







一、贝尔曼公式中的return
1.return
- 计算求解的过程可以看成是从开始网格到目标网格的轨迹路线,到达目标网格有着不同的策略,即在一个网格时有着下一时刻的不同行动,return就是评估每一条到达目标网格的策略的一个关键参数;
- 通过对比不同策略的return结果就可以评估策略的优劣;
- return:沿着轨迹路线得到奖励的(discounted)总和。
2.例子
下边计算的每一项策略都是从s1出发的
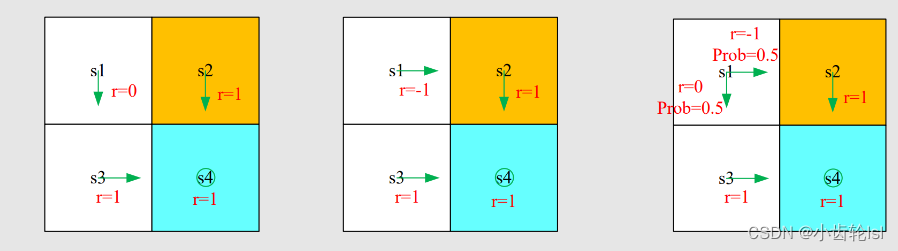
- 策略1:
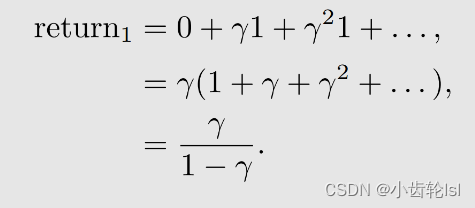
- 策略2:
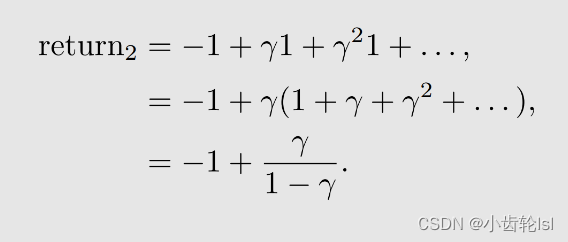
- 策略3:
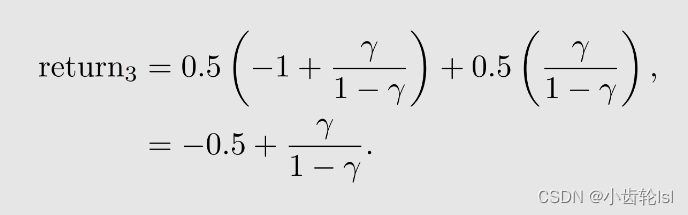
- 在三个例子中的return计算结果中,策略1的值最大,策略2的值最小,因此策略1是最优策略,策略2是最差的策略;
- 在策略1和2中,轨迹路线都是确定的,所以计算的是确定轨迹的奖励return;
- 策略3中,在s1状态时,有着两种概率的不同行动,因此我们计算的结果和s1s2不同,并不是return,计算的是状态条件期望,是策略评估的状态值(state value);
- 计算得到的statue value是期望,不是平均,因为我们研究的是随即策略的随机变量。
二、return的计算实例
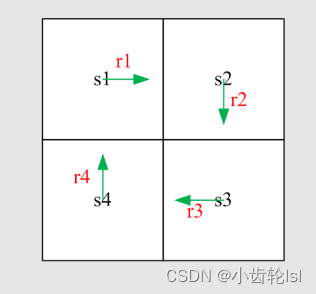
在此小节的例子计算中的return和value,都是确定已知的策略,并且轨迹是无穷的,没有停止,列:
分别带入得:
同理:
这样就将求解得过程前后关联,不同状态出发得到的 return 依赖于从其他状态出发得到的 return,回报(return)相互依赖。 可以做一矩阵来更清楚得理解并看到状态值:
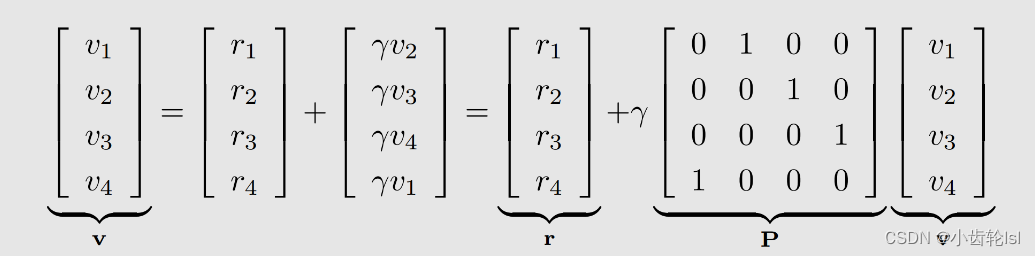
式子:
计算举例


在此例子中可以先根据第四个式子求解,再求解剩余几个。
三、State value计算(随机策略)
1.state value的定义
在此小节中的state、return、action都是随机而不是确定的策略中的。它们的产生都是由概率分布所决定的。
t, t + 1:离散时间实例,t 指当前的时刻,t+1 指下一个时刻 :t 时刻的状态
:在状态
采取的动作
:在状态
采取动作
之后获得的奖励(reward)
:采取动作
后转换到的状态
、
、
都是大写的,代表随机变量(random variables),就是我们可以对他进行一系列的操作,比如求期望(expectation)。
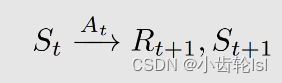
在 要采取什么样的动作(action)由策略
来决定
在 采取动作(take action)
,要得到什么样的奖励(Reward)由奖励概率(reward probability)决定
在采取动作(take action)
,要跳到下一个什么状态(State)由状态转移概率( state transition probability)决定
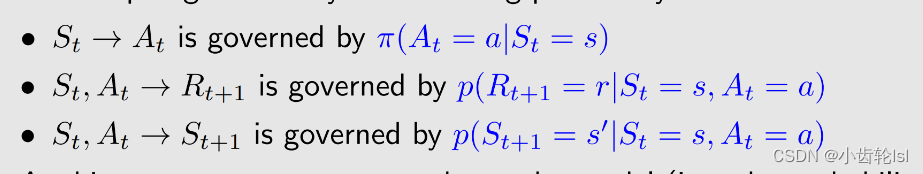
2.例子
假定了一个策略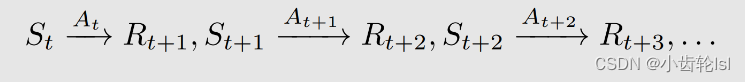
在这个策略中state、return、action都是随机变量,则return的有效值discounted return也是一个随机变量, 折扣回报(discounted return)G(t) 是所有瞬时回报(immediate reward)与折扣因子(discount rate)乘积相加:定义成G(t)。则G(t)为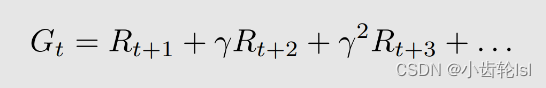
- 将计算得到的G(t)称为State value状态值(就是一个期望值)。state value 是一个关于s的计算函数,而这个函数的条件期望值就是state value ;
- 因为过程是随机的,策略也是随机的,故state value 的值也是随机的;
- 状态值(state value)它是策略 Π 的函数,对于不同的策略(policy) ,会得到不同的轨迹,不同的轨迹会得到不同的折扣回报(discounted return)Gt,就会得到不同的状态值(state value);
- 条件期望值越大,则证明这个策略好,因为计算得到的奖励值足够大。
state value 表达式如下:

- 在下边这三个例子分别对应三个策略
,三个策略导致了三个轨迹(trajectory 理解为根据策略可能走出的轨迹),要计算在这三个不同策略下同一个状态 s1 的状态值(state value);
-
策略 1 和 2 从
出发,能得到唯一的一个 trajectory,这个 trajectory 的 return 就是它们分别的 state value;
-
策略 3 有两条轨迹,状态值(state value)是这两条轨迹分别得到的回报(return)的平均值。就是把 概率probability 乘到前面去,这实际上就是期望(expectation)的求法。
-
在第二小节中的例子策略都是确定的,return(s1和s2)和本节的state value(s3)值是不一样的,除非本节 π(a|s), p(r|s, a), p(s'|s, a)都被确定,计算的state value 和 return一样。

四、贝尔曼公式(推导过程和使用)
1.贝尔曼公式的推导
state value 是评估策略好坏的关键,贝尔曼公式是计算state value的关键;
贝尔曼公式描述了不同状态价值的关系;
贝尔曼公式是计算随机策略的。
依旧用上节的随机策略: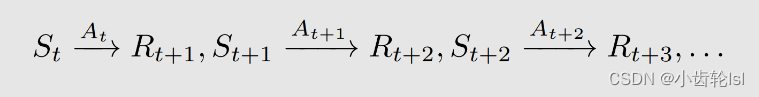 再根据第二节计算return的方法,将不同状态的价值关联起来,也将本节的不同状态关联计算状态值如下:
再根据第二节计算return的方法,将不同状态的价值关联起来,也将本节的不同状态关联计算状态值如下: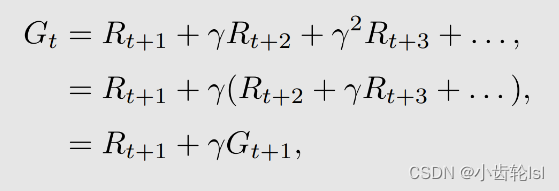
所以这个时刻所得到的 return 等于我能立即得到的奖励(immediate reward)Rt+1 加上到下一时刻从那出发能得到的 return(futrue reward)乘以 discount ratestate value计算过程就是求条件期望值: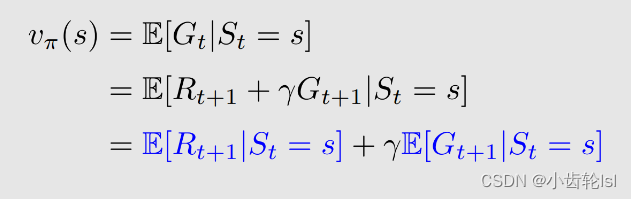
在上求解state value式子中,可以分成两个部分:
第一部分:即时奖励immediate rewards
在状态 s ,我有多个 action 可以去选择,take action a 的概率是 Π(a|s),当我 take action a 我所得到的 value 是 E[Rt+1|St = s, At = a]。E[Rt+1|St = s, At = a] 可以写成如下:
第二部分:未来奖励future rewards,从当前状态 s 出发得到的下一个时刻的回报(return)的期望(mean)
- 第一行:从当前 s 出发,有多个选择,可以跳到不同 s' ,跳到不同 s' 的概率是 p(s' | s),跳到不同 s' 所得到的值是 E[Gt+1|St = s, St+1 = s’ ],一相加就是 E[Gt+1|St = s]
-
从第一行到第二行:E[Gt+1 | St = s, St+1 = s’ ] 意思是当前状态是 s,下一个状态是 s',计算从下一个状态出发所得到回报(return)的期望(mean),第二行 E[Gt+1|St+1 = s' ] 把第一行中那一项的 St = s 去掉了,因为我已经知道了下一个状态是 s',就不用关系我之前究竟是在什么状态了,这其实就是马尔可夫的性质,是无记忆的(memoryless Markov property);
-
从第二行到第三行:E[Gt+1 | St+1 = s' ] 意思是从下一个状态 s' 出发计算我所能得到的回报(return)的平均值(mean),这个就是第三行写的一个状态值(state value)v_π(s’),只不过是针对 s' 的状态值(state value)v_π(s’)。——最开始的状态值(state value)的定义;
-
从第三行到第四行:从 s 到 s' 的概率 p(s' | s):从 s 出发我有多种选择,可以选择不同的动作(action),选择 action a 的概率是 π(a|s) ,选择这个 action 我跳到 s' 的概率是 p(s' |s, a),通过两者相乘相加可以得到 p(s' | s)。
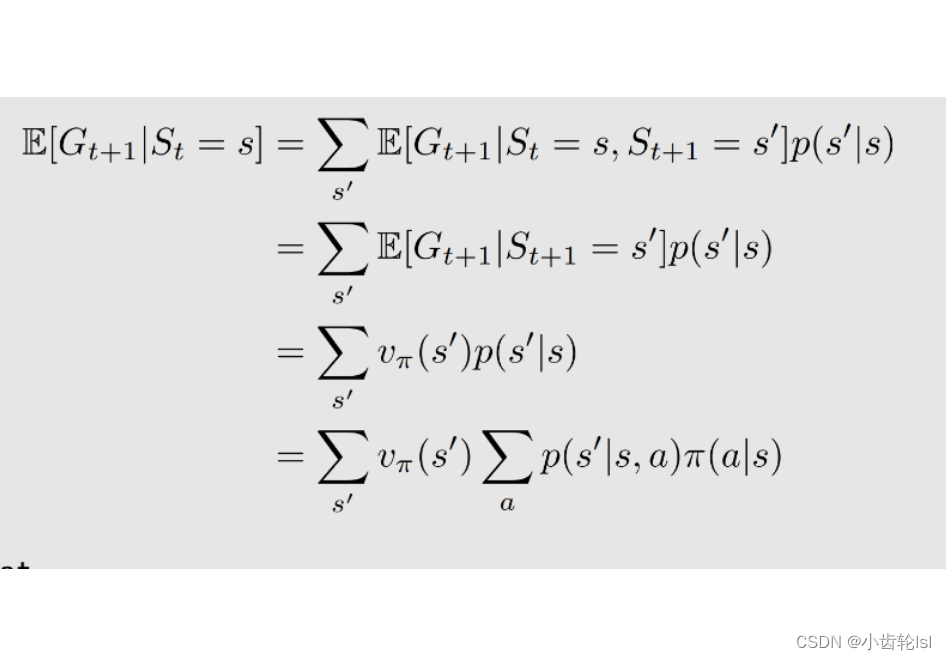
综合上述两部分的推导过程,可以写出贝尔曼公式:
总结:
贝尔曼公式描述的是不同状态state value之间的关系;
贝尔曼公式是由两部分组成当前奖励immediate rewards和未来奖励future rewards;
贝尔曼方程应用于所有状态,即每一个状态都都有相应的贝尔曼公式;
π(a|s) 是是一个给定策略的概率;
解方程称为策略评估(policy evaluation):贝尔曼公式依赖于策略(policy),如果我们能计算出状态值(state value),其实我们在做的一件事就是评估这个策略(policy evaluation)究竟是好是坏;
v_π(s) 和 v_π(s') 是我们要计算的状态值,计算的思想就是 Bootstrapping ! 直观上来讲,等式左边的状态值(state value)v_π(s) 依赖于等式右边的状态值(state value)v_π(s') ,看起来好像没法计算,其实我们有一组这样的式子,把这些式子连立就可以算出来。
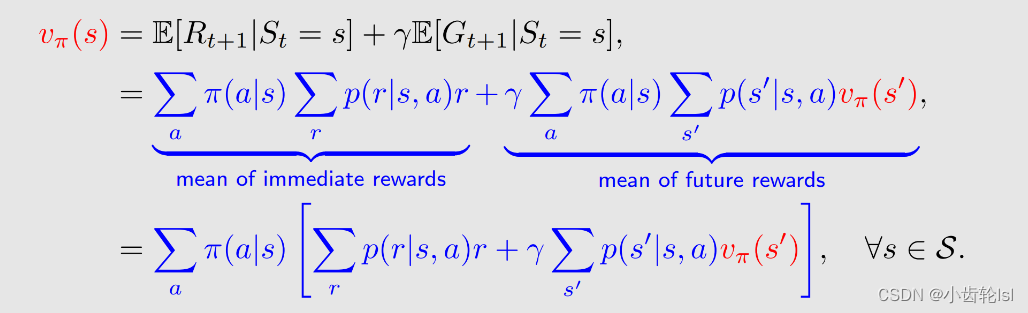
2.例子
这个例子的策略都是确定的。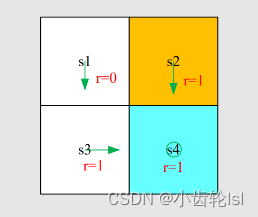
将得出的结果带入贝尔曼公式可得:
同理有:
在得到的式子组中,可以由第四个式子得到S4的结果,并依次推出S3\S2\S1
总结:贝尔曼公式求state value的过程
- 写出每个状态对应的贝尔曼公式;
- 从贝尔曼公式中求出state value;
- 与上一个策略中的state value对比,分辨出哪一个策略更优。
在上述例子中,我们已经求出了每个状态的state value,假设γ值为0.9,带入可得S1=9,S2/S3/S4=10,S1的state value最小,故这个策略最差,在网格中我们也可以看出S1是距离目标网格最远的,显而易见此策略最差,与计算得到的结果一致。
实例:
五、贝尔曼公式的矩阵向量形式和求解
1.贝尔曼公式的矩阵向量形式的推导
想要求解状态值(state value),单从一个贝尔曼公式无法求解,因为贝尔曼公式有两个状态的未知状态值,但是通过贝尔曼公式已知一个状态的状态值(value)依赖于另一个状态的状态值(value),并且对于所有的状态,都可以写一个贝尔曼公式来计算它当前状态的状态值(value),如果把所有状态求解状态值的贝尔曼公式都写到一块做一组线性方程,则这个线性方程就可以写成矩阵-向量模式。
贝尔曼公式(s ∈ S):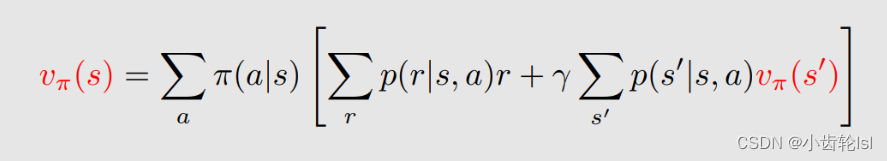
对于上式,为了更容易写出矩阵向量形式,我们可以进行化简得: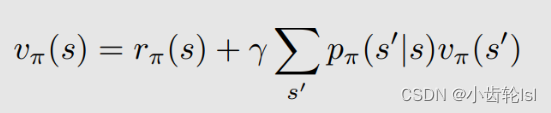
在这个式子中,第加号前的第一部分其实就是贝尔曼公式中推导的即时奖励,加号后的第二部分即使未来奖励。
其中前后两部分推导如下,第一个推导公式就是在s状态下所有可能行动得到奖励r的状态期望,即所得到的即时奖励(immediate reward)的平均值;第二个推导公式就是在s状态下采取所有可能行动到达s'的概率:
用 i、j 表示的通用计算表达式(其中,(
)是 从 si 跳到 sj 所取的 state value ):
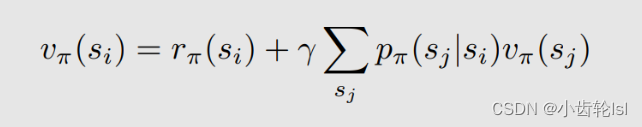
将式子写成可以作矩阵向量形式的线性方程,线性方程表达式(其中的就是一个向量):

2.例子
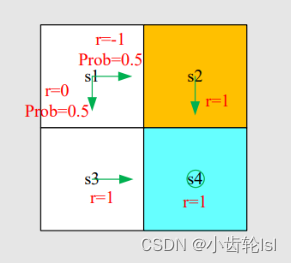
在此例子中有四个状态,可以先写出每个状态对应的贝尔曼公式的矩阵向量形式,在此例子中其中的和
都是已知的:
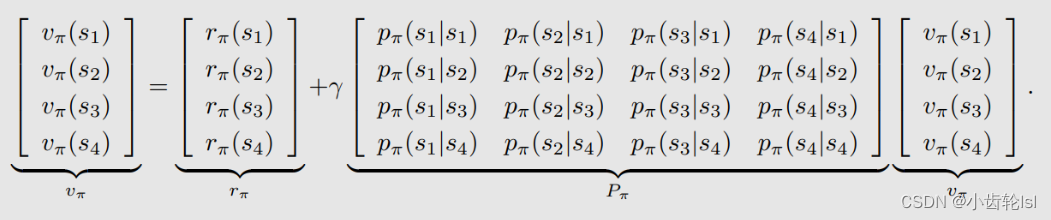
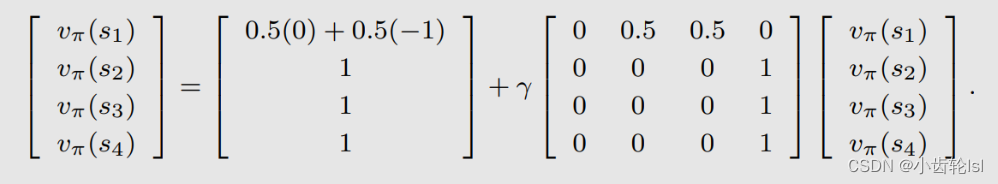
六、贝尔曼公式求解状态值(state value)
策略评估(policy evaluation):我们在想要达到一个目标状态时,有多种不同的策略,我们需要通过计算去评估这些策略哪一个更优,这就叫做策略评估,而在策略评估的过程中,使用的方法就是通过列出贝尔曼公式计算得到不同策略的状态值(state value),然后比较这些状态值来区分策略的优劣,最终通过改进得到最优的策略。
1.推导过程
贝尔曼公式的矩阵向量形式如下,在这个贝尔曼公式中,其中的矩阵P和向量i已知,求解状态值
可以用因式分解
然后作逆矩阵的方法(
),但是使用逆矩阵的方法时,假设状态有很多个,那么计算量就会很大,因此我们可以选择使用迭代算法的方式:
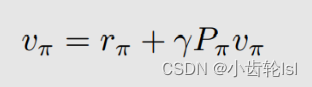
迭代法的迭代公式:
首先可以随便猜一个 等于什么(比如为0),然后带入到等式右边,得到等式左边的
;然后把
再带到等式右边,得到等式左边的
;然后把
再带到等式右边,得到等式左边的
,如此循环计算下去,就会得到一个序列 {
}。我们可以证明当 k 趋向于 ∞ 的时候,
就收敛到了
,这个
就是真实的状态值(state value)

2.例子
- 在此例中
;
- 此例子中的两个策略都是好的策略,它们的状态值都为正数,并且可以看到当靠近目标网格的时候,状态值是逐渐增大的;
- 这两个策略是不一样的,但是得到的状态值(state value)都是一样的,因此不同的策略也是可以得到相同的状态值的。
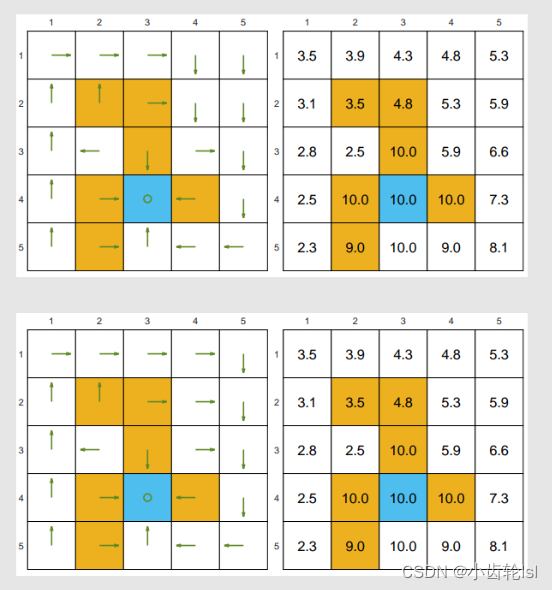
- 在下边这个例子中,两个策略都是坏的,因此它们的状态值(state value)得到的也都是负数。
- 其中的第二个是一个随机的策略产生过程,比较贴近实际,在我们的强化学习过程中正是需要通过改变随机的策略来使得状态值(state value)变大得到好的策略。

七、Action value计算(随即策略)
状态值(state value)和动作值(action value)的区别:
- 状态值(state value):从某一个状态开始到达目标状态所能获得的平均回报(average return);
- 动作值(action value):从某一个状态出发采取monument一项动作所能获得的平均回报。
- 在策略中我们选择动作值(action value)大的行动。
1.Action value的推导
action value的定义式(在状态s采取行动a,得到的平均奖励):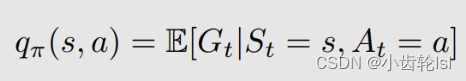
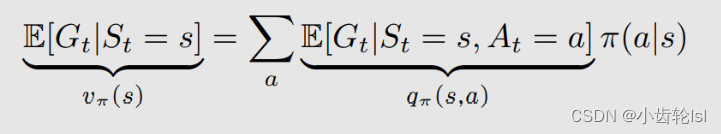
其实就是在上一节中计算状态值state value下某一状态下某一行动的期望奖励,state value和action value的关系如下,很明显的可以看出来不同策略采取不同行动的概率和在一个状态s下采取行动a,得到的平均奖励的乘积,就是策略评估中的状态值(state value):
- 对state value的计算表达式,表示了从动作值获得状态值;
- 对action value的计算表达式,表示了从状态值获得动作值。
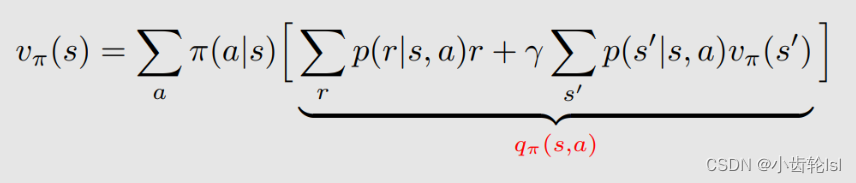
2.例子
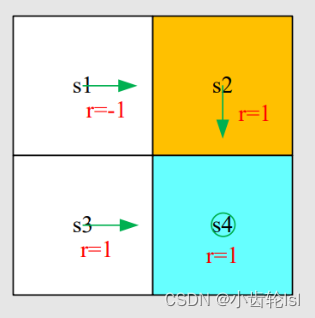
可以根据action value表达式写出在s1状态采取行动a2的计算式: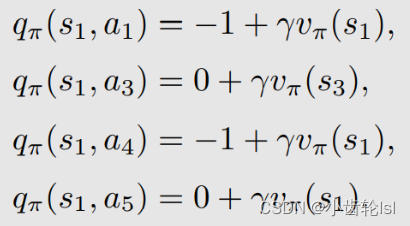
总结:
- action value动作值是评估动作好坏的参数,它对于下一步行动的选择非常重要,关系到下一侧采取哪种动作;
- 先计算状态值(state value),然后再计算动作值(action value);
- 也可以直接计算动作值(action value)。
章节总结
















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









