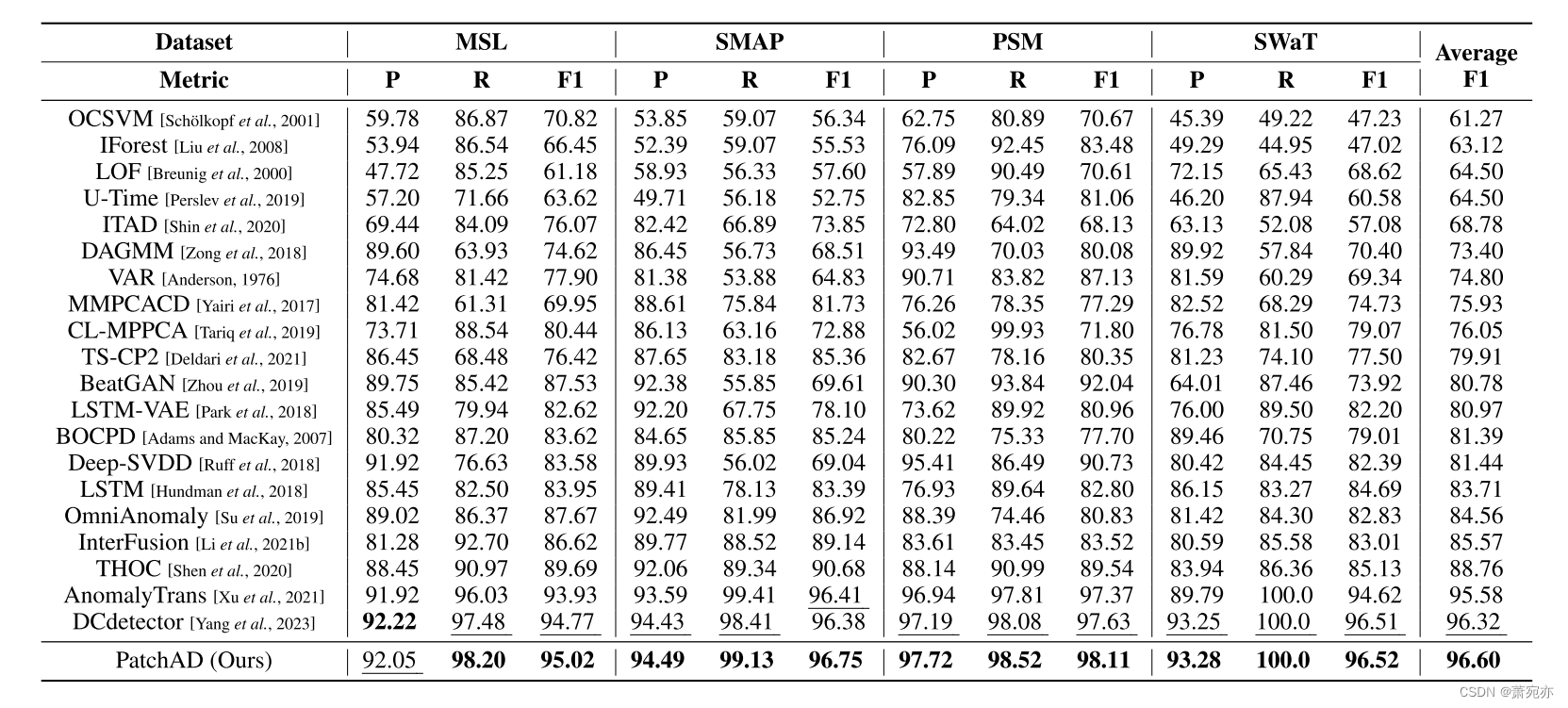
表2:NIPS-TS数据集的总体结果。所有结果以%表示,最好的用粗体表示,次优的用下划线表示。
四、实验
4.1设置和评估指标
我们应用了8个数据集进行评估:(1)MSL (2) SMAP 2(3) PSM (4) SMD 3 (5) SWaT 4 (6) WADI 5 (7) NIPS-TSSWAN (8) NIPSTS-GECCO 6。关于这些数据集的详细信息在附录的表4中列出。另外,算法1的实现和伪代码详见附录。
我们将我们的模型与27个基准模型进行了比较,包括:(1)基于重构的模型;(2)基于自回归的;(3)基于密度;(4)基于聚类;(5)经典方法;(6)变化点检测和时间序列分割方法;(7)基于变压器的方法;详见表1和表2或附录5。
此外,我们采用了各种评估指标进行评估,包括时间序列异常检测中常用的指标,如准确性、精密度、召回率和F1-score [Xu et al., 2021]。此外,我们采用了最先进的评估技术,如隶属关系精度和隶属关系召回率[Huet et al., 2022],以及表面下体积(VUS) [Paparrizos et al., 2022]。虽然f1分数是一个广泛使用的度量,但它并不能有效地评估异常事件。因此,我们引入以下两个新指标。关联精度和召回率是基于预测事件与真实标签的接近程度的评估指标。VUS通过计算接收算子特征(ROC)曲线,将异常事件纳入评估。采用各种方法可以对我们的模型进行更全面的评估。为了与其他方法进行公平的比较,我们使用了点调整技术,如果模型在段内检测到任何异常点,则识别异常段。
4.2对比结果
数据来源澄清:由于设备存在较大差异,为确保与异常变压器(AnomalyTrans)和DCdetector进行公平比较,文中提到的所有结果都是通过我们重新实现其代码获得的。表1和表2中的anomalytrans和DCdetector的结果是我们的复制。
从表1中可以看出,PatchAD达到了最佳的平均水平F1性能。据我们所知,关于时间序列异常检测的评价一直存在争议。然而,准确率、召回率和f1分数仍然是最广泛使用的评估指标。为了全面评估我们的方法的性能,引入了额外的指标,如隶属关系精度/召回率和VUS。
在表2中,NIPS-TS-SWAN和NIPS-TS-GECCO数据集代表了更具挑战性的数据集,包含了更广泛的异常类型。与其他基线方法相比,PatchAD在这两个数据集上一致地获得SOTA结果。特别值得注意的是,在NIPS-TS-GECCO数据集上,f1得分比DCdetector提高了9.3%,比Anomaly Transformer提高了24.9%。
鉴于AnomalyTrans和DCdetector的显著性能明显超过其他基线,我们使用多个指标对所有数据集的PatchAD进行了全面比较,如附录中的表5所示。与这两种SOTA方法相比,我们提出的方法优于或至少保持竞争力。PatchAD在多个数据集和多个指标上取得了卓越的结果。尽管PatchAD的网络结构相对简单,但其性能仍然具有竞争力。
4.3模型分析
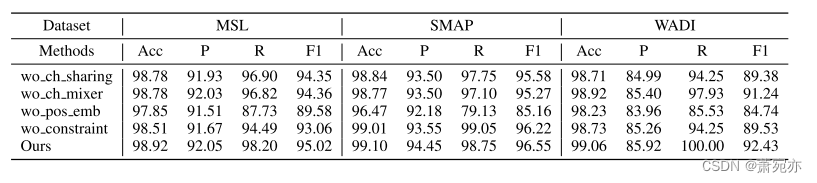
Ablation Studies消融研究
为了研究模型中不同成分的影响,我们在三个数据集上进行了烧蚀实验,如表3所示。“双向共享”方法采用两个独立的通道混频器模块来建模通道特征,而“双向混频器”表示去除通道混频器模块。这两种变量对模型学习的影响显著,尤其是在MSL和SMAP数据集上,表明通道间信息建模和通道信息共享有利于模型学习。此外,“wo pos emb”代表了一种没有位置编码的变体,去除位置编码对PatchAD的影响很大,这凸显了位置编码在PatchAD设计中的关键作用。此外,“无约束”展示了移除约束对投影头的影响。结合图4a,我们观察到,一定程度的约束有利于模型优化,从而改善了结果。这个约束防止模型收敛到平凡的解。在随后的实验中,投影头约束的默认设置为0.2。
Parameter Sensitivity 参数灵敏度
我们对PatchAD的参数进行了敏感性分析。默认参数设置与基本配置保持一致。图2a展示了投影头约束对PatchAD的影响。总的来说,它对MSL这样的小规模数据集更有意义。然而,过于强烈的约束阻碍了模型的学习过程。因此,将此约束设置在0.1到0.4之间更为可取。图2b分析了异常阈值σ在0.5 ~ 1.2范围内时PatchAD模型的最终性能。与MSL数据集相比,PSM和SMAP数据集对异常阈值的选择更加稳健。对于大多数数据集,将此值设置在0.8到1之间会产生最佳结果。图2c说明了模型的性能如何受到网络维度dmodel的影响。PatchAD在模型尺寸较小的情况下效果更好。因此,为了在模型性能和复杂性之间取得平衡,我们设置dmodel = 40,以确保PatchAD有效运行。图2d表明,PatchAD的性能受到编码器层数的影响,给出一个折衷方案,我们将其设置为3或4。图2e展示了PatchAD关于窗口大小的稳健性,窗口大小范围从60到210。时间窗口是一个关键参数,通常在大多数数据集中设置为105的初始值。最后,图2f显示了不同多尺度补丁大小组合下PatchAD的性能。结果表明,结合不同的补丁大小可以提高PatchAD的性能。

Figure 2: Parameter sensitivity studies of main hyper-parameters in PatchAD.
Table 3: Ablation experiments on MSL, SMAP, WADI datasets.
Visual Analysis
我们在图3中可视化了PatchAD对各种异常的响应。合成的单变量时间序列由[Lai等人,2021]生成,包括全球点异常、上下文点异常和模式异常,如季节性、群体和基于趋势的异常。第一行描述了原始数据,而第二行显示了PatchAD针对异常阈值的异常分数输出。特别是,PatchAD具有检测各种类型异常的能力。
Time Cost
我们在相同的实验条件下对SMD数据集进行了时间消耗分析。图4b表明,在不同滑动阶跃条件下,我们的方法优于dc检测器。具体来说,当步长设置为1时,PatchAD的速度比DCdetector快1.45倍。此外,图4d说明了固定窗口大小(窗口大小=105)下模型训练所需的时间。这表明PatchAD在训练中比DCdetector表现出更高的效率。图4c显示了使用固定滑动步长(步长=35)训练模型所需的时间,同时对于不同的模型大小,窗口大小从35到175不等。两幅图都表明,PatchAD的时间消耗相对于自变量呈线性增长。因此,增加窗口大小或扩大模型对PatchAD的影响相对较小。但是,时间步长明显影响持续时间,因为该参数会导致数据量增加。
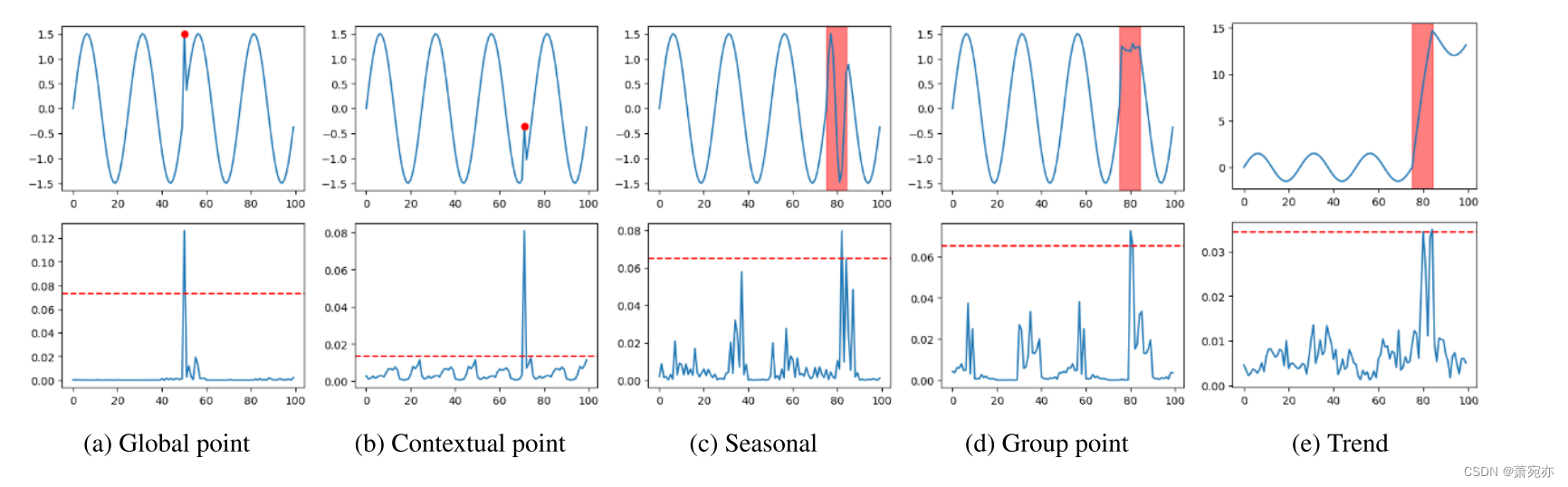
图3:生成的合成数据、PatchAD异常得分和地面真值的可视化。
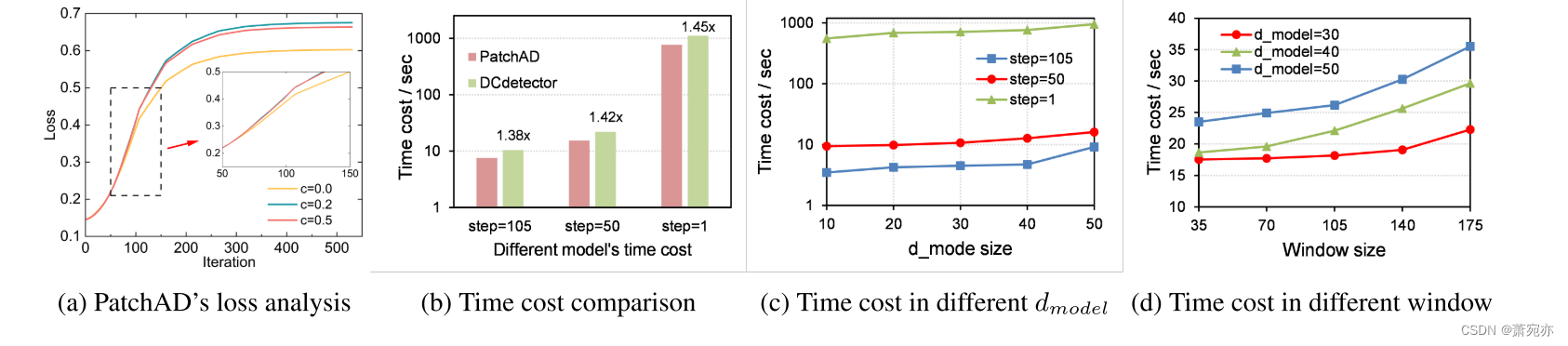
Figure 4: The analysis of PatchAD and DCdetector.
五、结论
本文提出了一种新颖的时间序列异常检测算法PatchAD。PatchAD开发了一个基于对比学习的多尺度、基于patch的MLP Mixer架构。该架构的独特之处在于它使用了纯粹基于mlp的方法来识别时间序列序列中的补丁间和补丁内关系。通过放大两个数据视图之间的差异,PatchAD增强了区分正常和异常模式的能力。此外,PatchAD熟练地学习不同数据通道之间的关系,并结合双项目约束来避免模型退化。此外,PatchAD的功效,包括其各种成分,是通过广泛的实验验证的。结果表明,该方法在8个基准数据集上优于其他方法。
















 2858
2858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









