





摘要
自回归模型在自然语言处理(NLP)领域取得了巨大成功。最近,自回归模型在计算机视觉中也成为一个重要的研究领域,它们在生成高质量视觉内容方面表现出色。与NLP中通常操作的子词元不同,计算机视觉中的表示策略可以在不同层级变化,即像素级、标记级或尺度级,反映了视觉数据与语言的序列结构相比的多样性和层次性。本综述全面检查了应用于视觉的自回归模型文献。为了提高来自不同研究背景的研究人员的可读性,我们首先介绍视觉中的初步序列表示和建模。接下来,我们将视觉自回归模型的基本框架分为三个一般子类别,包括基于像素的、基于标记的和基于尺度的模型,这些是基于表示策略的。然后,我们探索了自回归模型与其他生成模型之间的相互联系。此外,我们提出了一个多角度分类的计算机视觉自回归模型,包括图像生成、视频生成、3D生成和多模态生成。我们还详细阐述了它们在不同领域,包括新兴领域如具身AI和3D医疗AI的应用,引用了约250篇相关文献。最后,我们强调了自回归模型在视觉中当前面临的挑战,并提出了关于潜在研究方向的建议。我们还建立了一个GitHub仓库,以组织本综述中包含的论文:Autoregressive Models in Vision Survey。
1 引言(要点总结)
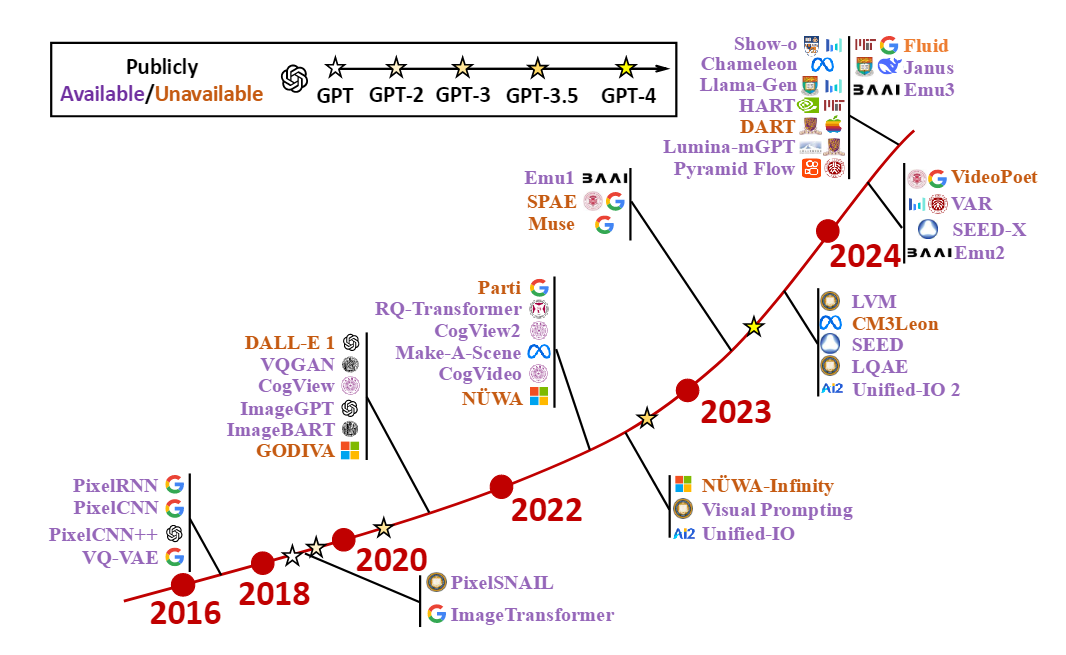
- 自回归模型起源:在NLP领域取得成功后,开始在计算机视觉中展现潜力。
- 模型优势:擅长捕获长期依赖关系,生成高质量、上下文相关的输出。
- 缩放定律:模型规模和计算预算的增加可以改善多个领域的性能。
- 视觉任务应用:自回归模型已应用于图像生成、超分辨率、编辑、翻译和视频生成等任务。
- 研究挑战:随着模型快速发展,综述最新的进展对研究社区至关重要。
- 模型分类:分为基于像素、基于标记和基于尺度的模型,每种都有其优势和挑战。
2 自回归模型
2.1 预备知识
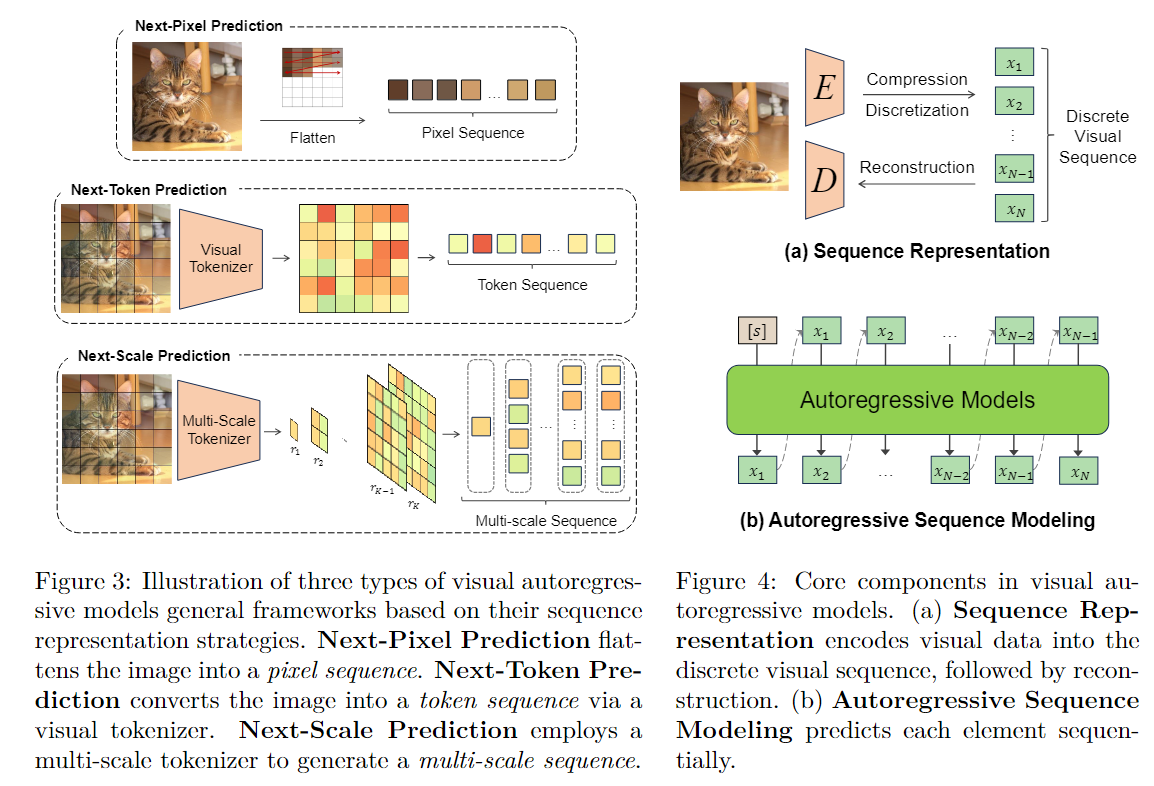
- 序列表示:视觉数据首先被转换成一系列离散元素,这些元素可能是像素、图像块或潜在代码。
- 自回归序列建模:模型训练的目标是生成每个元素,条件是所有前面的元素,通过最小化负对数似然损失。

2.2 通用框架
2.2.1 Pixel-based Models
- 基于像素的模型:直接在像素级别操作,捕获局部和长期依赖关系,但计算成本高。
1)随着序列长度的增加,计算成本呈二次方增加;2)逐像素信息的固有冗余。一些研究探索了采用并行技术在256×256分辨率下生成图像。然而,这些方法往往会产生次优和模糊的结果。
2.2.2 Token-based Models
基于标记的模型代表了视觉自回归建模的一个重大进步,这一范式从自然语言处理(NLP)中获得灵感。与直接在原始视觉数据上操作的像素级模型不同,这类模型将图像或视频压缩并量化为一系列离散的标记,从而实现对高分辨率内容的高效处理。
-
向量量化(VQ)技术:基于标记的模型使用向量量化技术将连续的视觉特征映射到离散的潜在代码序列。给定一个原始图像,编码器首先将图像映射到一个潜在特征图,然后这些连续的特征通过量化操作被转换为离散的代码。
-
VQ-VAE框架:VQ-VAE(Van Den Oord et al., 2017)是这一领域的开创性工作,它引入了一个两阶段范式,首先训练一个编码器-解码器架构来学习图像的离散表示,然后训练一个自回归模型来预测序列中的下一个离散标记。
-
编码器-解码器架构:在VQ-VAE框架中,编码器将输入图像映射到潜在空间,其中连续的潜在特征通过VQ被量化为离散代码。解码器随后从这些离散代码重建图像。
-
损失函数:VQ-VAE的训练目标包括重建损失和承诺损失,以确保潜在代码有效表示输入图像。

-
VQ-VAE的改进:后续工作如VQ-VAE-2和VQGAN通过引入多尺度层次结构和对抗训练进一步提升了生成图像的质量和多样性。
-
基于标记的模型的优势:与像素级模型相比,基于标记的模型能够更高效地处理高分辨率图像,并且能够扩展到更复杂的视觉任务。
-
挑战与未来方向:尽管基于标记的模型取得了进展,但仍面临如何提高码本利用率、优化采样速度等挑战。未来的研究可能会探索更大的码本尺寸、新的量化技术,以及如何将这些模型与大型语言模型(LLMs)结合,以实现更强大的多模态输入输出任务。
2.2.3 Scale-based Models
基于尺度的模型引入了一种层次化的方法来生成视觉内容,这与仅在单一分辨率上操作的传统的下一个标记预测模型不同。这类模型能够在多个尺度上生成图像,从粗糙的低分辨率逐步过渡到精细的高分辨率,从而更好地捕获视觉信息的多尺度特性。
-
多尺度表示:基于尺度的模型通过在多个尺度上表示图像,允许模型同时处理全局结构和细节特征。这种表示方法使得模型能够从不同分辨率理解视觉数据,增强了生成图像的质量和一致性。
-
自回归单元:在基于尺度的模型中,自回归单元是一个完整的标记图,而不是单个标记。这使得模型在生成过程中能够并行生成一个尺度上的所有标记,提高了生成效率。
-
生成过程:生成过程从最粗糙的尺度开始,逐步自回归地生成更高分辨率的标记图。在每一步中,模型都会生成一个完整的标记图,从而保持空间局部性并利用图像的固有结构。
-
VAR模型:VAR(Tian et al., 2024)是实现基于尺度预测的先驱工作,它从NLP中的自回归模型中汲取灵感,将这一概念应用于视觉领域。VAR模型通过多尺度量化自编码器将图像离散化为不同尺度的标记图,并从低分辨率逐步构建到高分辨率。
-
Residual Quantization (RQ):RQ技术是RQ-VAE(Lee et al., 2022a)中引入的,它通过递归量化残差向量来改进标准VQ。这种方法允许模型用固定大小的码本来表示高分辨率图像,同时减少空间分辨率,保留关键信息。
-
优势:基于尺度的模型相比基于标记的模型,提供了几个优势,包括更好的空间局部性保持,以及通过在每个标记图中并行生成标记来提高效率,这对于扩展到更大的图像分辨率特别有益。
-
挑战与未来方向:尽管基于尺度的模型提供了多尺度生成的能力,但它们在训练和计算上引入了显著的复杂性。未来的研究可能会集中在如何优化这些模型以提高效率,以及如何进一步整合多尺度信息以增强生成的视觉内容的质量和多样性。
2.3 与其他生成模型的关系
- 变分自编码器(VAEs):通过变分下界优化,与自回归模型相比,可能产生较模糊的输出。
- 生成对抗网络(GANs):以快速推理和高质量图像生成而闻名,但训练过程可能不稳定。
- 正则化流:通过可逆变换优化似然,与自回归模型相比,架构上更为受限。
- 扩散模型:作为最新的生成范式,与自回归模型在优化似然和生成高质量样本方面相似,但生成过程不同。
2.4 自回归模型的挑战和未来研究方向
- 标记器设计:如何设计一个强大的标记器以有效压缩和重建视觉内容。
- 离散与连续:探讨自回归模型中使用离散或连续表示的优劣。
- 模型架构:研究是否需要特定于视觉的归纳偏置,以及如何整合这些偏置。
- 下游任务适应性:探索自回归模型如何适应新的下游任务,以及是否能够通过提示调整快速适应。
3 Visual Autoregressive Models
3.1 图像生成
3.1.1 无条件图像生成
无条件图像生成指的是模型在没有任何输入或引导条件下生成图像,仅依赖于训练数据中学习到的视觉模式。
3.1.1.a 像素级生成
- PixelRNN 和 PixelCNN:通过RNN和CNN技术顺序预测像素值,捕获复杂依赖关系。
- PixelCNN++:优化PixelCNN,使用离散逻辑混合似然函数和架构改进,提高图像质量和效率。
- Transformer-based Approaches:利用Transformer模型的长距离依赖捕捉能力,进行像素级生成。
3.1.1.b 标记级生成
- VQ-VAE:引入向量量化技术和两阶段范式,将图像压缩成离散标记序列。
- VQ-VAE-2 和 VQGAN:通过多尺度层次结构和对抗训练提升生成图像的质量和多样性。
- Image Tokenizer Design:设计有效的图像标记器,将图像转换为离散标记序列。
3.1.1.c 尺度级生成
- VAR:引入基于尺度的生成方法,从粗糙到精细多尺度生成图像,减少序列长度,提高效率。
3.1.2 文本到图像合成
文本到图像的生成涉及根据文本描述生成图像,使模型能够产生更有针对性的、与上下文相关的图像。
3.1.2.a 标记级生成
- DALL·E 和 CogView:将文本和图像转换为离散标记,并使用文本标记作为前缀条件来预测图像标记。
- Integration with Diffusion Models:结合扩散模型和自回归模型,如VQ-Diffusion和Kaleido Diffusion,提升文本到图像合成的质量。
3.1.2.b 尺度级生成
- STAR 和 VAR-CLIP:将尺度级生成范式应用于文本到图像合成,生成从粗糙到精细的多尺度图像。
3.1.3 图像条件合成
自回归模型在图像到图像的翻译任务中发挥了重要作用,目标是将一个图像域翻译到另一个域。
3.1.3.a 图像绘画
- Inpainting 和 Outpainting:修复和扩展图像,需要与现有内容保持视觉连贯性。
3.1.3.b 多视图生成
- MIS 和 SceneScript:自回归框架用于生成多个相关图像,保持场景间的语义一致性。
3.1.3.c 视觉上下文学习
- MAE-VQGAN 和 VICL:通过视觉提示和上下文学习,使模型能够根据提供的图像查询生成预测。
3.1.4 图像编辑
图像编辑专注于根据用户输入修改、增强或重建图像。
3.1.4.a 文本驱动的图像编辑
- VQGAN-CLIP 和 Make-A-Scene:结合VQGAN的图像合成能力和CLIP的文本引导图像修改能力,实现基于文本的图像编辑。
3.1.4.b 图像驱动的图像编辑
- ControlAR 和 ControlVAR:引入空间控制机制,如Canny边缘和深度图,以精确控制图像标记的生成过程。
3.2 视频生成
3.2.1 无条件视频生成
- 视频像素网络 (VPNs):将PixelCNN模型扩展到视频数据,基于之前像素和帧生成每个像素。
- MoCoGAN:通过将视频生成分解为运动和内容两个组件,使用GANs分别生成静态内容帧和运动向量序列。
- Video Transformer:利用Transformer架构处理大型数据集,生成更高分辨率、更长的视频。
- LVT 和 VideoGPT:结合VQ-VAE和Transformer,实现在离散潜在空间中的平衡,提高视频生成的多样性和保真度。
- TATS 和 PVDM:基于VQGAN和Transformer架构,生成时间上一致的长视频,展示视频生成中的先进扩散方法。
3.2.2 条件视频生成
- 文本到视频合成:将文本描述转换为视频序列,如IRC-GAN、Godiva和CogVideo等模型,通过不同的方法提高文本到视频合成的质量和一致性。
- 视觉条件视频生成:基于初始帧或图像生成未来的视频帧,如Convolutional LSTM Network和PredRNN等模型,有效捕捉空间和时间依赖性。
3.2.3 具身AI
在这种情况下,视频生成不仅仅是创建视觉上吸引人的或现实的序列;相反,它作为训练和增强与环境中交互和导航的智能代理的关键组成部分。通过提供合成但逼真的视觉数据,视频生成技术可以显着提高嵌入式 AI 系统的学习过程,使它们能够更好地理解和响应动态的现实世界场景。
如何利用视频生成来增强具身AI,弥合视觉合成与智能交互之间的差距?
- 学习通用世界模型:通过提供合成的视觉数据,增强具身AI系统的训练,使其更好地理解和响应动态的真实世界场景。
- 行动条件视频预测模型:预测基于当前观察和动作的未来帧,提高样本效率并减少调整需求,特别是在Atari 100k基准测试中表现突出。
4 评估指标
视觉标记器重建评估
- 峰值信噪比 (PSNR):↑ 表示越高越好,衡量重建图像与其参考图像之间的像素级对齐程度。
- 结构相似性指数 (SSIM):↑ 表示越高越好,考虑结构、亮度和对比度的感知差异。
- 学习感知图像补丁相似性 (LPIPS):↓ 表示越低越好,通过评估预训练VGG网络的特征来衡量感知相似性。
- 重建Fréchet Inception距离 (rFID):↓ 表示越低越好,衡量原始和重建图像集在特征空间中的分布差异。
视觉自回归生成评估
-
视觉质量:
- 负对数似然 (NLL):↓ 表示越低越好,直接量化模型学习分布下生成数据的可能性。
- Inception Score (IS):↑ 表示越高越好,衡量生成样本的质量和多样性。
- Fréchet Inception Distance (FID):↓ 表示越低越好,衡量生成样本与真实数据分布的接近程度。
- Kernel Inception Distance (KID):↓ 表示越低越好,基于核方法的FID变体。
- Fréchet Video Distance (FVD):↓ 表示越低越好,考虑时间建模的视频生成任务的FID扩展。
-
多样性:
- 精确度和召回率:↑ 表示越高越好,衡量生成样本的多样性和丰富性。
- MODE Score:↑ 表示越高越好,量化生成样本的质量和多样性。
-
语义一致性:
- CLIP相似性 (CLIPSIM):↑ 表示越高越好,使用预训练的CLIP模型量化视觉输出和文本输入之间的余弦相似性。
- R-precision:↑ 表示越高越好,衡量与预期上下文对齐的相关生成样本的排名。
-
时间一致性:
- Warping Errors:↑ 表示越高越好,基于光流的度量,衡量生成帧之间的运动和对象放置的一致性。
- CLIPSIM-Temp:↑ 表示越高越好,计算连续帧嵌入之间的CLIP相似性。
-
以人为本的评估:
- 人类偏好得分 (HPS):↑ 表示越高越好,利用在人类偏好数据上训练的分类器估计生成输出与人类审美判断的一致性。
- 质量ELO得分:↑ 表示越高越好,基于在线平台上用户对模型输出的偏好表达计算得分。
- 用户研究指标:包括评分、偏好等主观度量,提供特定案例的洞察。
5 挑战和未来工作
设计强大的标记器(Tokenizer)
- 现有模型分类:自回归模型分为基于像素、基于标记和基于尺度的方法。基于标记和基于尺度的方法依赖于强大的标记器,将图像或视频压缩成离散的视觉标记。
- VQGAN挑战:VQGAN因其丰富的感知标记器而广泛使用,但随着码本大小的增加,其利用率成为瓶颈。
- 码本设计趋势:研究趋势指向使用较小的向量维度和较大的码本大小以提高查找效率和码本利用率。
- 先进训练策略:探索提高VQGAN码本利用率的先进训练策略。
- 层次多尺度特性:利用层次多尺度特性改善视觉数据压缩。
离散还是连续(Discrete or Continuous)?
- 传统自回归模型:通常与离散表示相关,但视觉数据本质上是连续的。
- 连续表示的优势:简化视觉数据压缩器的训练,但需要设计新的损失函数和处理多模态适应性问题。
- 连续表示的挑战:在自回归模型中整合连续和离散表示是一个复杂任务。
架构中的归纳偏置(Inductive Bias)
- 自回归模型架构:探讨是否需要为视觉信号定制的归纳偏置。
- 特定视觉架构的优势:一些方法利用层次多尺度特性或掩码图像建模策略来提高性能。
- 双向注意力的优势:双向注意力对于处理视觉信号的优势。
下游任务(Downstream Tasks)
- 零样本能力:当前研究集中在有限任务的零样本能力或为特定下游应用定制模型。
- 适应新任务:探讨自回归模型是否能够通过提示调整和指令调整快速适应新任务。
- 统一自回归模型:开发能够适应下游任务的统一自回归模型是未来工作的重点。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









