







文章目录
0. RLHF
强化学习比 SFT 更可以考虑整体影响
强化学习更容易解决幻觉问题
强化学习可以更好的解决多轮对话奖励累积问题
强化学习(Reinforcement Learning,RL)研究的问题是智能体(Agent)与环境(Environment) 交互的问题,其目标是使智能体在复杂且不确定的环境中最大化奖励(Reward)。
智能体在这个过程中不断学习,它的最终目标是:找到一个策略,这个策略根据当前观测到的环境状态和奖励反馈,来选择最佳的动作。
1. RLHF 的核心思想
RLHF 的本质 :让模型通过人类的主观反馈(比如“这个回答更好”或“这个故事更有趣”)来学习,而不仅仅是依赖预定义的数学目标。
为什么需要它?
- 传统强化学习依赖明确的奖励函数(比如游戏得分),但很多任务(如对话、写作)的“好坏”难以用数学公式定义。
- 人类可以直观判断输出质量,但无法直接写出规则。RLHF 将人类的模糊偏好转化为模型可学习的信号。
2. RLHF 的三大步骤
步骤 1:预训练语言模型(Pre-trained LM)
目标 :先让模型学会语言的基本规律(比如语法、常识)。
方法 :在大量文本数据上进行自监督学习(如 GPT 的预训练)。
公式 :
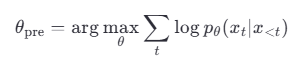
其中,θ 是模型参数,xt 是第 t 个 token,x<t 是前面的 token 序列。
例子 :预训练后的模型能续写句子,但可能缺乏对“好回答”的理解
步骤 2:训练奖励模型(Reward Model, RM)
目标 :用人类偏好数据教会模型“什么是好的输出”。
人类反馈数据 :收集人类对同一问题的多个模型输出的偏好标注(比如选择 A 回答比 B 更好)。
模型结构 :通常是一个神经网络,输入是(问题+模型输出),输出是标量奖励值 r。
公式 :
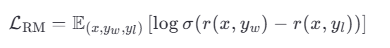
其中,x 是输入,yw 是人类偏好的回答,yl 是较差的回答,σ 是 Sigmoid 函数。目标是让 r(x,yw)>r(x,yl)。
例子 :对于问题“解释相对论”,人类标注者选择“简洁版”而非“冗长版”,奖励模型会学习到简洁性更重要
步骤 3:强化学习微调(RL Fine-tuning)
目标 :用奖励模型指导模型生成更符合人类偏好的输出。
方法 :使用强化学习算法(如 PPO,近端策略优化)更新模型参数。
公式 :
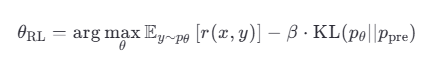
第一项:最大化预期奖励(让输出更符合人类偏好)。
第二项:KL 散度约束(防止模型偏离预训练分布太远,β 是超参数)。
例子 :模型生成回答后,奖励模型打分,强化学习根据分数调整生成策略
3. RLHF 的关键优势与挑战
优势
直接对齐人类价值观 :无需手动设计奖励函数,适用于复杂任务(如对话、创意写作)
提升模型安全性 :通过人类反馈减少有害输出(如 ChatGPT 的伦理约束)
挑战
数据成本高 :需要大量高质量人类标注数据。
奖励模型偏差 :人类偏好可能不一致或存在偏见,导致模型学习到错误信号
1. RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
A key advantage of RL is its ability to discover optimal action distributions through trial and-error exploration, leading to more robust and efficient policies compared to pure imitation learning.
强化学习的一个关键优势在于其能够通过试错探索发现最优的动作分布,从而与纯模仿学习相比产生更鲁棒和高效的策略。
然而, 强化学习策略通常难以泛化到其训练分布之外,需要为每个任务变体或环境条件单独训练策略。
[EAI-021] RLDG,通过蒸馏RL策略提高VLA的精细操作能力
针对痛点和贡献
痛点:
- 人类演示数据的不一致性:人类演示往往在执行质量和风格上存在不一致性,导致基础模型难以学习到鲁棒的策略。
- 精确操作任务的挑战:接触丰富的操作任务需要精细的、反应式的控制,而现有基础模型在这些任务中表现不佳。
- 强化学习直接微调的困难:直接使用强化学习对基础模型进行微调存在优化不稳定、计算成本高和灾难性遗忘等问题。
- 数据收集成本高:依赖人类演示的数据收集成本高且效率低。
贡献:
- 提出 RLDG 方法:通过强化学习生成高质量训练数据,为预训练的机器人基础模型提供自动化的微调方法。
- 提升性能和泛化能力:RLDG 在精确操作任务中显著提升了通用策略的成功率和泛化能力,减少了对人类演示数据的依赖。
- 灵活的应用场景:RLDG 可以灵活地应用于多阶段任务,通过强化学习数据解决关键阶段的“瓶颈”问题,同时保留人类演示在其他阶段的优势。
- 样本效率高:RLDG 在样本效率上优于传统方法,使用更少的数据即可达到更高的性能。
摘要和结论
本文提出了一种名为 Reinforcement Learning Distilled Generalist(RLDG) 的方法,通过强化学习生成高质量训练数据来微调机器人基础模型。 通过在多个精确操作任务上的实验,我们证明了 RLDG 在成功率和泛化能力上显著优于使用人类演示的传统微调方法。RLDG 不仅减少了对人类演示数据的依赖,还展示了在复杂多阶段任务中的灵活性和有效性。我们的研究为机器人学习提供了一个有前景的方向,即利用强化学习作为基础模型的高质量训练数据的自动化来源,从而实现更精确的操作和更广泛的泛化能力。
引言
近期,机器人基础模型的研究进展使得开发能够适应多样化任务的通用策略成为可能。然而,这些模型的性能高度依赖于训练数据的质量。人类演示虽然易于获取,但存在不一致性和不精确性,限制了模型的鲁棒性和性能。 为此,我们提出了 RLDG,一种通过强化学习生成高质量训练数据的方法,用于微调机器人基础模型。RLDG 结合了强化学习的优化能力和基础模型的强大泛化能力,显著提升了通用策略在精确操作任务中的性能和泛化能力。
模型框架
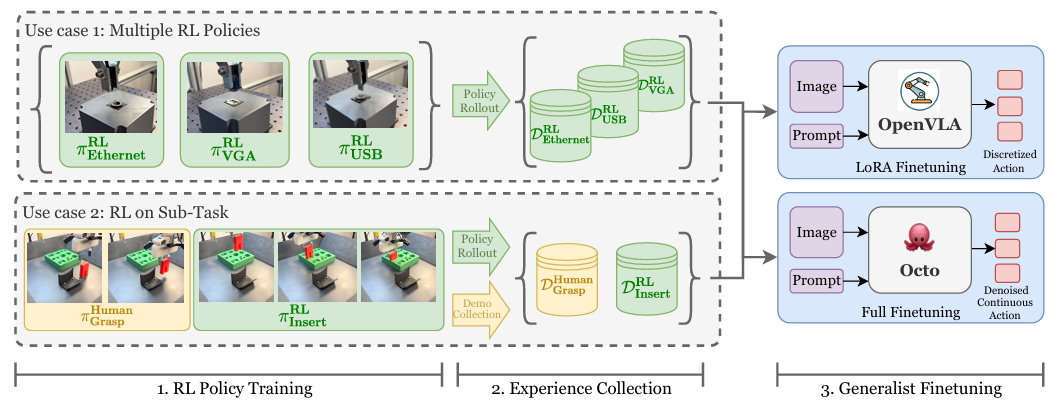
RLDG 通过使用专业的 RL 策略进行训练,并利用这些策略生成高质量的微调数据集,改进了 OpenVLA 和 Octo 等通用机器人策略。它可以灵活地从针对单个窄范围任务训练的多个 RL 策略中提炼知识,并将其汇集成一个通用策略。它还可以应用于长期操作任务中最关键的子任务,在“bottleneck”部分提高成功率,同时在任务的某些部分充分利用人类的演示。
RLDG 的框架包括三个主要步骤:
-
在线强化学习训练:使用样本高效的强化学习框架(如 HIL-SERL)训练专门的强化学习策略,直到策略收敛。
-
经验收集:从收敛的强化学习策略中收集高质量的训练数据,用于微调通用策略。
-
通用策略微调:使用收集的数据对预训练的通用策略(如 OpenVLA 或 Octo)进行微调,以提升其在特定任务上的性能。
实验
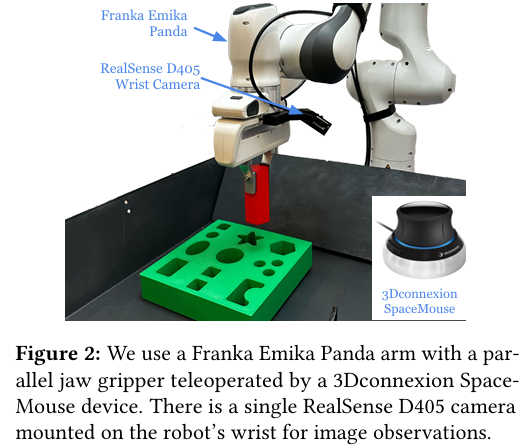

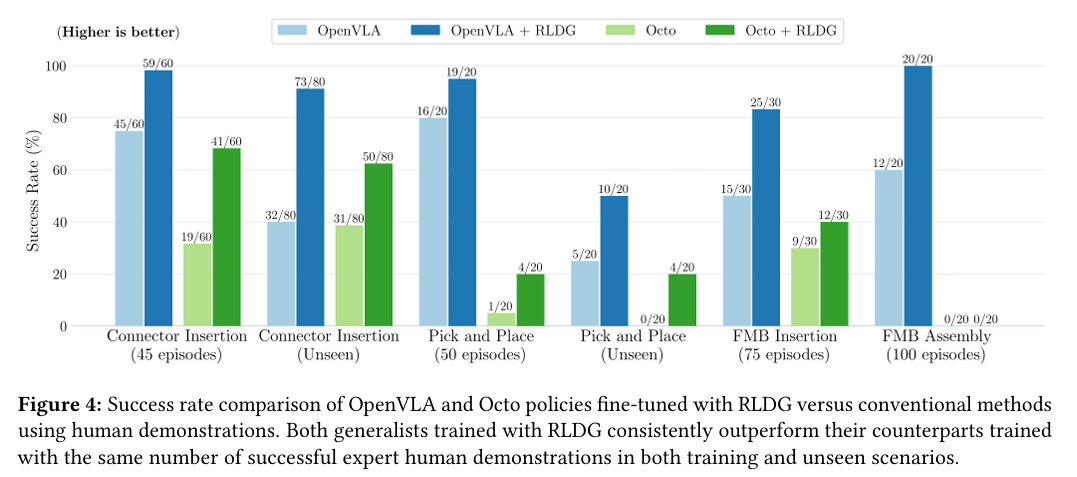
图 4:使用 RLDG 与传统方法微调的 OpenVLA 和 Octo 策略的成功率比较;使用人工演示。在训练和未见过的场景中,使用 RLDG 训练的两位通才策略始终优于使用相同数量的专家级人工演示进行训练的对手。
思考不足之处
- 对奖励函数的依赖:RLDG 假设可以访问微调任务的奖励函数,这在某些实际应用中可能难以实现。
- 速度优化的局限性:强化学习策略优化的速度目标可能导致策略在某些任务中过于追求速度,从而引入新的失败模式(如拾取与放置任务中的早期释放问题)。
- 计算资源需求:尽管 RLDG 减少了对人类演示数据的依赖,但强化学习训练仍需要较高的计算资源。
- 未来方向:未来的研究可以探索自动生成微调任务和奖励函数的方法,以减少对手动任务规范的依赖,并进一步提升策略的鲁棒性和泛化能力。
2. Improving Vision-Language-Action Model with Online Reinforcement Learning
针对痛点和贡献
痛点:
- 高质量专家数据集的获取困难:在机器人领域,获取高质量的专家数据集成本高昂且实施难度大,这限制了监督微调(SFT)方法的进一步应用。
- 监督学习的局限性:由于分布偏移问题,监督学习可能无法使视觉-语言-行动(VLA)模型完全适应物理环境。
- 在线强化学习的不稳定性:将标准的在线强化学习(RL)算法直接应用于大型VLA模型时,会导致训练过程不稳定,甚至出现性能下降的情况。
- 计算资源的限制:大型VLA模型的微调需要大量的计算资源,这超出了大多数本地机器的能力,同时完全依赖远程服务器又会引入参数传输问题并降低控制频率。
贡献:
- 提出了iRe-VLA框架,该框架通过在强化学习和监督学习之间进行迭代,有效改进了VLA模型,同时保持了训练的稳定性。
- 在RL阶段冻结视觉-语言模型(VLM)参数,仅训练轻量级动作头,从而避免了模型崩溃并加速了学习过程。
- 在监督学习阶段,利用成功轨迹对整个模型进行微调,充分利用了大型模型的表达能力,提升了模型性能。
- 通过在模拟和真实世界环境中的实验验证,证明了iRe-VLA方法在提升模型性能、稳定训练过程以及提高计算效率方面的有效性。
- 展示了iRe-VLA方法在解决未见任务和提升模型泛化能力方面的潜力。
摘要和结论
摘要:
本文探索了如何通过在线强化学习进一步提升视觉-语言-行动(VLA)模型的性能。针对直接应用在线RL算法导致的训练不稳定和性能下降问题,我们提出了iRe-VLA框架。该框架通过迭代强化学习和监督学习,在保持训练稳定性的同时,有效提升了VLA模型的性能。实验结果表明,iRe-VLA在模拟和真实世界任务中均表现出色,不仅提升了模型在原始任务上的性能,还增强了其在未见任务上的泛化能力。
结论:
iRe-VLA方法成功地解决了在大型VLA模型上进行微调时遇到的训练不稳定和计算资源限制的问题。通过在模拟和真实世界操作任务中的实验验证,我们确认了iRe-VLA的有效性。然而,该方法目前的局限性在于只能改进已见类型的技能,无法在稀疏奖励的在线RL条件下学习全新的技能。
引言
随着大型语言模型(LLMs)和视觉-语言模型(VLMs)在各种高级任务中的应用,如对话系统、代码生成和任务规划,这些模型也开始被应用于低级机器人控制。通过监督微调(SFT),VLMs被开发成视觉-语言-行动(VLA)模型,能够直接输出低级机器人控制信号。然而,SFT依赖于高质量的专家数据集,且可能无法完全适应物理环境。为了解决这些问题,我们尝试使用在线强化学习(RL)来进一步改进VLA模型。然而,直接应用标准RL算法会导致训练不稳定。为此,我们提出了iRe-VLA框架,通过迭代RL和SL来稳定训练过程并提升模型性能。
模型框架
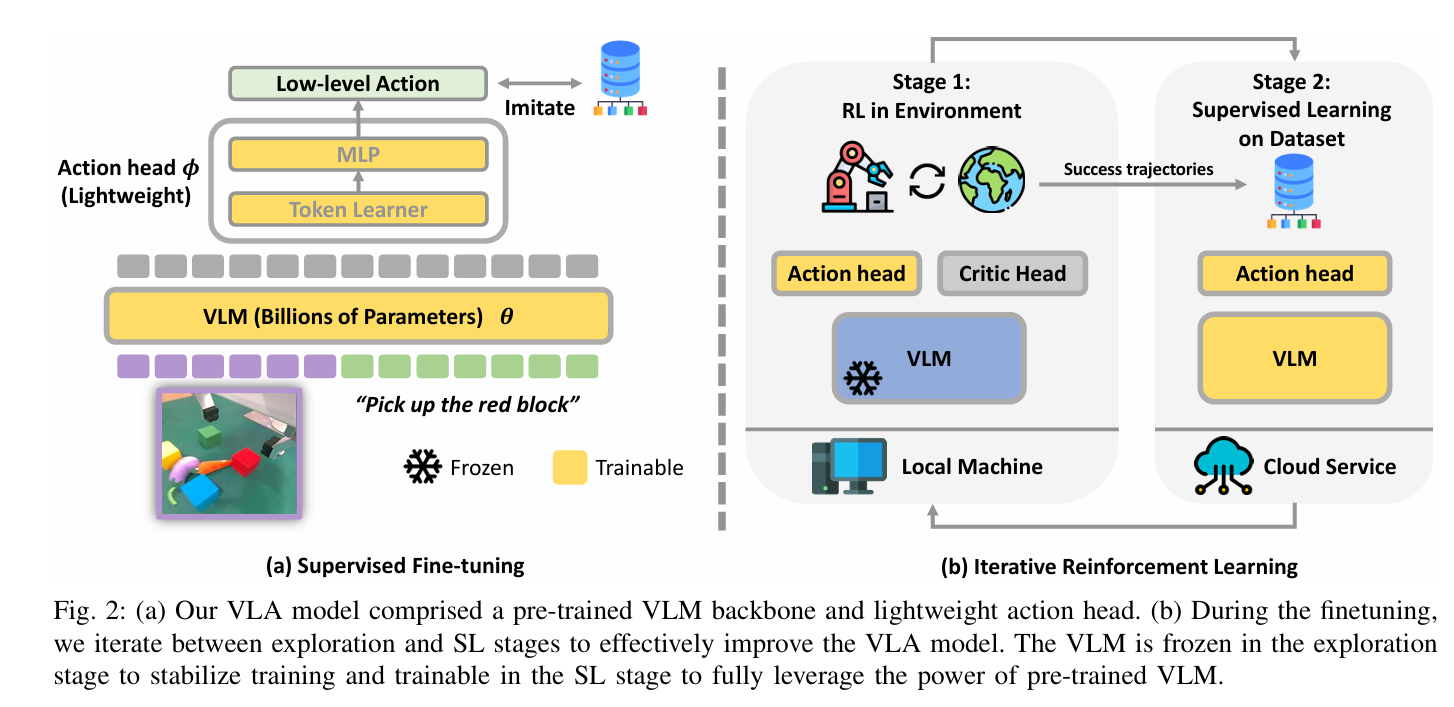
iRe-VLA框架包含三个主要阶段:监督微调(SFT)、在线强化学习(RL)和监督学习(SL)。
在SFT阶段,VLA模型在专家数据集上进行训练。我们首先对VLA模型 πθ,ϕ 进行标准的监督微调,使用专家机器人数据集 De={(o1,l1,a1),(o2,l2,a2),…,(oi,li,ai)}。形式上,学习目标由均方误差(MSE)损失定义为:
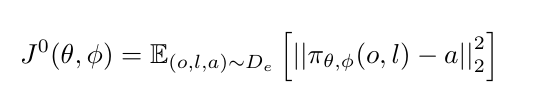
在RL阶段,冻结VLM参数【为了防止模型崩溃并加速学习过程】,仅训练动作头,以维持训练稳定性。经过在线强化学习后,机器人可能会发现新的轨迹 xi 来解决新任务。 然后我们将这些成功轨迹收集到在线数据集 DRL=DRL∪xi 中。
在专家和在线收集的数据上进行监督学习。在阶段1中,智能体在新任务上进行RL时,可能会遗忘之前学到的任务。因此,在阶段2中,我们使用新收集到的在线数据 DRL 和原始专家数据集 De 对整个模型进行监督学习,以减轻灾难性遗忘。形式上,目标可以写为:
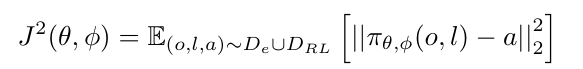
在阶段1和阶段2之间进行迭代。如前所述,智能体在阶段1中探索新任务的新解决方案,而在阶段2中,它模仿所有可用的成功轨迹。通过在阶段1和阶段2之间交替,大型VLA模型能够逐步解决更广泛的任务范围,同时防止在已见任务上出现灾难性遗忘。 此外,如以往的研究所述,通过模仿更广泛的任务,VLA模型可能会变得更加具有泛化能力。整个流程如算法1所示。

实验
实验设置:
我们在三个领域进行了实验:MetaWorld、FrankaKitchen和真实世界的Panda操作任务。每个领域包含三类任务:专家数据集中的任务、通过在线RL训练的任务以及未见任务。我们使用单一的文本条件VLA模型来解决每个领域中的所有任务。
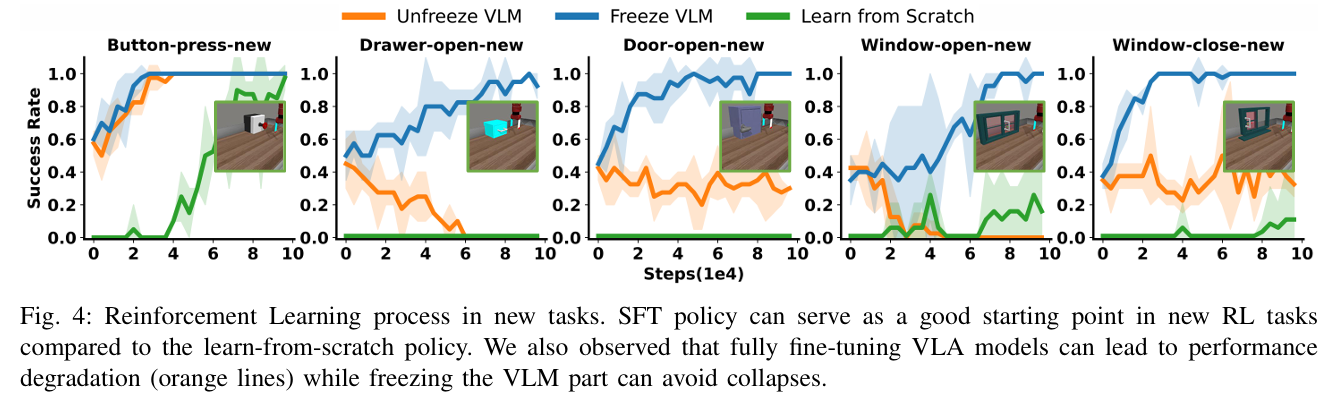
冻结VLM参数 避免模型坍塌。
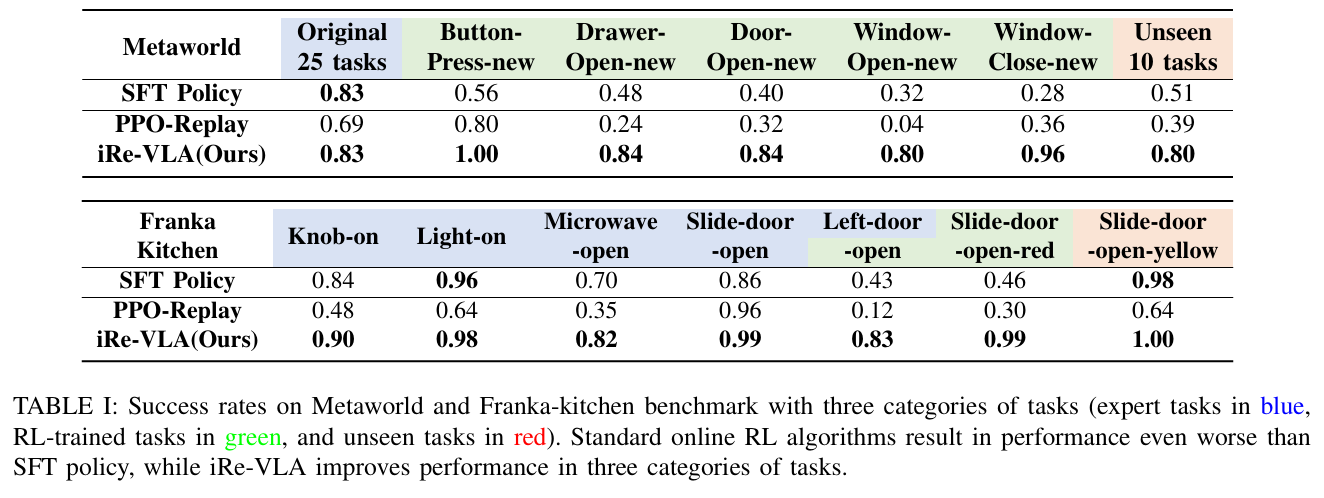
iRe-VLA在专家任务、RL训练任务和未见任务上均表现出色,成功提升了任务成功率。
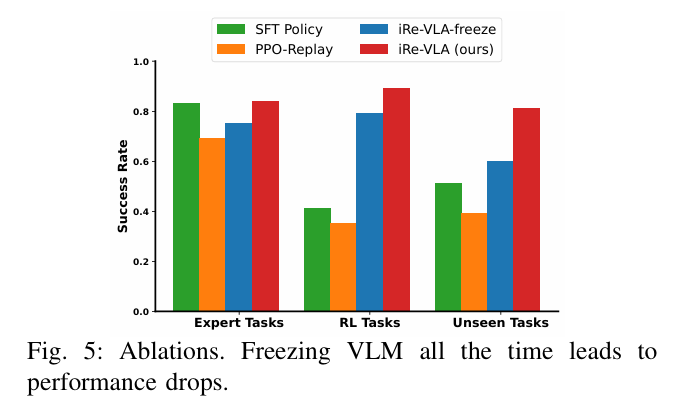
关键结论:
- 训练稳定性:直接应用标准RL算法会导致性能下降,而iRe-VLA通过冻结VLM参数有效避免了这一问题。
- 性能提升:iRe-VLA在专家任务、RL训练任务和未见任务上均表现出色,成功提升了任务成功率。
- 泛化能力:通过在线交互,iRe-VLA增强了VLA模型的泛化能力,使其能够更好地处理未见任务。
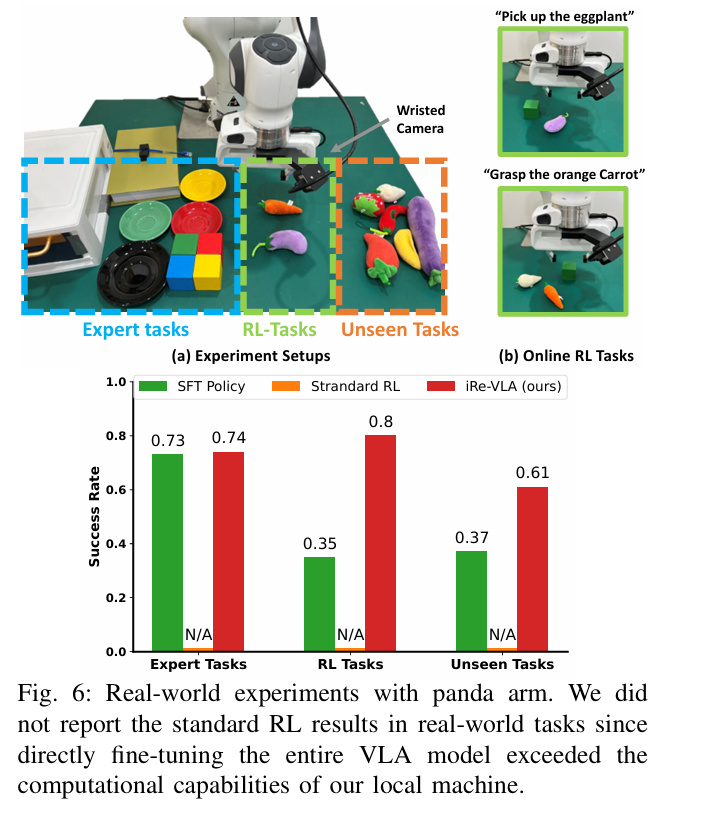
具体结果:
- 在MetaWorld的25个专家任务中,iRe-VLA成功提升了任务成功率,例如在Frankakitchen基准测试中,将left-door-open任务的成功率从0.43提升到0.83。
- 在真实世界实验中,iRe-VLA将抓取未见物体(如胡萝卜和茄子)的成功率从0.35提升到0.80,同时保持了原始任务的成功率稳定。
思考不足之处
尽管iRe-VLA在提升VLA模型性能和泛化能力方面表现出色,但该方法仍存在一些局限性:
- 技能范围限制:iRe-VLA只能改进已见类型的技能,无法在稀疏奖励的在线RL条件下学习全新的技能。
- 计算资源需求:尽管iRe-VLA通过分阶段优化降低了计算负担,但仍然需要一定的计算资源,这可能限制了其在资源受限环境中的应用。
- 泛化能力的进一步提升:虽然iRe-VLA增强了模型的泛化能力,但在面对更加复杂的未见任务时,可能仍需要更多的改进和优化。

















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









