





系列文章目录
CUTS+:从不规则时间序列中发现高维因果关系 AAAI24
摘要
时间序列中的因果发现是机器学习社区的一个基本问题,可以在复杂场景中进行因果推理和决策。 最近,研究人员通过将神经网络与格兰杰因果关系相结合,成功地发现了因果关系,但由于高度冗余的网络设计和巨大的因果图,当遇到高维数据时,其性能会大幅下降。 此外,观察中缺失的条目进一步阻碍了因果结构学习。 为了克服这些限制,我们提出了 CUTS+,它建立在基于格兰杰因果关系的因果发现方法 CUTS 的基础上,并通过引入一种称为粗到细发现(C2FD)的技术并利用基于消息传递的图神经网络来提高可扩展性 网络(MPGNN)。 与之前在模拟、准真实和真实数据集上的方法相比,我们表明 CUTS+ 极大地提高了不同类型不规则采样的高维数据上的因果发现性能。
引言
分析观察到的时间序列背后的复杂相互作用,即时间序列分析,是机器学习中的一个基本问题,在各种现实应用中具有巨大的潜力。 然而,揭示隐藏在大量变量之下的复杂关系对于算法设计来说可能是一个挑战。 最近,人们提出了从观测数据中提取因果关系的方法(Tank et al. 2022;Lěowe et al. 2022;Khanna and Tan 2020;Runge et al. 2019;Cheng et al. 2023;Xu,Huang,and 哟2019)。 这项任务称为时间序列因果发现,它通过实现时间序列的因果推理而成为机器学习的基本工具。
尽管被证明能够有效地发现因果关系,但这些方法大多数缺乏处理高维时间序列的能力。 实际上,许多因果发现算法仅在少于 20 个时间序列(即 N ≤ 20)的数据集上进行测试(Tank et al. 2022;Khanna and Tan 2020),而真实的时间序列数据集通常包含数十甚至数百个 时间序列,例如基因调控网络或空气质量指数。 最近,程等人。 (2023) 提出了 CUTS,这是一种针对不规则时间数据联合执行因果图学习和缺失数据插补的迭代方法。 尽管提出 CUTS 是为了通过数据插补和相反的方式来促进因果发现,但数据预测模块由具有冗余结构和参数的组件式 LSTM 和 MLP 组成,在遇到高维数据集时阻碍了可扩展性。 此外,CUTS 中的因果图可能太大而无法高精度学习。
为了克服这些问题,我们提出了 CUTS+,它是 CUTS 的扩展,可扩展到高维时间序列,通过提出两种专门设计的技术:从粗到细的因果发现(C2FD)和用于数据预测的消息传递图神经网络(MPGNN)。 我们的贡献包括:
• 我们提出 CUTS+,升级 CUTS(Cheng et al. 2023),以大幅提高高维时间序列的可扩展性。 具体来说,我们利用两种新颖的技术,即粗到细发现(C2FD),一种简单而有效的技术来促进可扩展的因果图优化,以及基于消息传递的图神经网络(MPGNN)来消除结构冗余 削减+。
• 通过大量实验,我们表明 CUTS+ 极大地提高了因果发现性能并降低了时间成本,特别是在高维数据集上,具有多种类型的不规则采样或无缺失值。
Related Works
因果结构学习/因果发现。 现有的因果结构学习(或因果发现)方法可以分为五类。 (i) 基于约束的方法,例如 PC (Spirtes and Glymour 1991)、FCI (Spirtes et al. 2000) 和 PCMCI (Runge et al. 2019; Runge 2020; Gerhardus and Runge 2020),通过条件独立性测试构建因果图 。 (ii) 基于分数的学习算法,包括惩罚神经常微分方程和非循环约束(Bellot、Branson 和 van der Schaar 2022)(Pamfil 等人,2020)。 (iii) Sugihara 等人提出的收敛交叉映射(CCM)。 (2012) 重建不可分离弱连接动态系统的非线性状态空间。 这种方法后来扩展到同步、混杂或零星时间序列的情况(Ye et al. 2015;Benk˝ et al. 2020;Brouwer et al. 2021)。 (iv) 基于加性噪声模型 (ANM) 的方法,根据加性噪声假设推断因果图(Shimizu 等人,2006 年;Hoyer 等人,2008 年)。 Hoyer 等人扩展了 ANM。 (2008) 到具有几乎任何非线性的非线性模型。 (v) 基于格兰杰因果关系的方法。 格兰杰因果关系最初由 Granger (1969) 提出,他提出通过测试一个时间序列对预测另一个时间序列的帮助来分析时间因果关系。 近年来,深度神经网络(NN)被广泛应用于推断非线性格兰杰因果关系,因为格兰杰因果关系的中心思想与神经网络高度兼容。 研究人员已成功使用循环神经网络 (RNN) 或其他神经网络进行时间序列分析,以发现因果图(Wu、Singh 和 Berger 2022;Tank 等人 2022;Khanna 和 Tan 2020;Lěowe 等人 2022;Cheng 等2023)。 这项工作还结合了深度神经网络来发现格兰杰因果关系。
可扩展/高维因果发现。 将因果发现算法应用于实际数据时,可扩展性可能是一个严重的问题。 对于数百个时间序列(或数百个静态节点),因果关系的潜在可能性呈指数级增长。 现有方法可能会失败,因为它们要么涉及大量条件独立性测试(Runge et al. 2019),要么需要调节太多变量(Hong, Liu, and Mai 2017),要么需要优化大量参数(Tank et al. 2017)。 2022;程等人,2023)。 为了解决这个问题,提出了可扩展或高维因果发现方法。 在静态设置中,Hong、Liu 和 Mai (2017) 以及 Morales-Alvarez 等人。 Lopez 等人 (2022) 提出通过分而治之技术来提高可扩展性。 (2022) 将搜索空间限制为低秩因子图,Cundy、Grover 和 Ermon (2021) 则利用变分框架。 在像我们这样的时间序列设置中,可扩展性问题很少被探讨。 与我们最相关的工作是 Xu、Huang 和 Yoo (2019) 的工作,它也使用格兰杰因果关系并通过低秩近似简化高维邻接矩阵。 然而,在实际场景中,低秩假设可能不被满足。 我们的 CUTS+ 是基于格兰杰因果关系的方法的扩展,通过缓解可扩展性问题而无需低秩近似。
Background
Time Series and Granger Causality
我们继承了 (Cheng et al. 2023) 中的符号,并将动态系统的均匀采样观测表示为
X
=
{
x
i
,
1
:
T
}
i
=
1
N
\mathbf{X}=\{\mathbf{x}_{i,1:T}\}_{i=1}^{N}
X={xi,1:T}i=1N ,其中
x
i
,
t
x_{i,t}
xi,t 表示在某个时间采样的第 i 个时间序列 点 t,
t
∈
{
1
,
.
.
.
,
T
}
,
i
∈
{
1
,
.
.
.
,
N
}
,
t\in\{1,...,T\},i\in\{1,...,N\},
t∈{1,...,T},i∈{1,...,N},其中 T 和 N 是时间序列的长度和数量。 假设每个采样变量
x
i
,
t
x_{i,t}
xi,t由以下具有加性噪声的结构因果模型 (SCM) 生成:
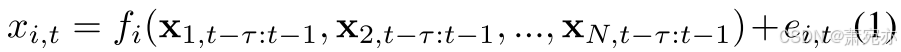
其中 τ 表示最大时滞,i = 1, 2, …,N。 我们的 CUTS+ 还可以通过联合执行插补和因果发现来处理不规则时间序列。 因此,为了对不规则时间序列进行建模,使用双值观测掩码
o
t
,
i
o_{t,i}
ot,i来标记缺失的条目,即,当
o
t
,
i
o_{t,i}
ot,i等于 1 时,观测点等于生成的
x
i
,
t
x_{i,t}
xi,t。在本文中,我们 采用先前工作的协议(Yi et al. 2016;Cini、Marisca 和 Alippi 2022)并考虑实际观测中经常出现的两类数据缺失:
• 随机缺失(RM)。 观测中的数据条目以一定的概率 p 缺失,在我们的实验中,缺失概率遵循伯努利分布
o
t
,
i
∼
B
e
r
(
1
−
p
)
\begin{aligned}o_{t,i}\sim Ber(1-p)\end{aligned}
ot,i∼Ber(1−p)。
• 随机块丢失(RBM)。 在 RM 的 p 相对较小的情况下,我们设置块失败概率
p
b
l
k
p_{\mathrm{blk}}
pblk 和块长度
L
b
l
k
∼
Uniform
(
L
min
,
L
max
)
L_{\mathrm{blk~}}\sim\text{ Uniform}(L_{\min},L_{\max})
Lblk ∼ Uniform(Lmin,Lmax),即平均存在
p
b
l
k
p_{\mathrm{blk}}
pblk·N·T 个缺失块,每个块的长度均匀分布在
[
L
min
,
L
max
]
[L_{\min},L_{\max}]
[Lmin,Lmax]中。
请注意,这两种类型都可以归类为随机完整缺失 (MCAR),这是一种最常见的数据缺失类型 (Geffner et al. 2022)。 在这项工作中,我们以格兰杰因果关系为基础。 实际上,格兰杰因果关系不一定是基于 SCM 的因果关系,因为后者通常考虑非循环性。 在没有未观察到的变量和瞬时效应的假设下,Peters、Janzing 和 Scholkopf (2017) 显示了时不变 Granger 因果关系的可识别性 (Lówe et al. 2022;Vowels、Camgoz 和 Bowden 2021)。 对于动态系统,当时间序列
x
i
x_i
xi 的过去值有助于预测时间序列
x
j
x_j
xj的当前和未来状态时,时间序列 i Granger 会导致时间序列 j。 具体来说,我们采用(Tank et al. 2022)中的定义,即如果存在
x
i
,
t
−
τ
:
t
−
1
′
≠
x
i
,
t
−
τ
:
t
−
1
\mathbf{x}_{i,t-\tau:t-1}^{\prime}\neq\mathbf{x}_{i,t-\tau:t-1}
xi,t−τ:t−1′=xi,t−τ:t−1,则时间序列 i 是 j 的格兰杰非因果关系。 1 满意
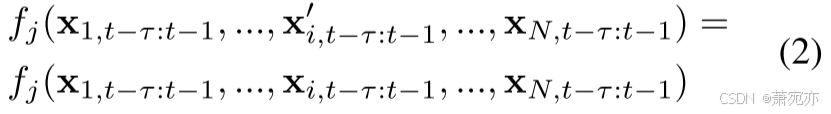 即,时间序列 i 的过去数据点影响
x
j
,
t
x_{j,t}
xj,t 的预测。 为了简单起见,下面我们用
x
i
x_i
xi 来表示
x
i
,
t
−
τ
:
t
−
1
\mathbf{x}_{i,t-\tau:t-1}
xi,t−τ:t−1。 发现的成对格兰杰因果关系是一个有向图,然后用邻接矩阵
A
=
{
a
i
j
}
i
,
j
=
1
N
\mathbf{A}=\{a_{ij}\}_{i,j=1}^{N}
A={aij}i,j=1N表示,其中
a
i
j
a_{ij}
aij= 1 表示时间序列 i 格兰杰原因 j,
a
i
j
a_{ij}
aij= 0 表示 否则。 格兰杰因果关系的思想与神经网络(NN)的基本思想高度兼容,因为神经网络可以作为强大的预测器。 在之前的工作中,(Cheng et al. 2023)证明了他们的 CUTS 中的因果图发现在加性噪声模型和通用逼近定理下收敛到真实图,这再次验证了格兰杰因果关系和神经网络的成功结合。
即,时间序列 i 的过去数据点影响
x
j
,
t
x_{j,t}
xj,t 的预测。 为了简单起见,下面我们用
x
i
x_i
xi 来表示
x
i
,
t
−
τ
:
t
−
1
\mathbf{x}_{i,t-\tau:t-1}
xi,t−τ:t−1。 发现的成对格兰杰因果关系是一个有向图,然后用邻接矩阵
A
=
{
a
i
j
}
i
,
j
=
1
N
\mathbf{A}=\{a_{ij}\}_{i,j=1}^{N}
A={aij}i,j=1N表示,其中
a
i
j
a_{ij}
aij= 1 表示时间序列 i 格兰杰原因 j,
a
i
j
a_{ij}
aij= 0 表示 否则。 格兰杰因果关系的思想与神经网络(NN)的基本思想高度兼容,因为神经网络可以作为强大的预测器。 在之前的工作中,(Cheng et al. 2023)证明了他们的 CUTS 中的因果图发现在加性噪声模型和通用逼近定理下收敛到真实图,这再次验证了格兰杰因果关系和神经网络的成功结合。
Difficulties with High Dimensional Time-series
在实际场景中,通常会面临数百个具有复杂因果图的长时间序列。 我们现在继续展示 CUTS 或其他因果发现算法处理此类数据时的困难。
大邻接矩阵。 成对的 GC 关系表示为矩阵 AN×N,随着 N 的增加会变得非常大。 之前的工作主要集中在 N ≤ 20 时的设置(Tank et al. 2022;Khanna and Tan 2020;Cheng et al. 2023),我们在实验中表明,当 N > 20 时,它们的性能会大幅下降。 Huang和Yoo(2019)通过对邻接矩阵进行低秩逼近解决了增加数据维度时的可扩展性问题,但AN×N的强低秩假设在许多场景中并不成立。 cMLP / cLSTM 的冗余。

cMLP / cLSTM 的冗余。 为了揭开神经网络的黑匣子,Cheng 等人。 (2023); 坦克等人。 (2022)将因果效应从因果父母分解到个体输出序列。 因此,必须使用 N 个独立的 MLP / LSTM 来确保解开。 这称为组件式 MLP / LSTM (cMLP / cLSTM),在发现 Granger 因果关系时经常使用 (Khanna and Tan 2020)。 在下文中,我们将组件级神经网络形式化为“因果解缠神经网络”。
Definition 1 设 x ∈ X ⊂ R n , A ∈ A ⊂ { 0 , 1 } n × n \begin{aligned}\mathbf{x} \in \mathcal{X} \subset \mathbb{R}^n,\mathbf{A} \in \mathcal{A} \subset \left\{0,1\right\}^{n\times n}\end{aligned} x∈X⊂Rn,A∈A⊂{0,1}n×n y ∈ Y ⊂ R n \mathbf{y}\in\mathcal{Y}\subset\mathbb{R}^n y∈Y⊂Rn 为输入和输出空间。我们说神经网络 f Θ : ⟨ X , A ⟩ → Y \mathbf{f}_{\Theta}:\langle\mathcal X,\mathcal A\rangle\to\mathcal Y fΘ:⟨X,A⟩→Y是一个因果解缠的神经网络 神经网络(CDNN),如果它具有以下形式
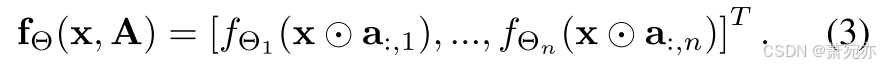
这里a:,j是输入因果邻接矩阵A的列向量;
f
ϕ
j
:
X
j
→
Y
j
f_{\phi_{j}} : \mathcal{X}_{j} \to \mathcal{Y}_{j}
fϕj:Xj→Yj,其中
X
j
⊂
R
n
and
Y
j
⊂
R
\mathcal{X}_j \subset \mathbb{R}^n \textit{and }\mathcal{Y}_j \subset \mathbb{R}
Xj⊂Rnand Yj⊂R; 运算符 ⊙ 表示哈达玛积。
这里函数 f Θ j ( ⋅ ) f_{\Theta_{j}}(\cdot) fΘj(⋅)表示用于近似等式(1)中的fj(·)的神经网络函数。 CDNN 的输入也可以是具有时间维度的 X 而不是 x,则 ⊙ 定义为 f ϕ j ( X ⊙ a : , j ) = Δ f_{\phi_{j}}(\mathbf{X} \odot \mathbf{a}_{:,j})\quad\stackrel{\Delta}{=} fϕj(X⊙a:,j)=Δ f ϕ j ( { x 1 ⋅ a 1 j , . . . , x N ⋅ a N j } ) f_{\phi_j}\left(\{\mathbf{x}_1\cdot a_{1j},...,\mathbf{x}_N\cdot a_{Nj}\}\right) fϕj({x1⋅a1j,...,xN⋅aNj})。 根据这个定义,Cheng 等人。 (2023)证明,当用 f ϕ j f_{\phi_{j}} fϕj以及其他假设)逼近 f j f_j fj 时,发现的因果邻接矩阵将收敛到真正的格兰杰因果矩阵。 尽管是 CDNN,cMLP / cLSTM 由 N 个独立的网络组成,并且具有高度冗余性,因为不同时间序列之间的共享动态被建模了 N 次。 这种冗余不仅减慢了学习过程,而且降低了因果发现的准确性。 因此,该模型不能很好地扩展到高维时间序列。 在下一节中,我们将介绍两种缓解可扩展性问题的技术。
CUTS+
在这项工作中,我们将因果图实现为因果概率图(CPG)M,其中元素 mij 表示时间序列 i 格兰杰导致 j 的概率,即 m i j = P ( x i → x j ) \begin{aligned}m_{ij} = P(x_i \to x_j)\end{aligned} mij=P(xi→xj)。 如果发现的图 M ~ \tilde{\mathbf{M}} M~中的 m ~ i j \tilde{m}_{ij} m~ij被惩罚为零(或低于某个特定阈值),我们可以推断时间序列i不会格兰杰导致j。
与 CUTS (Cheng et al. 2023) 类似,我们也采用两阶段训练策略,并迭代执行因果发现阶段和预测阶段——前者在稀疏惩罚下构建具有可用时间序列的因果概率矩阵,而后者 拟合高维时间序列的复杂分布并填充缺失的条目。 然而,这两个阶段都是全新的设计,以克服遇到高维时间序列时的困难,如图1所示。具体来说,我们建议在因果发现阶段和消息传递中使用从粗到细的发现(C2FD)技术 预测阶段的图神经网络(MPGNN),将在以下小节中详细介绍。
Coarse-to-fine Causal Discovery
为了解决之前讨论的大邻接矩阵问题,我们提出了从粗到细的因果发现(C2FD)。 具体来说,我们将时间序列分为几组,即时间序列组
X
G
k
=
{
x
i
}
i
∈
G
k
\mathbf{X}_{\mathcal{G}_k}=\left\{\mathbf{x}_i\right\}_{i\in\mathcal{G}_k}
XGk={xi}i∈Gk,其中 Gk 是第 k 组内的索引集,
k
∈
[
1
,
N
g
]
k\in[1,N_{g}]
k∈[1,Ng],其中 Ng 是 组号。 每个时间序列只能分配到一组,即
∀
k
≠
l
∈
[
1
,
N
g
]
,
G
k
∩
\forall k\neq l\in\left[1,N_{g}\right],\mathcal{G}_{k}\cap
∀k=l∈[1,Ng],Gk∩
G
l
=
ϕ
\mathcal{G}_{l} = \phi
Gl=ϕ。 分组是通过
M
~
\tilde{\mathbf{M}}
M~的矩阵分解来实现的:

其中
G
∈
R
N
g
×
N
\mathbf{G}\quad\in\quad\mathbb{R}^{N_g\times N}
G∈RNg×N 由条目
g
k
i
g_{ki}
gki =
{
0
,
if
i
∉
G
k
1
,
if
i
∈
G
k
\left\{\begin{matrix}0,&\text{if }i\notin\mathcal{G}_k\\1,&\text{if }i\in\mathcal{G}_k\end{matrix}\right.
{0,1,if i∈/Gkif i∈Gk 组成。 由于每个时间序列只能分配到一组,因此 G 的每个列向量之和为 1,即
∀
i
∈
[
1
,
N
]
,
∑
k
=
1
N
g
g
k
i
=
1
\forall i\in[1,N] ,\sum_{k=1}^{N_{g}}g_{ki}=1
∀i∈[1,N],∑k=1Nggki=1。我们从组中定义格兰杰因果关系
X
G
k
\mathbf{X}_{\mathcal{G}_{k}}
XGk如下
定义2 如果存在 X G k ′ ≠ X G k \mathrm{X}_{\mathcal{G}_k}^{\prime}\neq\mathrm{X}_{\mathcal{G}_k} XGk′=XGk ,则群 X G k \mathbf{X}_{\mathcal{G}_k} XGk是 x j x_j xj 的格兰杰非因果,
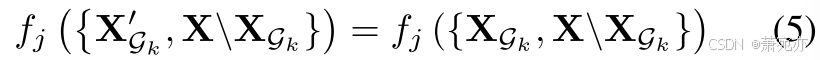 即,组
x
G
k
x_{\mathcal{G}_k}
xGk影响
x
j
,
t
x_{j,t}
xj,t的预测。 这里我们定义
X
\
X
G
k
≡
Δ
{
x
i
}
i
∉
G
k
\mathbf{X}\backslash\mathbf{X}_{\mathcal{G}_k}\stackrel{\Delta}{\equiv}\left\{\mathbf{x}_i\right\}_{i\notin\mathcal{G}_k}
X\XGk≡Δ{xi}i∈/Gk 。
即,组
x
G
k
x_{\mathcal{G}_k}
xGk影响
x
j
,
t
x_{j,t}
xj,t的预测。 这里我们定义
X
\
X
G
k
≡
Δ
{
x
i
}
i
∉
G
k
\mathbf{X}\backslash\mathbf{X}_{\mathcal{G}_k}\stackrel{\Delta}{\equiv}\left\{\mathbf{x}_i\right\}_{i\notin\mathcal{G}_k}
X\XGk≡Δ{xi}i∈/Gk 。
那么 Q ∈ R N g × N \mathbf{Q}\in\mathbb{R}^{N_g\times N} Q∈RNg×N是群因果概率图 (GCPG),其中 q i j = P ( X G i → x j ) . q_{ij}=P(\mathbf{X}_{\mathcal{G}_i}\to\mathbf{x}_j). qij=P(XGi→xj).
初始分配。 在训练之前,我们用相对较小的 Ng 启动 G,从而获得“粗略”分组。 具体来说,时间序列被分配到以下组中
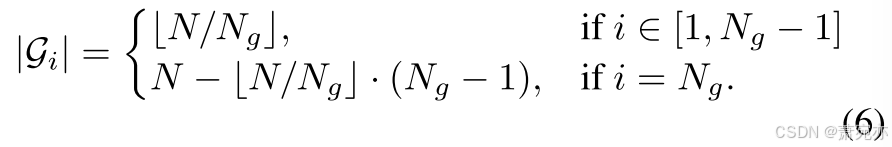
小组分裂。 在训练过程中,我们定期将每组分成两组,然后每 20 个 epoch 将 Ng 加倍,直到每组只包含一个时间序列。 相应地,当组数加倍时,GCPG元素
q
i
j
q_{ij}
qij被分配给新GCPG中的2个元素
q
i
1
,
j
and
q
i
2
,
j
q_{i_1,j}\text{ and }q_{i_2,j}
qi1,j and qi2,j,作为初始猜测。 这里我们假设一组格兰杰原因
x
j
x_j
xj 如果至少有一个子群格兰杰原因
x
j
x_j
xj,则 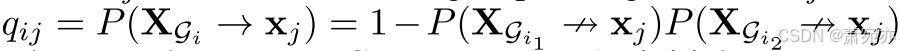
,其中 ↛ 表示不是格兰杰原因 。 作为最初的猜测,我们假设
P
(
X
G
i
1
→
x
j
)
=
P
(
X
G
i
2
→
x
j
)
P(\mathbf{X}_{\mathcal{G}_{i_{1}}}\to\mathbf{x}_{j}) = P(\mathbf{X}_{\mathcal{G}_{i_{2}}} \to \mathbf{x}_{j})
P(XGi1→xj)=P(XGi2→xj),然后
q
i
1
,
j
q_{i_1,j}
qi1,j和
q
i
2
,
j
q_{i_2,j}
qi2,j计算如下
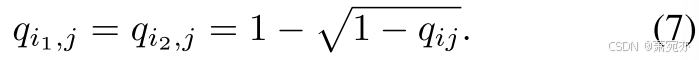
C2FD的收敛。 我们用与 (Cheng et al. 2023) 类似的方式证明了 C2FD 以 CDNN 作为预测器的收敛性。 由于篇幅限制,我们将详细的假设、定理和证明放在补充材料的 A 节中。
从粗到细的想法在机器学习领域非常常见(Fleuret and Geman 2001;Sarlin et al. 2019)。 然而,据我们所知,我们是第一个将这个想法引入基于神经网络的格兰杰因果关系的人。 实际上,引入 C2FD 的优势有两个。 首先,初始阶段需要学习的参数数量大大减少。 在初始阶段,当 N g N_{g} Ng<N时,只需要优化N· N g N_{g} Ng参数,而不需要优化N2参数。 其次,较小 N g N_{g} Ng的学习结果作为较大 N g N_{g} Ng学习的初始猜测。 当 |Gk| > 1,如果至少一个成员 Granger 导致时间序列 j,则 GCPG 元素 q k j q_{kj} qkj 向 1 增加。 然后用整个组来进行更高精度的数据预测。 将 N g N_{g} Ng加倍后,优化器进一步定位实际Granger导致j的子组。 C2FD 的经验优势在实验部分得到了验证。
Message-passing-based Graph Neural Network
为了满足因果解缠神经网络 (CDNN) 的定义,同时防止使用高度冗余的 cMLP / cLSTM,我们利用消息传递神经网络 (MPNN (Gilmer et al. 2017)) 作为数据预测编码器。 为了了解高维时间序列的动态,我们通过添加消息传递层来改变门控循环单元(GRU,(Cho et al. 2014))。 首先,我们将单层 MPNN 表示为
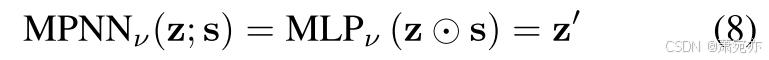
其中 h′ 是 MPNN 最后一层的输出,MLP1(·)、MLP2(·) 是多层感知器(MLP),⊙ 表示 Hadamard 乘积,
s
∈
{
0
,
1
}
N
\mathbf{s}\in\left\{0,1\right\}^{N}
s∈{0,1}N 是二元因果关系 向量,即采样的二元因果图(BCG,在第 1 节中描述)中的一列,其中
s
i
s_{i}
si = 1 表示
z
i
z_{i}
zi Granger 导致预测。 与(Cini、Marisca 和 Alippi 2022)类似,我们将 MPNN 添加到 GRU 单元,它充当 MPGNN 中的一层:
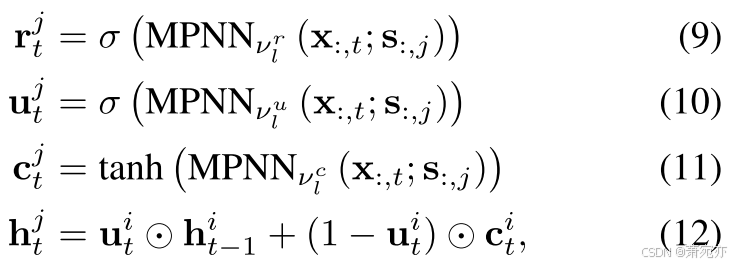
其中 σ(·) 是 sigmoid 函数。 与标准 GRU 单元不同,每个门仅使用输入向量进行计算,这减少了参数数量。 下面我们用
M
P
G
N
N
ν
(
x
:
,
t
,
h
0
j
;
s
:
,
j
)
\mathrm{MPGNN}_\nu\left(\mathbf{x}_{:,t},\mathbf{h}_0^j;\mathbf{s}_{:,j}\right)
MPGNNν(x:,t,h0j;s:,j) 表示 l MPGNN 层;其中
ν
=
{
ν
1
r
,
ν
1
u
,
ν
1
c
,
.
.
.
,
ν
l
r
,
ν
l
u
,
ν
l
c
}
\nu = \{\nu_1^r,\nu_1^u,\nu_1^c,...,\nu_l^r,\nu_l^u,\nu_l^c\}
ν={ν1r,ν1u,ν1c,...,νlr,νlu,νlc}(所有层中 MPNN 的参数)。 请注意,我们为每个 j 共享 ν,这是有助于高可扩展性的关键设计。
Scalability of MPGNN Encoder MPGNN 编码器的可扩展性
MPGNN 编码器中需要优化的参数数量可以计算为 l ( ∣ ν r ∣ + ∣ ν u ∣ + ∣ ν c ∣ ) {l}\left(\left|\nu^r\right|+\left|\nu^u\right|+\left|\nu^c\right|\right) l(∣νr∣+∣νu∣+∣νc∣),其中 l 是 MPGNN 层数。 将 CUTS+ 与参数数量为 N l ( ∣ ν r ∣ + ∣ ν u ∣ + ∣ ν c ∣ ) Nl\left(|\nu^{r}|+|\nu^{u}|+|\nu^{c}|\right) Nl(∣νr∣+∣νu∣+∣νc∣)(或 cMLP / cLSTM (Tank et al. 2022),也是 O(Nl))的组件级 GRU 进行比较,MPGNN 实现了较高的性能 通过显着减少编码器中优化参数的数量来实现可扩展性。 此外,由于基于组件网络的预测模型通常过度参数化,因此容易过度拟合(Khanna 和 Tan 2020),我们的设计也有助于减轻过度拟合。
解码器。 使用 MPGNN 进行编码后,使用两部分解码器检索预测结果 x ^ j , t \hat{x}_{j,t} x^j,t,即
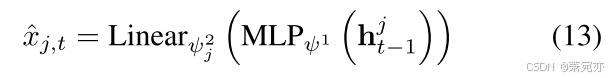
其中
L
i
n
e
a
r
ψ
j
2
(
⋅
)
\mathrm{Linear}_{\psi_{j}^{2}}(\cdot)
Linearψj2(⋅)表示具有不共享权重的单个线性层。 为了捕获时间序列之间的异质性,同时尽可能地消除结构冗余,这里我们共享第一个 MLP 部分 (ψ) 的权重,而不共享第二个单层部分的权重(每个目标时间序列的不同
ψ
j
\psi_{j}
ψj)。
Overall Architecture
CPG 的伯努利采样。 我们的 CUTS+ 代表与 CPG
M
~
\tilde{\mathbf{M}}
M~ 的因果关系。 为了确保
M
~
\tilde{\mathbf{M}}
M~ 的元素在 [0, 1] 范围内,我们设置 Q = σ(
Θ
\boldsymbol{\Theta}
Θ),其中
Θ
\boldsymbol{\Theta}
Θ 是要学习的参数。 在因果发现阶段,使用 Gumbel-Softmax 估计器(Jang、Gu 和 Poole 2016)优化
Θ
\boldsymbol{\Theta}
Θ,即
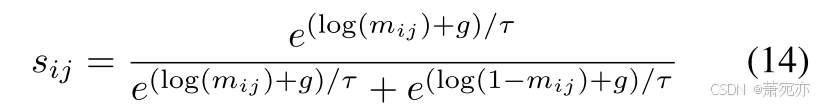
其中
g
=
−
log
(
−
log
(
u
)
)
,
u
∼
Uniform
(
0
,
1
)
g = -\log(-\log(u)),u \sim \text{Uniform}(0,1)
g=−log(−log(u)),u∼Uniform(0,1)。 我们在初始阶段使用较大的 τ,然后减小到一个较小的值。 该估计量具有相对较低的方差,模拟 τ 较小时的伯努利分布,更重要的是,可以连续优化
Θ
\boldsymbol{\Theta}
Θ。
在预测阶段,CPG M ~ \tilde{\mathbf{M}} M~被采样为二元因果图(BCG)S,其中 s i j ∼ B e r ( m i j ) s_{ij}\sim\mathrm{Ber}(m_{ij}) sij∼Ber(mij)。 最后,BCG 列 s : , j \mathbf{s}_{:,j} s:,j 用作 MPNN 中的邻接矩阵。
损失函数。 CUTS+ 在因果发现阶段和预测阶段之间迭代。 在前一阶段,仅优化CPG M ~ = σ ( Θ ) \tilde{\mathbf{M}}=\sigma(\boldsymbol{\Theta}) M~=σ(Θ),因此优化问题为
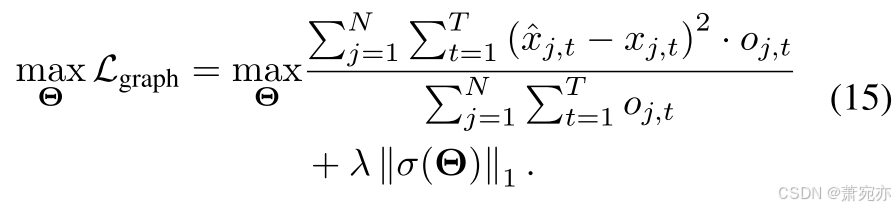
后期我们只优化网络参数:
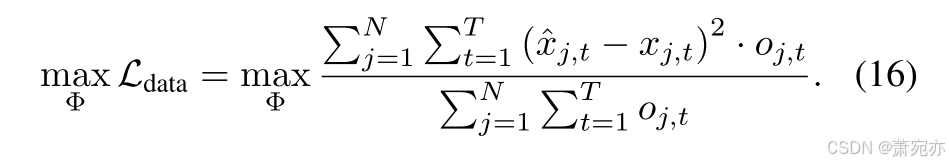
其中 Φ = { ν , ψ 1 , { ψ 2 j } j = 1 N } \Phi=\left\{\nu,\psi_{1},\{\psi_{2}^{j}\}_{j=1}^{N}\right\} Φ={ν,ψ1,{ψ2j}j=1N}是 MPGNN 编码器和解码器中的所有网络参数。
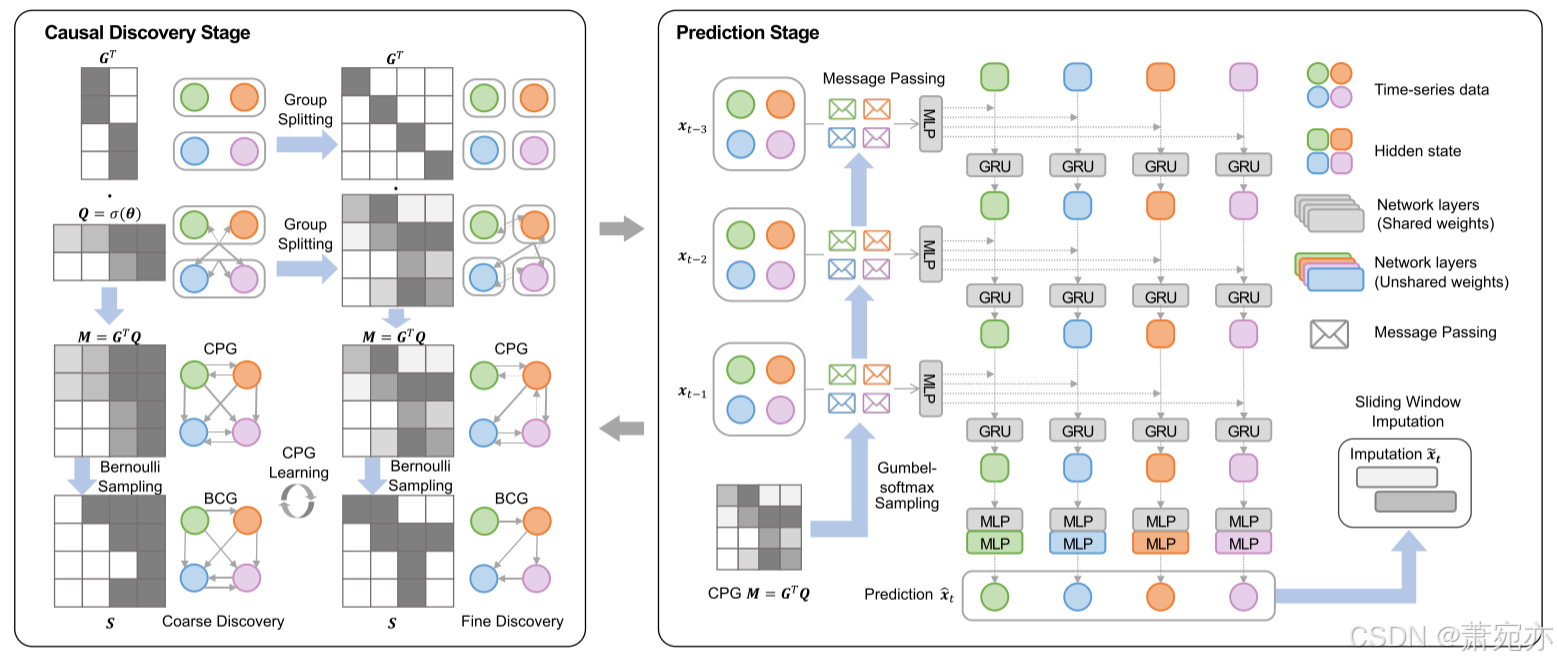
图 1:CUTS+ 的架构具有两个交替阶段,两个阶段都促进了高维因果发现。 因果发现阶段配备了从粗到细的因果发现(C2FD),而预测阶段则配备了基于消息传递的图神经网络(MPGNN)。
Satisfaction of CDNN。 当矩阵 A 的某一列仅影响预测 f Φ ( x , A ) \mathbf f_{\Phi}(x,\mathbf A) fΦ(x,A)的相应分量时,满足定义 1 中的 CDNN。 如果我们结合预测模块 M P G N N ν ( X ~ , h 0 j ; s : , j ) \mathrm{MPGNN}_{\nu}\left(\tilde{\mathbf{X}},\mathbf{h}_{0}^{j};\mathbf{s}_{:,j}\right) MPGNNν(X~,h0j;s:,j)与 L i n e a r ψ j 2 ( M L P ψ 1 ( ⋅ ) ) \mathrm{Linear}_{\psi_j^2}\left(\mathrm{MLP}_{\psi^1}\left(\cdot\right)\right) Linearψj2(MLPψ1(⋅)),我们得到
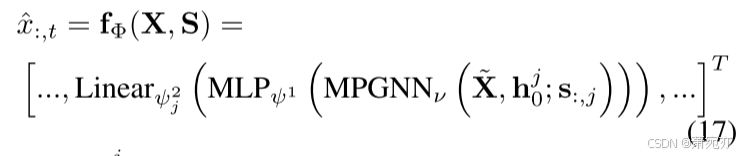
其中
h
0
j
\mathbf h_{0}^{j}
h0j是 GRU 隐藏状态的初始值,与 x 无关。 因此,我们的CUTS是一个CDNN,根据补充A节中的定理1,可以恢复正确的因果图。
通过插补处理不规则时间序列。 在这项工作中,我们通过在预测阶段执行并发数据插补来处理不规则时间序列。 我们的数据插补是通过滑动窗口执行的,其中一个时间窗口中缺失的条目由最后一个窗口的预测 x ^ j , t {\hat{x}}_{j,t} x^j,t填充。 由于页面限制,我们将滑动窗口插补的详细信息放在补充部分 C.3 中。
Experiments
在本节中,我们定量评估所提出的 CUTS+ 并将其与最先进的方法进行全面比较以验证我们的设计。
基线算法。 为了证明其优越的性能,我们将 CUTS+ 与 7 种基线算法进行了比较:(i)神经格兰杰因果关系(NGC,(Tank et al. 2022)),它利用 cMLP 和 cLSTM 来推断格兰杰因果关系; (ii) 经济 SRU(eSRU,(Khanna 和 Tan 2020)),SRU 的一种变体,在推断格兰杰因果关系时不太容易过度拟合; (iii) PCMCI(Runge et al. 2019),一种基于非格兰杰因果关系的方法,使用条件独立性检验; (iv) 潜在收敛交叉映射(LCCM,(Brouwer et al. 2021)),一种基于 CCM 的方法,也可以解决不规则时间序列问题; (v) 神经图形模型(NGM,(Bellot、Branson 和 van der Schaar 2022)),使用神经常微分方程(Neural-ODE)来处理不规则时间序列数据; (vi) 可扩展因果图学习(SCGL,(Xu、Huang 和 Yoo 2019)),解决具有低秩假设的可扩展因果发现问题; (vii) 削减(Cheng 等人,2023)。 我们根据 ROC 曲线下面积 (AUROC) 标准评估性能。 为了公平比较,我们在验证数据集上搜索基线算法的最佳超参数,并在每个实验的 5 个随机种子的测试集上测试性能。 对于无法处理不规则时间序列数据的基线算法,即NGC、PCMCI、SCGL和eSRU,我们使用两种算法来插补不规则时间序列: 零阶持有者(ZOH,用最近的历史样本填充,不 引入未来的样本),以及最先进的插补算法 TimesNet(Wu et al. 2023)。
消融研究设置。 我们的主要技术贡献是将 C2FD 和 MPGNN 引入因果发现。 为了定量验证这两种技术,我们将 C2FD 添加到原始 CUTS(Cheng et al. 2023)中,得到“CUTS with C2FD”。 因此,我们可以通过比较“CUTS”与“CUTS with C2FD”来衡量 C2FD 的性能增益,并通过比较“CUTS with C2FD”与“CUTS+”来验证 MPGNN。
数据集。 我们评估因果 MLP MLP MLP 发现方法 CUTS+ 在三种类型的数据集上的性能:模拟数据、准现实数据(即在物理上有意义的因果关系下合成)和真实数据。 模拟数据集包括线性向量自回归 (VAR) 和非线性 Lorenz-96 模型(Karimi 和 Paul 2010),拟现实数据集来自 Dream-3(Prill 等人,2010),而真实数据集包括来自 20 个国家/地区 163 个监测站的空气质量数据集。 中国城市。 不规则观测值是通过随机缺失 (RM) 和随机块缺失 (RBM) 生成的。 为了对因果发现算法进行统计评估,我们对 5 个不同随机种子的模拟结果进行平均。 在下面的实验中,我们还展示了标准推导。
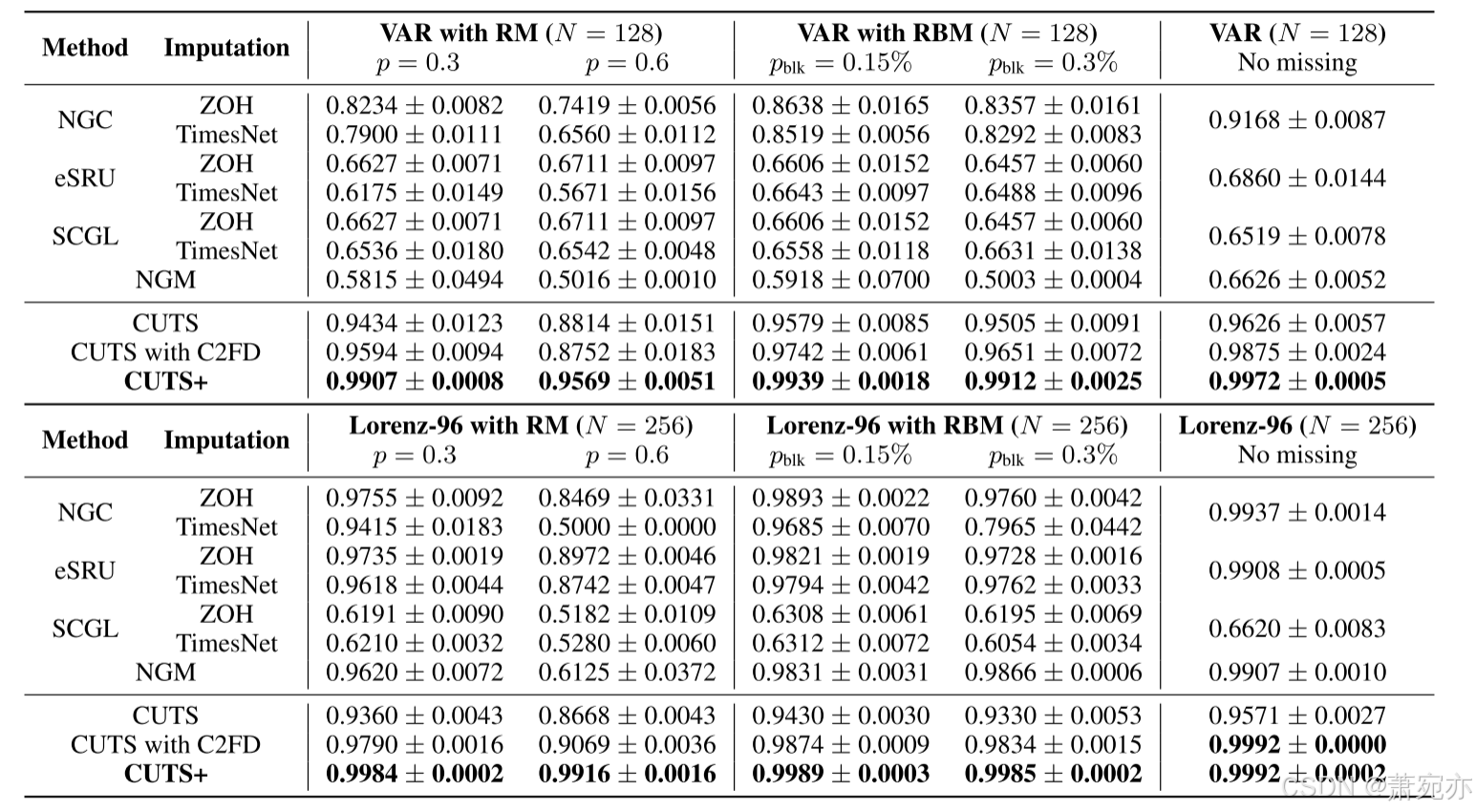
表 2:CUTS+ 与 NGC、eSRU、NGM、SCGL 以及 CUTS 结合 ZOH 和 TimesNet 进行插补的性能比较。我们没有与 PCMCI 和 LCCM 进行比较实验,因为在 N 和 T 较大的情况下,这两者的运行时间 方法非常长。 与它们的比较是在 Dream-3 数据集上进行的(表 3)。
Results on Simulated Datasets
VAR。 VAR 数据集使用线性方程
x
:
,
t
=
∑
τ
=
1
τ
m
a
x
A
x
:
,
t
−
τ
+
e
:
,
t
\mathbf{x}_{:,t} = \sum_{\tau=1}^{\tau_{max}}\mathbf{A}\mathbf{x}_{:,t-\tau} +\mathbf{e}_{:,t}
x:,t=∑τ=1τmaxAx:,t−τ+e:,t进行模拟,其中矩阵 A 是因果系数,
e
:
,
t
∼
N
(
0
,
σ
I
)
\mathbf{e}_{:,t}\sim\mathcal{N}(\mathbf{0},\sigma\mathbf{I})
e:,t∼N(0,σI)。 如果
a
i
j
a_{ij}
aij > 0,则时间序列 i 格兰杰导致时间序列 j。因果发现的目标是找到因果图 A 中的非零元素,其中
M
~
\tilde{\mathbf{M}}
M~ 。 在本实验中,我们设置
τ
m
a
x
\tau_{max}
τmax = 3 和时间序列长度 L = 1000。 从表 2 中可以看出,CUTS+ 以明显优势击败了所有其他算法。 此外,我们在补充部分 B.1 中对具有不同图密度的 VAR 数据集进行了比较实验。
Lorenz-96. Lorenz-96数据集根据 d x i , t d t = − x i − 1 , t ( x i − 2 , t − x i + 1 , t ) − x i , t + F \frac{dx_{i,t}}{dt}=-x_{i-1,t}(x_{i-2,t}-x_{i+1,t})-x_{i,t}+F dtdxi,t=−xi−1,t(xi−2,t−xi+1,t)−xi,t+F进行模拟,其中我们设置F = 10,L = 1000 在此模型中,每个时间序列 xi 都受到四个时间序列 x i − 2 , x i − 1 , x i , x i + 1 \mathbf{x}_{i-2},\mathbf{x}_{i-1},\mathbf{x}_{i},\mathbf{x}_{i+1} xi−2,xi−1,xi,xi+1的历史值的影响,并且真实因果图 A 中的每一行都有四个非零元素。 表2显示了CUTS+相对于其他算法的优势。
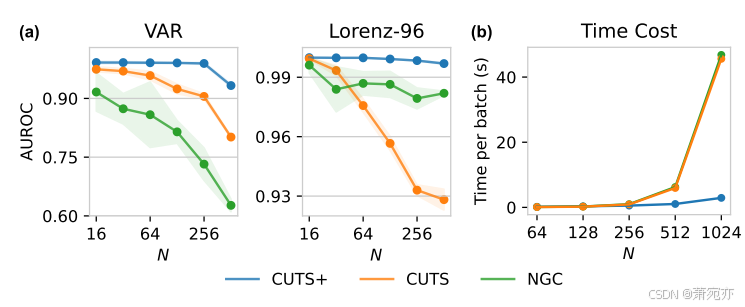
图 2:模型可扩展性实验。 (a) 在 AUROC 方面与 CUTS 和 NGC 的可扩展性比较(RM,p = 0.3)。 (b) CUTS+与NGC和CUTS+的时间成本比较,onN = 64, 128, 256, 512, 1024。
消融研究。 通过比较“CUTS”、“CUTS with C2FD”和“CUTS+”,我们发现 C2FD 和 MPGNN 都有助于性能增益。 C2FD在Lorenz-96上相对更有帮助,MPGNN在VAR上帮助更多。
可扩展性。 VAR 和 Lorenz-96 数据集支持设置 N。为了演示 CUTS+ 对高维数据的可扩展性,我们将 CUTS+ 与两种性能最佳的算法(即 CUTS 和 NGC(结合 ZOH))进行比较。 当 N 变化时,我们在 VAR 中为因果父母设置相同的平均数。 如图 2(a) 所示,通过增加 VAR 和 Lorenz96 数据集的时间序列数 N,我们观察到当两个数据集上的 N 增加时,CUTS 和 NGC 的 AUROC 显着降低。 相反,CUTS+ 以明显的优势击败了这两种算法,并且在 N 较大时优势尤其突出。只有当 VAR 数据集上的 N = 512 时,CUTS+ 的性能才会明显下降。 补充部分 B.2 中显示了使用多种类型的不规则采样或无缺失值的更多可扩展性实验。 我们相对于其他方法的优势还存在于计算复杂性方面。 图 2(b) 所示为每次前向+后向传播的时间成本。 我们将 CUTS+ 中的网络与 NGC 和 CUTS 中的 cMLP 和 cLSTM 进行比较。 结果表明,与 cMLP 和 cLSTM 相比,计算成本大大降低,特别是当 N > 256 时。
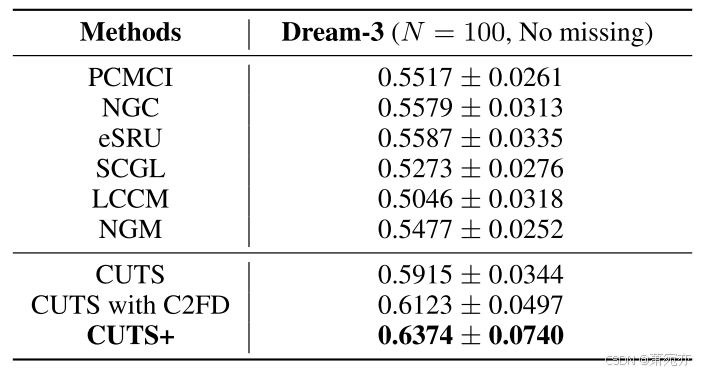
表 3:CUTS+ 与 PCMCI、NGC、eSRU、NGM、SCGL、LCCM 和 CUTS 在没有缺失值的 Dream-3 数据集上的性能比较。
Results on Quasi-Realistic Datasets
Dream-3(Prill 等人,2010)是一个基因表达和调控数据集,广泛用作因果发现基准(Khanna 和 Tan,2020 年;Tank 等人,2022 年)。 该数据集包含 5 个模型,每个模型代表 100 个基因表达水平的测量结果。 每个测量轨迹的长度为 T = 21,这对于执行 RM 或 RBM 来说太短,因此我们仅与 Dream-3 上没有数据丢失的时间序列基线进行比较。 结果列于表 3,这表明我们的 CUTS+ 比其他方法表现更好,证明我们的方法也可以处理数据而不会丢失条目。 至于消融研究,我们观察到 MPGNN 和 C2FD 都有明显的贡献,就 AUROC 而言,两者的性能增益均超过 0.02。
Results on Real Datasets
空气质量(AQI)。 我们在 AQI 上测试我们的 CUTS+,这是一个真实的高维数据集,N = 163,T = 8760(该数据集的详细描述在补充部分 C.2 中)。 由于大气物理极其复杂,我们无法获得真实的因果图,因此定量性能评估和与基线的比较可能缺乏说服力(如补充部分 B.3 所示)。 然而,我们有一个先验,即真正的因果关系与几何距离密切相关。 因此,为了验证 CUTS+ 的因果发现结果,我们将发现的 CPG M~(图 3(a) 左)与距离矩阵 D(其中元素 dij ∝ 1/dist(i, j),图 3(a) ) 正确的)。 可以看出,发现的因果矩阵确实模仿了距离矩阵。 我们还在地图上绘制了 P(i → j) > 0.5 的 CPG 边(图 3(b)),这表明发现的大多数因果边将相距不远的站点连接起来。 这间接证明了CUTS+在真实高维数据上的有效性。
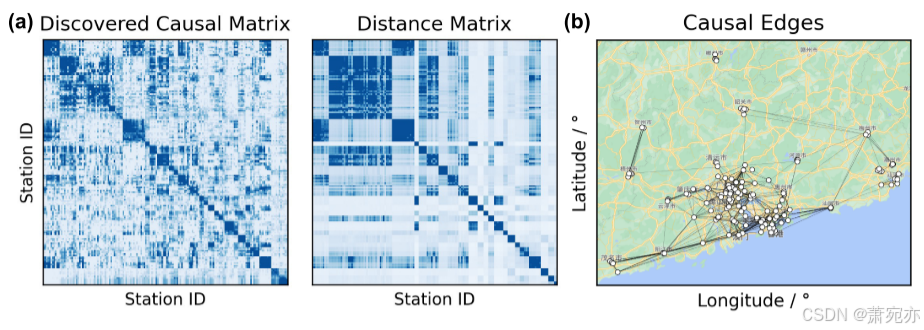
图 3:AQI 数据集的因果发现结果。 (a) AQI 数据集上的因果发现结果与距离矩阵(可能指示真实的因果图)相比 (b) 覆盖在地图上的因果发现结果图。
Additional Information
补充部分 A 提供了 CUTS+ 中 CPG 收敛的假设、定理和证明。在补充部分 A 中,我们进行了其他补充实验,包括图密度、可扩展性和 AQI 数据集定量比较的实验。 我们在 C 节中提供了 CUTS 的实现细节,包括网络结构、每个实验的超参数、RM 和 RBM 的配置以及基线算法的详细设置。 此外,我们在 D 节和 E 节中列出了更广泛的影响和限制。
Conclusions
我们提出了 CUTS+,一种基于格兰杰因果关系的因果发现方法,用于处理具有不规则采样的高维时间序列。 我们通过(a)引入从粗到细的发现(C2FD)来解决大型 CPG 问题,以及(b)设计基于消息传递的图神经网络(MPGNN)来解决冗余问题,从而大大提高了数据维度的可扩展性。 网络参数问题。 与以前的方法相比,CUTS+ 大大提高了 AUROC 并降低了时间成本,尤其是在面对高维时间序列时。 我们未来的工作包括:(i)具有潜在混杂因素或瞬时效应的高维因果发现。 (ii) 用因果模型解释神经网络。 我们的代码可在 https://github.com/jarrycyx/unn 获取。

















 5319
5319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









